简介
TreeMap使用红黑树存储元素,可以保证元素按key值的大小进行遍历
继承体系
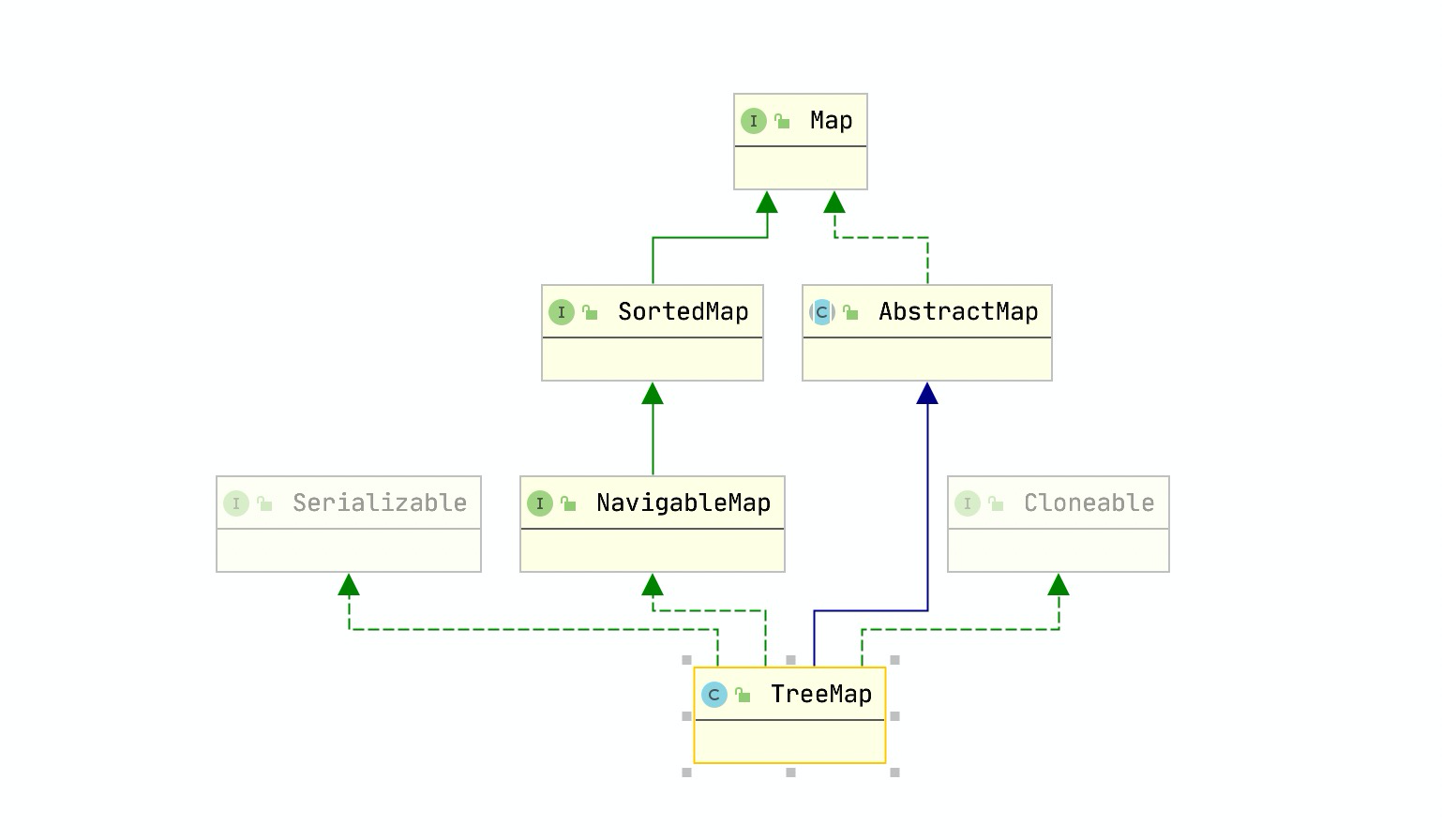
TreeMap实现了Map、SortedMap、NavigableMap、Cloneable、Serializable等接口。
SortedMap规定了元素可以按key的大小来遍历,它定义了一些返回部分map的方法
public interface SortedMap<K,V> extends Map<K,V> {// key的比较器Comparator<? super K> comparator();// 返回fromKey(包含)到toKey(不包含)之间的元素组成的子mapSortedMap<K,V> subMap(K fromKey, K toKey);// 返回小于toKey(不包含)的子mapSortedMap<K,V> headMap(K toKey);// 返回大于等于fromKey(包含)的子mapSortedMap<K,V> tailMap(K fromKey);// 返回最小的keyK firstKey();// 返回最大的keyK lastKey();// 返回key集合Set<K> keySet();// 返回value集合Collection<V> values();// 返回节点集合Set<Map.Entry<K, V>> entrySet();}
NavigableMap是对SortedMap的增强,定义了一些返回离目标key最近的元素的方法
public interface NavigableMap<K,V> extends SortedMap<K,V> {// 小于给定key的最大节点Map.Entry<K,V> lowerEntry(K key);// 小于给定key的最大keyK lowerKey(K key);// 小于等于给定key的最大节点Map.Entry<K,V> floorEntry(K key);// 小于等于给定key的最大keyK floorKey(K key);// 大于等于给定key的最小节点Map.Entry<K,V> ceilingEntry(K key);// 大于等于给定key的最小keyK ceilingKey(K key);// 大于给定key的最小节点Map.Entry<K,V> higherEntry(K key);// 大于给定key的最小keyK higherKey(K key);// 最小的节点Map.Entry<K,V> firstEntry();// 最大的节点Map.Entry<K,V> lastEntry();// 弹出最小的节点Map.Entry<K,V> pollFirstEntry();// 弹出最大的节点Map.Entry<K,V> pollLastEntry();// 返回倒序的mapNavigableMap<K,V> descendingMap();// 返回有序的key集合NavigableSet<K> navigableKeySet();// 返回倒序的key集合NavigableSet<K> descendingKeySet();// 返回从fromKey到toKey的子map,是否包含起止元素可以自己决定NavigableMap<K,V> subMap(K fromKey, boolean fromInclusive,K toKey, boolean toInclusive);// 返回小于toKey的子map,是否包含toKey自己决定NavigableMap<K,V> headMap(K toKey, boolean inclusive);// 返回大于fromKey的子map,是否包含fromKey自己决定NavigableMap<K,V> tailMap(K fromKey, boolean inclusive);// 等价于subMap(fromKey, true, toKey, false)SortedMap<K,V> subMap(K fromKey, K toKey);// 等价于headMap(toKey, false)SortedMap<K,V> headMap(K toKey);// 等价于tailMap(fromKey, true)SortedMap<K,V> tailMap(K fromKey);}
存储结构
TreeMap只使用到了红黑树,所以它的时间复杂度为O(log n),在数据结构和算法我们在详细讲解红黑树。
红黑树特性
(1)每个节点或者是黑色,或者是红色。
(2)根节点是黑色。
(3)每个叶子节点(NIL)是黑色。(注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点!)
(4)如果一个节点是红色的,则它的子节点必须是黑色的。
