author: UpDown published: True created: 2022年5月10日15点20分 tags: Done version: Outer
参考:https://blog.updown.world/articles/python/pythonbook2/01-%E4%B8%89%E5%99%A8%E4%B8%80%E9%97%AD/index.html 参考:https://updownxh.notion.site/python-5afba0d07da74027a6b07cfb108050c1
迭代器
迭代
我们已经知道可以对list、tuple、str等类型的数据使用for…in…的循环语法从其中依次拿到数据进行使用,我们把这样的过程称为遍历,也叫迭代
可迭代对象
只要是可以通过for…in…的形式进行遍历的,那么这个数据类型就是可以迭代的
下面的是可以迭代的数据类型
- 列表
- 元组
- 字典
- 字符串
不可以迭代的数据类型
print(isinstance([], Iterable)) # True
print(isinstance({}, Iterable)) # True
print(isinstance(‘abc’, Iterable)) # True
print(isinstance(100, Iterable)) # False
<a name="k0gwm"></a>#### 可迭代对象的本质可迭代对象的本质就是可以向我们提供一个这样的中间“人”,即迭代器帮助我们对其进行迭代遍历使用。<br />list、tuple等都是可迭代对象,我们可以通过iter()函数获取这些可迭代对象的迭代器。然后我们可以对获取到的迭代器不断使用next()函数来获取下一条数据。<a name="R3Gpt"></a>#### 获取可迭代对象的迭代器```pythonfrom collections.abc import Iteratornums = [11, 22, 33, 44]print(type(nums))# 获取列表的迭代器nums_iter = iter(nums)# 查看类型print(type(nums_iter))# 判断是不是迭代器print("nums", isinstance(nums, Iterator))print("nums_iter", isinstance(nums_iter, Iterator))"""<class 'list'><class 'list_iterator'>nums Falsenums_iter True"""
获取迭代器的数据
nums = [11, 22, 33, 44]
# 获取列表的迭代器
nums_iter = iter(nums)
num1 = next(nums_iter)
print(num1)
num2 = next(nums_iter)
print(num2)
num3 = next(nums_iter)
print(num3)
num4 = next(nums_iter)
print(num4)
"""
11
22
33
44
"""
StopIteration异常
当调用的.next()多于迭代个数时,报错告知迭代结束的标志
iter
iter()方法必须是对”可迭代“对象 才能 提取到 ”迭代器“对象,但是怎样保证自定义的对象是”可迭代“对象呢?
- 只要在类中,定义iter方法,那么这个类创建出来的对象一定是可迭代对象
一个类,只要有iter方法,那么这个类创建出来的对象就是可以迭代对象,那为什么依然报错呢?
- 其实,当我们调用iter()函数提取一个可迭代对象的 迭代器时,实际上会自动调用这个对象的iter方法,并且这个方法返回迭代器,我们并没有返回迭代器。
next
在使用next()函数的时候,调用的就是迭代器对象的next方法
python要求迭代器本身也是可迭代的,所以我们还要为迭代器实现iter方法,而iter方法要返回一个迭代器,迭代器自身正是一个迭代器,所以迭代器的iter方法返回自身即可。
一个实现了iter方法和next方法的对象,就是迭代器
class MyList(object):
"""自定义的一个可迭代对象"""
def __init__(self):
self.items = []
def add(self, val):
self.items.append(val)
def __iter__(self):
myiterator = MyIterator(self)
return myiterator
class MyIterator(object):
"""自定义的供上面可迭代对象使用的一个迭代器"""
def __init__(self, mylist):
self.mylist = mylist
# current用来记录当前访问到的位置
self.current = 0
def __next__(self):
# 判断是否全部迭代完毕
if self.current < len(self.mylist.items):
# 每次获取一个值然后返回
item = self.mylist.items[self.current]
self.current += 1
return item
else:
raise StopIteration
def __iter__(self):
return self
if __name__ == '__main__':
mylist = MyList()
mylist.add(1)
mylist.add(2)
mylist.add(3)
