TLD算法由三个模块组成:追踪器、检测器、学习模块。<br /> 追踪器的作用是跟踪连续帧间的运动,当物体始终可见时跟踪器才会有效。追踪器根据物体在前一帧已知的位置估计在当前帧的位置,这样就会产生一条物体运动的轨迹,从这条轨迹可以为学习模块产生正样本(Tracking->Learning)。<br /> 检测器的作用是估计追踪器的误差,如果误差很大就改正追踪器的结果。检测器对每一帧图像都做全面的扫描,找到与目标物体相似的所有外观的位置,从检测产生的结果中产生正样本和负样本,交给学习模块(Detection->Learning)。算法从所有正样本中选出一个最可信的位置作为这一帧TLD的输出结果,然后用这个结果更新追踪器的起始位置(Detection->Tracking)。<br /> 学习模块根据追踪器和检测器产生的正负样本,迭代训练分类器,改善检测器的精度(Learning->Detection)。
1、追踪器模块
TLD算法规定了任意一个追踪器的FB误差(forward-backward error):从时间t的初始位置x(t)开始追踪产生时间t+p的位置x(t+p),再从位置x(t+p)反向追踪产生时间t的预测位置x`(t),初始位置和预测位置之间的欧氏距离就作为追踪器在t时间的FB误差。<br />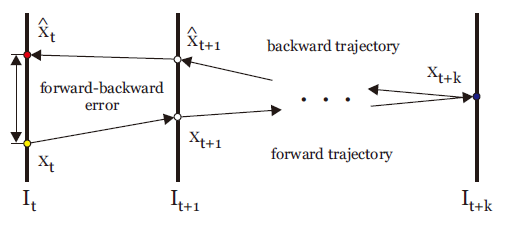首先在上一帧t的物体包围框里均匀地产生一些点,然后用Lucas-Kanade光流追踪器正向追踪这些点到t+1帧,再反向追踪到t帧,计算FB误差,筛选出FB误差最小的一半点作为最佳追踪点。最后根据这些点的坐标变化和距离的变化计算t+1帧包围框的位置和大小。计算时采用取中值的光流法。
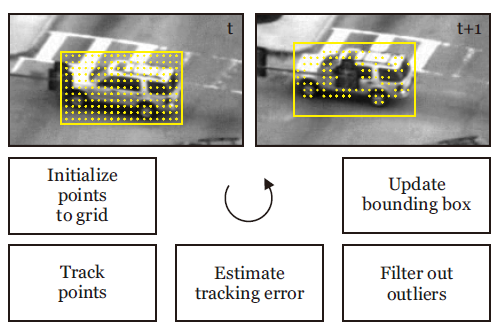
2、学习器模块
TLD使用的机器学习方法是作者提出的P-N学习(P-N Learning)。P专家(P-expert):检出漏检(false negative,正样本误分为负样本)的正样本;N专家(N-expert):改正误检(false positive,负样本误分为正样本)的正样本。<br /> 用不同尺寸的扫描窗(scanning grid)对图像进行逐行扫描,每在一个位置就形成一个包围框(bounding box),包围框所确定的图像区域称为一个图像元(patch),图像元进入机器学习的样本集就成为一个样本。扫描产生的样本是未标签样本,需要用分类器来分类,确定它的标签。<br /> 如果算法已经确定物体在t+1帧的位置(实际上是确定了相应包围框的位置),从检测器产生的包围框中筛选出10个与它距离最近的包围框(两个包围框的交的面积除以并的面积大于0.7),对每个包围框做微小的仿射变换(平移10%、缩放10%、旋转10°以内),产生20个图像元,这样就产生200个正样本。再选出若干距离较远的包围框(交的面积除以并的面积小于0.2),产生负样本。这样产生的样本是已标签的样本,把这些样本放入训练集,用于更新分类器的参数。下图中的a图展示的是扫描窗的例子。<br /> P专家的作用是寻找数据在时间上的结构性,它利用追踪器的结果预测物体在t+1帧的位置。如果这个位置(包围框)被检测器分类为负,P专家就把这个位置改为正。也就是说P专家要保证物体在连续帧上出现的位置可以构成连续的轨迹;<br />N专家的作用是寻找数据在空间上的结构性,它把检测器产生的和P专家产生的所有正样本进行比较,选择出一个最可信的位置,保证物体最多只出现在一个位置上,把这个位置作为TLD算法的追踪结果。