函数介绍
每个函数的作用:
accept_request: 处理从套接字上监听到的一个 HTTP 请求,在这里可以很大一部分地体现服务器处理请求流程。
bad_request: 返回给客户端这是个错误请求,HTTP 状态吗 400 BAD REQUEST.
cat: 读取服务器上某个文件写到 socket 套接字。
cannot_execute: 主要处理发生在执行 cgi 程序时出现的错误。
error_die: 把错误信息写到 perror 并退出。
execute_cgi: 运行 cgi 程序的处理,也是个主要函数。
get_line: 读取套接字的一行,把回车换行等情况都统一为换行符结束。
headers: 把 HTTP 响应的头部写到套接字。
not_found: 主要处理找不到请求的文件时的情况。
sever_file: 调用 cat 把服务器文件返回给浏览器。
startup: 初始化 httpd 服务,包括建立套接字,绑定端口,进行监听等。
unimplemented: 返回给浏览器表明收到的 HTTP 请求所用的 method 不被支持。
源码阅读顺序: main -> startup -> accept_request -> execute_cgi, 通晓主要工作流程后再仔细把每个函数的源码看一看。
1. main 函数
首先从main函数来看起,可以通过main函数来得知整个程序的大概流程,然后再详细解析其他代码。代码如下:
int main(void){/* 变量初始化 */int server_sock = -1;u_short port = 4000;int client_sock = -1;struct sockaddr_in client_name;socklen_t client_name_len = sizeof(client_name);pthread_t newthread;/* 启动服务器,在指定端口或者随机选取端口绑定 httpd 服务 */server_sock = startup(&port);/* 打印启动服务器消息 */printf("httpd running on port %d\n", port);while (1){client_sock = accept(server_sock, //调用 accept 等待客户端请求,这里 accept 处于阻塞状态,(struct sockaddr *)&client_name, //直到有客户端连接才会返回已连接套接字描述符 client_sock&client_name_len);if (client_sock == -1) //处理 accept 异常error_die("accept");/* 创建一个新线程运行 accept_request 函数去处理客户端的请求 */if (pthread_create(&newthread , NULL, (void *)accept_request, (void *)(intptr_t)client_sock) != 0)perror("pthread_create"); //处理 pthread_create 异常}close(server_sock); //关闭return(0);}
main函数先初始化server_sock:监听套接字描述符、port:服务器默认启动端口 、client_sock:客户端套接字描述符、client_name: 客户端套接字地址结构、 client_name_len:客户端套接字地址结构长度 、newthread:新线程。关于sockaddr_in套接字地址结构,其内部结构如下:
struct sockaddr_in {uint16_t sin_family; // Protocol family (always AF_INET)uint16_t sin_port; // Port number in network byte orderstruct in_addr sin_addr; // IP address in network byte orderunsigned char sin_zero[8]; // Pad to sizeof(struct sockaddr)}
接下来调用startup函数来启动服务器,在指定端口或随机选取端口绑定 httpd 服务,返回监听套接字描述符。
进入一个 while 循环,调用accept函数来等待客户端请求,将accept函数阻塞,直到有客户端连接,也就是收到一个 HTTP 请求时,返回一个已连接套接字描述符client_sock。
如果accept成功返回一个client_sock,那么就派生一个新线程,调用accept_request(client_sock),来处理客户端请求。
2. startup 函数
startup函数用来初始化 httpd 服务,包括建立套接字,绑定端口,进行监听等。代码如下:
/**********************************************************************//* This function starts the process of listening for web connections* on a specified port. If the port is 0, then dynamically allocate a* port and modify the original port variable to reflect the actual* port.* Parameters: pointer to variable containing the port to connect on* Returns: the socket *//**********************************************************************/int startup(u_short *port){int httpd = 0;int on = 1;struct sockaddr_in name;/* 创建一个新的套接字描述符 */httpd = socket(PF_INET, SOCK_STREAM, 0);if (httpd == -1)error_die("socket");/* 初始化套接字地址结构 */memset(&name, 0, sizeof(name));/* 填充套接字地址结构 */name.sin_family = AF_INET;name.sin_port = htons(*port);name.sin_addr.s_addr = htonl(INADDR_ANY);/* 设置套接字为 SO_REUSEADDR 选项,即允许套接口和一个已在使用中的地址捆绑 */if ((setsockopt(httpd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on))) < 0){error_die("setsockopt failed");}/* 将当前套接字绑定到对应的端口 */if (bind(httpd, (struct sockaddr *)&name, sizeof(name)) < 0)error_die("bind");/* 如果默认指定端口值为0,那么就动态随机分配一个端口 */if (*port == 0){socklen_t namelen = sizeof(name);/* 通过 getsockname 函数获取与当前套接字相关的地址,并将指定端口设置为获取到的地址的端口int getsockname(int sockfd, struct sockaddr *localaddr,socklen_t *addrlen);参数:sockfd:需要获取名称的套接字。localaddr:存放所获取套接字名称的缓冲区。addrlen:作为入口参数,name指向空间的最大长度。作为出口参数,name的实际长度。描述:getsockname可以获得一个与socket相关的地址。服务器端可以通过它得到相关客户端地址。而客户端也可以得到当前已连接成功的socket的ip和端口。对于TCP连接的情况,如果不进行bind指定IP和端口,那么调用connect连接成功后,使用getsockname可以正确获得当前正在通信的socket的IP和端口地址。而对于UDP的情况,无论是在调用sendto之后还是收到服务器返回的信息之后调用,都无法得到正确的ip地址:使用getsockname得到ip为0,端口正确。*/if (getsockname(httpd, (struct sockaddr *)&name, &namelen) == -1)error_die("getsockname");*port = ntohs(name.sin_port);}/* 开始监听,将 httpd 转为监听套接字描述符 */if (listen(httpd, 5) < 0)error_die("listen");return(httpd);}
startup函数先初始化httpd:套接字描述符、on:setsockopt 函数中指向选项值的缓冲区、name:服务器套接字地址结构。
int socket(int domain, int type, int protocol);
在参数表中,domain指定使用何种的地址类型,比较常用的有:
PF_INET, AF_INET: Ipv4网络协议;
PF_INET6, AF_INET6: Ipv6网络协议。
type参数的作用是设置通信的协议类型,可能的取值如下所示:
SOCK_STREAM: 提供面向连接的稳定数据传输,即TCP协议。
OOB: 在所有数据传送前必须使用connect()来建立连接状态。
