
 ">
">

 ">
">





1.实战
练习:线性回归




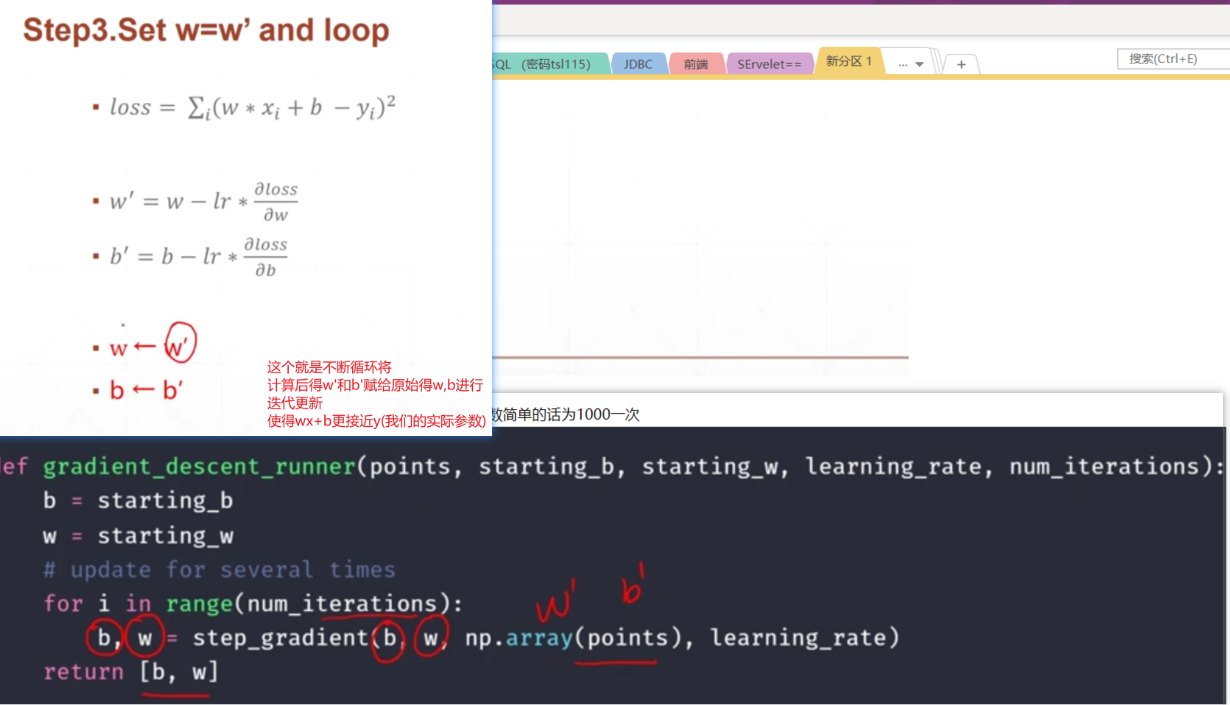
具体的代码部分:
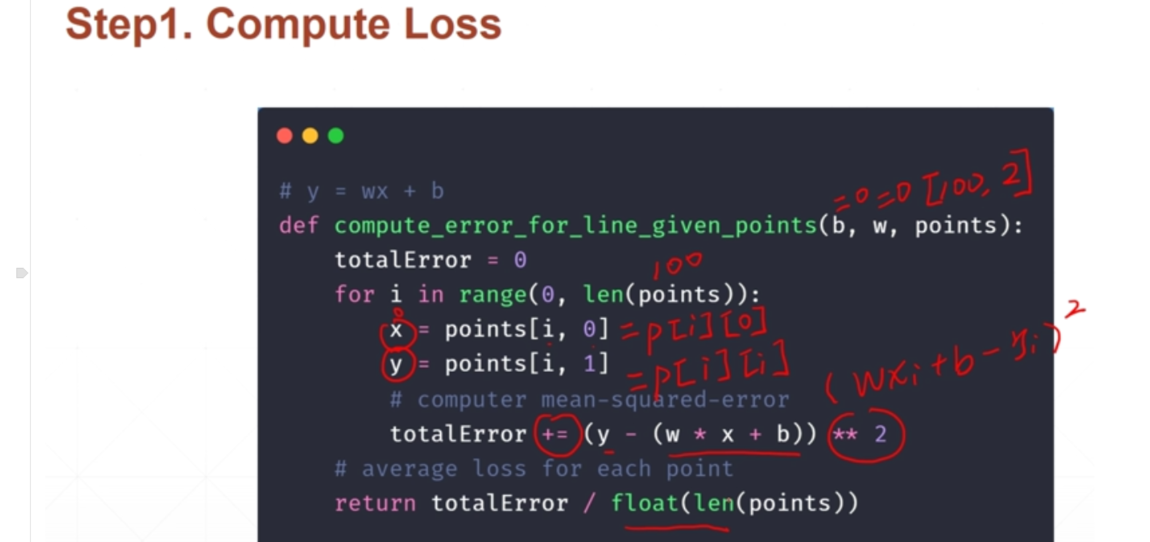
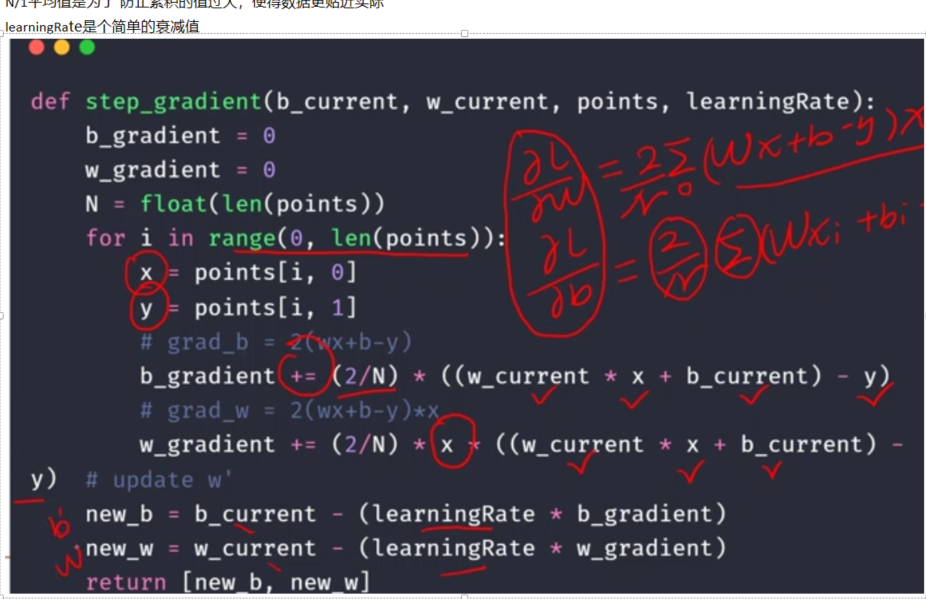
import numpy as np#线性回归问题学习# y = wx + b# step1: 计算lossdef compute_error_for_line_given_points(b, w, points):totalError = 0for i in range(0, len(points)):x = points[i, 0]y = points[i, 1]# computer mean-squared-errortotalError += (y - (w * x + b)) ** 2# average loss for each pointreturn totalError / float(len(points))#step2: 每次循环完成一个总的梯度的计算,以及更新def step_gradient(b_current, w_current, points, learningRate):b_gradient = 0w_gradient = 0N = float(len(points))for i in range(0, len(points)):x = points[i, 0]y = points[i, 1]# grad_b = 2(wx+b-y)b_gradient += (2/N) * ((w_current * x + b_current) - y)# grad_w = 2(wx+b-y)*xw_gradient += (2/N) * x * ((w_current * x + b_current) - y)# update w'new_b = b_current - (learningRate * b_gradient)new_w = w_current - (learningRate * w_gradient)return [new_b, new_w]#step3: 循环梯度,将W',B’不断赋给W,Bdef gradient_descent_runner(points, starting_b, starting_w, learning_rate, num_iterations):b = starting_bw = starting_w# update for several timesfor i in range(num_iterations):b, w = step_gradient(b, w, np.array(points), learning_rate) #每次将优化后得B'和W'赋给b,wreturn [b, w]def run():points = np.genfromtxt("data.csv", delimiter=",") #首先是加载文件数据 得到一个120的二维数组learning_rate = 0.0001 # 衰减函数initial_b = 0 # initial y-intercept guessinitial_w = 0 # initial slope guessnum_iterations = 1000 #循环1000次print("Starting gradient descent at b = {0}, w = {1}, error = {2}".format(initial_b, initial_w, #将初始化的w和b的值打印出来compute_error_for_line_given_points(initial_b, initial_w, points)) #compute_error_for_line_given_points 在计算下初始的误差LOSS,因为根据每一个当前的w和b的值都可以得到一个当前的loss)print("Running...")[b, w] = gradient_descent_runner(points, initial_b, initial_w, learning_rate, num_iterations)print("After {0} iterations b = {1}, w = {2}, error = {3}".format(num_iterations, b, w, #计算完成后有个计算完成的b和w(最好的w'和b‘的值)compute_error_for_line_given_points(b, w, points)) #然后计算当前的误差)# 可以预见,经过1000次iterations后的b'和w'肯定会好于初始的w和b,故得到得loss也肯定比之前得好if __name__ == '__main__':run()# 输出结果:# Starting gradient descent at b = 0, w = 0, error = 5565.107834483211# Running...# After 1000 iterations b = 0.08893651993741346, w = 1.4777440851894448, error = 112.61481011613473## 可以看到初始化为0,平方和loss为5565 ,经过1000次循环之后,loss变为了112小了很多
2.离散值的预测
手写数字loss计算的概念部分
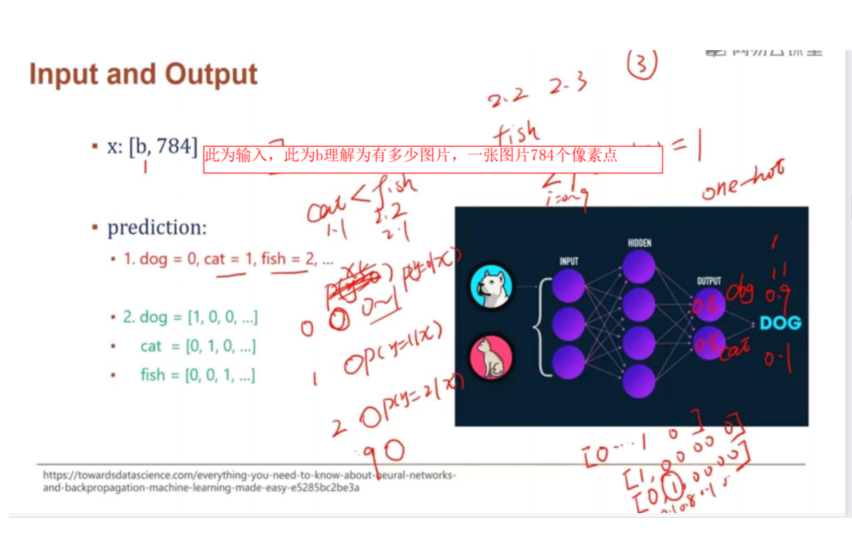
然后将28X28的数据打平显示:如何操作呢:
第一行28,后面跟28,再跟28,(一共有28个28),相当于将[28,28]变成一个[28X28],即打平成一维的784,上下的关系就丢失了,就只有左右的邻近关系(虽然损失了上下的关系,不过还是完整保留了图片的信息)
