scrapy 框架中间件使用
导论
中间件:
作用:批量拦截请求和响应
Scrapy 中间件的分类:
- 爬虫中间件
- 下载中间件(推荐)
```pythonDefine here the models for your spider middleware
#See documentation in:
https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
爬虫中间件
class SecondSpiderMiddleware:
# Not all methods need to be defined. If a method is not defined,# scrapy acts as if the spider middleware does not modify the# passed objects.@classmethoddef from_crawler(cls, crawler):# This method is used by Scrapy to create your spiders.s = cls()crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)return sdef process_spider_input(self, response, spider):# Called for each response that goes through the spider# middleware and into the spider.# Should return None or raise an exception.return Nonedef process_spider_output(self, response, result, spider):# Called with the results returned from the Spider, after# it has processed the response.# Must return an iterable of Request, or item objects.for i in result:yield idef process_spider_exception(self, response, exception, spider):# Called when a spider or process_spider_input() method# (from other spider middleware) raises an exception.# Should return either None or an iterable of Request or item objects.passdef process_start_requests(self, start_requests, spider):# Called with the start requests of the spider, and works# similarly to the process_spider_output() method, except# that it doesn’t have a response associated.# Must return only requests (not items).for r in start_requests:yield rdef spider_opened(self, spider):spider.logger.info('Spider opened: %s' % spider.name)
下载中间件
class SecondDownloaderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# 返回一个下载中间件到实例
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# 拦截请求的中间件方法
# (1) request 拦截的请求
# (2) spider spider实例化对象
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
def process_response(self, request, response, spider):
# 拦截相应的中间件方法
# (1) response 拦截的响应数据
# (2) request 拦截的请求
# (3) spider spider实例化对象
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# 拦截异常请求的中间件方法
# (1) request 拦截的响应数据
# (2) exception 拦截的请求异常
# (3) spider spider实例化对象
# 作用 不中断程序,将异常的请求进行修改,将其变成正常请求,然后对其进行重新发送
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
# 入职输出的一个中间件方法
spider.logger.info('Spider opened: %s' % spider.name)
- 拦截请求
- 篡改请求的url
- 伪装请求头信息
- ua
- cookie
- 设置请求代理(重点)
- 拦截响应
- 篡改响应信息
<a name="432cbbab"></a>
## **概述**
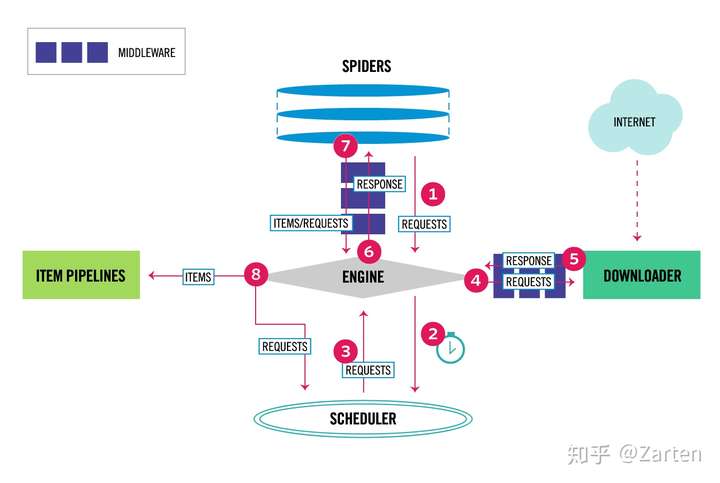
整体的详细流程如下,来源scrapy的官网,地址点[这里](https://link.zhihu.com/?target=https%3A//github.com/scrapy/scrapy/blob/master/docs/topics/architecture.rst)

<a name="7a4d1741"></a>
## **下载器中间件(Downloader Middleware)**
如上图标号4、5处所示,下载器中间件用于处理scrapy的request和response的钩子框架,可以全局的修改一些参数,如代理ip,header等
使用下载器中间件时必须激活这个中间件,方法是在settings.py文件中设置DOWNLOADER_MIDDLEWARES这个字典,格式类似如下:
```python3
DOWNLOADERMIDDLEWARES = {
'myproject.middlewares.Custom_A_DownloaderMiddleware': 543,
'myproject.middlewares.Custom_B_DownloaderMiddleware': 643,
'myproject.middlewares.Custom_B_DownloaderMiddleware': None,
