1 计算机基础知识
1.1 计算机是什么
计算机就是用来计算的机器,目前来说,计算机只能根据人类的指令来完成各种操作,所以学习计算机或者说学习一种语言,也就是学习如何去操控计算机来为我们服务!
1.2 计算机的组成
- 计算机的组成部分:硬件系统和软件系统
- 硬件系统一般包括:CPU,存储器,输入设备,输出设备。
- 软件系统一般分为:系统软件(windows,macOS,linux)和应用软件(QQ,office,google)。
-
1.3 如何使用计算机
除了一般的电脑基础知识外(电脑开关机,安装卸载软件,浏览器的使用),一般有两个交互方式来使用计算机,一个是TUI(文本交互界面),也是开发中必须掌握的技能,linux服务器就是典型的TUI,使用命令去操作计算机,另一种是GUI(图形交互界面),这是最常用的操作计算机的方式,简单,方便,牺牲了一点速度来换取方便。
1.4 windows下的命令行
windows下也有自己的图形交互界面,也就是常说的DOS系统,是最早期的可以直接操作硬件的系统,学习计算机的开始,我们都要掌握DOS的常用命令。
如何进入到命令行界面:
- 第一:win10系统下。左下角呼唤小娜,搜索框 输入cmd,可以进入到命令行
- 第二:左下角右击,有一个运行,点击进去输入cmd,可以进入到命令行
- 第三:Windows+R键,唤起运行,然后输入cmd,进入到命令行
常用的DOS命令如下,仅供参考
- X: 切换都X盘
- dir 查看当前路径下的所有文件和文件夹
- cd path 进入到指定目录path
- cd .. 返回到上一次目录
- cd . 表示当前目录
- md name 创建文件夹name
- rd name 删除文件夹name
- del abc 删除文件abc
- cls 清空屏幕
一些小技巧:
- 方向键上下,可以查看命令的历史记录
-
1.5 环境变量和Path环境变量
1.5.1 环境变量
环境变量指的是操作系统中的一些变量,通过修改环境变量,可以对计算机进行一定的配置,主要是配置一些加载的路径
如何查看并修改环境变量
- 右键
我的电脑,选择属性 - 系统界面左侧选择
高级系统设置 - 选择
环境变量
- 右键
可以对环境变量增删改查
当我们在电脑DOS环境下输入一个命令,打开一个文件,或者访问一个文件的时候
- 首先就会在当前目录下搜索,如果找到了就会直接执行或者打开
- 如果没有找到,就会去Path环境变量下,逐个匹配,如果找到,就执行或者打开
- 如果没有找到就会报错
所以我们可以把经常访问的程序或者文件,配置到Path环境变量去,方便使用
2 Python入门及配置
2.1 什么是计算机语言
计算机就是一台用来计算的机器,我们用来操作计算机来帮助我们处理事情的语言就称为
计算机语言计算机语言的简单发展史
根据转换时间的不同,编程语言被分成了两大类
- 编译型语言
- 编译型语言会在代码执行前把代码编译成机器码,然后再被计算机执行
- 源码—-编译器—-> 编译后的机器码
- 特点
- 执行速度快,相当于做好的菜,直接上桌
- 由于在某种硬件结构上编译成的,跨平台性比较差
- 解释型语言
- 编译型语言
简单易学,比很多其他编程语言易上手
- 开放源码,生态环境好,众多高手活跃在社区中
-
2.3.2 Python用途
WEB应用
- 爬虫程序
- 数据分析
- 科学计算,精确度高
- 自动化运维,脚本语言
- 大数据,数据清洗
-
2.4 Python安装及配置
不做记录,就官网下载,逐步安装就行了,安装过程可以参考 廖雪峰的安装教程
2.5 Pycharm专业版破解安装
工欲善其事,必先利其器。Pycharm可以说是开发python最专业,功能最强大的工具了,我当然也得学习如何使用,由于安装专业版是收费的,所以另起一篇写Pycharm破解安装以及常用的配置。 详情看这里 Pycharm专业版破解安装及配置
2.6 VS Code和Python的搭配
Visual Studio Code(简称VS Code)是微软旗下发布的编辑器,功能非常之强大,在这不在赘述,可以使用VS code搭建Python的开发环境。
2.6.1 安装VS Code
官网下载 VS Code 安装包,然后点击,一步一步就安装好了
2.6.2 VS Code中安装插件
打开VS Code,左侧栏有一个Extends栏,输入Python,找到
Python和Python for VSCode两个插件并安装2.6.3 测试是否安装成功
新建一个python程序,编写
print("Hello Python")
点击F5,选择Python运行,查看输出结果是否正确,如果正确说明,环境搭建成功。
3 注释、变量、数据类型和格式化输出
3.1 Python代码规范
Python中严格要求大小写
- Python中每一行就是一条语句,每一条语句以换行符结束
- Python中每一行语句不要过长,符合Python语言的优雅性
- Python中不要随意空格和缩进
-
3.2 注释
所谓注释,就是通过用自己熟悉的语言,在程序中对某些代码进行标注说明,能够大大增加代码的可读性,也方便别人能够理解代码的逻辑。
3.2.1 注释的分类和语法
Python中注释分为:
单行注释和多行注释 单行注释:只能注释一行内容,写法如下
# 注释内容
多行注释:可以注释多行内容,一般用在注释一段代码块的情况下,写法如下
"""第一行注释第二行注释第三行注释"""或者'''第一行注释第二行注释第三行注释'''
3.3 变量
变量就是存储数据的载体,就是当前存储数据的内存地址的一个名字。
3.3.1 定义变量
变量名 = 值
Python中,
=不再是往常等于的意思,而是赋值的意思,上面定义变量的语义值赋值给变量名,其中变量名要满足标识符命名规则。
Python中定义各种名字的统一规范叫做标识符命名规则,主要包括以下几点:由字母、数字、下划线组成
