Flink知识点
Flink CEP
CEP相关依赖:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-cep_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency>
基本使用:
// 1. 定义模式
Pattern<WaterSensor, WaterSensor> pattern = Pattern
.<WaterSensor>begin("start") // begin()是模式,事件
.where(new SimpleCondition<WaterSensor>() { // where()是条件
@Override
public boolean filter(WaterSensor value) throws Exception {
return "sensor_1".equals(value.getId());
}
});
// 2. 在流上应用模式
PatternStream<WaterSensor> waterSensorPS = CEP.pattern(waterSensorStream, pattern);
// 3. 获取匹配到的结果
waterSensorPS
.select(new PatternSelectFunction<WaterSensor, String>() {
@Override
public String select(Map<String, List<WaterSensor>> pattern) throws Exception {
return pattern.toString();
}
})
.print();
模式API
单例模式:单例模式只接受一个事件, 默认情况模式都是单例模式.
循环模式:可以接受多个事件,单例模式配合上量词就是循环模式.
量词:
times(2):出现两次; times(2,4):出现2-4次; oneOrMore():出现一次或多次; timesOrMore(2):出现两次及多次以上
条件:
迭代条件:最普遍的条件,使用它可以指定一个基于前面已经被接受的事件的属性或者它们的一个子集的统计数据来决定是否接受时间 序列的条件例如where中的IterativeCondition。
简单条件:这种类型的条件扩展了前面提到的IterativeCondition类,它决定是否接受一个事件只取决于事件自身的属性。
组合条件:可以写多个条件形成and或or。
停止条件:在循环模式下,读取无界流数据时,指定一个停止条件。timeOrMore()循环才可以指定,因为该循环没有明确的次数。
注:迭代条件与简单条件的区别在与条件中new的类不同,迭代条件中是 IterativeCondition,简单条件中是 SimpleCondition,两个 条件的输出结果一样,区别点在于new的类中重写的方法中参数的不同,迭代条件中是 Context
组合模式:将多个单个模式组合到一块。
严格连续:期望所有匹配的事件严格的一个接一个出现,中间没有任何不匹配的事件
松散连续:忽略匹配的事件之间的不匹配的事件
非确定的松散连续:
next():下一个相连的;notNext():不是下一个相连的;followedBy():松散连续,两个条件之前不匹配的;followedByAny():非严格松散连续,多条件匹配,不管中间的
// 默认是松散模式
//.times(2) // 连续两个
.timesOrMore(2) // 连续两个及以上
// 严格连续和非确定的松散连续必须在循环模式下才行
// 严格连续,必须是连续的,中间有不符合的数据就不行
//.consecutive()
//.within(Time.seconds(3))
// 非确定的松散连续,不管中间有没有其他的不符合的数据
.allowCombinations()
循环的贪婪性:在组合模式情况下, 对次数的处理尽快能获取最多个的那个次数, 就是贪婪!当一个事件同时满足两个模式的时候起作用
.times(2, 3)
//贪婪,要循环最多的那个次数
.greedy()
.next("end") // 组合模式
.where(new IterativeCondition<WaterSensor>() {
@Override
public boolean filter(WaterSensor value, IterativeCondition.Context<WaterSensor> ctx) throws Exception {
return value.getVc() == 30;
}
});
模式的可选性:可以使用pattern.optional()方法让所有的模式变成可选的,不管是否是循环模式。适合在做一些判断的时候不需要全部的数据的情况。
.times(2, 3) // 可选性
.optional()
.next("end")
.where(new IterativeCondition<WaterSensor>() {
@Override
public boolean filter(WaterSensor waterSensor, Context<WaterSensor> context) throws Exception {
return "sensor_2".equals(waterSensor.getId());
}
});
