- MySQL数据管理
- MySQL体系结构
- 查询数据库支持的存储引擎
show engines \G;
# 查询默认存储引擎
MariaDB [(none)]> show variables like “default_storage_engine”;
+————————————+————+
| Variable_name | Value |
+————————————+————+
| default_storage_engine | InnoDB |
+————————————+————+
# 指定存储引擎
第一种方式:在建表的时候指定
subpartition_definition:
[[STORAGE] ENGINE [=] engine_name]
create table t1(id int(4),name char(10)) engine=MyISAM;
第二种方式:修改已存在表的存储引擎
alter table t1 engine=MyISAM;
# 在配置文件当中可以指定
[mysqld]
default-storage-engine=INNODB
MySQL在启动的过程中:会去读取配置文件
读取配置文件的顺序:/etc/mysql/my.cnf /etc/my.cnf ~/.my.cnf # 如果配置文件中,某个参数存在多个值,以最后一个配置为准 - 表操作
- 数据类型
- 创建表中一个默认宽度的init,一个是指定宽度的int(5)
create table test(id int,id_2 int(5))
#向test表中插入数据1
#insert into table name values(v1,v2)
insert into test values(1,1)
当我们插入比宽度大的值不会报错,所以正确的数值不会受到宽度的影响
#修改ID字段,给字段添加一个unsigned约束条件表示无符号
alter table test change id id int UNSIGNED
DESCRIBE test - 给id字段插入一个比2147488364
— insert into test values (2147488365,2147488365)
# 小数示例
# 创建test2表,二个字段float,double
create table test2(num1 FLOAT(5,2),num2 DOUBLE(5,2))
# 向表中插入1.23
insert into test2 VALUES(1.23,1.23)
select from test2
# 向表中插入1.234
insert into test2 VALUES(1.235,1.235)
# 创建test3表,二个字段,但是去掉参数约束
create table test3(num1 FLOAT,num2 DOUBLE);
insert into test3 VALUES(1.234,1.234);
select from test3;
# 没有约束条件,所以1.234能够正常插入
# 对小数位没有约束的时候,输入超长的小数
insert into test3 VALUES(1.234111111111,1.234111111111111111111111);
select from test3;
# float数据类型会截断小数位第5位,而double数据类型会截断小数位第16位
日期时间类型
DATE:YY-MM-DD (3bytes)
TIME:HH:MM:SS (3bytes)
YEAR: YYYY (1bytes)
DATETIME:YYYY-MM-DD HH:MM:SS (8bytes)
TIMESTAP:YYYYMMDD HHMMSS(4bytes);混合日期和时间值,时间戳
示例:
# 创建date表,3个字段:date time datetime
— create table data (date date,time time,datetime datetime)
— desc data
—
# 显示当前时间,使用内聚函数now()
— select now()
insert into data VALUES(now(),now(),now());
SELECT FROM data
# 创建date2表,1个字段:id字段的数据类型为:timestamp
create table date2 (id timestamp);
insert into date2 VALUES(null);
SELECT from date2
# 即使我们插入的数据为NULL,但是会自动帮我们插入当前的时间
字符串类型:
CHAR:定长字符串(0-255bytes)
VARCHAR:可变长字符串(0-65535bytes)
TEXT:长文本数据(0-65535bytes)
# 创建name表,2个字段:name1 char(4),name2 varchar(4)
— create table name (name1 char(4),name2 varchar(4));
— insert into name VALUES(‘ab ‘,’ab ‘);
— select from name;
select LENGTH(name1),LENGTH(name2) from name
# 当插入的字符串值大于宽度会被截断
insert into name VALUES(‘abcde’,’abcde’);
ENUM类型和SET类型
ENUM类型:枚举类型,它的值范围需要在创建的时候在表中通过枚举方式显示
ENUM只允许从值集合中选取单个值,而不能一次性取多个
SET类型:也是一个字符串对象,里面可以包含0-64个成员,根据成员的不同
存储上也有所不同。set类型可以允许值集合中任意选择1个或多个元素组成集合
性别:男 | 女
兴趣爱好: basketball rap song