mylist.add(4)
mylist.add(5)
for num in mylist:
print(num)
'''
1
2
3
4
5
'''
for…in…循环的本质
- 凡是可作用于for循环的对象都是Iterable 类型;
- 凡是可作用于 next() 函数的对象都是Iterator 类型
- 集合数据类型如list 、dict、str等是 Iterable但不是Iterator,不过可以通过 iter()函数获得一个 Iterator对象
for循环迭代结束不会报StopIteration异常因为内部处理过了,但next迭代完再执行的话会报StopIteration异常
isinstance() 与 type() 区别:
type() 不会认为子类是一种父类类型,不考虑继承关系。
- isinstance() 会认为子类是一种父类类型,考虑继承关系。
如果要判断两个类型是否相同推荐使用 isinstance()。
class A:
pass
class B(A):
pass
isinstance(A(), A) # returns True
type(A()) == A # returns True
isinstance(B(), A) # returns True
type(B()) == A # returns False
生成器
在Python中,这种一边循环一边计算的机制,称为生成器:generator。
生成器是一类特殊的迭代器
- 使用了yield关键字的函数不再是函数,而是生成器。
- 使用next调用生成器,执行顺序:
print(l) #[0, 2, 4, 6, 8]
g = ( x*2 for x in range(5))
print(g) #
创建 L 和 G 的区别仅在于最外层的 [ ] 和 ( ) , L 是一个列表,而 G 是一个生成器。我们可以直接打印出列表L的每一个元素,而对于生成器G,我们可以按照迭代器的使用方法来使用,即可以通过next()函数、for循环、list()等方法使用。
```python
from collections.abc import Iterable, Iterator
g = (x * 2 for x in range(5))
# 检测是否可以迭代
print(isinstance(g, Iterable))
# 是否是迭代器
print(isinstance(g, Iterator))
for x in g:
print(x)
"""
True
True
0
2
4
6
8
"""
创建生成器(yield)
只要在def中有yield关键字的 就称为 生成器,代码中的gen()得到的是一个生成器,可以用next()来获取生成器的数据,生成器是可以迭代的
def gen():
i = 0
while i < 5:
yield i
i += 1
# 此时获取的是一个生成器 不是在执行一个函数
g = gen()
print(g) # <generator object gen at 0x000001AF5E151F48>
print(next(g))
print(next(g))
print(next(g))
print(next(g))
print(next(g))
print(next(g))
获取return的值
使用用for循环调用generator时,发现拿不到generator的return语句的返回值。如果想要拿到返回值,需要使用next()调用,并且必须捕获StopIteration错误,返回值包含在StopIteration的value中:
def nmb():
print(1)
yield 2
return 'sbi'
try:
nmb1 = nmb()
next(nmb1)
next(nmb1)
except StopIteration as e:
print(f"返回值:{e.value}")
send
我们除了可以使用next()函数来唤醒生成器继续执行外,还可以使用send()函数来唤醒执行。
send()函数的一个好处是可以在唤醒的同时向断点处传入一个附加数据。
def gen():
i = 0
while i < 5:
print(2)
temp = yield i
print(temp)
f = gen()
print(next(f))
print('--------------------')
print(next(f))
print('--------------------')
print(f.send('haha'))
print('--------------------')
"""
2
0
--------------------
None
2
0
--------------------
haha
2
0
--------------------
"""
特点
生成器的特点:
- 生成器不仅“记住”了它数据状态;生成器还“记住”了它在流控制构造(在命令式编程中,这种构造不只是数据值)中的位置。
存储的是生成数据的方式(即算法),而不是存储生成的数据,因此节约内存
装饰器
```python def check(func): def inner():
# 验证1 # 验证2 # 验证3 func()return inner
@check def f1(): print(‘f1’)
1. @check等价于 check(f1)
1. 即将check的返回值再重新赋值给 f1, 也就是 新f1 = inner
<a name="DBwEV"></a>
#### 小总结
普通的闭包和把闭包作为装饰器使用有什么区别呢?