SOCK_DGRAM: 使用不连续不可靠的数据包连接。
SOCK_SEQPACKET: 提供连续可靠的数据包连接。
SOCK_RAW: 提供原始网络协议存取。
SOCK_RDM: 提供可靠的数据包连接。
SOCK_PACKET: 与网络驱动程序直接通信。
通过socket函数来创建一个套接字描述符,其中 PF_INET(与AF_INET同义)表明使用IPV4,SOCK_STREAM表示数据传输方式,提供面向连接的稳定数据传输,即TCP协议。
设置服务器套接字地址结构,分别是其协议、端口和 IP 地址。
通过setsockopt函数设置套接字为 SO_REUSEADDR 选项,即允许套接口和一个已在使用中的地址捆绑。
将当前套接字描述符httpd绑定到对应的端口,即name中的服务器套接字地址。
如果默认指定端口值为0,就会动态随机分配一个端口,通过getsockname函数获取与当前套接字相关的服务器地址,并将指定端口设置为获取到的服务器地址的端口。
套接字描述符绑定完毕后,将httpd转为监听套接字描述符。
返回监听套接字描述符。
3. accept_request 函数
accept_request函数用来处理从套接字上监听到的一个 HTTP 请求,在这里可以很大一部分地体现服务器处理请求流程。代码如下:
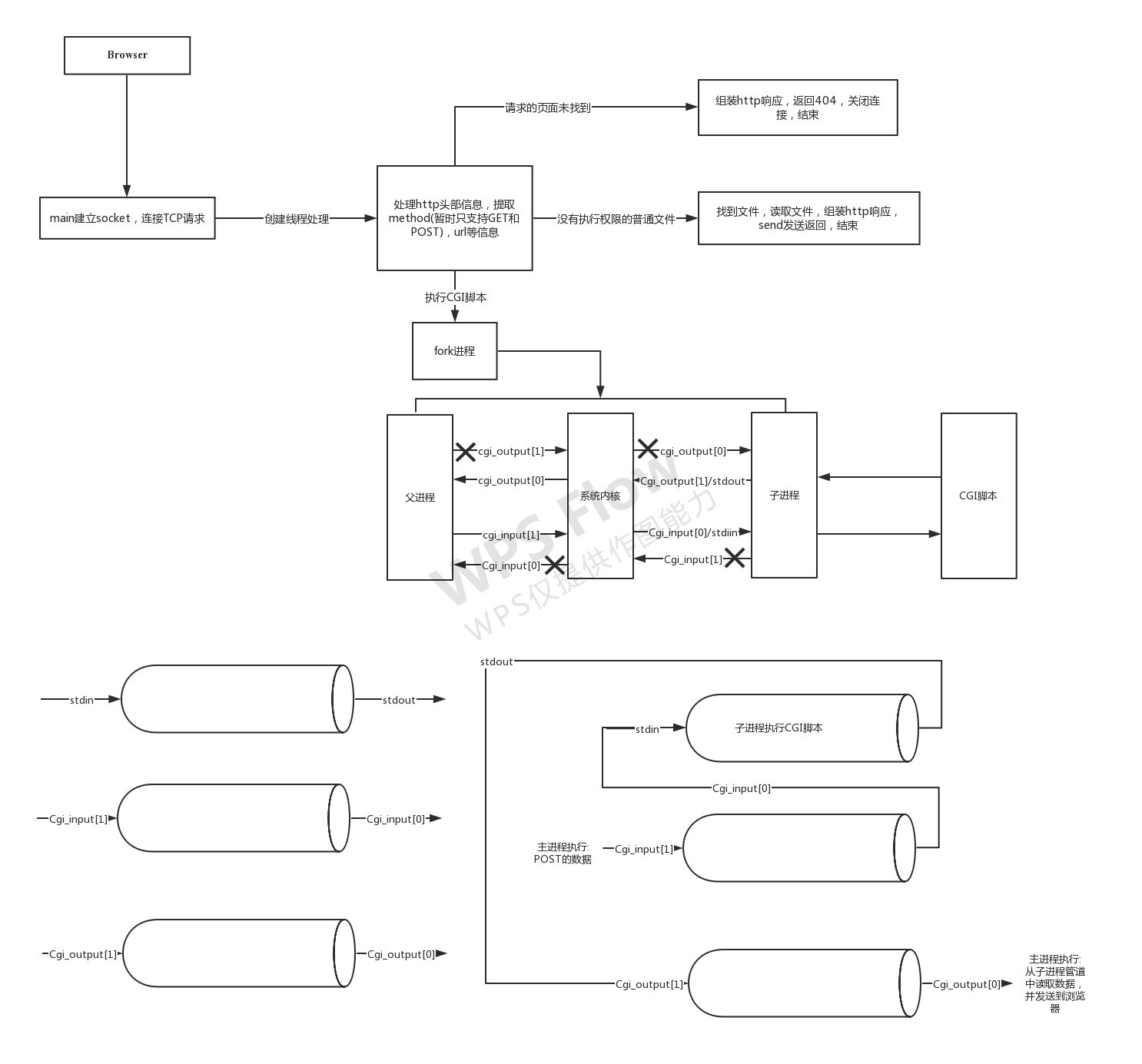
/**********************************************************************//* A request has caused a call to accept() on the server port to* return. Process the request appropriately.* Parameters: the socket connected to the client *//**********************************************************************/void accept_request(void *arg){int client = (intptr_t)arg;char buf[1024];size_t numchars;char method[255];char url[255];char path[512];size_t i, j;struct stat st;int cgi = 0; /* becomes true if server decides this is a CGI program */char *query_string = NULL;/* 获取客户端发送的 HTTP 请求报文的请求行 requestline 部分,并存储在字符串数组 buf 中 */numchars = get_line(client, buf, sizeof(buf));i = 0; j = 0;/* 截取 buf 中的方法字段,存储在字符串数组 method 中 */while (!ISspace(buf[i]) && (i < sizeof(method) - 1)){method[i] = buf[i];i++;}j=i;method[i] = '\0';/* 只实现了GET与POST方法,如果既不是GET又不是POST方法,则返回错误int strcasecmp (const char *s1, const char *s2);strcasecmp()用来比较参数s1和s2字符串,比较时会自动忽略大小写的差异。参数s1和s2字符串相等则返回0。s1大于s2则返回大于0 的值,s1 小于s2 则返回小于0的值。*/if (strcasecmp(method, "GET") && strcasecmp(method, "POST")){unimplemented(client);return;}/* 如果为 POST 方法,将 cgi 标志位置1,将开启 cgi */if (strcasecmp(method, "POST") == 0)cgi = 1;i = 0;/* 截取 buf 中的 URL 字段,存储在字符串数组 url 中 */while (ISspace(buf[j]) && (j < numchars)) //跳过空白字符j++;while (!ISspace(buf[j]) && (i < sizeof(url) - 1) && (j < numchars)){url[i] = buf[j];i++; j++;}url[i] = '\0';/* 如果为 GET 方法 */if (strcasecmp(method, "GET") == 0){/* 处理URL */query_string = url;/* 查找URL是否存在'?' */while ((*query_string != '?') && (*query_string != '\0'))query_string++;/* 如果URL存在'?',开启 cgi,并将 query_string 指针指向'?'