https://lonepatient.top/2019/01/09/BERT-self-Attention.html
本系列文章希望对 google BERT 模型做一点解读。打算采取一种由点到线到面的方式,从基本的元素讲起,逐渐展开。
讲到 BERT 就不能不提到 Transformer,而 self-attention 则是 Transformer 的精髓所在。简单来说,可以将 Transformer 看成和 RNN 类似的特征提取器,而其有别于 RNN、CNN 这些传统特征提取器的是,它另辟蹊径,采用的是 attention 机制对文本序列进行特征提取。
所以我们从 self-Attention 出发。
Attention is all your need
尽管 attention 机制由来已久,但真正令其声名大噪的是 google 2017 年的这篇名为《attention is all your need》的论文。
让我们从一个简单的例子看起:
假设我们想用机器翻译的手段将下面这句话翻译成中文:
“The animal didn’t cross the street because it was too tired”
当机器读到 “it” 时,“it”代表 “animal” 还是 “street” 呢?对于人类来讲,这是一个极其简单的问题,但是对于机器或者说算法来讲却十分不容易。
self-Attention 则是处理此类问题的一个解决方案,也是目前看起来一个比较好的方案。当模型处理到 “it” 时,self-Attention 可以将 “it” 和“animal‘联系到一起。
它是怎么做到的呢?
通俗地讲,当模型处理一句话中某一个位置的单词时,self-Attention 允许它看一看这句话中其他位置的单词,看是否能够找到能够一些线索,有助于更好地表示(或者说编码)这个单词。
如果你对 RNN 比较熟悉的话,我们不妨做一个比较。RNN 通过保存一个隐藏态,将前面词的信息编码后依次往后面传递,达到利用前面词的信息来编码当前词的目的。而 self-Attention 仿佛有个上帝之眼,纵观全局,看看上下文中每个词对当前词的贡献。
[
]
下面来看下具体是怎么实现的。
Self-Attention in Detail
首先,来看下怎样使用向量来计算 self-attention,紧接着看如何用矩阵来计算 self-attention。
使用向量
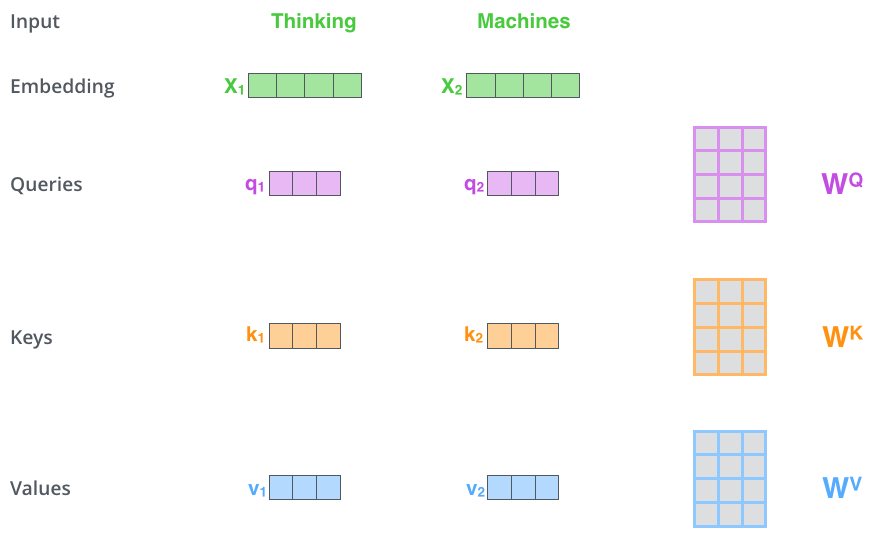
如下图所示,一般而言,输入的句子进入模型的第一步是对单词进行 embedding,每个单词对应一个 embedding。对于每个 embedding,我们创建三个向量,Query、Key 和 Value 向量。我们如何来创建三个向量呢?如图,我们假设 embedding 的维度为 4,我们希望得到一个维度为 3 的 Query、Key 和 Value 向量,只需将每个 embedding 乘上一个维度为 4*3 的矩阵即可。这些矩阵就是训练过程中要学习的。
[
]
那么,Query、Key 和 Value 向量代表什么呢?他们在 attention 的计算中发挥了什么样的作用呢?
