索引
目的:提高数据访问的效率。
但是并不一定加了索引一定可以提高数据访问效率。
Oracle索引类型:
- B-tree:B树索引
- Bitmap:位图索引
- Text Index:全文索引
B-tree索引
B-tree索引里,数据的排列是非常严格按顺序排列的,所以搜索定位速度很快。
B-tree是按字典层级存储的,如图:
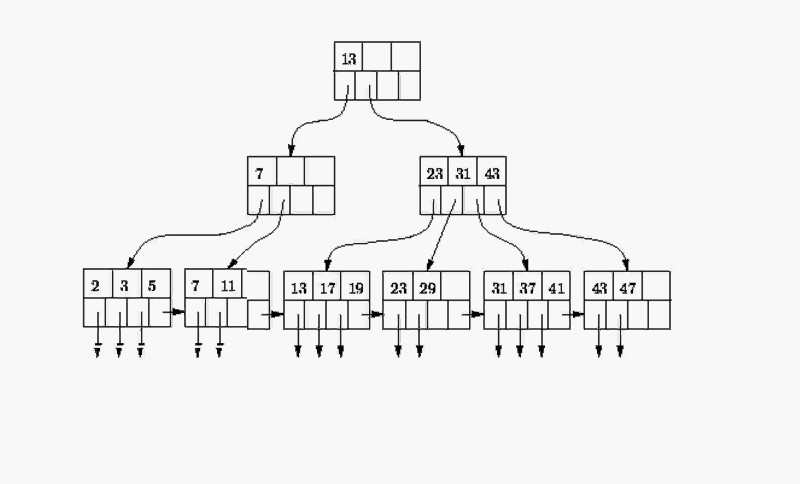
一般是存储的3层,极少情况下数据倾斜严重时会出现4层。
最上面的一层称为根,后面的称为枝叶。
查询时从根向下查找,例如查找索引为11的数据块:先从根查询0-13范围对应的分支,查询到第二层左边的分支,继续在该分支上查找大于7的范围的叶子节点,找到第3层第2个块上的第2项,获取到该项对应的值即为该索引对应的数据块。
B-tree索引的叶子节点和叶子节点之间也是有连接的。如果扫描了2/3/5这个叶子,需要继续扫7/11的叶子时,不需要再返回上一层branch上,可以直接继续扫描。
只有从入口向下查找时才需要从根向下查,如果是index range scan,则可以在一个叶子节点扫描完继续扫描下一个叶子节点。
高效的应用场景:索引字段有很高的selectivity或者结果集很小的时候。
基本上适合所有类型的数据库(OLAP、OLTP),没有太明显的缺点。
位图索引
针对重复性比较高的值的索引(例如性别)。
示例:表中数据如下,性别、婚姻状况两个字段建立位图索引
1 张三 男 已婚2 李四 女 离异3 王五 男 已婚4 赵六 男 已婚5 孙七 男 已婚6 周八 男 未婚7 吴九 女 未婚
位图索引的存储:(按位存储)
| value | Row1 | Row2 | Row3 | Row4 | Row5 | Row6 | Row7 |
|---|---|---|---|---|---|---|---|
| 男 | 1 | 0 | 1 | 1 | 1 | 1 | 0 |
| 女 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 已婚 | 1 | 0 | 1 | 1 | 1 | 0 | 0 |
| 离异 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 未婚 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
位图索引的运算就是计算机的位运算。
例如:获取性别为男且婚姻状况为未婚、离异的数据,则通过位运算得出:
| value | Row1 | Row2 | Row3 | Row4 | Row5 | Row6 | Row7 |
|---|---|---|---|---|---|---|---|
| 男 | 1 | 0 | 1 | 1 | 1 | 1 | 0 |
| 离异 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 未婚 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 位运算结果 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
最终可以取出第6条数据。
使用场景:
- 只适合OLAP,不适合OLTP
- 重复率很高的键值
OLTP数据库中DML频繁操作,不适合用位图索引。因为进行DML操作时,位图索引锁定的不只是当前操作行的数据,而是整个位图段的数据都将锁定,很影响并发性能。
全文索引
用法示例:
-- 查询条件中,左右两边都是模糊查询,Oracle找不到索引的入口-- 一般情况下,Oracle对这种情况使用的是全表扫描select object_name from twhere object_name like '%TABLE%';
针对这种左右两边的模糊查询,Oracle提供了一种全文索引。
建立全文索引的字段通常是字符型的字段,oracle会将这个字段的值进行拆解分词建立索引。
-- 创建全文索引create index idx_t on t(object_name)indextype is ctxsys.context;
全文索引的搜索语法:
select count(*) from twhere contains(object_name, 'TAB') > 0;
此时执行计划显示的是DOMAIN INDEX域索引(一般情况下域索引就是全文索引)。
全文索引的数据存储还是基于B-tree方式,只是全文索引类似于一个包,把很多对象都包了进去。当创建了一个全文索引后,在user_index视图中会出现很多个索引,多出来的那些就是这个全文索引下的对象。
这个全文索引本身并不是一个段对象实体,它自己并不占空间,它占据的空间是它内部的基索引占据的。在user_segments中查询不到刚刚创建的全文索引IDX_T。
使用场景:
- b-tree、bitmap无法使用的场景:左右两边模糊查询
缺点:
- 占用过大的磁盘空间(有可能比源表占用的空间还大)
- 维护成本高(重建索引非常耗时)
- bug多
分区
分区表注意事项:
- 表分区后,每个分区变成各自的段对象,而原表则变成为一个逻辑名称。所以对于分区表,表本身没有对应的表空间,每个分区表可以存储在不同表空间中
- 分区裁剪。如果表没有索引,没有表分区时需要对表进行全表扫描到表的高水位;有了表分区,oracle可以定位到要查询的数据位于某一个或某几个表分区,然后只扫描这个表分区的起始点到高水位。
分区可以方便数据的管理,但是并不一定能提高性能。
分类:
- List partitioning
- Range Partitioning
- Hash Partitioning
创建语句:
create table t_p (id int)partition by range(id)(partition p1 values less than(100),partition p2 values less than(200),partition pm values less than(maxvalue));
组合分区(子分区)
子分区:建了一个分区之后,还可以对这个分区做子分区(组合分区)。
Oracle 10g下提供两种组合:
- Range-hash
- Range-list
Oracle 11g增加了4种组合:
- Range-Range
- List-Range
- List-Hash
- List-List
分区索引
Local Partition Index(本地索引):对当前分区的数据做的索引
- 对分区做DDL操作不会导致索引无效,无需rebuild索引
- 可以非常方便的管理数据
Global Partition Index(全局索引):虽然表做了分区,但是索引是全局的没有分区
- 对分区做DDL操作会导致索引无效
创建语句:
-- 全局索引create index idx_t on t(id);-- 分区索引create index idx_t_p on t_p(id) local;
因为索引是顺序存储的,所以分区索引并不一定比全局索引的扫描性能好,有些情况下分区索引的性能反而更差一些。一般情况下,分区索引和全局索引的性能差别不大。
分区索引的目的在于数据的管理而非性能。
一个分区表上如果经常有DDL操作,将会导致全局索引无效,需要对索引重建,此时创建分区索引更加适合。

若有收获,就点个赞吧
0 人点赞