- 不能以数字开头
- 严格区分大小写
- 不能使用内置关键字
False None True and as assert break class continuedef del else except finally for from global 等等
3.3.2 使用变量
```python定义变量
my_name= “程飞龙”使用变量
print(my_name)
定义变量
my_school = “鞍山师范学院”
使用变量
print(my_name+”大学就读于”+my_school)
<a name="3787f6af"></a>### 3.4 基本数据类型<a name="531aadcd"></a>#### 3.4.1 数值在Python中,数值分为三种,整数、浮点数、复数。- 整数- 在Python中所有的整数都是int型(python 3.x)- Python中的整数大小没有限制,可以是无限大的整数- 十进制的数字不能以0开头- 二进制0b开头- 八进制0o开头- 十六进制0x开头- 浮点数- 在Python中所有的浮点数都是float型- 浮点数运算会得到一个不精确的值- 复数- 暂且用不到<a name="615132fe"></a>#### 3.4.2 布尔型Bool值也就是常见的`True`和`False`两个取值。<a name="cc4dd1da"></a>#### 3.4.3 字符串字符串用来表示一段文本信息,是程序中使用最多的数据类型。- Python中使用字符串需要使用引号引起来,单引号、双引号都可以- 相同的引号之间不能嵌套- 单引号和双引号不可以跨行使用,如果想跨行使用,可以使用三重引号- 转义字符\,可以使特殊符号表达本身的含义- \' 表示'- \" 表示''- \t 表示制表符- \n 表示换行符- \\ 表示反斜杠<a name="fa6c7a72"></a>### 3.5 格式化输出<a name="3e3dc362"></a>#### 常见的格式化符号| 格式符号 | 表达含义 || --- | --- || **%s** | 字符串 || **%d** | 有符号的十进制整数 || **%f** | 浮点数 || %c | 字符 || %u | 无符号十进制整数 || %o | 八进制整数 || %x | 十六进制整数(小写ox) || %X | 十六进制整数(大写OX) || %e | 科学计数法(小写'e') || %e | 科学计数法(大写 || %g | %f和%E的简写 |**特殊用法**- f'{}'表达式,高级的格式化输出方式,可读性也更好- %06d,06表示输出位数,不足则用0补全,超过则原样输出- %f默认保留的是小数点后六位,如想要保留所需位数,%.2f,2代表位数代码示例如下```python"""1.准备一部分数据2.格式化输出数据3.演示常用的%s、%d、%f及特殊用法"""name='程飞龙'age=25weight=68.5stu_id=1506stu_id2=1506010606# 我的名字叫程飞龙print('我的名字叫%s'% name)# 我的年龄是25岁print('我的年龄是%d'% age)# 我的学号是1506,%06d,06表示输出位数,不足则用0补全,超过则原样输出print('我的学号是%d'% stu_id)print('我的学号是%06d'% stu_id)print('我的学号是%06d'% stu_id2)# 我的体重是68.5公斤,%f默认保留的是小数点后六位,如想要保留所需位数,%.xf,x代表位数,下面为示例print('我的体重是%f公斤'% weight)print('我的体重是%.1f公斤'% weight)# 我的名字叫程飞龙,今年25岁print('我的名字叫%s,今年%d岁'%(name,age))# f'{}'表达式,高级的格式化输出方式,可读性也更好print(f'我的名字是{name},今年{age}岁')
4 判断语句if和else
4.1 if和else的使用
在各种开发语言中,条件判断语句都要学习这两个,条件成立,执行if下的代码,条件不成立,执行else下的代码。Python的语法格式如下:
if 条件成立:要执行的代码else:要执行的代码
跟C/C++,Java等语言不同的点是,Python中没有使用()来管理判断条件,也没有使用{}来构造代码块,而是使用了缩进的方式来表达代码的层次结构,如果条件成立,执行多条代码,这些代码都要保持相同的缩进。
"""练习使用if和else模拟网吧上网场景,输入年龄,如果成年,输出,已成年,可以上网, 否则输出未成年,不可上网"""age = int(input('请输入您的年龄:'))if age >= 18:print(f'您的年龄是{age},已成年,可以上网')else:print(f'您的年龄是{age},未成年,不可以上网')
4.2 多重判断if、elif和else
所谓多重判断,也就是超过一种判断条件,产生超过两种以上的结果,这种情况下使用elif关键字来进行多重判断。
"""练习多重判断分段函数求值:3x - 5 (x > 1)f(x) = x + 2 (-1 <= x <= 1)5x + 3 (x < -1)"""x = float(input('x='))if x>1:y=3*x-5elif -1 <= x <= 1:y=x+2else:y=5*x+3print(f'f(x)={y:0.2f}')
5 循环结构for和while
5.1 循环结构
循环结构就是程序中某条或某些指令重复执行的结构。循环使得程序更高效的执行。
Python中构造循环结构一般有两种形式,一种是while循环,一种是for…in循环。
5.2 for循环
Python中的for循环结构跟其他语言不同,表达形式为:
for 临时变量 in 序列范围需要循环的代码1需要循环的代码2...