y是个低维,线性的时序空间,是一段连续的数值就归类为Regression问题
@ 是矩阵相乘的意思
 Relu是激活函数
Relu是激活函数
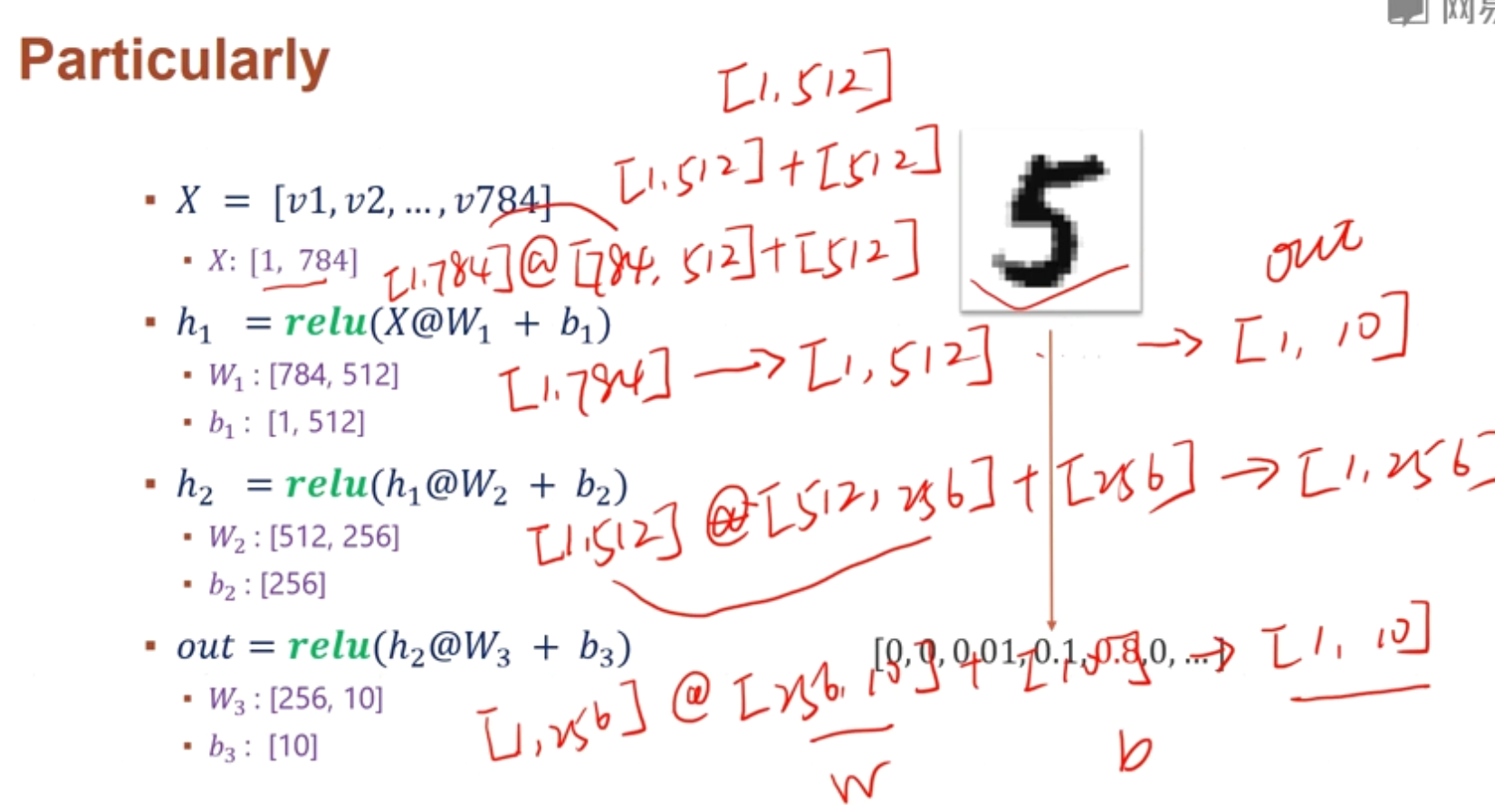
这样得出的输出我们可以理解为每一类的置信度每一档工序相当于一次降维,然后其最大值为当前图形的类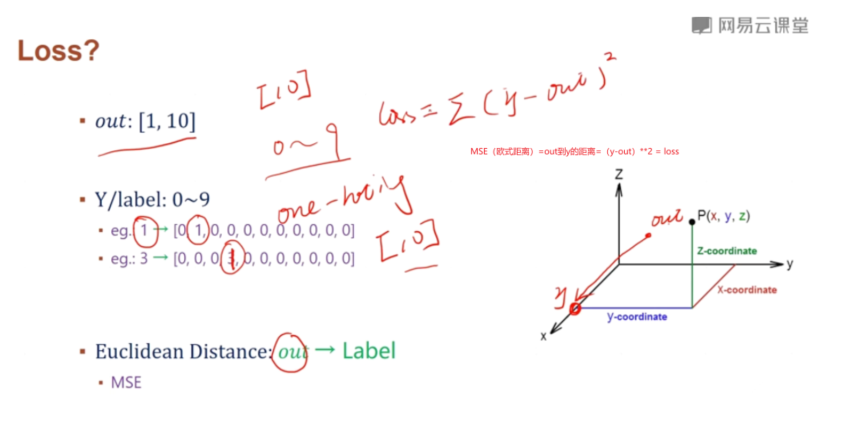
不停的迭代,会得到一个最优的w1’,b1..w3’,b3’,然后用这个参数来预计新的out
取out所在最大的置信度,就记为该类的预测类型


课程安排

练习:手写数字识别的loss
1.数据集的准备
2.完成h1,h2,out的推算
3.根据y计算loss
4.根据loss求出梯度在算出迭代的
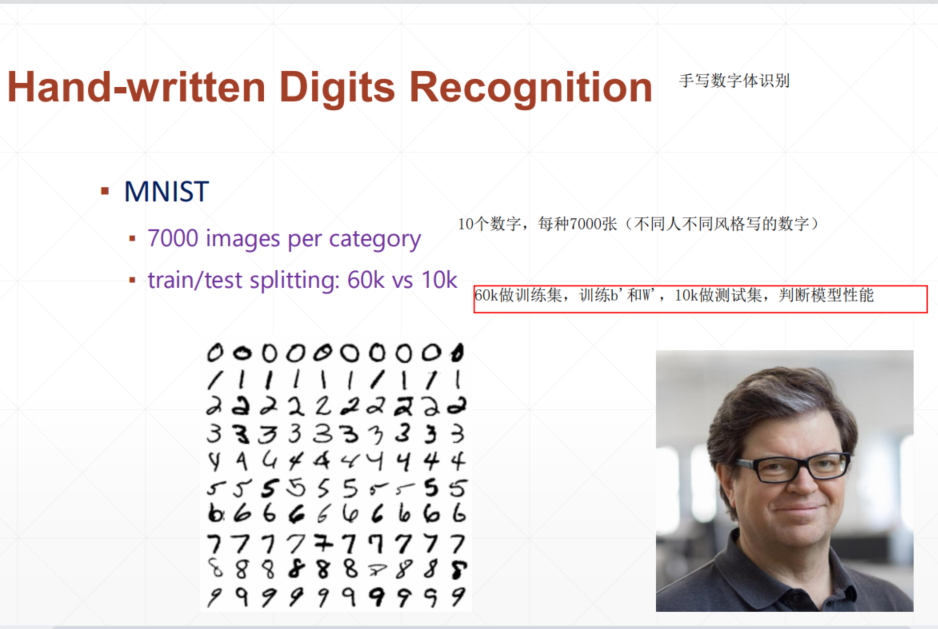
 google收搜mnist http://yann.lecun.com/exdb/mnist/
google收搜mnist http://yann.lecun.com/exdb/mnist/

再用numpy读取
如果你的网速够快,这个数据集可以用tensorflow下的datasets直接去下载这个数据集,第二次用的时候就不用再下载了


import os
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, optimizers, datasets
os.environ['TF_CPP_MIN_LOG_LEVEL']='2' #减少tensorflow的打印的无关信息
#STEP0 数据集加载
# 如果你的网速够快,这个数据集可以用tensorflow下的datasets直接去下载这个数据集,第二次用的时候就不用再下载了
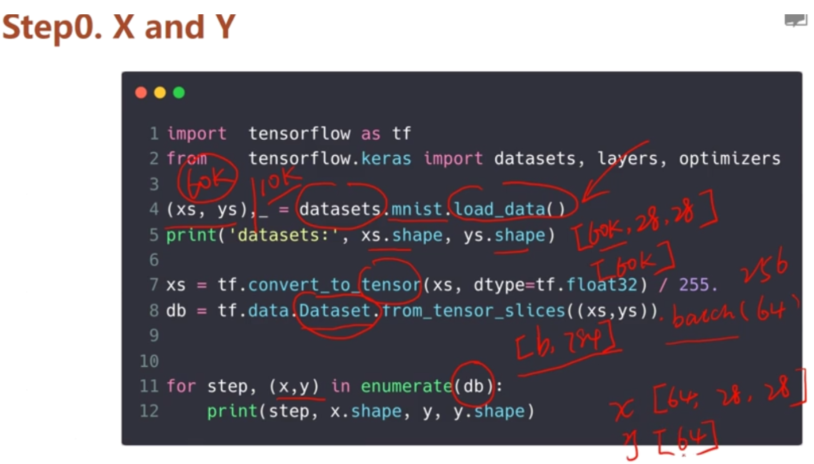