- 普通闭包:内部函数将使用的外部变量当做数据来用
- 将闭包当做装饰器:内部函数将使用的外部变量当做可调用的对象(例如函数)来调用
<a name="peGod"></a>
#### 有参数装饰器
```python
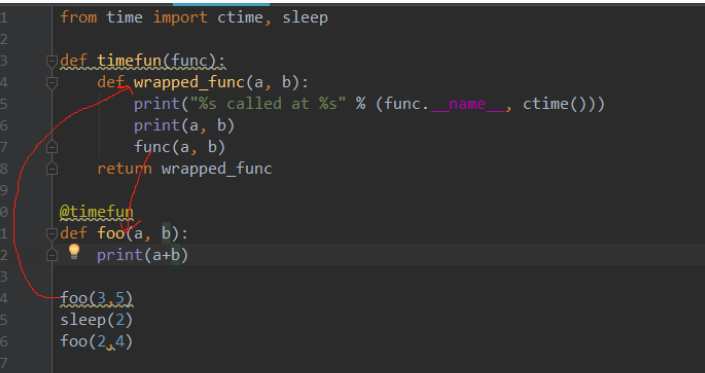
from time import ctime, sleep
def timefun(func):
def wrapped_func(a, b):
print("%s called at %s" % (func.__name__, ctime()))
print(a, b)
func(a, b)
return wrapped_func
@timefun
def foo(a, b):
print(a+b)
foo(3,5)
sleep(2)
foo(2,4)
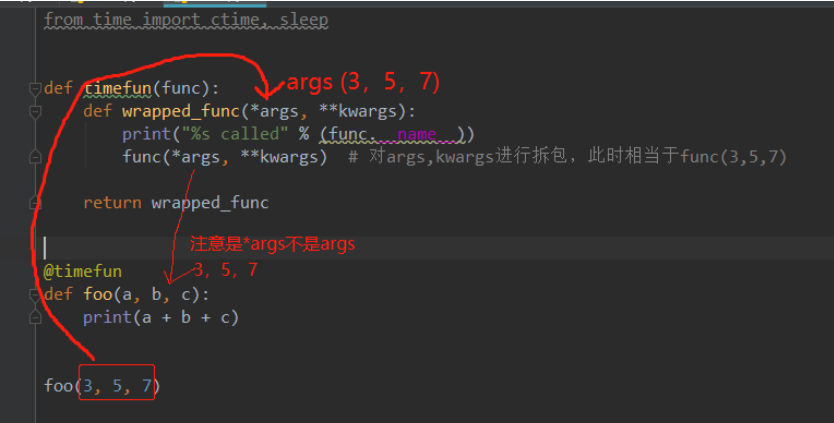
对带有不定长参数的函数进行装饰
from time import ctime, sleep
def timefun(func):
def wrapped_func(*args, **kwargs):
print("%s called at %s"%(func.__name__, ctime()))
func(*args, **kwargs)
return wrapped_func
@timefun
def foo(a, b, c):
print(a+b+c)
foo(3,5,7)
return
- 一般情况下为了让装饰器更通用,可以有return,即使这个被装饰的函数默认没有返回值也不会有问题,因为此时相当于return None
多层嵌套装饰器
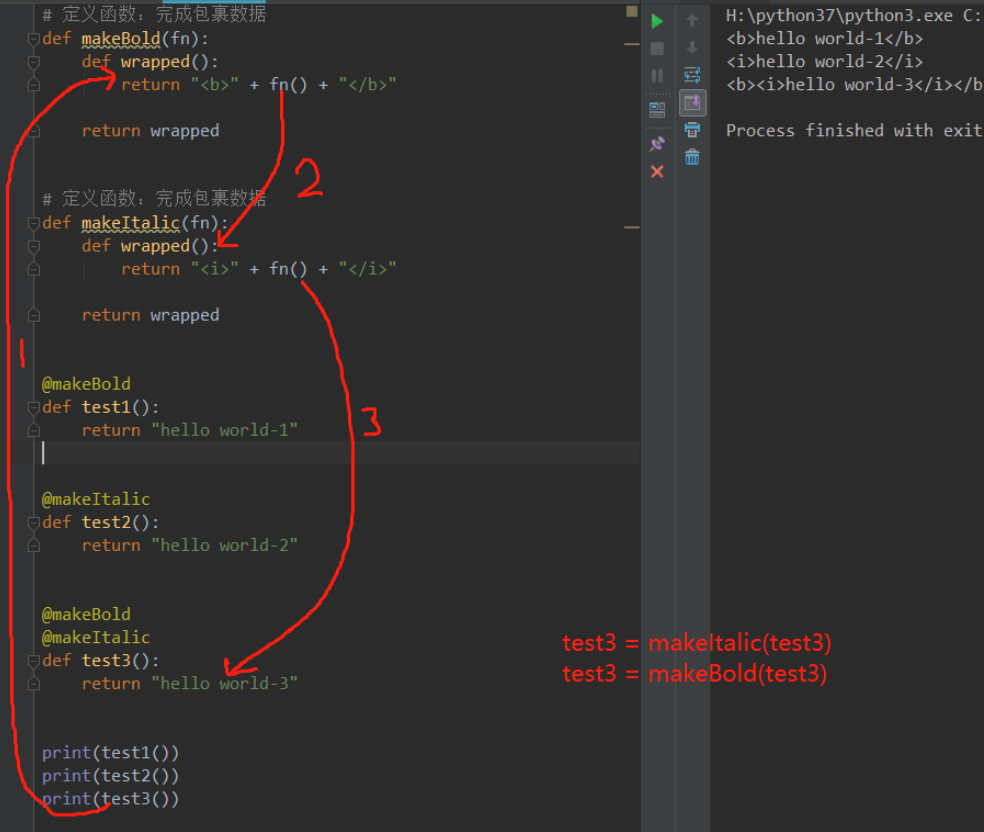
装饰器带参数
外层参数,中层函数
三个函数嵌套 ```python def out_def1(pre): def out_def(func):
def in_def(a,b): print('haha') print(pre) func(a,b) return in_defreturn out_def
@out_def1(‘nihao’) def bei(a,b): print(a,b)
bei(1,2)
<a name="lgdlo"></a>
#### 类装饰器
> [https://blog.updown.world/articles/python/pythonbook2/01-%E4%B8%89%E5%99%A8%E4%B8%80%E9%97%AD/04-%E8%A3%85%E9%A5%B0%E5%99%A8.html](https://blog.updown.world/articles/python/pythonbook2/01-%E4%B8%89%E5%99%A8%E4%B8%80%E9%97%AD/04-%E8%A3%85%E9%A5%B0%E5%99%A8.html)
装饰器函数其实是这样一个接口约束,它必须接受一个callable对象作为参数,然后返回一个callable对象。在Python中一般callable对象都是函数,但也有例外。只要某个对象重写了 __call__() 方法,那么这个对象就是callable的。
