一、特点
- NoSQL(Not Only SQL非关系型数据库)的性能和效果更佳,它无需固定的模式,去掉了关系数据库的关系特性,因此横向拓展容易。
- NoSQL的读写性能很高,尤其是大数据量下,得益于它的无关系型,结构简单,约每8-10万
- 无需为数据建立字段(类似于id,name等),随时可以自定义存储数据格式(键值对存储),而关系型数据库中增删表字段的开销是非常大的。
- Redis:KV+catch+persistence
二、目前NoSQL的经典应用
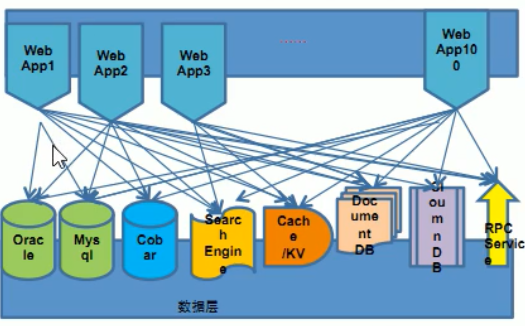
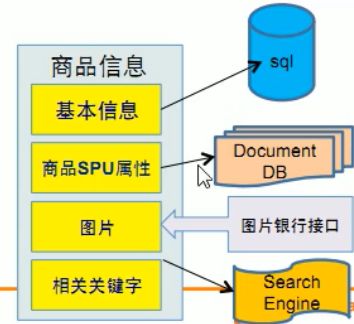
- 商品的基本信息:名称、出产日期等一般存在关系型数据库中,MySQL(淘宝中的MySQL都是自己改造的,而且去Oracle化)
- 商品描述、详情、评价等多文字:存在文档类数据库MongDB(IO读写性能差)
- 商品图片:分布式的文件系统,淘宝自己的TFS
- 商品的关键字:搜索引擎ISearch
- 商品的波段性热点高频信息:内存数据库,Tair,Redis,Memcached
- 商品的交易、价格计算:支付宝等外部接口
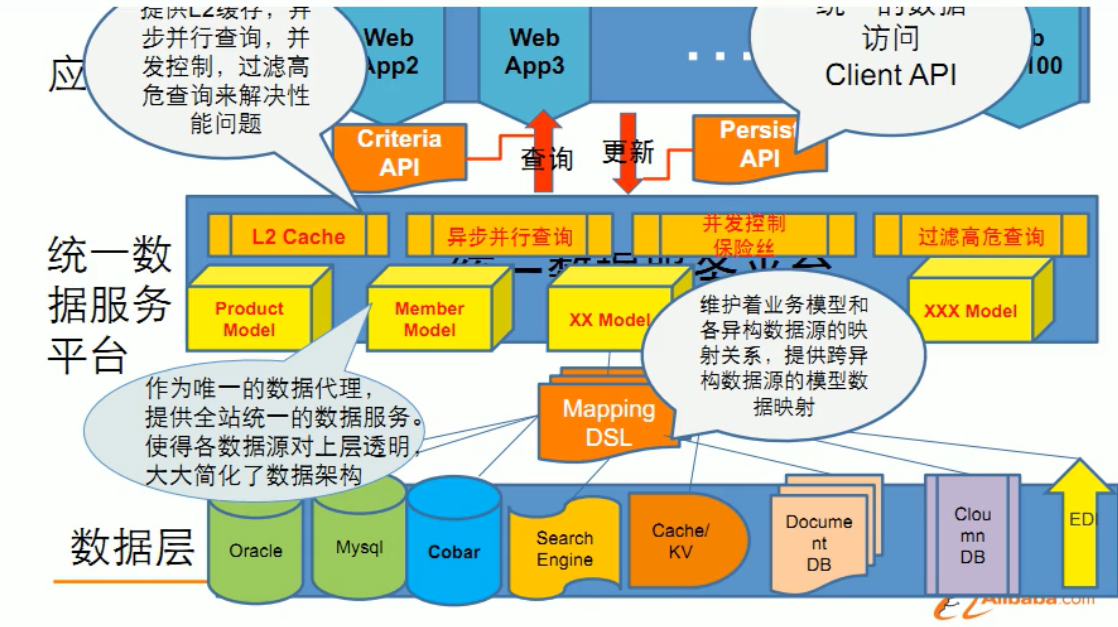
- 多数据源多数据类型:使用UDSL统一数据平台服务层,通过该层提供的API可以访问各种类型的数据库
 .