超时数据:当一个模式上通过within加上窗口长度后,部分匹配的事件序列就可能因为超过窗口长度而被丢弃
.next("end")
.where(new IterativeCondition<WaterSensor>() {
@Override
public boolean filter(WaterSensor value, Context<WaterSensor> ctx) throws Exception {
return "sensor_2".equals(value.getId());
}
})
//窗口时间为3,当两条匹配到的数据之间间隔超过3S(包含3S)则匹配不到
//如果用到循环模式,则是否超时比的是当前模式第一个进来的事件
.within(Time.seconds(3))
FlinkSQL
简单使用:
// TODO 3.获取表的执行环境
StreamTableEnvironment streamTableEnvironment = StreamTableEnvironment.create(env);
// TODO 4.将流转换为动态表
Table table = streamTableEnvironment.fromDataStream(waterSensorStream);
// TODO 5.通过连续查询表总的数据
Table select = table.select($("id"), $("ts"), $("vc"));
// TODO 6.将结果转换成流
DataStream<Row> rowDataStream = streamTableEnvironment.toAppendStream(table, Row.class);
rowDataStream.print();
在进行聚合操作时,不能使用追加流 toAppendStream() 进行表转换成流的操作,会报错:toAppendStream doesn’t support consuming update changes which is produced by node GroupAggregate(groupBy=[id], select=[id, SUM(vc) AS TMP_0]),应使用撤回流 toRetractStream() 进行转换。
OLTP(联机事务处理):一类数据库操作,增删改查。
OLAP(联机分析处理):一类数据库操作,一次写入多次查询
从文件系统读取数据:创建表执行环境->创建表连接信息、创建表字段(连接外部文件系统)->读取文件的地址、数据存储格式、表连接信息、临时表的名称->利用表执行环境将临时表转换成Table对象->对动态表进行查询->将表转换为流进行输出;
将数据写入文件系统:创建表执行环境->将流转换为动态表->查询动态表->创建表连接信息、创建表字段(连接外部文件系统)->读取文件的写入地址、文件存储格式、表连接信息、临时表名->动态表调用executeInsert将数据写入文件;
事件时间:在创建表的DDL中定义事件时间时,时间的列必须为 TIMESTAMP(3) 类型,且是schema中的顶层列,也可以是一个计算列。定义方式:”t as to_timestamp(from_unixtime(ts/1000,’yyyy-MM-dd HH:mm:ss’)),”
tableEnv.executeSql("create table sensor(" +
"id string," +
"ts bigint," +
"vc int, " +
"t as to_timestamp(from_unixtime(ts/1000,'yyyy-MM-dd HH:mm:ss'))," + // 定义事件时间
"watermark for t as t - interval '5' second)" + // 指定WaterMark
"with("
+ "'connector' = 'filesystem',"
+ "'path' = 'input/sensor-sql.txt',"
+ "'format' = 'csv'"
+ ")"
);
如果因时区问题导致时间不一致,可以设置本地使用的时区:
Configuration configuration = tableEnv.getConfig().getConfiguration(); configuration.setString(“table.local-time-zone”, “GMT”);
窗口:
1.窗口类型:
滚动窗口:.window(Tumble.over(lit(10).second()).on($(“ts”)).as(“w”))
滑动窗口:.window(Slide.over(lit(3).seconds()).every(lit(2).second()).on(“ts”).as(“w”))
会话窗口:.window(Session.withGap(lit(2).seconds()).on(“ts”).as(“w”))
2.窗口相关参数:比如窗口大小
.window(Tumble.over(lit(10).second()).on($(“ts”)).as(“w”))
3.指定时间字段:.window(Tumble.over(lit(_10)_.second()).on($(“ts”)).as(“w”))
4.窗口别名:.window(Tumble.over(lit(10).second()).on($(“ts”)).as(“w”))
table