create table fav(id int PRIMARY key auto_increment,sex enum(‘n’,’v’),fov SET(‘c’,’t’,’r’,’l’)) - 表的约束
- 单表查询记录操作:
MySQL数据管理
MySQL是一个关系型数据库,将数据保存到不同的表中,而不是将数据放到一个大的仓库中,这样能够增加速度和我们的灵活性
安装MariaDB
[root@localhost ~]# yum install mariadb mariadb-server -y #安装相关软件包
[root@localhost ~]# systemctl start mariadb #开启MariaDB服务
[root@localhost ~]# mysql_secure_installation #初始化数据库
1.设置用户密码
2.删除匿名用户
3.是否禁止root用户远程登陆
4.删除test数据库
5.删除授权表,让初始化生效
sql语句基础
MySQL命令
常用选项
-D:指定数据库
-e:执行命令后退出
-h:指定主机
-p:指定密码
-u:指定用户
-P:指定端口(默认端口是3306)
连接数据库
mysql -uroot -ppassward
MariaDB [(none)]> select user(); # 查看当前用户
MariaDB [(none)]> set password = password(‘000000’); # 修改当前用户密码
创建用户
- CREATE USER ‘jeffrey’@’localhost’ IDENTIFIED BY ‘mypass’;
create user -> 创建用户命令
‘jeffrey’@’localhost’ -> 创建的用户是本地用户还是远程登录用户
localhost:本地用户
%:所有地址
192.168.10.% : 只允许来自于192.168.10.0/24网段机器来进行连接数据库
IDENTIFIED BY ‘mypass’; -> 指定该用户的密码
查询用户权限
MariaDB [mysql]> show grants for ‘test’@’192.168.10.%’;
Select_priv: N
Insert_priv: N
Update_priv: N
Delete_priv: N
Create_priv: N
Drop_priv: N
Reload_priv: N
Shutdown_priv: N
Process_priv: N
File_priv: N
Grant_priv: N
References_priv: N
Index_priv: N
Alter_priv: N
Show_db_priv: N
Super_priv: N
Create_tmp_table_priv: N
Lock_tables_priv: N
Execute_priv: N
Repl_slave_priv: N
Repl_client_priv: N
Create_view_priv: N
Show_view_priv: N
Create_routine_priv: N
Alter_routine_priv: N
Create_user_priv: N
Event_priv: N
Trigger_priv: N
Create_tablespace_priv: N
授权操作
grants <权限> on
grant select on mysql.user to ‘test’@’192.168.10.%’;
# 给远程用户test授予select查询权限
MariaDB [(none)]> grant select on mysql.user to ‘test’@’192.168.10.%’;
# 刷新权限
flush privileges;
# 创建用户并授权
grants <权限> on
SQL语句主要用于存取数据,查询数据,更新数据和管理关系型数据库系统
SQL语句分为三类:
1.DDL语句:数据库定义语句:数据库、表、视图、索引、存储过程等
2.DML语句:数据库操作语句:插入数据、删除数据、更新数据、查询数据等等
3.DCL语句:数据库控制语句:控制用户访问权限等等
操作数据库
增
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name
[create_specification] …
删
DROP {DATABASE | SCHEMA} [IF EXISTS] db_name
改
ALTER {DATABASE | SCHEMA} [db_name]
alter_specification …
查:show databases;
操作表
增
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
(create_definition,…)
[table_options]
[partition_options]
删
DROP [TEMPORARY] TABLE [IF EXISTS]
tbl_name [, tbl_name] …
[RESTRICT | CASCADE]
改
ALTER [ONLINE | OFFLINE] [IGNORE] TABLE tbl_name
[alter_specification [, alter_specification] …]
[partition_options]
查:show tables;
操作表中的记录
增INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name [(col_name,…)]
{VALUES | VALUE} ({expr | DEFAULT},…),(…),…
[ ON DUPLICATE KEY UPDATE
col_name=expr
[, col_name=expr] … ]
删 DELETE [LOW_PRIORITY] [QUICK] [IGNORE] FROM tbl_name