下面用for…in结构实现常见的几个例题
"""for..in循环结构练习1.计算1+2+3+...100的值2.输入一个正整数判断是不是素数3.输入两个正整数,输出最大公约数和最小公倍数"""# 1.计算1+2+3+...100的值sum = 0for i in range(101):sum += iprint(f'1+2+3+4+...+100的和为{sum}')# 2.输入一个正整数判断是不是素数from math import sqrtnum = int(input('请输入一个正整数'))isPrime = Truefor i in range(2,num):if num % i==0:isPrime=Falsebreakif isPrime and num!=1:print(f'{num}是个素数')else:print(f'{num}不是素数')# 3.输入两个正整数,输出最大公约数和最小公倍数
5.3 while循环
while循环一般使用场景是,不确定循环什么时候结束,这时候使用while循环,条件设为bool的True值,然后执行到需要的场景,条件变为False,退出循环。
while 循环条件:条件成立执行的代码1条件成立执行的代码2...
下面的猜数字游戏,使用while循环结构来实现
import randomanswer = random.randint(1, 100)counter = 0while True:counter += 1number = int(input('请输入: '))if number < answer:print('大一点')elif number > answer:print('小一点')else:print('恭喜你猜对了!')break
5.3 break和continue的使用
break和continue都是用来跳出循环的,break是终止循环,跳出当前的循环结构,continue是放弃本次循环,下面的循环接着执行。
6数据结构之字符串
在python中,我们用input函数输入的数据都是字符串类型的,所以字符串是数据类型中最为重要的一类。
6.1 认识字符串
Python中一般使用引号来创建字符串,其实使用三引号也可以创建字符串。
# 1.1单引号创建字符串a='I am waldeincheng'print(a)print(type(a))# 1.2双引号创建字符串b="I am waldeincheng"print(b)print(type(b))# 1.3三引号创建字符串c='''I am waldeincheng'''print(c)print(type(c))d="""I am waldeincheng"""print(d)print(type(d))
三引号跟多行注释的用法差不多,区别为,单引号换行时会有一个反斜杠,输出时还是单行输出,三引号可以直接换行书写,输出会按照书写方式输出。
e='I am ' \'waldeincheng'print(e)f='''I amwaldeincheng'''print(f)# 输入结果为I am waldeinchengI amwaldeincheng
6.2 字符串输入输出
6.3 下标
下标又叫索引,作用是通过下标快速找到对应的数据,下标是从0开始的,变量名[下标值]。
str='abcdef'print(str[0])print(str[1])
6.4 切片
切片是对操作的对象截取一部分的操作。使用语法如下:
序列名[开始下标:结束下标:步长]
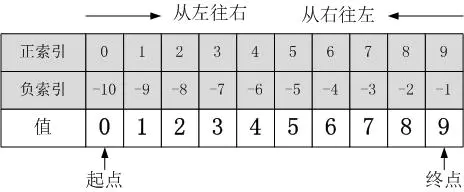
注:图中正索引,副索引也就是步长的的正负。
- 开始下标和结束下标选取的范围为左闭右开区间,也就是结束下标所在的那个元素不选取,正负都行
- 步长为选取间隔,正负都行,默认为1
- 开始下标为空,表示从开头开始选取,结束下标为空,表示选取到最后,步长为空,表示默认为1
- 步长为负数,表示从后往前选取
开始下标为-1,表示最后一个元素,依次往前为-2,-3等等
'''字符串进阶知识点练习1.切片的使用:`切片`是对操作的对象截取一部分的操作。使用语法如下:序列名[开始下标:结束下标:步长]'''str='0123456789'print(str[2:5:1]) # 输出234,从2到5,左开右闭,间隔为1print(str[2:5:2]) # 输出24,从2到5,左开右闭,间隔为2print(str[2:5]) # 输出234,从2到5,左开右闭,间隔默认为1print(str[:5:1]) # 输出01234,开始下标为空,默认从头开始print(str[2::1]) # 输出23456789,结束下标为空,默认到尾print(str[2:5:-1]) # 输出为空,从2到5为从左到右方向,步长为负,方向为从右到左,方向冲突print(str[-2:-5:1]) # 输出为空,从-2到-5为从右到左方向,步长为正,方向为从左到右,方向冲突print(str[-2:-5:-1]) # 输出876,从-2到-5为从右到左方向,步长为负,方向为从右到左
