深度网络的公理归因
【如何高效读论文?】
前提:尽量不被打断思路。意味着不要看手机胡思乱想。思想集中一段时间。
操作:
- 首先 Abstract Introduction 对论文的总体有个大致的思路,比如为了解决什么问题,提出什么算法。此时不需要了解算法具体实现。以及现有算法的缺陷等等。
- 论文实验部分,用了什么数据,证明了什么东西。
- 细看算法,主要包括现有算法的优缺点和提出的新算法。
- 新算法的正确性。和实验部分对比观看。
本文形成顺序 摘要 -> 目录 -> 8 结论 -> 6 应用 ->
摘要
我们研究了将深度网络的预测归因于其输入特征的问题,这是先前由其他几篇著作进行研究的问题。 我们确定了归因方法应满足的两个基本公理-敏感性和实现不变性。 我们表明,大多数已知的归因方法都不满足他们的要求,我们认为这是这些方法的根本缺陷。 我们使用公理来指导称为集成梯度的新归因方法的设计。 我们的方法不需要修改原始网络,实现起来非常简单。 它只需要对标准梯度运算符的几个调用即可。 我们将此方法应用于几个图像模型,几个文本模型和一个化学模型,证明了其调试网络,从网络中提取规则以及使用户能够更好地参与模型的能力。
主要目标,解决深度网络解释问题,提出新的基本公理敏感性和实现不变性,指出现有算法的根本缺陷,提出新算法IG 集成梯度。
目录
1动机和起因,2两个基本公理,3IG,4面临的挑战,很难实证评估,5,6IG对DL的适用性
2 两个基本公理
我们现在讨论两个公理(理想特性)的归因方法,我们发现文献中的其他特征归因方法至少打破了两个公理中的一个。比如DeepLIFT,Layer-wise relevance propagation, Deconvolutional networks, Guided back-propagation。 正如我们将在第3节中看到的,这些公理也将指导我们的方法的设计。
2.1 灵敏度(a)
【输入的函数值与基线值不同的情况下应该非0归因】
如果一个特征的每一个输入和基线都不相同的情况下,预测都不同,那么这个特征应该被赋予非零归因。
如果对一个特征不同但预测不同的每个输入和基线,则一种归因方法满足敏感度(a),则应为不同的特征赋予非零归因。 (本文稍后,我们将在此定义的一部分(b)。)
梯度违反了灵敏度(敏感度)(a):
对于一个具体的例子,考虑一个变量,一个ReLU网络, 。 假设基线为x=0,输入为x=2.. 函数从0变为1,但是由于f在x = 1处变得平坦,因此梯度方法将x的属性归因于0。 从直觉上看,梯度会破坏敏感性,因为预测函数可能会在输入时变平因此梯度为零,尽管 输入处的函数值与基线处的函数值不同。 这一现象在以前的工作中已有报道。
。 假设基线为x=0,输入为x=2.. 函数从0变为1,但是由于f在x = 1处变得平坦,因此梯度方法将x的属性归因于0。 从直觉上看,梯度会破坏敏感性,因为预测函数可能会在输入时变平因此梯度为零,尽管 输入处的函数值与基线处的函数值不同。 这一现象在以前的工作中已有报道。
实际上,由于缺乏敏感性,梯度会集中于不相关的特征。(见图中的“消防船”图2)
其他基于反向传播的方法。 第二组方法涉及反向传播最终预测分数通过网络的每一层向下到单个特征。 包括深度提升,分层相关性传播(LRP),反卷积网络和引导反向传播(DeepLift, Layer-wise
relevance propagation (LRP), Deconvolutional networks
(DeConvNets), and Guided back-propagation.