(5)从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
源码解析
属性
/*** 比较器,如果没传则key要实现Comparable接口*/private final Comparator<? super K> comparator;/*** 根节点*/private transient Entry<K,V> root;/*** 元素个数*/private transient int size = 0;/*** 修改次数*/private transient int modCount = 0;
(1)comparator
按key的大小排序有两种方式,一种是key实现Comparable接口,一种方式通过构造方法传入比较器。
(2)root
根节点,TreeMap没有桶的概念,所有的元素都存储在一颗树中。
Entry内部类
存储节点,典型的红黑树结构
static final class Entry<K,V> implements Map.Entry<K,V> {K key;V value;Entry<K,V> left;Entry<K,V> right;Entry<K,V> parent;boolean color = BLACK;}
构造方法
/*** 默认构造方法,key必须实现Comparable接口*/public TreeMap() {comparator = null;}/*** 使用传入的comparator比较两个key的大小*/public TreeMap(Comparator<? super K> comparator) {this.comparator = comparator;}/*** key必须实现Comparable接口,把传入map中的所有元素保存到新的TreeMap中*/public TreeMap(Map<? extends K, ? extends V> m) {comparator = null;putAll(m);}/*** 使用传入map的比较器,并把传入map中的所有元素保存到新的TreeMap中*/public TreeMap(SortedMap<K, ? extends V> m) {comparator = m.comparator();try {buildFromSorted(m.size(), m.entrySet().iterator(), null, null);} catch (java.io.IOException cannotHappen) {} catch (ClassNotFoundException cannotHappen) {}}
构造方法主要分成两类,一类是使用comparator比较器,一类是key必须实现Comparable接口。
其实,笔者认为这两种比较方式可以合并成一种,当没有传comparator的时候,可以用以下方式来给comparator赋值,这样后续所有的比较操作都可以使用一样的逻辑处理了,而不用每次都检查comparator为空的时候又用Comparable来实现一遍逻辑。
// 如果comparator为空,则key必须实现Comparable接口,所以这里肯定可以强转// 这样在构造方法中统一替换掉,后续的逻辑就都一致了comparator = (k1, k2) -> ((Comparable<? super K>)k1).compareTo(k2);
get(Object key)方法
获取元素,典型的二叉查找树的查找方法
public V get(Object key) {// 根据key查找元素Entry<K,V> p = getEntry(key);// 找到了返回value值,没找到返回nullreturn (p==null ? null : p.value);}final Entry<K,V> getEntry(Object key) {// 如果comparator不为空,使用comparator的版本获取元素if (comparator != null)return getEntryUsingComparator(key);// 如果key为空返回空指针异常if (key == null)throw new NullPointerException();// 将key强转为Comparable@SuppressWarnings("unchecked")Comparable<? super K> k = (Comparable<? super K>) key;// 从根元素开始遍历Entry<K,V> p = root;while (p != null) {int cmp = k.compareTo(p.key);if (cmp < 0)// 如果小于0从左子树查找p = p.left;else if (cmp > 0)// 如果大于0从右子树查找p = p.right;else// 如果相等说明找到了直接返回return p;}// 没找到返回nullreturn null;}final Entry<K,V> getEntryUsingComparator(Object key) {@SuppressWarnings("unchecked")K k = (K) key;Comparator<? super K> cpr = comparator;if (cpr != null) {// 从根元素开始遍历Entry<K,V> p = root;while (p != null) {int cmp = cpr.compare(k, p.key);if (cmp < 0)// 如果小于0从左子树查找p = p.left;else if (cmp > 0)// 如果大于0从右子树查找p = p.right;else// 如果相等说明找到了直接返回return p;}}// 没找到返回nullreturn null;}
(1)从root遍历整个树;
(2)如果待查找的key比当前遍历的key小,则在其左子树中查找;
(3)如果待查找的key比当前遍历的key大,则在其右子树中查找;
(4)如果待查找的key与当前遍历的key相等,则找到了该元素,直接返回;
(5)从这里可以看出是否有comparator分化成了两个方法,但是内部逻辑一模一样,因此可见笔者comparator = (k1, k2) -> ((Comparable<? super K>)k1).compareTo(k2);这种改造的必要性
插入元素
插入元素,如果元素在树中存在,则替换value;如果元素不存在,则插入到对应的位置,再平衡树
public V put(K key, V value) {Entry<K,V> t = root;if (t == null) {// 如果没有根节点,直接插入到根节点compare(key, key); // type (and possibly null) checkroot = new Entry<>(key, value, null);size = 1;modCount++;return null;}// key比较的结果int cmp;// 用来寻找待插入节点的父节点Entry<K,V> parent;// 根据是否有comparator使用不同的分支Comparator<? super K> cpr = comparator;if (cpr != null) {// 如果使用的是comparator方式,key值可以为null,只要在comparator.compare()中允许即可// 从根节点开始遍历寻找do {parent = t;cmp = cpr.compare(key, t.key);if (cmp < 0)// 如果小于0从左子树寻找t = t.left;else if (cmp > 0)// 如果大于0从右子树寻找t = t.right;else// 如果等于0,说明插入的节点已经存在了,直接更换其value值并返回旧值return t.setValue(value);} while (t != null);}else {// 如果使用的是Comparable方式,key不能为nullif (key == null)throw new NullPointerException();@SuppressWarnings("unchecked")Comparable<? super K> k = (Comparable<? super K>) key;// 从根节点开始遍历寻找do {parent = t;cmp = k.compareTo(t.key);if (cmp < 0)// 如果小于0从左子树寻找t = t.left;else if (cmp > 0)// 如果大于0从右子树寻找t = t.right;else// 如果等于0,说明插入的节点已经存在了,直接更换其value值并返回旧值return t.setValue(value);} while (t != null);}// 如果没找到,那么新建一个节点,并插入到树中Entry<K,V> e = new Entry<>(key, value, parent);if (cmp < 0)// 如果小于0插入到左子节点parent.left = e;else// 如果大于0插入到右子节点parent.right = e;// 插入之后的平衡fixAfterInsertion(e);// 元素个数加1(不需要扩容)size++;// 修改次数加1modCount++;// 如果插入了新节点返回空return null;}
删除元素
删除元素本身比较简单,就是采用二叉树的删除规则。
(1)如果删除的位置有两个叶子节点,则从其右子树中取最小的元素放到删除的位置,然后把删除位置移到替代元素的位置,进入下一步。