}
数字越小,越靠近引擎,数字越大越靠近下载器,所以数字越小的,processrequest()优先处理;数字越大的,process_response()优先处理;若需要关闭某个中间件直接设为None即可
自定义下载器中间件
有时我们需要编写自己的一些下载器中间件,如使用代理,更换user-agent等,对于请求的中间件实现 process_request(request, spider);对于处理回复中间件实现process_response(request, response, spider);以及异常处理实现 process_exception(request, exception, spider)
**process_request**(request, spider)
每当scrapy进行一个request请求时,这个方法被调用。通常它可以返回1.None 2.Response对象 3.Request对象 4.抛出IgnoreRequest对象
通常返回None较常见,它会继续执行爬虫下去。其他返回情况参考这里
例如下面2个例子是更换user-agent和代理ip的下载中间件
user-agent中间件
from faker import Faker
class UserAgent_Middleware():
def process_request(self, request, spider):
f = Faker()
agent = f.firefox()
request.headers['User-Agent'] = agent
代理ip中间件
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
# 'Connection': 'close'
}
class Proxy_Middleware():
def __init__(self):
self.s = requests.session()
def process_request(self, request, spider):
try:
xdaili_url = spider.settings.get('XDAILI_URL')
r = self.s.get(xdaili_url, headers= headers)
proxy_ip_port = r.text
request.meta['proxy'] = 'http://' + proxy_ip_port
except requests.exceptions.RequestException:
print('***get xdaili fail!')
spider.logger.error('***get xdaili fail!')
def process_response(self, request, response, spider):
if response.status != 200:
try:
xdaili_url = spider.settings.get('XDAILI_URL')
r = self.s.get(xdaili_url, headers= headers)
proxy_ip_port = r.text
request.meta['proxy'] = 'http://' + proxy_ip_port
except requests.exceptions.RequestException:
print('***get xdaili fail!')
spider.logger.error('***get xdaili fail!')
return request
return response
def process_exception(self, request, exception, spider):
try:
xdaili_url = spider.settings.get('XDAILI_URL')
r = self.s.get(xdaili_url, headers= headers)
proxy_ip_port = r.text
request.meta['proxy'] = 'http://' + proxy_ip_port
except requests.exceptions.RequestException:
print('***get xdaili fail!')
spider.logger.error('***get xdaili fail!')
return request
遇到验证码的处理方法
同样有时我们会遇到输入验证码的页面,除了自动识别验证码之外,还可以重新请求(前提是使用了代理ip),只需在spider中禁止过滤
def parse(self, response):
result = response.text
if re.search(r'make sure you\'re not a robot', result):
self.logger.error('check时ip被限制! asin为: {0}'.format(origin_asin))
print('check时ip被限制! asin为: {0}'.format(origin_asin))
response.request.meta['dont_filter'] = True
return response.request
重试中间件
有时使用代理会被远程拒绝或超时等错误,这时我们需要换代理ip重试,重写scrapy.downloadermiddlewares.retry.RetryMiddleware
from scrapy.downloadermiddlewares.retry import RetryMiddleware
from scrapy.utils.response import response_status_message
class My_RetryMiddleware(RetryMiddleware):
def process_response(self, request, response, spider):
if request.meta.get('dont_retry', False):
return response
if response.status in self.retry_http_codes:
reason = response_status_message(response.status)
try:
xdaili_url = spider.settings.get('XDAILI_URL')
r = requests.get(xdaili_url)
proxy_ip_port = r.text
request.meta['proxy'] = 'https://' + proxy_ip_port
except requests.exceptions.RequestException:
print('获取讯代理ip失败!')