[WHERE where_condition]
[ORDER BY …]
[LIMIT row_count]
改UPDATE [LOW_PRIORITY] [IGNORE] table_reference
SET col_name1={expr1|DEFAULT} [, col_name2={expr2|DEFAULT}] …
[WHERE where_condition]
[ORDER BY …]
[LIMIT row_count]
查SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr …]
[FROM table_references
[WHERE where_condition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], … [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], …]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[PROCEDURE procedure_name(argument_list)]
[INTO OUTFILE ‘file_name’
[CHARACTER SET charset_name]
export_options
| INTO DUMPFILE ‘file_name’
| INTO var_name [, var_name]]
[FOR UPDATE | LOCK IN SHARE MODE]]
清空表:
1. delete from tb1_name; # 如果有自增id,新增的数据,仍然是以删除前的最后一行作为起始
2. truncate table tb1_name; # 数据大的情况下,删除速度比上一条快,且直接从0开始
MySQL体系结构
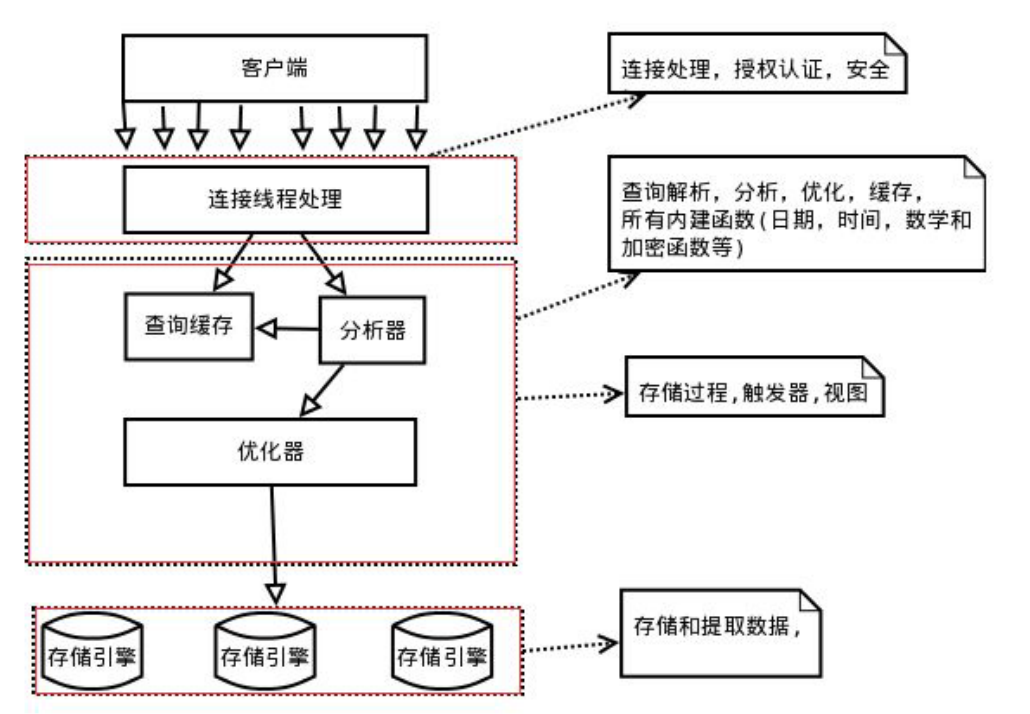
MySQ体系结构分为四层
1.提供给网络客户端连接接口:授权认证和安全
2.MySQL的核心服务:功能——查询、解析、分析、优化、缓存等,还包括存储过程、触发器、视图等
3.存储引擎:功能——存取和提取数据,存储引擎以插件的形式存在于MySQL当中(作用范围:表)
不同的表有不同的存储引擎,不同的存储引擎之间不能通信
4.文件系统:所有表结构和数据以及用户操作的日志最终还是以文件的形式存在于硬盘上
存储引擎
存储引擎:MySQL将数据用不同的技术存储在文件(或内存)中,不同的技术拥有不同的存储机制、索引技巧、锁定水平等,通过选取不同的存储引擎,能够改善应用整体的功能,那这些不同的技术和功能就是“存储引擎”(表引擎)
MySQL支持的数据库引擎:innoDB、MyISAM、memory等
*innoDB
innoDB(默认的存储引擎):是一个事务安全的引擎
1.它具备提交、回滚以及崩溃恢复的功能来保证数据的完整性
2.innoDB的行级别锁和一致性无锁读技术提升多用户并发读的性能
3.innoDB将用户数据存放在聚集索引(聚簇索引)中以减少基于主键的查询带来的额外IO开销
4.为了保证数据的完整性,innoDB还支持外键约束
应用场景:高并发、数据一致性、更新和删除操作较多,事务的完整性提交和回滚
MyISAM
memory
存储引擎相关命令
查询数据库支持的存储引擎
show engines \G;
# 查询默认存储引擎
MariaDB [(none)]> show variables like “default_storage_engine”;
+————————————+————+
| Variable_name | Value |
+————————————+————+
| default_storage_engine | InnoDB |
+————————————+————+
# 指定存储引擎
第一种方式:在建表的时候指定
subpartition_definition:
[[STORAGE] ENGINE [=] engine_name]
create table t1(id int(4),name char(10)) engine=MyISAM;
第二种方式:修改已存在表的存储引擎
alter table t1 engine=MyISAM;
# 在配置文件当中可以指定
[mysqld]
default-storage-engine=INNODB
MySQL在启动的过程中:会去读取配置文件
读取配置文件的顺序:/etc/mysql/my.cnf /etc/my.cnf ~/.my.cnf # 如果配置文件中,某个参数存在多个值,以最后一个配置为准
表操作
创建表:
语法:
增:CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
(create_definition,…)
[table_options]
[partition_options]
CREATE TABLE tb1_name(field1 type[宽度] 约束条件1,
field2 type[宽度] 约束条件2
……
)[table_options]
注意:
1. 在同一张表中,字段名必须唯一
2. 宽度和约束条件可选
3. 字段名和类型是必须要有的
实例1:员工信息表
create table staff_info(
id int,
name varchar(10),
age int(3),
sex enum(‘male’,’female’),
job varchar(10)
);
查看表结构:DESCRIBE staff_info;
+———-+———————————-+———+——-+————-+———-+
| Field | Type | Null | Key | Default | Extra |