后的请求参数 */if (*query_string == '?') //退出循环后检查当前的字符是 ?还是字符串(url)的结尾{cgi = 1;/* 将 URL 与参数字段分离 */*query_string = '\0';//使指针指向字符 ?后面的那个字符query_string++;}}/* 格式化 URL 在 path 数组,默认服务器文件根目录在 htdocs 下 */sprintf(path, "htdocs%s", url);/* 如果路径以'/'符号结尾,则加上 "index.html",即默认访问 index */if (path[strlen(path) - 1] == '/')strcat(path, "index.html");/* 判断请求的文件在服务器中是否存在 *//*struct stat {dev_t st_dev; //文件的设备编号ino_t st_ino; //节点mode_t st_mode; //文件的类型和存取的权限nlink_t st_nlink; //连到该文件的硬连接数目,刚建立的文件值为1uid_t st_uid; //用户IDgid_t st_gid; //组IDdev_t st_rdev; //(设备类型)若此文件为设备文件,则为其设备编号off_t st_size; //文件字节数(文件大小)unsigned long st_blksize; //块大小(文件系统的I/O 缓冲区大小)unsigned long st_blocks; //块数time_t st_atime; //最后一次访问时间time_t st_mtime; //最后一次修改时间time_t st_ctime; //最后一次改变时间(指属性)};函数定义: int stat(const char *file_name, struct stat *buf);函数说明: 通过文件名filename获取文件信息,并保存在buf所指的结构体stat中返回值: 执行成功则返回0,失败返回-1,错误代码存于errno(需要include <errno.h>)错误代码:ENOENT 参数file_name指定的文件不存在ENOTDIR 路径中的目录存在但却非真正的目录ELOOP 欲打开的文件有过多符号连接问题,上限为16符号连接EFAULT 参数buf为无效指针,指向无法存在的内存空间EACCESS 存取文件时被拒绝ENOMEM 核心内存不足ENAMETOOLONG 参数file_name的路径名称太长st_mode 则定义了下列数种情况S_IFMT 0170000 文件类型的位遮罩S_IFSOCK 0140000 scoketS_IFLNK 0120000 符号连接S_IFREG 0100000 一般文件S_IFBLK 0060000 区块装置S_IFDIR 0040000 目录S_IFCHR 0020000 字符装置S_IFIFO 0010000 先进先出S_ISUID 04000 文件的(set user-id on execution)位S_ISGID 02000 文件的(set group-id on execution)位S_ISVTX 01000 文件的sticky位S_IRUSR(S_IREAD) 00400 文件所有者具可读取权限S_IWUSR(S_IWRITE)00200 文件所有者具可写入权限S_IXUSR(S_IEXEC) 00100 文件所有者具可执行权限S_IRGRP 00040 用户组具可读取权限S_IWGRP 00020 用户组具可写入权限S_IXGRP 00010 用户组具可执行权限S_IROTH 00004 其他用户具可读取权限S_IWOTH 00002 其他用户具可写入权限S_IXOTH 00001 其他用户具可执行权限上述的文件类型在POSIX中定义了检查这些类型的宏定义:S_ISLNK (st_mode) 判断是否为符号连接S_ISREG (st_mode) 是否为一般文件S_ISDIR (st_mode) 是否为目录S_ISCHR (st_mode) 是否为字符装置文件S_ISBLK (s3e) 是否为先进先出S_ISSOCK (st_mode) 是否为socket若一目录具有sticky位(S_ISVTX),则表示在此目录下的文件只能被该文件所有者、此目录所有者或root来删除或改名。