难点:获取热点数据
测试工具
使用Jemter对服务进行测试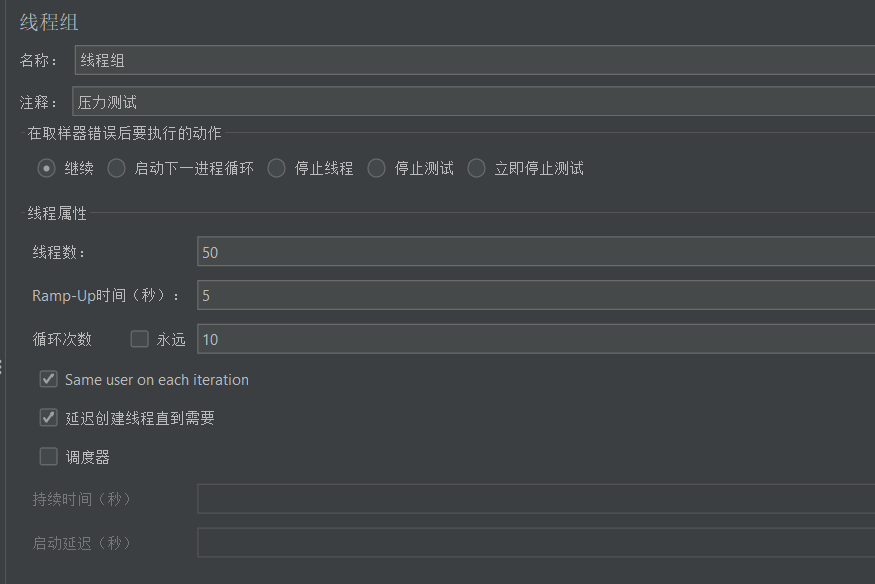
创建一组线程(500个)同时对热点数据进行压力测试。
1、原始方法
直接从数据库中查询热点数据
@Overridepublic List<CategoryVO> getAllCategories() {return categoryFromDB();}
/*** 从数据库中获取商品分类** @return 分类集合*/private List<CategoryVO> categoryFromDB() {log.info("从数据库中查询热点信息......");// 获取所有展示商品List<CategoryEntity> categories =baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("show_status", 1));// 组装树形结构并返回 平均30~40毫秒return categories.stream().map(item -> {CategoryVO categoryVO = new CategoryVO();categoryVO.setId(item.getCatId());categoryVO.setName(item.getName());// set childrencategoryVO.setChildren(getChildren(item.getCatId(), categories));return categoryVO;}).collect(Collectors.toList());}
测试结果
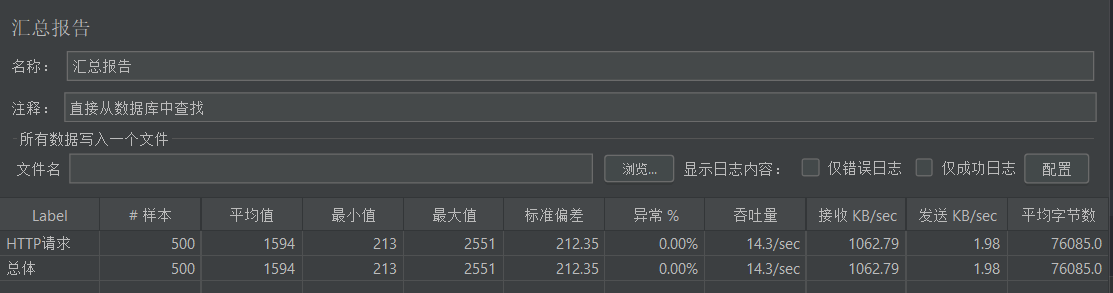
分析
通过汇总报告可以看出来性能测试每秒只有14个吞吐量,也就是说,在并发访问热点的时候,直接从数据库中进行查找,每秒只能处理14个请求。
原因:
- 由于我的数据库服务器是放在远程服务器上面的。所以在进压力测试的时候,可能由于网络带宽和网络波动导致,处理速度减缓。(即使我将这些热点数据放在本地机器上秒每秒也只有38个吞吐量。)
然而这种”优秀”的吞吐量还是基于MyBatis的缓存机,也就是说,如果没有该缓存机制,那么处理速率将会更低,甚至导致数据库的宕机。
2、改进方法
将热点数据查到之后放入Redis缓存,由于Redis有着良好的读写速率,数据先从Redis中查找,查不到之后再从数据库中查找。
// 先从缓存中查询数据,如果缓存没有则执行方法@Cacheable(value = "product:category", key = "#root.methodName")@Overridepublic List<CategoryVO> getAllCategories() {return categoryFromDB();}
算法优化
private List<CategoryEntity> categoryFromDB() {// 获取所有展示商品List<CategoryEntity> categories =baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("show_status", 1));// 组装成树形结构 --> 平均0~1msMap<Long, CategoryEntity> categoryMap = categories.stream().collect(Collectors.toMap(CategoryEntity::getCatId, v -> v));LinkedList<CategoryEntity> result = new LinkedList<>();for (CategoryEntity value : categoryMap.values()) {Long parentCid = value.getParentCid();if (parentCid != null && parentCid > 0L) {CategoryEntity pCategoryVO = categoryMap.get(parentCid);List<CategoryEntity> children = pCategoryVO.getChildren();if (children == null) {children = new LinkedList<>();}children.add(value);pCategoryVO.setChildren(children);}if (value.getCatLevel() == 1) {result.add(value);}}return result;}
将需要查找的数据放入到缓存中,避免大量的请求直接去查询数据库,可以良好的提升性能

看起来结果很完美,只有一个请求转向了数据库查询数据。这是因为在手动低速刷新浏览器的情况下,请求只有一个进来查询数据。
试想一下如果在高并发的情况下会有什么情况发生。。。。3、缓存穿透
现在我们将Redis缓存的数据删除之后,用JMeter开启500个线程模拟高并发请求。
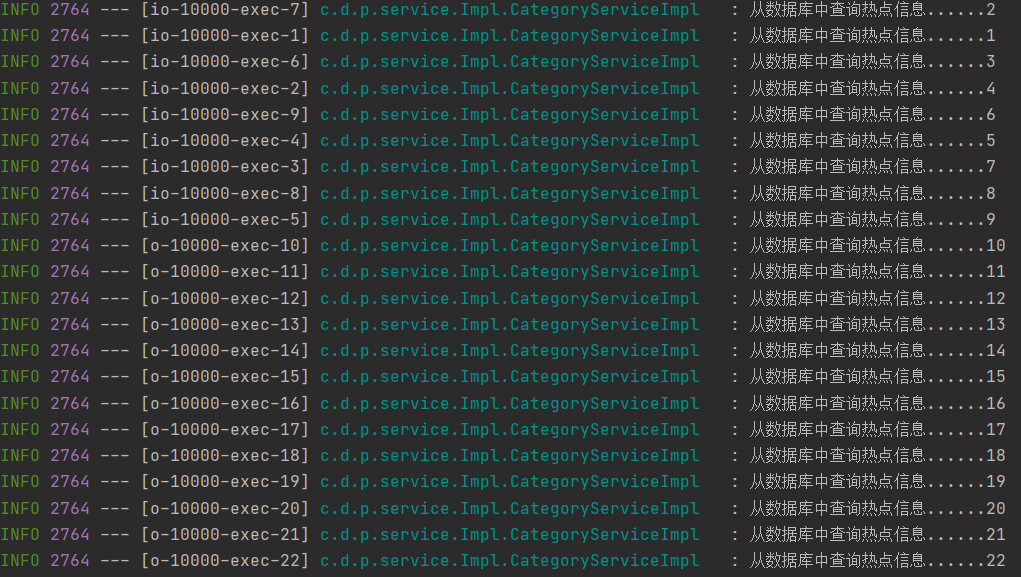
500个请求整整有22个请求穿过了缓存进而请求数据库服务器,数据库服务系统处理这22个请求还是绰绰有余的,倘若是数据高峰期(例如秒杀时期),那就不是这500个请求了,会有成千上万的请求穿过缓存直接请求数据库服务器。这就是我们需要解决的缓存穿透问题。缓存穿透概念
缓存的目的是为了缓解 CPU 或者 I/O 的压力,譬如对数据库做缓存,大部分流量都从缓存中直接返回,只有缓存未能命中的数据请求才会流到数据库中,这样数据库压力自然就减小了。但是如果查询的数据在数据库中根本不存在的话,缓存里自然也不会有,这类请求的流量每次都不会命中,每次都会触及到末端的数据库,缓存就起不到缓解压力的作用了,这种查询不存在数据的现象被称为缓存穿透。
解决方案
对于业务逻辑本身就不能避免的缓存穿透,可以约定在一定时间内对返回为空的 Key 值依然进行缓存(注意是正常返回但是结果为空,不应把抛异常的也当作空值来缓存了),使得在一段时间内缓存最多被穿透一次。如果后续业务在数据库中对该 Key 值插入了新记录,那应当在插入之后主动清理掉缓存的 Key 值。如果业务时效性允许的话,也可以将对缓存设置一个较短的超时时间来自动处理。
对于恶意攻击导致的缓存穿透,通常会在缓存之前设置一个布隆过滤器来解决。所谓恶意攻击是指请求者刻意构造数据库中肯定不存在的 Key 值,然后发送大量请求进行查询。布隆过滤器是用最小的代价来判断某个元素是否存在于某个集合的办法。如果布隆过滤器给出的判定结果是请求的数据不存在,那就直接返回即可,连缓存都不必去查。虽然维护布隆过滤器本身需要一定的成本,但比起攻击造成的资源损耗仍然是值得的。
缓存击穿
我们都知道缓存的基本工作原理是首次从真实数据源加载数据,完成加载后回填入缓存,以后其他相同的请求就从缓存中获取数据,缓解数据源的压力。如果缓存中某些热点数据忽然因某种原因失效了,譬如典型地由于超期而失效,此时又有多个针对该数据的请求同时发送过来,这些请求将全部未能命中缓存,都到达真实数据源中去,导致其压力剧增,这种现象被称为缓存击穿。要避免缓存击穿问题,通常会采取下面的两种办法:
加锁同步,以请求该数据的 Key 值为锁,使得只有第一个请求可以流入到真实的数据源中,其他线程采取阻塞或重试策略。如果是进程内缓存出现问题,施加普通互斥锁即可,如果是分布式缓存中出现的问题,就施加分布式锁,这样数据源就不会同时收到大量针对同一个数据的请求了。
热点数据由代码来手动管理,缓存击穿是仅针对热点数据被自动失效才引发的问题,对于这类数据,可以直接由开发者通过代码来有计划地完成更新、失效,避免由缓存的策略自动管理。
缓存雪崩
缓存击穿是针对单个热点数据失效,由大量请求击穿缓存而给真实数据源带来压力。有另一种可能是更普遍的情况,不需要是针对单个热点数据的大量请求,而是由于大批不同的数据在短时间内一起失效,导致了这些数据的请求都击穿了缓存到达数据源,同样令数据源在短时间内压力剧增。
出现这种情况,往往是系统有专门的缓存预热功能,也可能大量公共数据是由某一次冷操作加载的,这样都可能出现由此载入缓存的大批数据具有相同的过期时间,在同一时刻一起失效。还有一种情况是缓存服务由于某些原因崩溃后重启,此时也会造成大量数据同时失效,这种现象被称为缓存雪崩。要避免缓存雪崩问题,通常会采取下面的三种办法:提升缓存系统可用性,建设分布式缓存的集群。
- 启用透明多级缓存,各个服务节点一级缓存中的数据通常会具有不一样的加载时间,也就分散了它们的过期时间。
- 将缓存的生存期从固定时间改为一个时间段内的随机时间,譬如原本是一个小时过期,那可以缓存不同数据时,设置生存期为 55 分钟到 65 分钟之间的某个随机时间。
缓存污染
缓存污染是指缓存中的数据与真实数据源中的数据不一致的现象。尽管笔者在前面是说过缓存通常不追求强一致性,但这显然不能等同于缓存和数据源间连最终的一致性都可以不要求了。
缓存污染多数是由开发者更新缓存不规范造成的,譬如你从缓存中获得了某个对象,更新了对象的属性,但最后因为某些原因,譬如后续业务发生异常回滚了,最终没有成功写入到数据库,此时缓存的数据是新的,数据库中的数据是旧的。为了尽可能的提高使用缓存时的一致性,已经总结不少更新缓存可以遵循设计模式,譬如 Cache Aside、Read/Write Through、Write Behind Caching 等。其中最简单、成本最低的 Cache Aside 模式是指:
- 读数据时,先读缓存,缓存没有的话,再读数据源,然后将数据放入缓存,再响应请求。
- 写数据时,先写数据源,然后失效(而不是更新)掉缓存。
读数据方面一般没什么出错的余地,但是写数据时,就有必要专门强调两点:一是先后顺序是先数据源后缓存。试想一下,如果采用先失效缓存后写数据源的顺序,那一定存在一段时间缓存已经删除完毕,但数据源还未修改完成,此时新的查询请求到来,缓存未能命中,就会直接流到真实数据源中。这样请求读到的数据依然是旧数据,随后又重新回填到缓存中。当数据源的修改完成后,结果就成了数据在数据源中是新的,在缓存中是老的,两者就会有不一致的情况。另一点是应当失效缓存,而不是去尝试更新缓存,这很容易理解,如果去更新缓存,更新过程中数据源又被其他请求再次修改的话,缓存又要面临处理多次赋值的复杂时序问题。所以直接失效缓存,等下次用到该数据时自动回填,期间无论数据源中的值被改了多少次都不会造成任何影响。
Cache Aside 模式依然是不能保证在一致性上绝对不出问题的,否则就无须设计出Paxos这样复杂的共识算法了。典型的出错场景是如果某个数据是从未被缓存过的,请求会直接流到真实数据源中,如果数据源中的写操作发生在查询请求之后,结果回填到缓存之前,也会出现缓存中回填的内容与数据库的实际数据不一致的情况。但这种情况的概率是很低的,Cache Aside 模式仍然是以低成本更新缓存,并且获得相对可靠结果的解决方案。

若有收获,就点个赞吧
0 人点赞