+———-+———————————-+———+——-+————-+———-+
| id | int(11) | YES | | NULL | |
| name | varchar(10) | YES | | NULL | |
| age | int(3) | YES | | NULL | |
| sex | enum(‘male’,’female’) | YES | | NULL | |
| job | varchar(10) | YES | | NULL | |
+———-+———————————-+———+——-+————-+———-+
查询表的DDL语句:show create tables staff_info;
CREATE TABLE staff_info (
id int(11) DEFAULT NULL,
name varchar(10) DEFAULT NULL,
age int(3) DEFAULT NULL,
sex enum(‘male’,’female’) DEFAULT NULL,
job varchar(10) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
修改表结构:
ALTER [ONLINE | OFFLINE] [IGNORE] TABLE tbl_name
[alter_specification [, alter_specification] …]
[partition_options]
1. 修改表名:
alter table tb1_name rename new_tb1_name;
> alter table staff_info rename new_staff_info;
2. 增加字段:
alter table tb1_name add field3 type(宽度) 完整的约束条件;
> alter table new_staff_info add iphone int(13) not null;
3. 删除字段:
alter table tb1_name drop field_name;
> alter table new_staff_info drop sex;
4. 修改字段:
alter table tb1_name change old_field new_field type(宽度) 完整的约束条件;
> alter table new_staff_info change iphone address varchar(20) default NULL;
alter table tb1_name modify field_name type(宽度) 完整约束条件;
创建自增ID主键:
约束条件:
1. id是自增 —> auto_increment
2. 主键 —> primary key ; 特性:1.主键字段必须唯一
创建表时候添加约束条件
创建表后修改id字段
alter table new_staff_info change id id int PRIMARY KEY auto_increment;
删除自增ID主键
1. 去掉主键的自增约束
2. 然后再去删除主键约束
alter table new_staff_info MODIFY id int(10);
alter table new_staff_info drop primary key;
主键:
两个字段当作主键来作为约束的时候,我们称之为:联合主键
NULL:代表该字段是否可以为空
PRI:主键字段不可为空且必须唯一
default:该字段的默认值
表的编码方式:通常采用UTF-8
所以在创建表的时候要通过:charset=utf-8
查询数据库关于编码的信息
MariaDB [info]> show [global | session] variables like “%char%”;
+—————————————+——————————————+
| Variable_name | Value |
+—————————————+——————————————+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+—————————————+——————————————+
8 rows in set (0.00 sec)
global: 全局会话
session: 当前会话
[DEFAULT] CHARACTER SET [=] charset_name [COLLATE [=] collation_name]
修改当前会话编码:
set character_set_database = utf8;
set character_set_server = utf8;
全局永久修改字符编码:
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
character-set-server = utf8
接着然后重启MySQL服务
数据类型
数值类型
TINYINIT 小整数值(1bytes)
SAMLLINT 大整数值(2bytes)
MEDIUMINT 大整数值(bytes)
INT 大整数值(4bytes)
BIGINIT 极大整数值(8bytes)
FLAOT 单精度浮点类型(4bytes)
DOUBLE 双精度浮点类型(8bytes)
浮点类型:float(5,2) —-> 一共显示5位,小数位部分占2位
INT整数实例
创建表中一个默认宽度的init,一个是指定宽度的int(5)
create table test(id int,id_2 int(5))
#向test表中插入数据1
#insert into table name values(v1,v2)
insert into test values(1,1)
当我们插入比宽度大的值不会报错,所以正确的数值不会受到宽度的影响
#修改ID字段,给字段添加一个unsigned约束条件表示无符号