*/if (stat(path, &st) == -1) {/* 如果不存在,读取 HTTP 请求报文的请求头,然后丢弃 */while ((numchars > 0) && strcmp("\n", buf)) /* read & discard headers */numchars = get_line(client, buf, sizeof(buf));/* 返回404错误 */not_found(client);}else{/* 如果存在,但却是个目录而不是文件,则继续拼接目录,访问该目录下的 index.html */if ((st.st_mode & S_IFMT) == S_IFDIR)strcat(path, "/index.html");/* 判断用户权限 S_IXUSR:用户可以执行 S_IXGRP:组可以执行 S_IXOTH:其它人可以执行 */if ((st.st_mode & S_IXUSR) ||(st.st_mode & S_IXGRP) ||(st.st_mode & S_IXOTH))/* 如果通过权限判断,开启 cgi */cgi = 1;/* 如果 cgi 未开启,直接输出服务器文件到浏览器 */if (!cgi)serve_file(client, path);/* 如果 cgi 开启,则执行 cgi 程序 */elseexecute_cgi(client, path, method, query_string);}/* 断开与客户端的连接 */close(client);}
accept_request函数先初始化client:客户端套接字描述符、buf:读取请求行时的数据缓存区、numchars:请求行字符长度、method:请求行中的方法名、path:请求行中的路径、url:请求行中的 URL 字段、st:文件属性、cgi:cgi 标志位、query_string:指向 URL 中请求参数的指针。
先通过get_line函数获取客户端发送的 HTTP 请求报文的请求行 requestline 部分,并存储在字符串数组 buf 中,一个HTTP请求报文由请求行(requestline)、请求头部(header)、空行和请求数据4个部分组成,请求行由请求方法字段(get或post)、URL字段和HTTP协议版本字段3个字段组成,它们用空格分隔。如:GET /index.html HTTP/1.1。
将 buf 中的方法字段存储在字符串数组method中。
判断method中方法名,如果既不是 GET也不是POST 方法,则报错,如果为 POST 方法则将 cgi 字段置1,也就是开启 cgi。
将 buf 中的 URL 字段存储在字符串数组url中。
如果为 GET 方法,则先判断 URL 中是否存在?字符,如果存在,将query_string指向?后的参数字段,将 URL 与参数字段分离,且开启 cgi。
将分离后的 URL 存储在 path字段,默认服务器根目录为 htdocs,如果path字段以/结尾,则加上默认路径index.html,表示访问主页。判断该文件在服务器中是否存在,如果不存在该文件,读取 HTTP 请求报文的请求头,然后丢弃,返回404错误。如果存在但只是个目录名,而不是文件名,则查找该目录下的index.html文件。判断用户权限 S_IXUSR:用户可以执行、S_IXGRP:组可以执行、S_IXOTH:其它人可以执行,如果通过权限判断,则开启 cgi。
最后判断 cgi 是否开启,如果未开启(不带参数 GET),则直接调用serve_file函数,输出服务器文件到浏览器,即用 HTTP 格式写到套接字上。如果 cgi 开启(带参数 GET,POST 方式,url 为可执行文件),调用execute_cgi函数执行 CGI 脚本。
4. execute_cgi 函数
execute_cgi 函数用来运行 cgi 程序的处理,处理客户端请求中携带的的参数。代码如下:
/**********************************************************************//* Execute a CGI script. Will need to set environment variables as* appropriate.* Parameters: client socket descriptor* path to the CGI script *//**********************************************************************/void execute_cgi(int client, const char *path,const char *method, const char *query_string){char buf[1024];int cgi_output[2];int cgi_input[2];pid_t pid;int status;int i;char c;int numchars = 1;int content_length = -1;buf[0] = 'A'; buf[1] = '\0';/* 如果是 GET 方法,则丢弃 HTTP 报文的请求头 */if (strcasecmp(method, "GET") == 0)while ((numchars > 0) && strcmp("\n", buf)) /* read & discard headers */numchars = get_line(client, buf, sizeof(buf));/* 如果是 POST 方法,则需要从HTTP 报文的请求头中找出 Content-Length */else if (strcasecmp(method, "POST") == 0) /*POST*/{numchars = get_line(client, buf, sizeof(buf));while ((numchars > 0) && strcmp("\n", buf)){/* 分离 content_length */buf[15] = '\0';if (strcasecmp(buf, "Content-Length:") == 0)/* 读出 content_length *///记录 body 的长度大小,Content-Length: 后面还有一个空格,所以增加‘\0’不影响后面的读取content_length = atoi(&(buf[16]));numchars = get_line(client, buf, sizeof(buf));}/* 如果请求长度不合法(比如根本就不是数字),那么就报错,即没有找到content_length */if (content_length == -1) {bad_request(client);return;}}else/*HEAD or other*/{}/* 建立管道 */if (pipe(cgi_output) < 0) {cannot_execute(client);return;}/* 建立管道 */if (pipe(cgi_input) < 0) {cannot_execute(client);return;}/* 生成子进程 */if ( (pid = fork()) < 0 ) {cannot_execute(client);return;}/* 把 HTTP 200 状态码写到套接字 */sprintf(buf, "HTTP/1.0 200 OK\r\n");/* */send(client, buf, strlen(buf), 0);/* 子进程调用 CGI 脚本 */if (pid == 0) /* child: CGI script */{char meth_env[255];char query_env[255];char length_env[255];/* 将父进程的读写管道重定向到子进程的标准输入和标准输出*//* 把 STDOUT 重定向到 cgi_output 的写入端,把 STDIN 重定向到 cgi_input 的读取端 *//* 关闭 cgi_input 的写入端 和 cgi_output 的读取端 */dup2(cgi_output[1], STDOUT);dup2(cgi_input[0], STDIN);close(cgi_output[0]);close(cgi_input[1]);/* 设置 request_method 的环境变量,即服务器设置,设置基本的CGI环境变量,请求类型、参数、长度之类 */sprintf(meth_env, "REQUEST_METHOD=%s", method);putenv(meth_env);/* GET 方法设置 query_string 的环境变量 */if (strcasecmp(method, "GET") == 0) {sprintf(query_env, "QUERY_STRING=%s", query_string);putenv(query_env);}/* POST 方法设置 content_length 的环境变量 */else { /* POST */sprintf(length_env, "CONTENT_LENGTH=%d", content_length);putenv(length_env);}/* 使用 execl 运行 cgi 程序 */execl(path, NULL);exit(0);} else { /* parent *//* 父进程中关闭 cgi_input 的读取端 和 cgi_output 的写入端 */close(cgi_output[1]);close(cgi_input[0]);/* 把 POST 数据写入 cgi_input,已被重定向到 STDIN,读取 cgi_output 的管道输出到客户端,该管道输入是 STDOUT */if (strcasecmp(method, "POST") == 0)for (i = 0; i < content_length; i++) {recv(client, &c, 1, 0);write(cgi_input[1], &c, 1);}/* 父进程从输出管道里面读出所有结果,返回给客户端 */while (read(cgi_output[0], &c, 1) > 0)send(client, &c, 1, 0);/* 关闭剩余的管道 */close(cgi_output[0]);close(cgi_input[1]);/* 等待子进程结束 */waitpid(pid, &status, 0);}}