```python
class Test(object):
def __init__(self, func):
print("---初始化---")
print("func name is %s"%func.__name__)
self.__func = func
def __call__(self):
print("---装饰器中的功能---")
self.__func()
#说明:
#1. 当用Test来装作装饰器对test函数进行装饰的时候,首先会创建Test的实例对象
# 并且会把test这个函数名当做参数传递到__init__方法中
# 即在__init__方法中的属性__func指向了test指向的函数
#
#2. test指向了用Test创建出来的实例对象
#
#3. 当在使用test()进行调用时,就相当于让这个对象(),因此会调用这个对象的__call__方法
#
#4. 为了能够在__call__方法中调用原来test指向的函数体,所以在__init__方法中就需要一个实例属性来保存这个函数体的引用
# 所以才有了self.__func = func这句代码,从而在调用__call__方法中能够调用到test之前的函数体
@Test
def hi():
print("----test---")
hi()
闭包
- 在一个函数里,嵌套定义了另外一个函数,里面的函数使用的外部函数中的变量,最后把里面的函数作为外部函数的返回值返回,这样就形成一个闭包
```python
定义一个函数
def test(a): def test_in(b):print("in test_in 函数, b is %d" % b) return a+b其实这里返回的就是闭包的结果
return test_in
给test函数赋值,这个20就是给参数a
ret = test(20)
注意这里的100其实给参数b
print(ret(100))
注 意这里的200其实给参数b
print(ret(200)) “”” in test_in 函数, b is 100 120
in test_in 函数, b is 200 220 “””
由于闭包引用了外部函数的局部变量,则外部函数的局部变量没有及时释放,消耗内存
<a name="dfKDB"></a>
#### nonlocal
nonlocal可以访问外部函数里的非全局变量<br />global则可以修改全局变量
```python
def foo():
m = 0
def foo1():
nonlocal m
m = 1
print(m)
print(m)
foo1()
print(m)
foo()
"""
0
1
1
"""
m = 6
def foo():
m = 0
def foo1():
def haha():
nonlocal m
m = 1
print(m)
# return m
# return haha()
haha()
foo1()
print('----')
return m
print(foo())
print(m)
"""
1
----
1
6
"""

若有收获,就点个赞吧
0 人点赞