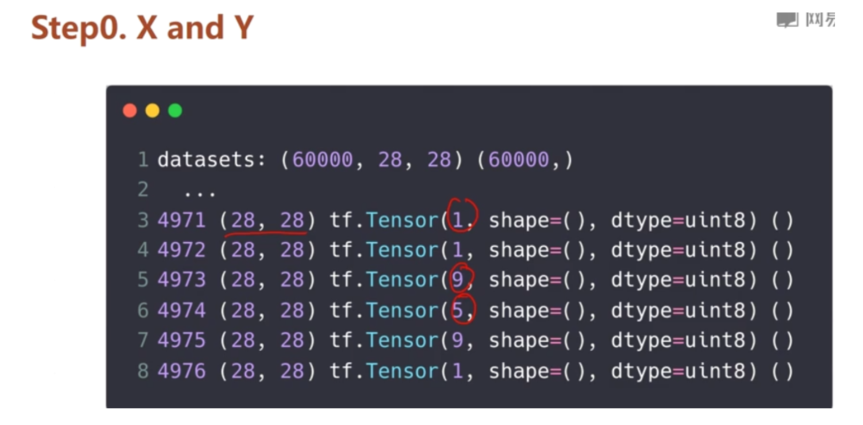
(x, y), (x_val, y_val) = datasets.mnist.load_data()
x = tf.convert_to_tensor(x, dtype=tf.float32) / 255. #要使用gpu加速,要用tensorflow的格式
y = tf.convert_to_tensor(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10) #打印出来就是 (60k,10)
print(x.shape, y.shape) #打印出每张图篇的形状,(60k,28,28)
print("特征切片",tf.data.Dataset.from_tensor_slices((x, y)))#特征切片 <TensorSliceDataset shapes: ((28, 28), (10,)), types: (tf.float32, tf.float32)>
train_dataset = tf.data.Dataset.from_tensor_slices((x, y)) #对特征进行特征切片
train_dataset = train_dataset.batch(200) #一次加载200张图片
#三道工序的模型 准备的网络结构模型
#784 - 512 第一层h1, 512-256 第二层h2, 256 -10 out
#Dense全连接层 activation是非线性参数,一个激活函数
model = keras.Sequential([
layers.Dense(512, activation='relu'),
layers.Dense(256, activation='relu'),
layers.Dense(10)])