alter table test change id id int UNSIGNED
DESCRIBE test
给id字段插入一个比2147488364
— insert into test values (2147488365,2147488365)
# 小数示例
# 创建test2表,二个字段float,double
create table test2(num1 FLOAT(5,2),num2 DOUBLE(5,2))
# 向表中插入1.23
insert into test2 VALUES(1.23,1.23)
select from test2
# 向表中插入1.234
insert into test2 VALUES(1.235,1.235)
# 创建test3表,二个字段,但是去掉参数约束
create table test3(num1 FLOAT,num2 DOUBLE);
insert into test3 VALUES(1.234,1.234);
select from test3;
# 没有约束条件,所以1.234能够正常插入
# 对小数位没有约束的时候,输入超长的小数
insert into test3 VALUES(1.234111111111,1.234111111111111111111111);
select from test3;
# float数据类型会截断小数位第5位,而double数据类型会截断小数位第16位
日期时间类型
DATE:YY-MM-DD (3bytes)
TIME:HH:MM:SS (3bytes)
YEAR: YYYY (1bytes)
DATETIME:YYYY-MM-DD HH:MM:SS (8bytes)
TIMESTAP:YYYYMMDD HHMMSS(4bytes);混合日期和时间值,时间戳
示例:
# 创建date表,3个字段:date time datetime
— create table data (date date,time time,datetime datetime)
— desc data
—
# 显示当前时间,使用内聚函数now()
— select now()
insert into data VALUES(now(),now(),now());
SELECT FROM data
# 创建date2表,1个字段:id字段的数据类型为:timestamp
create table date2 (id timestamp);
insert into date2 VALUES(null);
SELECT from date2
# 即使我们插入的数据为NULL,但是会自动帮我们插入当前的时间
字符串类型:
CHAR:定长字符串(0-255bytes)
VARCHAR:可变长字符串(0-65535bytes)
TEXT:长文本数据(0-65535bytes)
# 创建name表,2个字段:name1 char(4),name2 varchar(4)
— create table name (name1 char(4),name2 varchar(4));
— insert into name VALUES(‘ab ‘,’ab ‘);
— select from name;
select LENGTH(name1),LENGTH(name2) from name
# 当插入的字符串值大于宽度会被截断
insert into name VALUES(‘abcde’,’abcde’);
ENUM类型和SET类型
ENUM类型:枚举类型,它的值范围需要在创建的时候在表中通过枚举方式显示
ENUM只允许从值集合中选取单个值,而不能一次性取多个
SET类型:也是一个字符串对象,里面可以包含0-64个成员,根据成员的不同
存储上也有所不同。set类型可以允许值集合中任意选择1个或多个元素组成集合
性别:男 | 女
兴趣爱好: basketball rap song
create table fav(id int PRIMARY key auto_increment,sex enum(‘n’,’v’),fov SET(‘c’,’t’,’r’,’l’))
表的约束
为了防止不规范的数据存放在数据库中,通常DBS按照一定的约束条件对数据进行检测,确保数据库中存储的数据正确有效
分类:
NOT NULL:非空约束
UNIQUE:唯一约束
PRIMARY KEY:主键:唯一标识表中的一条记录
FOREIGN KEY:外键:从属于主表的一条记录
NOT NULL
NOT NULL: 不可为空
NULL : 可空
default:该字段的默认值;当表中有一列重复内容,避免频繁操作,可以设置其为
默认值
not null + default 组合
create table info1 (id int(4),id_name varchar(4),addr int(5) NOT NULL DEFAULT 111)
NOT NULL:不可空
设置严格模式:
不支持对not null字段插入null值
不支持对自增长字段插入null值
不支持text字段有默认
NULL:可空
default:某一字段的默认值,当表中有一列重复内容,避免频繁操作,可以设置默认值
UNIQUE:唯一约束
唯一约束: 指定某列或者某几列组合不能重复
第一种方式:
create table department1 (id int(5),name varchar(10) UNIQUE,comm text
(20))
第二种方式:
create table department1 (id int(5),name varchar(10),comm text UNIQUE(name)
(20))
desc department1
not null + unqiue组合使用
create table info3 (id int(10),id_name int(18) not null unqiue)