6.5 字符串常用方法
字符串常用方法分为查找、修改和判断三大类,其中修改功能最为常用。
6.5.1 查找
常用方法有三个,语法结构为:
字符串序列.find(子串,开始下标位置,结束下标位置)字符串序列.index(子串,开始下标位置,结束下标位置)字符串序列.count(子串,开始下标位置,结束下标位置)
语法逻辑是在开始下标和结束下标之间,查找子串
- find()是查找是否存在子串,存在返回子串开始位置的下标,不存在返回-1
- index()也是查找是否存在子串,存在返回子串开始位置的下标,不存在会报错
count()是查找子串出现的次数,返回出现的次数,不存在返回为0
6.5.2 修改
replace():替换
字符串序列.replace(旧子串,新子串,替换次数)
替换次数为空,默认就是替换所有出现的旧子串
replace()函数有返回值,会返回一个替换后的字符串,原字符串没有改变
str='I am a good boy'new_str=str.replace('good','bad')print(new_str) # I am a bad boy
split():分割
字符串序列.split(分割符,替换次数)
以分隔符为界限分割成一个列表,分隔符会丢失
分隔符为空,默认按空格分割
str2='I am a good boy and I like Python'print(str2.split()) # ['I', 'am', 'a', 'good', 'boy', 'and', 'I', 'like', 'Python']print(str2.split('I')) # ['', ' am a good boy and ', ' like Python']print(str2.split('I',1)) # ['', ' am a good boy and I like Python']
join():连接
字符或子串.join(多字符串组成的序列)list=['python','books','movie','music']newlist=' and '.join(list)print(newlist) # python and books and movie and music
其他常用方法如下:
capitalize():将字符串的第一个字符转换为大写
- title():将字符串的每一个单词的首字母大写
- lower():将字符串中大写转小写
- upper():将字符串中小写转大写
- lstrip():删除字符串左侧空白字符
- rstrip():删除字符串右侧空白字符
- strip():删除字符串两个空白字符
6.5.3 判断
判断即是判断真假,返回值为布尔型数据类型:True或False。
startswith():判断是否以某个子串开始,是返回为True,不是返回为False,也可以以某个区间为界限,判断在特定区间内是否以某个子串开始
endswith():判断是否以某个子串结束,是返回为True,不是返回为False,也可以以某个区间为界限,判断在特定区间内是否以某个子串结束 ```python 字符串序列.endswith(子串,开始下标位置,结束下标位置)字符串序列.startswith(子串,开始下标位置,结束下标位置)
1.startswith()
str3=’Life is short,I love Python’ print(str3.startswith(‘Life’)) print(str3.startswith(‘Lifs’))
2.endswith()
print(str3.endswith(‘Python’)) print(str3.endswith(‘Pythos’))
其他常用方法:- isalpha():判断是否都是字母组成- isdigit():判断是否都是数字组成- isalnum():判断是否是字母或者数字或者两者结合组成的- isspace():判断是否空白<a name="60f9f1ad"></a>## 7 数据结构之列表<a name="926b24ce"></a>### 7.1 认识列表`列表`是一种结构化、非标量类型、一系列值的有序序列。每个值都可以使用索引进行标识,访问。```python变量名[数据1,数据2,数据3,......]