.
三、NoSQL数据类型简介
- 简单的电商平台:利用传统的关系型数据库,用户(1)->订单(n),每个订单(1)->订单项目明细(n),用户(1)->收货地址(n)。
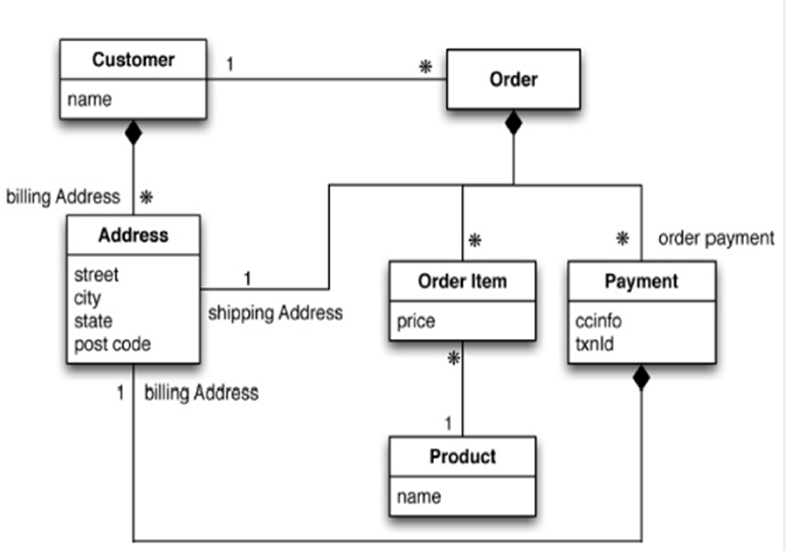
NoSQL设计:通过BSON完成(一种类JSON的二进制存储格式,简称Binary JSON,支持内嵌的文档对象和数组对象),如下可以使用聚合模型,无需外键和join等,只需要kv键值对就可以查询
{"customer":{"id":1136,"name":"Z3","billingAddress":[{"city":"beijing"}],"orders":[{"id":17,"customerId":1136,"orderItems":[{"productId":27,"price":77.5,"productName":"thinking in java"}],"shippingAddress":[{"city":"beijing"}]"orderPayment":[{"ccinfo":"111-222-333","txnid":"asdfadcd334","billingAddress":{"city":"beijing"}}],}]}}
聚合模型:kv键值对、BSON、(行键)列族、图形
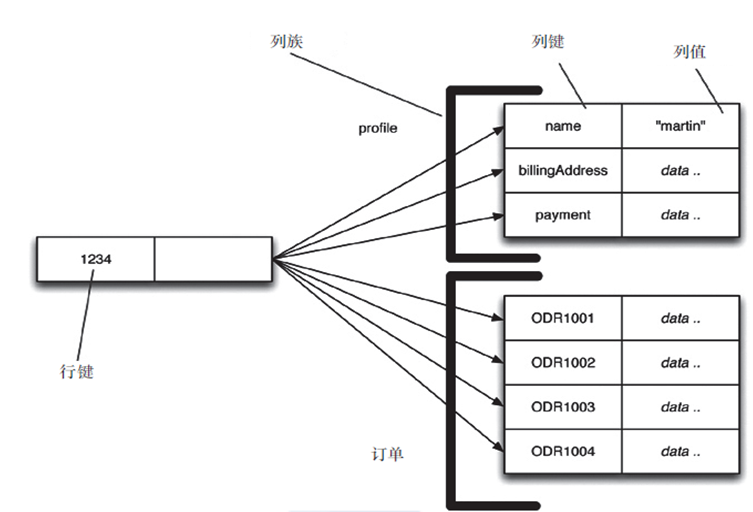
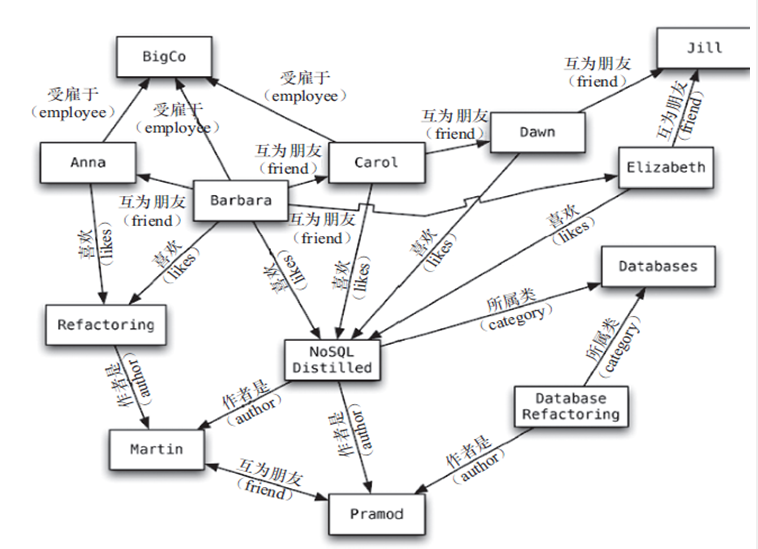
3.1 NoSQL数据库的四大分类:
- KV键值对:Redis,Oracle
- 文档型数据库(BSON格式较多):MongDB,CouchDB
- 列存储数据库:Cassandra,HBase,分布式文件系统
图关系数据库:比如朋友圈网络、广告推荐系统,Neo4J,InfoGrid
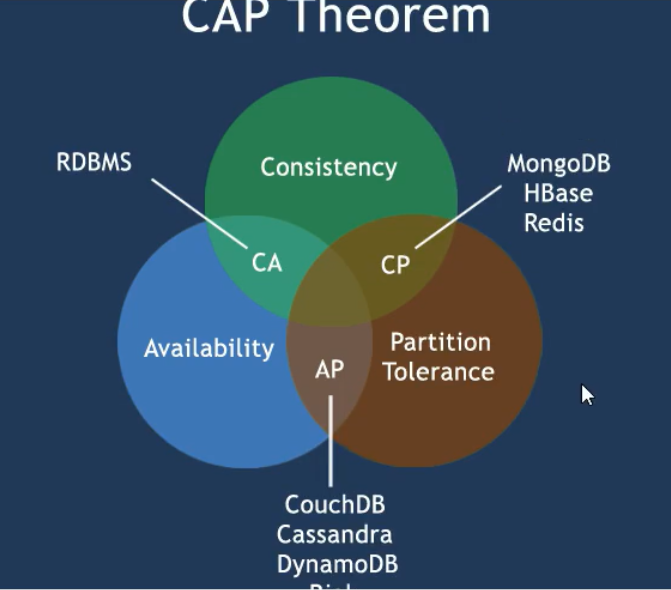
3.2 分布式数据库中CAP原理:CAP+BASE
传统的ACID