联合唯一
create table department2 (id int(5),name varchar(10),id_name int(18),UNIQUE(id,id_name))
主键:为了保证表中的每一条数据的该字段都是表格中的唯一值
主键必须唯一,主键值为非空,可以是单一字段,也可以是多个字段的组合
主键的约束条件=not null+unique+……
关键字:primary key
# 添加1个字段的主键
alter table info1 MODIFY id int(5) PRIMARY key;
# 删除主键
alter table info1 drop PRIMARY key
# 添加多个字段的主键
alter table info1 add PRIMARY key(id,id_name);
# 创建单个主键
create table host_info (id int(5),hostname varchar(10),ipaddress varchar(10),PRIMARY key(id))
— drop table host_info;
# 创建多个主键
create table host_info(id int(5),nid int(5),hostname varchar(10),ipaddress varchar(10),PRIMARY key(id,nid));
外键
作用:避免重复字段浪费存储资源;有利用用户查询
# 创建出版社表
create table pulisher(id int(5) PRIMARY key,name varchar(10) not null)
# 创建书籍表
create table book(id int(5) PRIMARY key,bname VARCHAR(10) not null,to_pid int(5),FOREIGN key(to_pid) REFERENCES pulisher(id))
# 当我们想要创建外键的时候,需要约束条件 UNIQUE —> pulisher表中的字段
desc book
单表查询记录操作:
增:插入记录
第一种: 插入完整记录
insert into book(field1,field2….fieln) values(v1,v2,v3…,vn)
insert into book(id,bname,topid) values(1,mysql,1)
insert into book values(2,linux,2)
第二种方式:指定字段插入数据
insert into book(id,to_pid) values(3,1)
第三种方式:插入多条数据
insert into book values(4,’java’,1),(5,’js’,2),(6,’go’,2)
删
delete from book where id = 1
改
update
查
# 单表查询
select bname from book where id=3
# where 后面+条件
# : 全部字段
# 语法: select fields from table_name conditions(条件)
— # conditions(条件)
— 以下语法具有优先级:优先如下:
— from 表名
— where 条件
— group by 分组(field)
— select fields 输出哪些字段信息
— DISTINCT 去重
— having 筛选 (where发生在分组前,having发生分组后)
— order by field(排序:顺序 | 倒序)
— limit by N (限制的条数)
— select bname from book where id > 3
# 分组查询
# count(): 进行统计 count(1) count()
select bname,count() from book group by bname
select bname,count() from book where id >= 5 group by bname
# having:对分组后的记录进行筛选
select bname,count() from book where id >= 5 group by bname having count(1) >=2
# 排序: order by field [ASC: 顺序 默认情况|DESC:倒序]
select from book ORDER BY id DESC
select id,bname,count() from book where id >= 5 group by bname having count(1) >=1 ORDER BY id DESC
# limit关键字
select id,bname,count() from book where id >= 5 group by bname having count(1) >=1 LIMIT 1
# DISTINCT 关键字:去重 关键字必须放到字段名前
select DISTINCT bname from book where bname=’go’
— from 表名
— where 条件
— group by 分组(field)
— select fields 输出哪些字段信息
— having 筛选 (where发生在分组前,having发生分组后)
— order by field(排序:顺序 | 倒序)
— limit by N (限制的条数)
— 查询操作的过程:
— 1. from:找到需要查询的表
— 2. where:通过where指定约束条件,去表中取出的一条条记录
— 3. group by: 将取出的记录进行分组,如果没有分组,则整体为一组
— 4. select:查询记录中的指定字段(可以进行去重操作)
— 5. having:将分组的结果进行过滤
— 6. order by:将结果按照条件进行排序