我们用一个例子来说明:
首先要明确一点,self-attention 其实是在计算每个单词对当前单词的贡献,也就是对每个单词对当前单词的贡献进行打分 score。假设我们现在要计算下图中所有单词对第一个单词 “Thinking” 的打分。那么分分数如何计算呢,只需要将该单词的 Query 向量和待打分单词的 Key 向量做点乘即可。比如,第一个单词对第一个单词的分数为 q1× k1,第二个单词对第一个单词的分数为 q1×k2。
[
]
我们现在得到了两个单词对第一个单词的打分(分数是个数字了),然后将其进行 softmax 归一化。需要注意的是,在 BERT 模型中,作者在 softmax 之前将分数除以了 Key 的维度的平方根(据说可以保持梯度稳定)。softmax 得到的是每个单词在 Thinking 这个单词上的贡献的权重。显然,当前单词对其自身的贡献肯定是最大的。
接着就是 Value 向量登场的地方了。将上面的分数分别和 Value 向量相乘,注意这里是对应位置相乘。

最后,将相乘的结果求和,这就得到了 self-attention 层对当前位置单词的输出。对每个单词进行如上操作,就能得到整个句子的 attention 输出了。在实际使用过程中,一般采用矩阵计算使整个过程更加高效。
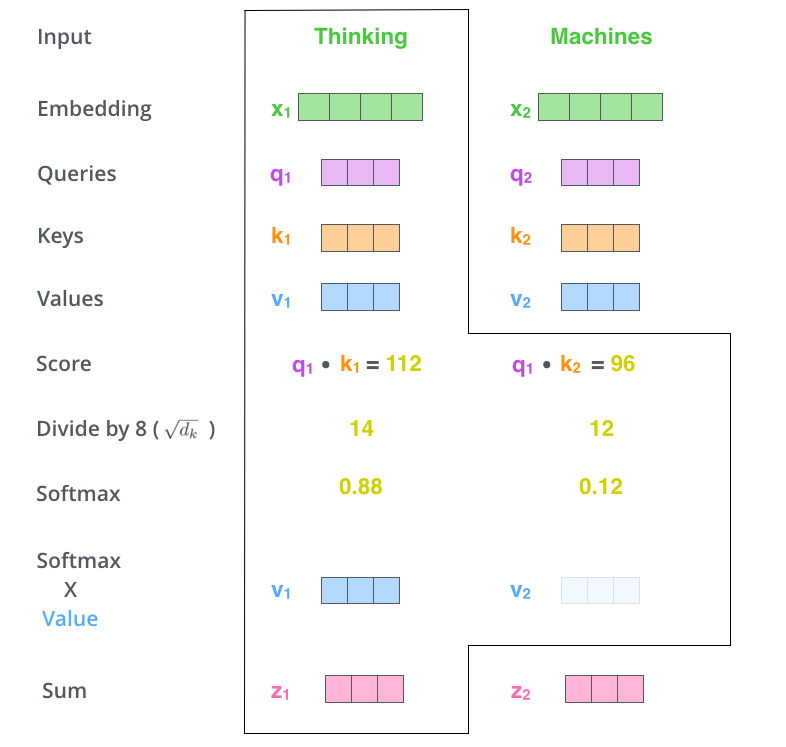
在开始矩阵计算之前,先回顾总结一下上面的步骤:
- 创建 Query、Key、Value 向量
- 计算每个单词在当前单词的分数
- 将分数归一化后与 Value 相乘
- 求和
值得注意的是,上面阐述的过程实际上是 Attention 机制的计算流程,对于 self-Attention,Query=Value。
Matrix Calculation of Self-Attention
其实矩阵计算就是将上面的向量放在一起,同时参与计算。
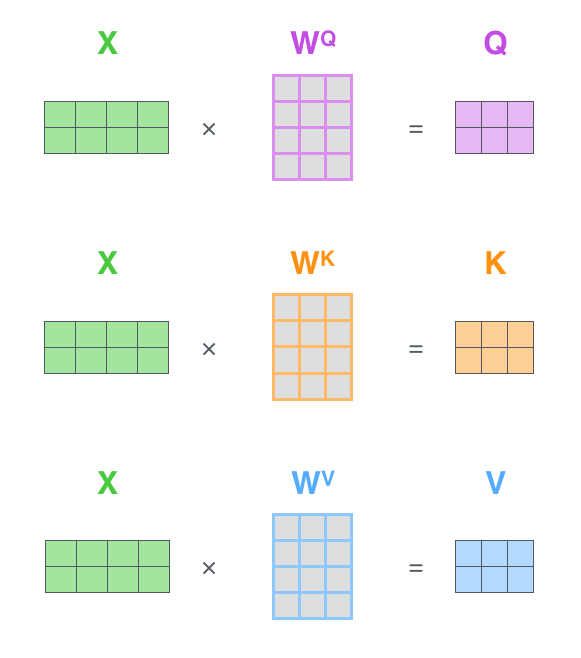
首先,将 embedding 向量 pack 成一个矩阵 X。假设我们有一句话有长度为 10,embedding 维度为 4,那么 X 的维度为(10 × 4).