#优化器 自动按规则更新参数,需给步长即可
optimizer = optimizers.SGD(learning_rate=0.001)
#对数据集进行一次训练称为epoch
#interi 对一个epoch迭代一次
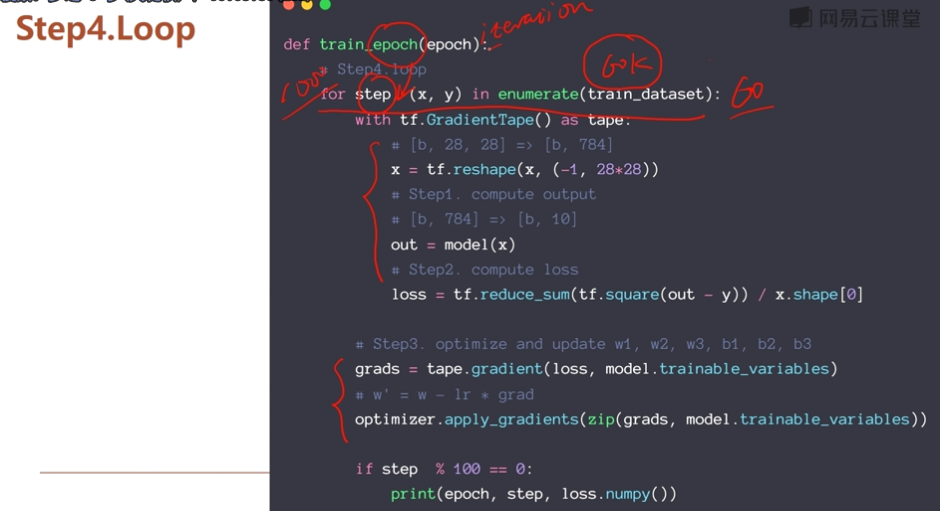
def train_epoch(epoch):
# Step4.loop 对一个数据集迭代这么多次 60k/200 大概300次,每个epoch有300个step,每一个step有30个epoch enumerate列举
for step, (x, y) in enumerate(train_dataset):
#Step1&2:
#tf.GradientTape:梯度求解利器
with tf.GradientTape() as tape:
# [b, 28, 28] => [b, 784] 第一个维度是b代表多少张,784是打平后的28*28
#打平操作
x = tf.reshape(x, (-1, 28*28))
# Step1. compute output 经过运算得到h1,h2,out,直接拿到最终得out
# [b, 784] => [b, 10]
out = model(x)
# Step2. compute loss x.shape[0]表示1/n 目的是更好得平均数据,更接近真实y
loss = tf.reduce_sum(tf.square(out - y)) / x.shape[0] #MSE欧式距离运算,得到损失函数
# Step3. optimize and update w1, w2, w3, b1, b2, b3 这个过程 tape.gradient计算量大得时候不可能人为计算,用这个函数自动求导
grads = tape.gradient(loss, model.trainable_variables) #计算梯度用的