— 7. limit:限制结果的显示行数
where约束:
1. 比较运算符: > < = >= !=
2. BETWEEN a and b: 在a到b值之间的记录
3. in(80,90,100) : 值是80或90或100
4. like 表示可以使用通配符的方式
%: 表示任意多个字符
: 表示任意单个字符
逻辑运算符:
and 且
or 或
not 非
关键字:IS NULL 判断某个字段是否为NULL
# 聚合函数
count(): 统计
MAX(): 寻找最大值
MIN(): 寻找最小值
SUM() : 求和
AVG(): 求平均值
insert into book values(4,’java’,1),(5,’js’,2),(6,’go’,2)
# 删除某条记录
delete from book where id = 1
# 更新记录
update book set bname=’javascript’ where bname = ‘js’
# 查询记录 ** 关键字:select
# 单表查询
select bname from book where id=3
select from book where id != 4
select from book where id BETWEEN 3 and 7
select from book where id in(4,7,2)
# 尽量少用,影响查询效率
select from book where bname like ‘lin%’
select from book where id>3 and bname=’go’
select from book where id<5 or bname='go'
select from book where id > 3 and not bname=’go’
select from book where bname IS NULL
# where 后面+条件
# : 全部字段
# 语法: select fields from table_name conditions(条件)
— # conditions(条件)
— 以下语法具有优先级:优先如下:
— from 表名
— where 条件
— group by 分组(field)
— select fields 输出哪些字段信息
— DISTINCT 去重
— having 筛选 (where发生在分组前,having发生分组后)
— order by field(排序:顺序 | 倒序)
— limit by N (限制的条数)
— select bname from book where id > 3
# 分组查询
# count(): 进行统计 count(1) count()
select bname,count() from book group by bname
select bname,count() from book where id >= 5 group by bname
# having:对分组后的记录进行筛选
select bname,count() from book where id >= 5 group by bname having count(1) >=2
# 排序: order by field [ASC: 顺序 默认情况|DESC:倒序]
select from book ORDER BY id DESC
select id,bname,count() from book where id >= 5 group by bname having count(1) >=1 ORDER BY id DESC
# limit关键字
#
select id,bname,count() from book where id >= 5 group by bname having count(1) >=1 limit 2 # 前多少行记录,默认其实位置为0
select id,bname,count() from book where id >= 5 group by bname having count(1) >=1 LIMIT 1,2 # 1,2行记录
# 后2行记录
select id,bname,count(*) from book where id >= 5 group by bname having count(1) >=1 order by count(1) desc LIMIT 2
# DISTINCT 关键字:去重 关键字必须放到字段名前
select DISTINCT bname from book where bname=’go’
— from 表名
— where 条件
— group by 分组(field)
— select fields 输出哪些字段信息
— having 筛选 (where发生在分组前,having发生分组后)
— order by field(排序:顺序 | 倒序)
— limit by N (限制的条数)
— 查询操作的过程:
— 1. from:找到需要查询的表
— 2. where:通过where指定约束条件,去表中取出的一条条记录
— 3. group by: 将取出的记录进行分组,如果没有分组,则整体为一组
— 4. select:查询记录中的指定字段(可以进行去重操作)
— 5. having:将分组的结果进行过滤
— 6. order by:将结果按照条件进行排序
— 7. limit:限制结果的显示行数
—
alter table book add price FLOAT;
select bname,max(price) from book;
select bname,min(price) from book;
select sum(price) from book;
select avg(price) from book;

若有收获,就点个赞吧
0 人点赞