7.2 列表的常用操作
7.2.1 查找
列表的查找常用到三个方法,分别为:
index():在特定的范围内返回指定数据所在的下标,不存在会报错
列表名.index(元素,开始位置,结束位置)
count():指定数据在当前列表中出现的次数,不存在返回为0
列表名.count(元素)
len():返回列表长度,即列表中元素的个数,通用方法,元组、集合、字典可用
len(列表名)
7.2.2 判断
列表中判断使用in和not in,in:判断指定数据在某个列表序列,not in:判定指定数据不在某个列表序列,返回布尔值。
list=['Alan','Bob','Vicky','Lily']print('Lily' in list) # Trueprint('Bingo' not in list) # False
7.2.3 添加
列表中添加指定数据有三个常用方法,分别如下:
append():列表尾部追加数据
列表名.append(数据)
extend():列表尾部追加数据,如果数据是一个序列,则将这个序列的数据逐一添加到列表
列表名.extend(数据)
insert():指定位置新增数据
列表名.insert(位置下标,数据)
代码示例:
'''append()追加数据,是整体追加到尾部,extend()是逐一追加到尾部'''name_list = ['Alan','Bob','Lily']name_list.append('Waldein')print(name_list) # ['Alan', 'Bob', 'Lily', 'Waldein']name_list.append(['ming','hong'])print(name_list) # ['Alan', 'Bob', 'Lily', 'Waldein', ['ming', 'hong']]name_list.extend('Cheng')print(name_list) # ['Alan', 'Bob', 'Lily', 'Waldein', ['ming', 'hong'], 'C', 'h', 'e', 'n', 'g']name_list.extend(['Waldein','Cheng'])print(name_list) # ['Alan', 'Bob', 'Lily', 'Waldein', ['ming', 'hong'], 'C', 'h', 'e', 'n', 'g', 'Waldein', 'Cheng']
7.2.4 删除
列表中添加删除数据有四个常用方法,分别如下:
del:删除列表,也可以删除指定下标的数据
del 列表名del 列表名[]
pop():删除指定下标的数据,默认删除列表最后一个数据,返回删除下标所在的数据
列表名.pop(下标)
remove:删除指定数据
列表名.remove(指定数据)
clear():清空列表,返回一个空列表
列表名.clear()
7.2.5 修改
列表中修改数据有三个常用方法,分别如下:
修改指定下标数据:由于列表是可变的数据结构,直接重新赋值即可
reverse():逆转列表
列表名.reverse()
sort():给列表排序,默认升序
列表名.sort(reverse=True) # 降序列表名.sort(reverse=False) # 升序
7.3 列表的遍历
while循环
name_list=['Alan','Bob','Vicky','Lily']i=0while i<len(name_list):print(name_list[i])i += 1
for循环
name_list=['Alan','Bob','Vicky','Lily']for i in name_list:print(i)
8 数据结构之元组、集合和字典
8.1 认识元组
一个元组可以存储多个数据,但是元组内的数据不能修改。元组定义使用小括号:
元组名=(数据1,数据2,数据...)
特别注意的是当元组里只有一个数据时,需要后面加个逗号,否则数据类型会体现为那仅有数据的数据类型。
t=(1,2,3,4)print(type(t))t1=(1,)print(type(t1)) # 数据类型为tuple元组t2=(1)print(type(t2)) # 数据类型为int整型
8.2 元组的常用操作
元组数据不能修改,所以没有增删改,只有查找,常用方法和列表类似。
8.2.1 查找
index():在特定的范围内返回指定数据所在的下标,不存在会报错
元组名.index(数据,开始位置,结束位置)
count():指定数据在当前列表中出现的次数,不存在返回为0
元组名.count(数据)
len():返回列表长度,即列表中数据的个数,通用方法,元组、集合、字典可用
len(元组名)
虽然元组里的数据不能修改,但如果数据是列表时,列表里的数据可以修改
8.3 认识集合
集合是一个不能重复的无序序列,创建集合使用{}或set(),但是创建空集合只能用set()。
s={1,2,34,5,6,7,45}print(s)print(type(s)) # 输出sets1=set((1,2,4,65,7,55))print(s1)print(type(s1)) # 输出set
set()函数是把字符串,列表,元组等数据结构转换为集合,里面只能有一个参数。
8.4 集合的常用操作
8.4.1 增加
add():集合中添加一个数据,因为集合有去重功能,当向集合内追加的数据是已有数据的话,则不进行任何操作。
update():集合中添加一个序列,序列中的数据,会逐一添加到原集合中。
s={10,20,30,50}s.add(40)print(s) # {40, 10, 50, 20, 30}s.update((60,79))print(s) # {40, 10, 79, 50, 20, 60, 30}
8.4.2 删除
remove():删除指定数据,如果数据不存在,报错。
discard():删除指定数据,如果数据不存在,不报错。
pop():随机删除数据,返回所删除的数据。
8.4.3 查找
集合中的查找,使用两个关键字in和not in,in判断在集合中,not in判断不在集合中,返回布尔值。
s={10,20,30,50}print(10 in s) # Trueprint(60 not in s) # False
8.5 认识字典
字典的数据是以键值对形式出现,字典数据和数据顺序没有关系,后面数据如何变化,只需要按照对应的键的名字查找数据即可。
字典名={key1:value1,key2:value2...}
8.6 字典的常用操作
8.6.1 增加/修改