Atomicty原子性
- Consistency一致性
- Isolation隔离性
-
非关系型CAP
Consistency强一致性
- Availablity可用性
- Partition tolerance分区容错性
CAP只能满足3选2:最多只能满足两个
- CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
- CP - 满足一致性,分区容忍必的系统,通常性能不是特别高。
- AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
分区容忍性是我们必须需要实现的(分布式系统)。所以我们只能在一致性和可用性之间进行权衡,没有NoSQL系统能同时保证这三点。
- CA 传统Oracle数据库
- AP 大多数网站架构的选择
- CP Redis、Mongodb
3.3 一致性和可用性的选择(C OR A)
- 数据库事务一致性需求
- 很多web实时系统并不要求严格的数据库事务,对读一致性的要求很低, 有些场合对写一致性要求并不高。允许实现最终一致性。
- 数据库的写实时性和读实时性需求
- 对关系数据库来说,插入一条数据之后立刻查询,是肯定可以读出来这条数据的,但是对于很多web应用来说,并不要求这么高的实时性,比方说发一条消息之 后,过几秒乃至十几秒之后,我的订阅者才看到这条动态是完全可以接受的。
- 对复杂的SQL查询,特别是多表关联查询的需求
- Basically Available基本可用
- Soft state软状态
- Eventually consistent最终一致
通过让系统放松对某一时刻数据一致性的要求来换取系统整体伸缩性和性能上改观。为什么这么说呢,缘由就在于大型系统往往由于地域分布和极高性能的要求,不可能采用分布式事务来完成这些指标,要想获得这些指标,我们必须采用另外一种方式来完成,这里BASE就是解决这个问题的办法。
四、分布式和集群
4.1 分布式

若有收获,就点个赞吧
0 人点赞