)。这些方法在不同激活函数的具体反向传播逻辑上有所不同(如ReLU、Max Pool等)。
2.2 实现不变性
两个网络在功能上是等价的,如果它们的输出对所有输入都是相等的,尽管它们的实现非常不同。归因方法应满足实现不变性,即,对于两个功能等效的网络归因始终相同。为此,请注意,归因可以定义为将输出的责任(或功劳)分配给输入要素。这样的定义未涉及实现细节。
我们现在讨论为什么深度提升DeepLIFT和LRP没有实现不变性的直觉;附录B提供了一个具体的例子。
首先,梯度计算是满足不变性的。链式规则 实现不变性的关键,将f、g看作是输入输出,h则是一个解释系统的细节。那么输入对输出的梯度可以直接通过
实现不变性的关键,将f、g看作是输入输出,h则是一个解释系统的细节。那么输入对输出的梯度可以直接通过 来计算而与h无关,这正是反向传播如何工作的。像LRP和DeepLift这样的方法将梯度替换为离散梯度,并且仍然使用一种改进的反向传播形式来将离散梯度组合属性。不幸的是,链式规则一般不适用于离散梯度。正式的,
来计算而与h无关,这正是反向传播如何工作的。像LRP和DeepLift这样的方法将梯度替换为离散梯度,并且仍然使用一种改进的反向传播形式来将离散梯度组合属性。不幸的是,链式规则一般不适用于离散梯度。正式的, 。因此这些方法不满足不变性。
。因此这些方法不满足不变性。
如果属性方法不能满足实现不变性,则属性可能对模型的不重要方面敏感。 例如,如果网络体系结构具有比表示函数所需的更多自由度,那么网络参数可能有两组值。 训练过程可以根据初始状态或其他原因收敛到任意一组值,但底层网络函数将保持不变。 由于这些原因,归属不同是不可取的。
3 Integrated Gradients
我们现在准备描述我们的技术。 直观地说,我们的技术结合了梯度的实现不变以及LRP或DeepLIFT等技术的灵敏度。
形式上,假设我们有一个函数 表示一个Deep Network。 具体地,设
表示一个Deep Network。 具体地,设 是手头的(眼前的)输入,
是手头的(眼前的)输入, 是基线输入。 对于图像网络,基地 行可以是黑色图像,而对于文本模型,它可以是零嵌入向量。
是基线输入。 对于图像网络,基地 行可以是黑色图像,而对于文本模型,它可以是零嵌入向量。
我们考虑从基线x’到输入x的直线路径(in  ),计算路径上所有点的梯度。集成梯度(IG)是通过累积这些梯度得到的。具体而言,积分梯度(IG)定义为沿从基线x到输入x的直线路径的梯度的路径积分。
),计算路径上所有点的梯度。集成梯度(IG)是通过累积这些梯度得到的。具体而言,积分梯度(IG)定义为沿从基线x到输入x的直线路径的梯度的路径积分。
输入x和基线x’沿 维的积分梯度定义如下。 这里,
维的积分梯度定义如下。 这里, 是F(X)沿维的梯度。
是F(X)沿维的梯度。
实际上是爬楼梯式的沿 路径走向
路径走向
公理:完整性
IG满足公理完整性completeness,属性(attributions 或译为归因?)加起来等于F在输入x处的输出与基线x’之间的差值,这条公理被Deeplift和LRP确定为可取的。归因法在会计核算中具有一定的综合性,这是一种明智的检查。如果网络评分是在数字意义上使用的,而不仅仅是为了选择顶部标签,那么将明显是一个理想符合预期的模型,例如,从个人信用特征估计保险费的模型。这是由下面的命题形式化的,它实例化了路径积分的微积分基本定理。
提议1
如果 几乎处处可微,那么有
几乎处处可微,那么有
对于大多数深度网络,可以选择一个基线,使基线的预测接近零( )。(对于图像模型,黑色图像基线满足此属性。)在这种情况下,对由此产生的属性的解释忽略了基线,等于将输出分配给单个输入特征。
)。(对于图像模型,黑色图像基线满足此属性。)在这种情况下,对由此产生的属性的解释忽略了基线,等于将输出分配给单个输入特征。
备注2
集成梯度满足灵敏度(a),因为完整性意味着灵敏度(a),因此是灵敏度(a)公理的加强。 这是因为敏感性(a)指的是一种情况基线和输入仅在一个变量中不同,为此,完整性要求两个输出值之差等于该变量的归因。 集成梯度生成的归因满足实现不变性,因为它们仅基于网络代表的函数的梯度。
4 集成梯度的唯一性
先前的文献依赖于实证评估归因技术。 例如,在对象识别任务的背景下,(Samek等人,2015年)建议我们选择顶部k像素通过归因和随机改变它们的强度,然后测量分数的下降。 如果归因方法好,那么分数的下降应该很大。 但是,由 像素扰动可能是不自然的,这可能是分数下降,仅仅是因为网络从来没有训练中看到过类似的东西。 (这与线性或逻辑关系不太相关 模型的简单性确保消融一个特征不会引起奇怪的交互。)
一种不同的评估技术考虑了物体周围有人绘制的边界框的图像,并计算了盒子内像素归属的百分比。 对于大多数物体来说, 将位于对象上的像素划分为最重要的预测,在某些情况下,对象发生的上下文也可能有助于预测。 白菜蝴蝶形象f 图2是一个很好的例子,其中叶子上的像素也被集成梯度所覆盖.