字典里增加数据的方式,就是直接字典名[key]=赋值,直接赋值,如果不存在key,则新增成功,如果存在key,则变成了修改字典。
dict1={'name':'waldeincheng','gender':'male','age':25}# 新增数据dict1['id']=1506print(dict1) # {'name': 'waldeincheng', 'gender': 'male', 'age': 25, 'id': 1506}dict1['name']='flovecheng'print(dict1) # name本身存在,输出为{'name': 'flovecheng', 'gender': 'male', 'age': 25, 'id': 1506}
8.6.2 删除
字典里的删除有del/del()和clear()方法,前者删除字典或者删除某个键值对,后者清空字典。
del(dict1)print(dict1) # NameError: name 'dict1' is not defineddel dict1["id"]print(dict1) # {'name': 'waldeincheng', 'gender': 'male', 'age': 25}dict1.clear()print(dict1) # {}
8.6.3 查找
字典里可以使用key直接查找,不过不存在的话会报错,一般不推荐使用。
dict1={'name':'waldeincheng','gender':'male','age':25,'id':1506}# 找到key为id的数据print(dict1['id'])
get(key,第二参考值):通过get方法查找数据,如果存在,输出value值,如果不存在,输出第二参考值,第二参考值为空的话,输出None。
dict1={'name':'waldeincheng','gender':'male','age':25,'id':1506}print(dict1.get('id',110)) # 输出1506print(dict1.get('math',110)) # 输出110
keys():查找所有的key值,返回可迭代的对象。
values():查找所有的value值,返回可迭代的对象。
items():查找字典所有的键值对,返回可迭代的对象(元组)。
dict1={'name':'waldeincheng','gender':'male','age':25,'id':1506}print(dict1.keys())print(dict1.values())print(dict1.items())'''输出为:dict_keys(['name', 'gender', 'age', 'id'])dict_values(['waldeincheng', 'male', 25, 1506])dict_items([('name', 'waldeincheng'), ('gender', 'male'), ('age', 25), ('id', 1506)])'''
8.7 字典的遍历
8.7.1 遍历key
dict1={'name':'waldeincheng','gender':'male','age':25,'id':1506}# 遍历keyfor key in dict1:print(key)
8.7.2 遍历value
dict1={'name':'waldeincheng','gender':'male','age':25,'id':1506}# 遍历valuefor value in dict1:print(value)
8.7.3 遍历键值对
dict1={'name':'waldeincheng','gender':'male','age':25,'id':1506}# 遍历键值对for item in dict1.items():print(item)
8.7.4 遍历键值对之拆包
dict1={'name':'waldeincheng','gender':'male','age':25,'id':1506}# 遍历之键值对的拆包for key,value in dict1.items():print(key)print(value)
9 公共操作及推导式
所谓公共操作就是之前讲到的字符串、列表、元组和字典大部分都通用的一些操作。
9.1 运算符
| 运算符 | 描述 | 支持的容器类型 |
|---|---|---|
| + | 合并 | 字符串、列表、元组 |
| * | 复制 | 字符串、列表、元组 |
| in | 元素是否存在 | 字符串、列表、元组、字典 |
| not in | 元素是否不存在 | 字符串、列表、元组、字典 |
代码示例:
str1='abc'str2='def'list1=[1,2]list2=[10,20]tuple1=(1,2)tuple2=(10,20)dict1={'name':'waldeincheng'}dict2={'age':25}# +号:合并print(str1+str2)print(list1+list2)print(tuple1+tuple2)# print(dict1+dict2) # TypeError: unsupported operand type(s) for +: 'dict' and 'dict'# *号:复制print(str1*5)print(list1*5)print(tuple1*5)# print(dict1*5) # TypeError: unsupported operand type(s) for +: 'dict' and 'dict'# in和not in: 判断数据是否存在print('a' in str1)print('d' not in str1)print('1' in list1)print('3' in list1)print('1' in tuple1)print('3' not in tuple1)print('name' in dict1)print('gender' not in dict1)
9.2 公共方法
| 函数方法 | 描述 |
|---|---|
| len() | 统计容器中元素个数 |
| del/del() | 删除 |
| max() | 返回容器中的最大值 |
| min() | 返回容器中的最小值 |
| range(start,end,step) | for循环使用,生成从start到end的数字,step为步长(左闭右开区间,end值取不到) |
| enumerate() | 将一个可遍历的数据对象组合成一个索引序列,同时列出数据和数据下标,一般用在for循环中 |