[
]
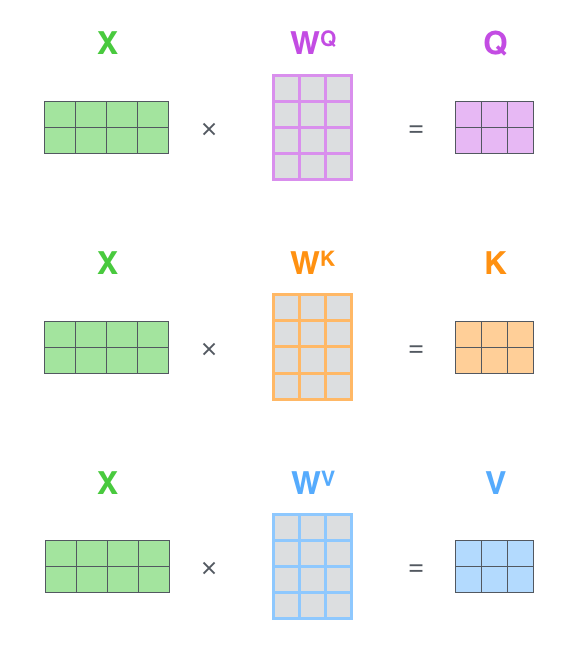
假设我们设定 Q、K、V 的维度为 3. 第二步我们构造一个维度为(4×3)的权值矩阵。将其与 X 做矩阵乘法,得到一个 10×3 的矩阵,这就能得到 Query 了。依样画葫芦,同样可以得到 Key 和 Value。
[
]
最后,将 Query 和 Key 相乘,得到打分,然后经过 softmax,接着乘上 V 的到最终的输出。
[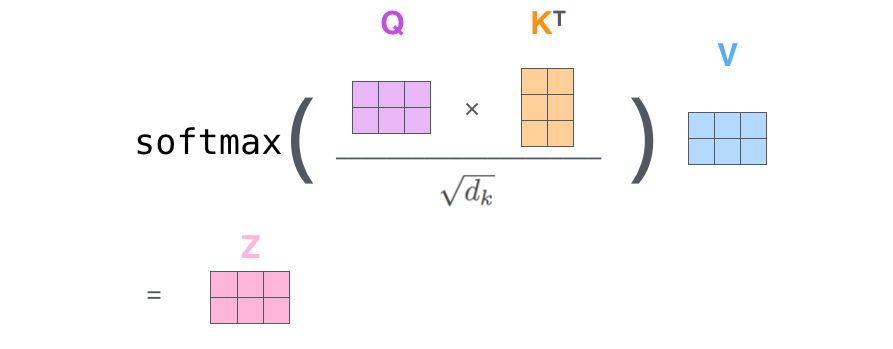
]
文章内容参考https://jalammar.github.io/illustrated-transformer/.
jalammar 的博客十分通俗易懂,且切中要害,本系列内容不乏很多翻译自 jalammar 的博客。
https://lonepatient.top/2019/01/09/BERT-self-Attention.html

若有收获,就点个赞吧
0 人点赞