# w' = w - lr * grad 功能:更新参数 把计算出来的梯度更新到变量上去。
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 100 == 0:
print(epoch, step, 'loss:', loss.numpy())
def train():
#对数据集迭代30次
for epoch in range(30):
train_epoch(epoch)
if __name__ == '__main__':
train()
#0 100 loss: 0.9563961
#epoch step(每100次打印一次)
#最初的loss 0 0 loss: 1.6428082
#29 200 loss: 0.23990849
线性回归概念
Linear Regression:如果模型是线性模型,eg: y =wx+b,w和b就是线性模型的参数
Classification:
Logistiic Regression:二分类问题
对离散值——》 classification解决
连续问题——》用regression问题解决

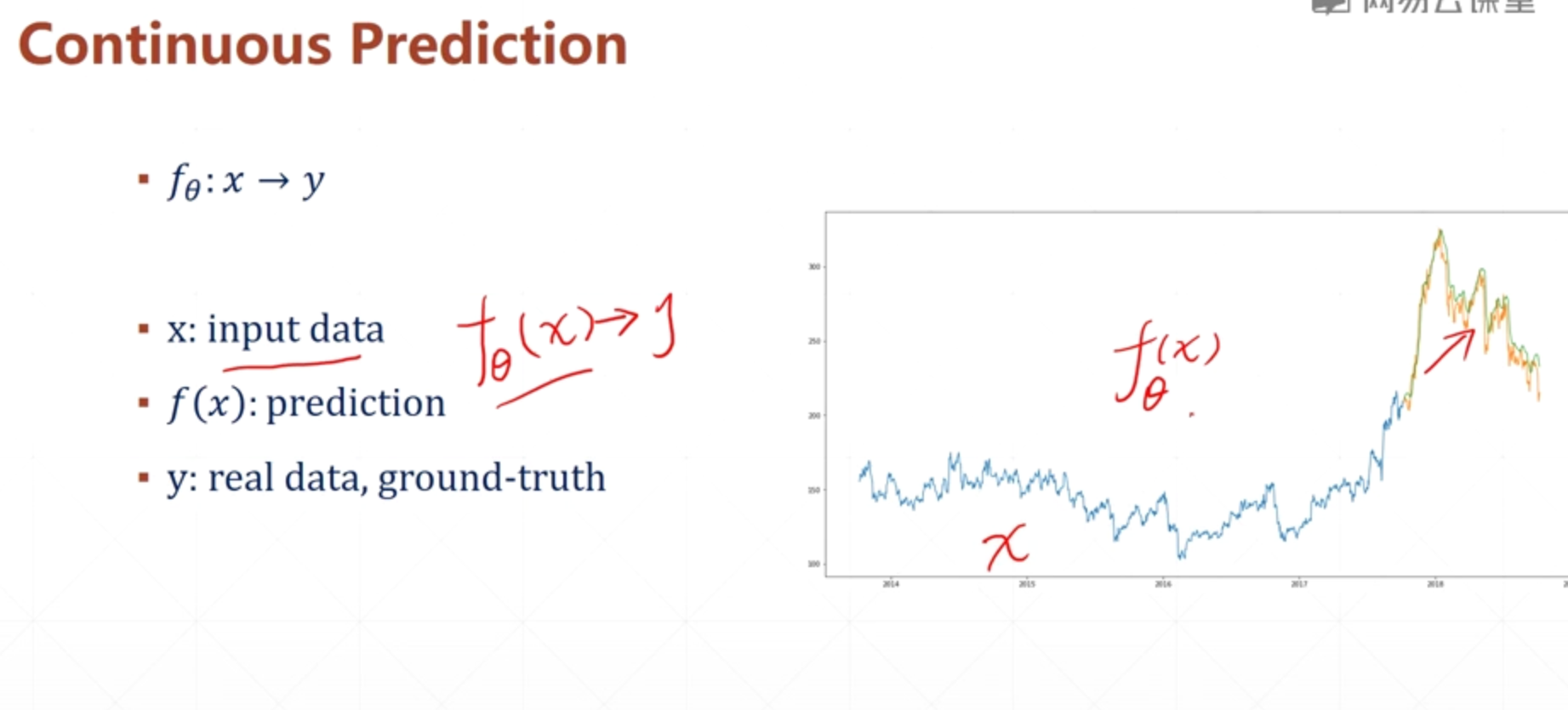

这种可以通过精确求解的情况叫 Closed Form solution
but现实中很多问题都无法做到精确求解,
1.模型本身的未知
2.采集的数据是有误差,观测的数据都有噪声
噪声用(abuselong)表示 ,并假设它符合一个假设的分布(eg:高斯分布)
,并假设它符合一个假设的分布(eg:高斯分布)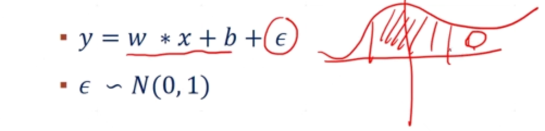
如果只根据观测到的两种
for example:
假设w,b已知 w=1.477 b=0.089,再添加一个高斯噪声
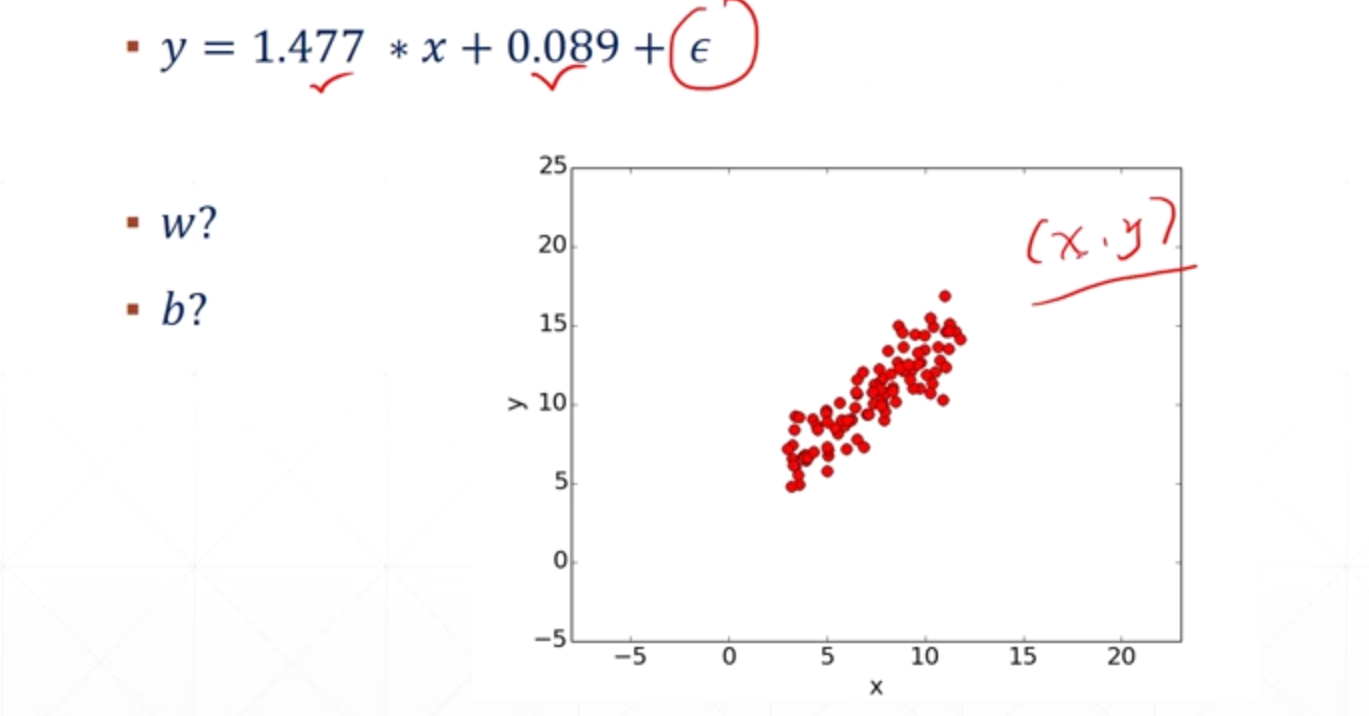
如何求解出w和b?