execute_cgi 函数先初始化buf:读取请求行时的数据缓存区、cgi_output:管道名、cgi_input:管道名、pid:进程号、status:进程的状态、numchars:请求行字符长度、content_length:POST 请求内容长度。
判断如果是 GET 方法,则丢弃掉 HTTP 报文的请求头,如果是 POST 方法,则需要从HTTP 报文的请求头中找出 Content-Length,将其值赋给变量content_length(转为整型),最后判断请求长度是否合法。
建立两个管道,cgi_input 和 cgi_output, 并 fork 自身产生子进程。
在子进程中,把 STDOUT 重定向到 cgi_outputt 的写入端,把 STDIN 重定向到 cgi_input 的读取端,关闭 cgi_input 的写入端 和 cgi_output 的读取端,目的是相当于将父进程的读写管道重定向到子进程的标准输入和标准输出。
CGI程序的特点是通过标准输入(stdin)和环境变量(可以理解成有两个传递数据的途径,二者相辅相成,其实跟请求方法是get或post也相关)来得到服务器的信息,并通过标准输出(stdout)向服务器输出信息。环境变量就是指的系统环境变量,就是linux中可以用echo命令查询那些,比如HOME, PATH等。http协议中也定义了一些自己的环境变量,用于在CGI与服务器之间传输参数。下面给出几个相关的环境变量:
SERVER_NAMECGI脚本运行时的主机名和IP地址.SERVER_SOFTWARE你的服务器的类型如: CERN/3.0 或 NCSA/1.3.GATEWAY_INTERFACE运行的CGI版本.对于UNIX服务器, 这是CGI/1.1.SERVER_PROTOCOL服务器运行的HTTP协议. 这里当是HTTP/1.0.SERVER_PORT服务器运行的TCP口,通常Web服务器是80.REQUEST_METHODPOST 或 GET, 取决于你的表单是怎样递交的.HTTP_ACCEPT浏览器能直接接收的Content-types, 可以有HTTP Accept header定义.HTTP_USER_AGENT递交表单的浏览器的名称、版本 和其他平台性的附加信息。HTTP_REFERER递交表单的文本的 URL,不是所有的浏览器都发出这个信息,不要依赖它PATH_INFO附加的路径信息, 由浏览器通过GET方法发出.PATH_TRANSLATED在PATH_INFO中系统规定的路径信息.SCRIPT_NAME指向这个CGI脚本的路径,是在URL中显示的(如, /cgi-bin/thescript).QUERY_STRING脚本参数或者表单输入项(如果是用GET递交). QUERY_STRING 包含URL中问号后面的参数.REMOTE_HOST递交脚本的主机名,这个值不能被设置.REMOTE_ADDR递交脚本的主机IP地址.REMOTE_USER递交脚本的用户名. 如果服务器的authentication被激活,这个值可以设置。REMOTE_IDENT如果Web服务器是在ident(一种确认用户连接你的协议)运行,递交表单的系统也在运行ident, 这个变量就含有ident返回值.CONTENT_TYPE如果表单是用POST递交, 这个值将是application/x-www-form-urlencoded. 在上载文件的表单中,content-type 是个multipart/form-data.CONTENT_LENGTH对于用POST递交的表单, 标准输入口的字节数.
然后设置 request_method 的环境变量,即设置基本的CGI环境变量,请求类型、参数、长度之类 ,GET 的话设置 query_string 的环境变量,POST 的话设置 content_length 的环境变量,这些环境变量都是为了给 cgi 脚本调用,接着用 execl 运行 cgi 程序。
在父进程中,关闭 cgi_input 的读取端 和 cgi_output 的写入端,如果 POST 的话,把 POST 数据写入 cgi_input,通过管道写入到子进程的 STDIN,通过cgi_output 的管道读取数据(相当于子进程的stdout)并输出到客户端。接着关闭所有管道,等待子进程结束。
关闭与浏览器的连接,完成了一次 HTTP 请求与回应,因为 HTTP 是无连接的。
框架流程图

若有收获,就点个赞吧
0 人点赞