主要代码实现一下enumerate()的使用:
enumerate(可遍历对象,start=0)
start参数用来设置遍历数据的下标的起始值,默认为0。
# enumerate 返回的是元组,元组的第一个数据是原迭代对象的数据对应下标,元组的第二个数据是原迭代对象的数据list3=['a','b','c','d','e']for i in enumerate(list3,0):print(i)# 输出结果(0, 'a')(1, 'b')(2, 'c')(3, 'd')(4, 'e')
9.3 容器类型转换
容器之间的相互转换,转换成集合可以去重。
list1=[10,20,30,40,50]s1={100,200,300,400}t1=('a','b','c','d','e',)# tuple():转换成元组print(tuple(list1))print(tuple(s1))# list():转换成列表print(list(s1))print(list(t1))# set():转换成集合print(set(list1))print(set(t1))
9.4 推导式
推导式comprehensions(又称解析式),是Python的一种独有特性。推导式是可以从一个数据序列构建另一个新的数据序列的结构体,作用就是简化书写的代码。
Python中共有三种数据结构支持推导式,分别是:
- 列表(list)推导式
- 字典(dict)推导式
- 集合(set)推导式
9.4.1 列表推导式
用列表推导式去创建一个有规律的列表或者控制一个有规律的列表。
基本格式为:
示例需求:创建一个0-10的列表 ```python[表达式 for 变量 in 列表] 或者 [表达式 for 变量 in 列表 if 条件]
先不用推导式实现,使用while和for循环实现,然后对比一下
while实现
list1=[] i=0 while i<10: list1.append(i) i+=1 print(list1)
使用for实现
list2=[] for i in range(10): list2.append(i) print(list2)
使用列表推导式实现
list3=[i for i in range(10)] print(list3)
示例需求:创建一个0-10的**偶数**列表,使用带if的列表推导式```python# 使用不带if的推导式也可以完成,步长为2list4=[i for i in range(0,10,2)]print(list4)# 使用带if的推导式,除以2余数为0的即为偶数list5=[i for i in range(10) if i%2==0]print(list5)
9.4.2 字典推导式
字典推导式的作用是合并两个列表为字典或者提取字典中目标数据。
# 2.1 合并两个列表list6=['name','gender','age']list7=['waldeincheng','male',25]dict1={list6[i]:list7[i] for i in range(len(list6))}print(dict1)
注意:当两个列表长度一样时:len()函数里的列表取哪一个都行,但是当列表长度不一样时,需要取列表长度短的那个,不然会越界报错。
实际应用中有时候需要查看特定条件下的数据,这时候可以使用字典推导式实现,比如:
示例需求:输出成绩大于85的考试科目和成绩
# 2.2 提取目标数据,输出成绩大于85的考试科目和成绩dict2={'语文':78,'数学':90,'英语':88,'物理':91}dict3={key:value for key,value in dict2.items() if value>85}print(dict3)
9.4.3 集合推导式
使用场景较少,了解即可
示例需求:创建一个集合,数据为下方列表的2次方
list8=[1,1,2,4]set1={i**2 for i in list8}print(set1) # {16, 1, 4}
10 函数概念及使用
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
函数能提高应用的模块性和代码的重复利用率。
定义函数
可以定义一个能够完成功能的函数,大致简单规则如下:
- 函数代码块以def关键字开头,后接函数标识符名和圆括号()。
- 任何传参和自变量必须放在圆括号()里,圆括号之间可以用于定义参数。
- 函数第一行一般用于写注释—函数功能。
- 函数以冒号开始,需要缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
函数定义的表达式结构为:
def 函数名(参数1,参数2):功能模块1功能模块2
使用函数
函数的定义就是完成重复的代码,实际使用中才是关键,使用方式很简单,就是直接使用函数名,里面传入需要的参数,就可以完成调用。
函数的参数
Python函数中的参数可以有多种表现方式,不需要其他需要语言中写函数重载,可以有默认值,也可以使用可变参数(在参数名前面的表示args是一个可变参数),传递参数时*可以不按照设定的顺序的进行传递。
# 3.函数的参数可以有默认值,传参的时候,传入值就代替掉默认值,否则就使用默认值# 4. 以摇骰子为例def roll_dice(n=2):total=0for i in range(n):total += randint(1,6)return totalprint(roll_dice()) # 使用默认参数print(roll_dice(2)) # 传入新的参数
经典练习题
学习编程语言的过程中一般都需要练习几个经典题目,现使用Python函数实现一下:
1.水仙花数,找出所有水仙花数
for num in range(100,1000):low=num%10mid=num//10%10high=num//100if num==low**3+mid**3+high**3:print(num)
2.正整数的反转
num=int(input('num='))reversed_num=0while num>0:reversed_num=reversed_num*10+num%10num//=10print(reversed_num)
3.百钱百鸡问题
# 公鸡5元一只,母鸡3元一只,小鸡1元三只,用100块钱买一百只鸡,问公鸡、母鸡、小鸡各有多少只?for x in range(0,20):for y in range(0,33):z=100-x-yif 5*x+3*y+z/3==100:print('公鸡:%d只,母鸡:%d只,小鸡:%d只'%(x,y,z))
2.1面向对象编程
什么是面向对象?