同时这个位置也用来重新初始化追踪器。<br /><br /> 在这个例子中,目标车辆是下面的深色车,每一帧中黑色框是检测器检测到的正样本,黄色框是追踪器产生的正样本,红星标记的是每一帧最后的追踪结果。在第t帧,检测器没有发现深色车,但P专家根据追踪器的结果认为深色车也是正样本,N专家经过比较,认为深色车的样本更可信,所以把浅色车输出为负样本。第t+1帧的过程与之类似。第t+2帧时,P专家产生了错误的结果,但经过N专家的比较,又把这个结果排除了,算法仍然可以追踪到正确的车辆。
3、检测器模块
检测器是追踪器的监督者,因为检测器要改正追踪器的错误;而追踪器是训练检测器时的监督者,因为要用追踪器的结果对检测器的分类结果进行监督。用另一段程序对训练过程进行监督,而不是由人来监督,这也是称P-N学习为“半监督”机器学习的原因。<br /> 检测模块使用一个级联分类器,对从包围框获得的样本进行分类。级联分类器包含三个级别:<br /> 图像元方差分类器(Patch Variance Classifier)。计算图像元像素灰度值的方差,把方差小于原始图像元方差一半的样本标记为负。论文提到在这一步可以排除掉一半以上的样本。<br /> 集成分类器(Ensemble Classifier)。实际上是一个随机蕨分类器(Random Ferns Classifier),类似于随机森林(Random Forest),区别在于随机森林的树中每层节点判断准则不同,而随机蕨的“蕨”中每层只有一种判断准则。<br />从图像元中任意选取两点A和B,比较这两点的亮度值,若A的亮度大于B,则特征值为1,否则为0。每选取一对新位置,就是一个新的特征值。蕨的每个节点就是对一对像素点进行比较。比如取5对点,红色为A,蓝色为B,样本图像经过含有5个节点的蕨,每个节点的结果按顺序排列起来,得到长度为5的二进制序列01011,转化成十进制数字11。这个11就是该样本经过这个蕨得到的结果。<br /><br /> 不同类的样本经过同一个蕨,得到不同的先验概率分布。<br />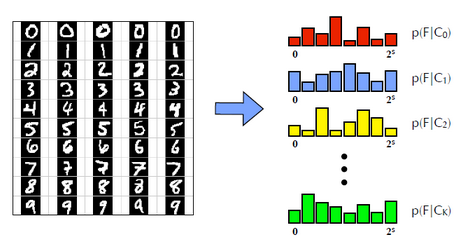<br /> 当有新的未标签样本加入时,假设它经过这个蕨的结果为00011(即3),然后从已知的分布中寻找后验概率最大的一个。由于样本集固定时,右下角公式的分母是相同的,所以只要找在F=3时高度最大的那一类,就是新样本的分类。
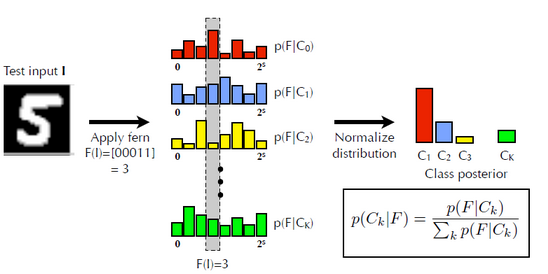
最近邻分类器(Nearest Neighbor Classifier)。计算新样本的相对相似度,如大于0.6,则认为是正样本。
图像元pi和pj的相似度规定如下,公式里的N是规范化的相关系数,所以S的取值范围就在[0,1]之间。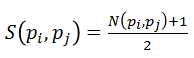
4、TLD总体流程
TLD的工作流程如下图所示。首先,检测器由一系列包围框产生样本,经过级联分类器产生正样本,放入样本集;然后使用追踪器估计出物体的新位置,P专家根据这个位置又产生正样本,N专家从这些正样本里选出一个最可信的,同时把其他正样本标记为负;最后用正样本更新检测器的分类器参数,并确定下一帧物体包围框的位置。<br />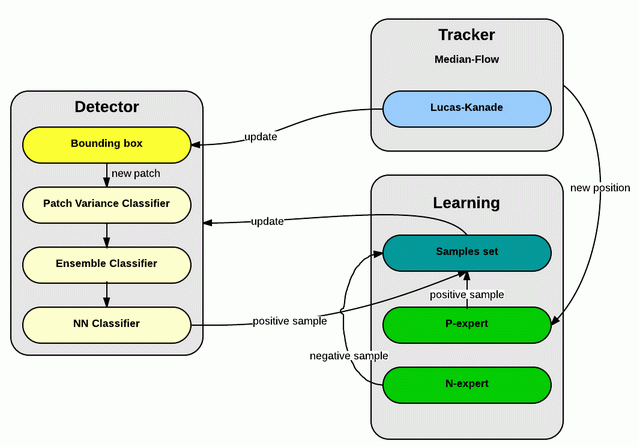

若有收获,就点个赞吧
0 人点赞