spider.logger.error('获取讯代理ip失败!')
return self._retry(request, reason, spider) or response
return response
def process_exception(self, request, exception, spider):
if isinstance(exception, self.EXCEPTIONS_TO_RETRY) and not request.meta.get('dont_retry', False):
try:
xdaili_url = spider.settings.get('XDAILI_URL')
r = requests.get(xdaili_url)
proxy_ip_port = r.text
request.meta['proxy'] = 'https://' + proxy_ip_port
except requests.exceptions.RequestException:
print('获取讯代理ip失败!')
spider.logger.error('获取讯代理ip失败!')
return self._retry(request, exception, spider)
scrapy中对接selenium
from scrapy.http import HtmlResponse
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from gp.configs import *
class ChromeDownloaderMiddleware(object):
def __init__(self):
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 设置无界面
if CHROME_PATH:
options.binary_location = CHROME_PATH
if CHROME_DRIVER_PATH:
self.driver = webdriver.Chrome(chrome_options=options, executable_path=CHROME_DRIVER_PATH) # 初始化Chrome驱动
else:
self.driver = webdriver.Chrome(chrome_options=options) # 初始化Chrome驱动
def __del__(self):
self.driver.close()
def process_request(self, request, spider):
try:
print('Chrome driver begin...')
self.driver.get(request.url) # 获取网页链接内容
return HtmlResponse(url=request.url, body=self.driver.page_source, request=request, encoding='utf-8',
status=200) # 返回HTML数据
except TimeoutException:
return HtmlResponse(url=request.url, request=request, encoding='utf-8', status=500)
finally:
print('Chrome driver end...')
**process_response**(request, response, spider)
当请求发出去返回时这个方法会被调用,它会返回 1.Response对象 2.Request对象 3.抛出IgnoreRequest对象
1.若返回Response对象,它会被下个中间件中的process_response()处理
2.若返回Request对象,中间链停止,然后返回的Request会被重新调度下载
3.抛出IgnoreRequest,回调函数 Request.errback将会被调用处理,若没处理,将会忽略
**process_exception**(request, exception, spider)
当下载处理模块或process_request()抛出一个异常(包括IgnoreRequest异常)时,该方法被调用
通常返回None,它会一直处理异常
**from_crawler**(cls, crawler)
这个类方法通常是访问settings和signals的入口函数
@classmethod
def from_crawler(cls, crawler):
return cls(
mysql_host = crawler.settings.get('MYSQL_HOST'),
mysql_db = crawler.settings.get('MYSQL_DB'),
mysql_user = crawler.settings.get('MYSQL_USER'),
mysql_pw = crawler.settings.get('MYSQL_PW')
)
scrapy自带下载器中间件
以下中间件是scrapy默认的下载器中间件
{
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100,
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300,
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350,
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 400,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 500,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560,
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590,
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600,
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,
'scrapy.downloadermiddlewares.stats.DownloaderStats': 850,
'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900,
}
scrapy自带中间件请参考这里
Spider中间件(Spider Middleware)
如文章第一张图所示,spider中间件用于处理response及spider生成的item和Request
注意:从上图看到第1步是没经过spider Middleware的
启动spider中间件必须先开启settings中的设置
SPIDER_MIDDLEWARES = {
'myproject.middlewares.CustomSpiderMiddleware': 543,
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': None,
}
数字越小越靠近引擎,process_spider_input()优先处理,数字越大越靠近spider,process_spider_output()优先处理,关闭用None
编写自定义spider中间件
**process_spider_input**(response, spider)
当response通过spider中间件时,这个方法被调用,返回None
**process_spider_output**(response, result, spider)
当spider处理response后返回result时,这个方法被调用,必须返回Request或Item对象的可迭代对象,一般返回result
**process_spider_exception**(response, exception, spider)
当spider中间件抛出异常时,这个方法被调用,返回None或可迭代对象的Request、dict、Item

若有收获,就点个赞吧
0 人点赞
