索引是帮助MySQL高效获取数据的数据结构,提取句子主干,就可以索引的本质,索引是数据结构。
索引的分类
在一个表中 主键索引只能有一个 唯一索引可以有多个
- 主键索引(PRIMARY KEY)
- 唯一标识,主键不可重复,只能有一个列作为主键
- 唯一索引(UNIQUE KEY)
- 避免重复的列出现 唯一索引可以重复 多个列都可以标识为唯一索引
- 常规索引(KEY)
- 默认的 index,key关键字
全文索引(FULLTEXT)
在创建表的时候给字段增加索引
- 创建完毕后,增加索引
- 使用SQL语句添加索引
``sql --第一种方式 CREATE TABLEuser_message(idINT(4) NOT NULL AUTO_INCREMENT PRIMARY KEY,name` VARCHAR(20) NOT FULL )ENGINE=INNODB DEFAULT CHARSET=utf8;
—第二种方式
CREATE TABLE user_message(
id INT(4) NOT NULL AUTO_INCREMENT,
name VARCHAR(20) NOT FULL,
PRIMARY KEY(id)
)ENGINE=INNODB DEFAULT CHARSET=utf8;
—第三种方式
CREATE TABLE user_message(
id INT(4) NOT NULL AUTO_INCREMENT,
name VARCHAR(20) NOT FULL
)ENGINE=INNODB DEFAULT CHARSET=utf8;
CREATE UNIQUE INDEX user_message_id ON user_message(id);
CREATE 索引类型 INDEX 索引名 ON 表名(字段);
<a name="j8YZL"></a>### 显示所以的索引信息```sqlshow index from 表
分析SQL执行的情况
EXPLAIN关键字
--分析SQL执行的状况EXPLAIN SELECT * FROM `student` /*非全文索引*/EXPLAIN SELECT * FROM `student` WHERE MATCH(`StudentName`) AGAINST ('刘'); /*全文索引*/

插入一百万条数据后
、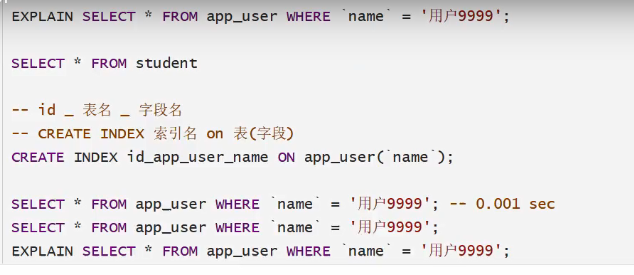
没有创建索引时
创建索引后
索引在小数据量的时候,用处不大。在大数据的时候,区别十分明显
索引原则
- 索引不是越多越好
- 不要对进程变动数据加索引
- 小数据量的表不需要索引
- 索引一般加在常用来查询的字段上
索引的数据结构
Hash类型的索引
Btree:INNODB默认数据结构、
阅读:http://blog.codinglabs.org/articles/theory-of-mysql-index.html

若有收获,就点个赞吧
0 人点赞