loss 误差函数越小,对任意X样本经过wx和b的运算后,就可以非常接近真实样本y
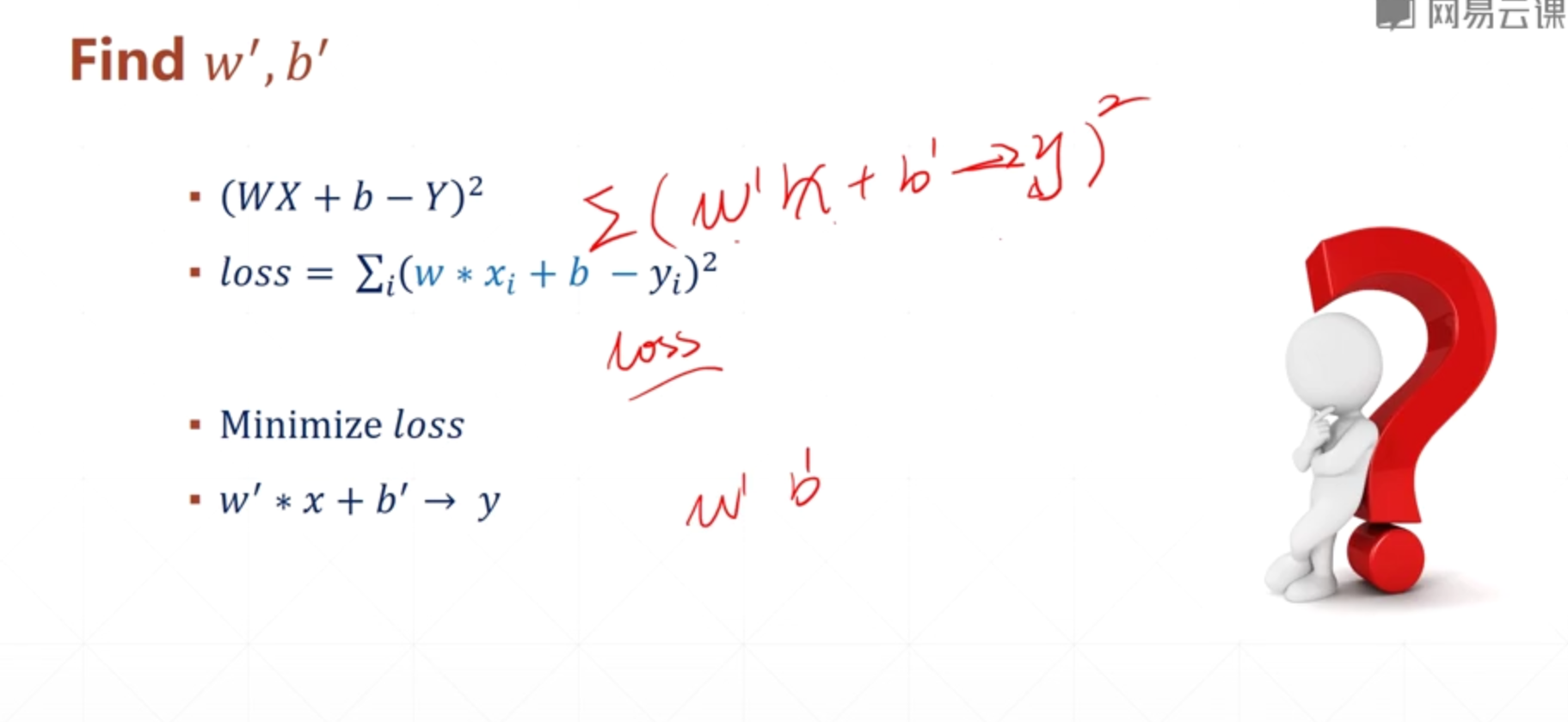
如何去找到这个最小的loss?——》 Gradient Descent 梯度下降

Linear Regression:如果模型是线性模型,eg: y =wx+b,w和b就是线性模型的参数
Classification:
Logistiic Regression:二分类问题
对离散值——》 classification解决
连续问题——》用regression问题解决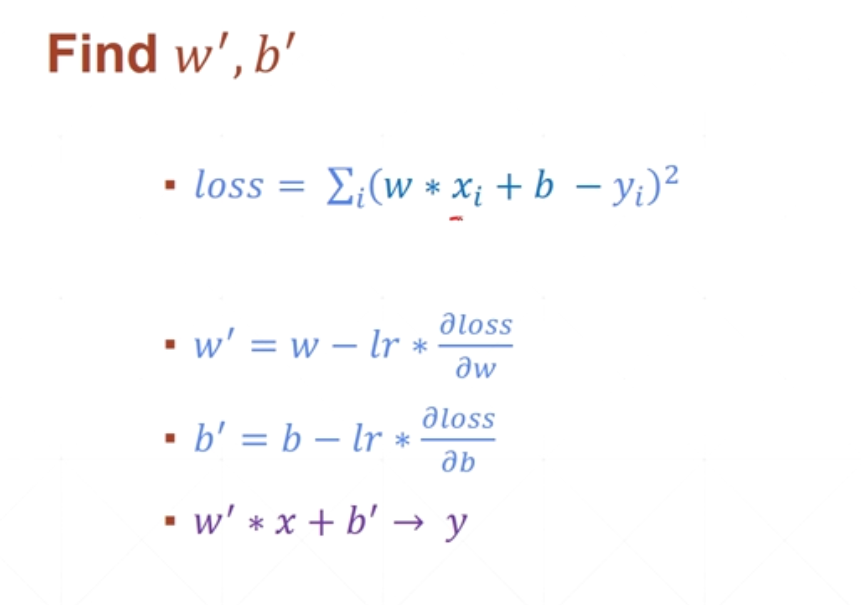

若有收获,就点个赞吧
0 人点赞