粗略地说,我们发现我们所能想到的每一种经验评估技术都无法区分干扰数据、行为不当模型和行为不当归因方法的伪装。 这就是为什么我们在设计一个好的归因方法时采用了公理化的方法( 2)。 虽然我们的方法满足灵敏度和实现不变性,但它当然不是唯一的方法。
我们现在证明了在两个步骤中选择集成梯度方法的合理性。 首先,我们确定了一类称为路径方法的方法,这些方法推广集成梯度。 我们讨论路径方法是满足某些理想公理的唯一方法。 其次,我们为什么认为集成梯度在不同的路径方法中是典型(权威)的。
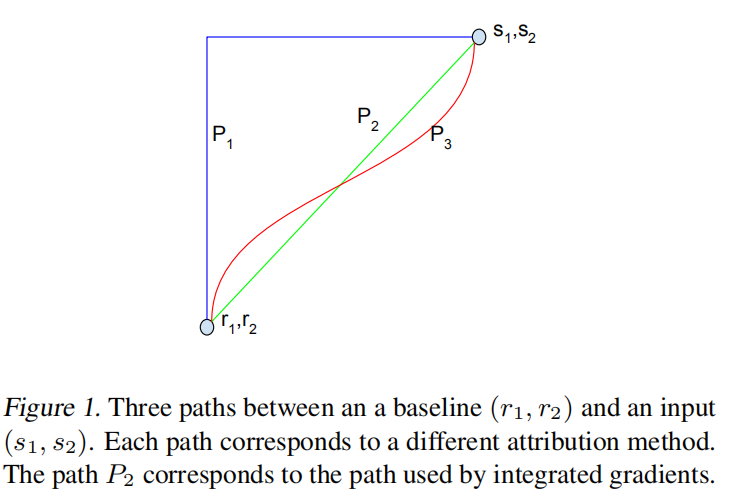
4.1 路径方法
4.2 IG是对称-保持
在这一部分中,我们形式化了为什么由集成梯度选择的直线路径是规范(权威 canonical)的。 首先,观察这是人们可以数学定义的一条最简单的路径,其次,归因方法的自然属性是在以下意义上保持对称性。
5 应用集成梯度
选择基线
计算集成梯度/积分梯度
可以通过求和有效地近似积分梯度的积分。 我们简单地将在从基线x0到输入x的直线路径上足够小的间隔。
应用黎曼积分
在实践中,我们发现20到300步之间的某个值足以逼近积分(在5%以内)。 我们建议开发人员检查归因是否大致加起来等于输入得分与基线得分之间的差异(请参见建议1),如果没有,则增加步长m。
6 应用
集成梯度技术适用于各种深层网络。 在这里,我们将其应用于两个图像模型、两个自然语言模型和一个化学模型。
更多例子
从集成梯度获得的可视化更好地反映图像的独特特征
【个人理解】IG貌似学到了边缘化的特征~~ 。
8 结论
本文的主要贡献是一种称为集成梯度的方法,它将深度网络的预测归因于其输入。 它可以使用一些梯度调用来实现 算子,可应用于各种深层网络,具有很强的理论依据。
本文的第二个贡献是利用一个公理框架来澄清归因方法的可取特征,该框架是由来自经济学的费用分摊文献启发的。 如果没有公理方法很难判断属性方法是否受到数据伪影、网络伪影或方法伪影的影响。 公理化方法排除了最后一种类型的工作。(应该是指去掉了不同方法的影响)
虽然我们的工作和其他工作在理解深度网络中输入特征的相对重要性方面取得了一些进展,但我们还没有讨论输入特征之间的相互作用,深度网络使用的逻辑。 因此,在调试深层网络的I/O行为方面,还有许多未解决的问题。
感谢ACKNOWLEDGMENTS
END
模型解释的优点
Benefits:
● Debug and understand models
● Build trust in the model
● Surface an explanation to the end-user
● Intellectual curiosity
好处:
●调试和了解模型
●建立对模型的信任
●向最终用户说明
●求知欲

若有收获,就点个赞吧
0 人点赞