.window(Tumble.over(lit(10).second()).on($("ts")).as("w")) // 定义滚动窗口并给窗口起一个别名
.groupBy($("id"), $("w")) // 窗口必须出现的分组字段中
.select($("id"), $("w").start(), $("w").end(), $("vc").sum())
.execute()
.print();
Flink DataStream Join
官网API:https://nightlies.apache.org/flink/flink-docs-release-1.12/dev/stream/operators/joining.html
Join分为两种Window Join(先开窗再join)、Interval join(数值上join,不开窗直接做join)
Window Join -> Tumbling Window Join/Sliding Window Join/Session Window Join
Tumbling Window Join(滚动窗口):先开窗,各个窗口与窗口之间进行join,与sparkstreaming直接做join一样,在flink中开窗可以看作是spark中的batch
Sliding Window Join(滑动窗口):窗口开的是滑动窗口,一个窗口跟一个窗口进行join,与滚动窗口的不同在于会有重复数据
Session Window Join(会话窗口):一个会话一个窗口,然后join,需要注意的是,要两个流同时满足一段时间没有数据才会关窗,主要是为了时间对齐
| 区别 | Tumbling Window Join | Sliding Window Join | Session Window Join |
|---|---|---|---|
| 窗口类型 | 滚动窗口 | 滑动窗口 | 会话窗口 |
| 区别 | 与sparkstreaming直接做join一样,在flink中开窗可以看作是spark中的batch,可能会丢数据 | 会有重复数据 | 需要两条流同时满足一段时间没有数据才会关窗 |
| 时间 | 时间不对齐 | 时间不对齐 | 时间对齐 |
代码:
// Tumblin Window Join
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(TumblingEventTimeWindows.of(Time.milliseconds(2)))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});
// Sliding Window Join
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(SlidingEventTimeWindows.of(Time.milliseconds(2) /* size */, Time.milliseconds(1) /* slide */))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});
// Session Window Join
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(EventTimeSessionWindows.withGap(Time.milliseconds(1)))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});
Interval join -> 不开窗直接join,拿一个点join一条线,会给定上下界(lower bound/upper bound),保留线和点的状态。仅支持事件时间,数据允许多对多,属于内连接,两边都要数据才有结果。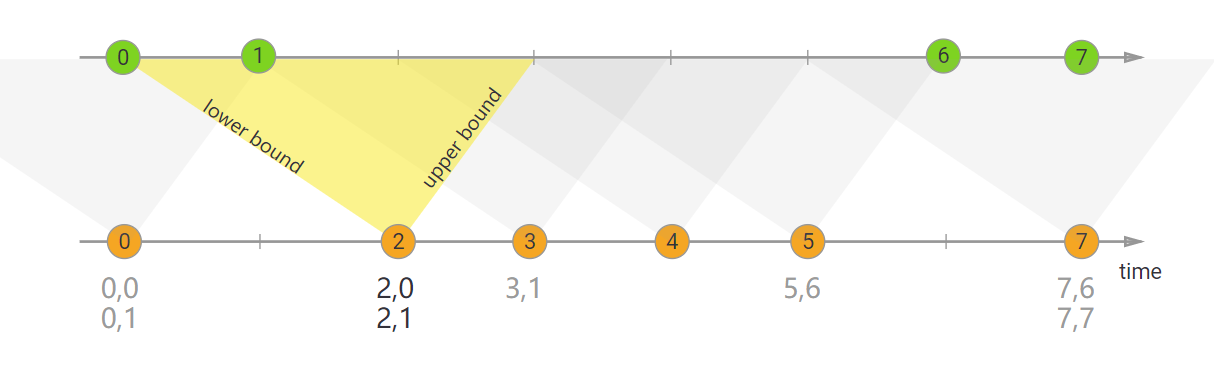
代码:
orangeStream
.keyBy(<KeySelector>)
.intervalJoin(greenStream.keyBy(<KeySelector>))
.between(Time.milliseconds(-2), Time.milliseconds(1)) // 给定延迟,防止数据丢失,与Redis中保存数据时间一样
.process (new ProcessJoinFunction<Integer, Integer, String(){
@Override
public void processElement(Integer first, Integer second, Context ctx, Collector<String> out) {
out.collect(first + "," + second);
}
});
双流join存在的问题:当两条流的并行度都是1时,两条流join,join后的流并行度是2,整个任务操作是在join之后。
Flink需求
DWS层访客主题需求。其他需求:在计算的时候,有可能在Javabean中加入辅助字段,算一些指标的时候不太好算
加入一些辅助字段辅助计算,辅助字段是 不需要写出的
所以javabean中的字段可能要比 clickhouse 中的字段多,此时遍历javabean遍历次数多于clickhouse中字段数
字段对应不上,对于这种字段,就不写出去,所以在赋值的时候进行一些加工