面向对象就是把要处理的事务分解成多个对象,每个对象都有自己独特的属性和功能。
概念化的说法就是“把一组数据结构和处理它们的方法组成对象(object),把相同行为的对象归纳为类(class),通过类的封装(encapsulation)隐藏内部细节,通过继承(inheritance)实现类的特化(specialization)和泛化(generalization),通过多态(polymorphism)实现基于对象类型的动态分派。”
类和对象
面向对象中最重要的两个关键字就是类和对象,类是对一类具有某些特定属性的事务的抽象,而对象就是类的实例,用来操作类完成需求。
类的定义
在Python中使用关键字class定义类,然后在类中使用前面学习的函数来定义方法,这样就可以把对象的动态特征描述出来,来等待调用。
# 1.定义一个类class Student(object):def __init__(self, name, age):self.name = nameself.age = agedef study(self, course_name):print(f'{self.name}正在学习{course_name}')def watch_movie(self):if self.age < 18:print(f'{self.name}只能看熊出没')else:print(f'{self.name}可以看爱情电影了')
创建和使用对象
# 2. 创建对象并使用类# 2.1 创建对象,并传入姓名和年龄s1 = Student('程飞龙', 26)# 2.2 调用学习方法,并传入要学习的课程s1.study('Python程序设计')# 2.3 调用看电影方法,判断年龄是否符合要求s1.watch_movie()
注:在Python中,属性和方法的访问权限只有两种,也就是公开的和私有的,如果希望属性是私有的,在给属性命名时可以用两个下划线作为开头。
类里的self
Python类里有个self关键字,表示当前类的对象地址,可以用来初始化数据,传参。
class Demo(object):def test(self):print(self)# 3.1验证selfD1 = Demo()print(D1) # <__main__.Demo object at 0x000001D2F771DAF0>D1.test() # <__main__.Demo object at 0x000001D2F771DAF0>
三个特殊函数
init()
Python有几个特殊函数,__init()__初始化函数,创建对象时自动调用,一般用来初始化数据。
class Student(object):def __init__(self, name, age, gender):self.name = nameself.age = ageself.gender = genderdef info(self):print([self.name,self.age,self.gender])s1=Student('程飞龙',26,'男')s1.info()
str()
当使用print打印对象的时候,会打印出对象的内存地址,如果类中定义了__str()__函数,会打印出此函数中return的数据。
class Student2(object):def __init__(self, name, age, gender):self.name = nameself.age = ageself.gender = genderdef __str__(self):return self.names2 = Student2('程飞龙', 26, '男')print(s2) # 程飞龙
del()
当我们删除对象时,会调用del(),并打印__del()__中的内容。
# 3.del()class Student3(object):def __del__(self):print("此对象已被删除")s3=Student3()del s3 # 此对象已被删除
静态方法和类方法
一般我们创建的函数(方法)都是需要创建对象后才能使用的,有时有些功能需要没有对象就需要完成,比如计算三角形的面积,在计算之前需要判断是否构成三角形,如果构成,才创建对象,调用计算面积的方法。这时候可以使用静态方法来实现判断是否构成三角形。
from math import sqrt# 1.静态方法的使用class Triangle(object):def __init__(self, a, b, c):self._a = aself._b = bself._c = c@staticmethoddef is_valid(a, b, c):return a + b > c and b + c > a and a + c > bdef area(self):half = (self._a + self._b + self._c) / 2return sqrt(half * (half - self._a) * (half - self._b) * (half - self._c))a, b, c = 3, 4, 5if Triangle.is_valid(a, b, c):t = Triangle(a, b, c)print(t.area())else:print('无法构成三角形')# 输出 6.0
Python还可以在类中定义类方法,类方法的第一个参数约定名为cls,它代表的是当前类相关的信息的对象(类本身也是一个对象,有的地方也称之为类的元数据对象),通过这个参数我们可以获取和类相关的信息并且可以创建出类的对象。
继承和多态
让一个类从其他类那里将属性和方法直接继承下来,减少重复代码的编写,提供继承信息的类称之为父类,也叫超类或基类,得到继承信息的类称之为子类,也叫派生类或衍生类。子类除了继承父类提供的属性和方法,还可以定义自己特有的属性和方法。这个过程就是继承。
单继承和多继承
单继承是指,子类只继承一个父类,多继承是指子类继承多个父类,调用父类的同名方法时,会默认调用第一个父类的属性和方法。
# 单继承class A(object):# 父类Adef __init__(self):self.num = 1def info_print(self):print(self.num)class B(A):# 子类Bpass# 验证继承result = B()result.info_print()
# 父类Aclass A(object):def __init__(self):self.num = 1def info_print(self):print(self.num)# 父类Bclass B(object):def __init__(self):self.num = 2def info_print(self):print(self.num)# 子类C继承父类A和Bclass C(A, B):pass# 创建子类对象,验证是否继承两个父类的方法,多继承中,同名方法,默认调用第一个父类的方法和属性result = C()result.info_print() # 1
多重继承
多重继承是指,B继承了A,C又继承了B,以此类推,产生了子孙类,例子不再记录。
super()的使用
**super()**函数是用于多继承中,调用父类方法的函数。
class A(object):def __init__(self):self.num = 1def info_print(self):print(self.num)class B(A):def __init__(self):self.num = 2def info_print(self):super().__init__()print(self.num)result = B()result.info_print() # 1
子类在继承了父类的方法后,可以对父类已有的方法给出新的实现版本,这个动作称之为方法重写(override)。通过方法重写我们可以让父类的同一个行为在子类中拥有不同的实现版本,当我们调用这个经过子类重写的方法时,不同的子类对象会表现出不同的行为,这个就是多态。
///缺个例子,以及Python中抽象类(不能创建对象的类)的使用,通过abc模块的ABCMeta元类和abstractmethod包装器来达到抽象类的效果,如果一个类中存在抽象方法那么这个类就不能够实例化(创建对象)。
mro函数和super的关系

若有收获,就点个赞吧
0 人点赞