javabean中有一类注解 @Transient ,给 bean 对象使用,加了这个注解的字段在序列化的时候这个字段不进行序列化,即不写出去
因为这个字段可能是另一个字段的延伸字段,例如:B是A的衍生字段,通过A可以创建B,B就不用非要写出去,此时对B字段使用注解即可public class ClickHoustUtil { // 方法的返回值是JdbcSink调用的 sink() 方法的返回值 SinkFunction // SinkFunction<>的<>中,按照调用应该写 VistorStats 但是工具类这里要写 T ,否则就是去了工具类的作用 // 所以这里泛型的类型应该写 T ,同时要在方法返回值之前做方法类型声明 // 参数传未来四张表不一样的参数 public static <T> SinkFunction<T> getJdbcSink(String sql) { return JdbcSink.<T>sink(sql,new JdbcStatementBuilder<T>() { @SneakyThrows @Override public void accept(PreparedStatement preparedStatement, T t) throws SQLException { // preparedStatement 用自己的构建的连接去预编译与sql产生关联 // 将 t 中的12个地段给 preparedStatement // 因为字段个数与javabean中声明的属性个数一样,因此可以将 t 中的值遍历出来,按顺序给 ? 赋值即可 // 这是 T 类型的对象,获取字段值或字段名用 反射 ,因此这里需要先获取字段名,然后通过字段名调用对象获取属性 Class<?> clz = t.getClass(); // 通过反射的方式拿到类中的所有属性名和方法名 //Field[] fields = clz.getFields(); // 获取所有公有的属性 Field[] declaredFields = clz.getDeclaredFields(); // 获取所有的属性 // 这里使用 fori 进行遍历,因为 prepareStatement 赋值的时候需要一个 index,如果使用增强for循环不知道第几个属性 // 获取所有的属性名 int offset = 0; for (int i = 0; i < declaredFields.length; i++) { // 获取当前属性 Field field = declaredFields[i]; // 通过反射的方法获取当前属性值,这里直接get获取不到,会报编译时异常,因此需设置当前属性可访问 field.setAccessible(true); // 尝试获取字段上的注解 TransientSink annotation = field.getAnnotation(TransientSink.class); // 这个注解有的话,这个对象就不为 null 没有就是 null ,不等于 null 说明这个字段不要,就可以不走赋值的逻辑 if (annotation != null) { offset++; continue; } Object value = field.get(t); // 给预编译 SQL 对象赋值 // 这里不确定赋值的类型,所以使用 Object 进行代替 preparedStatement.setObject(i + 1 - offset, value); /* 其他需求:在计算的时候,有可能在Javabean中加入辅助字段,算一些指标的时候不太好算 加入一些辅助字段辅助计算,辅助字段是 不需要写出的 所以javabean中的字段可能要比 clickhouse 中的字段多,此时遍历javabean遍历次数多于clickhouse中字段数 字段对应不上,对于这种字段,就不写出去,所以在赋值的时候进行一些加工 javabean中有一类注解 @Transient ,给 bean 对象使用,加了这个注解的字段在序列化的时候这个字段不进行序列化,即不写出去 因为这个字段可能是另一个字段的延伸字段,例如:B是A的衍生字段,通过A可以创建B,B就不用非要写出去,此时对B字段使用注解即可 这里不是序列化,只是模仿这个注解的方式来写一个注解用于本次需求 */ } Method[] methods = clz.getMethods(); } }, // 刚写完时,类下面报红线表示该类中的构造方法被私有化,应该通过调用 Builder().build() 实现 new JdbcExecutionOptions.Builder() // 填写一些批处理的参数 .withBatchSize(5) // 5 条数据提交一次,为了时效性,这个批处理的提交应该越小越好 .build(), new JdbcConnectionOptions.JdbcConnectionOptionsBuilder() // 填写一些连接参数 .withDriverName(GmallConfig.CLICKHOUSE_DRIVER) // 驱动 // .withUsername() // 用不到 // .withPassword() .withUrl(GmallConfig.CLICKHOUSE_URL) // 连接地址 .build() ); } }

若有收获,就点个赞吧
0 人点赞