(2)如果删除的位置只有一个叶子节点(有可能是经过第一步转换后的删除位置),则把那个叶子节点作为替代元素,放到删除的位置,然后把这个叶子节点删除。
(3)如果删除的位置没有叶子节点,则直接把这个删除位置的元素删除即可。
(4)针对红黑树,如果删除位置是黑色节点,还需要做再平衡。
(5)如果有替代元素,则以替代元素作为当前节点进入再平衡。
(6)如果没有替代元素,则以删除的位置的元素作为当前节点进入再平衡,平衡之后再删除这个节点。
public V remove(Object key) {
// 获取节点
Entry<K,V> p = getEntry(key);
if (p == null)
return null;
V oldValue = p.value;
// 删除节点
deleteEntry(p);
// 返回删除的value
return oldValue;
}
private void deleteEntry(Entry<K,V> p) {
// 修改次数加1
modCount++;
// 元素个数减1
size--;
if (p.left != null && p.right != null) {
// 如果当前节点既有左子节点,又有右子节点
// 取其右子树中最小的节点
Entry<K,V> s = successor(p);
// 用右子树中最小节点的值替换当前节点的值
p.key = s.key;
p.value = s.value;
// 把右子树中最小节点设为当前节点
p = s;
// 这种情况实际上并没有删除p节点,而是把p节点的值改了,实际删除的是p的后继节点
}
// 如果原来的当前节点(p)有2个子节点,则当前节点已经变成原来p的右子树中的最小节点了,也就是说其没有左子节点了
// 到这一步,p肯定只有一个子节点了
// 如果当前节点有子节点,则用子节点替换当前节点
Entry<K,V> replacement = (p.left != null ? p.left : p.right);
if (replacement != null) {
// 把替换节点直接放到当前节点的位置上(相当于删除了p,并把替换节点移动过来了)
replacement.parent = p.parent;
if (p.parent == null)
root = replacement;
else if (p == p.parent.left)
p.parent.left = replacement;
else
p.parent.right = replacement;
// 将p的各项属性都设为空
p.left = p.right = p.parent = null;
// 如果p是黑节点,则需要再平衡
if (p.color == BLACK)
fixAfterDeletion(replacement);
} else if (p.parent == null) {
// 如果当前节点就是根节点,则直接将根节点设为空即可
root = null;
} else {
// 如果当前节点没有子节点且其为黑节点,则把自己当作虚拟的替换节点进行再平衡
if (p.color == BLACK)
fixAfterDeletion(p);
// 平衡完成后删除当前节点(与父节点断绝关系)
if (p.parent != null) {
if (p == p.parent.left)
p.parent.left = null;
else if (p == p.parent.right)
p.parent.right = null;
p.parent = null;
}
}
}
TreeMap的遍历
@Override
public void forEach(BiConsumer<? super K, ? super V> action) {
Objects.requireNonNull(action);
// 遍历前的修改次数
int expectedModCount = modCount;
// 执行遍历,先获取第一个元素的位置,再循环遍历后继节点
for (Entry<K, V> e = getFirstEntry(); e != null; e = successor(e)) {
// 执行动作
action.accept(e.key, e.value);
// 如果发现修改次数变了,则抛出异常
if (expectedModCount != modCount) {
throw new ConcurrentModificationException();
}
}
}
总结
(1)TreeMap的存储结构只有一颗红黑树;
(2)TreeMap中的元素是有序的,按key的顺序排列;
(3)TreeMap比HashMap要慢一些,因为HashMap前面还做了一层桶,寻找元素要快很多;
(4)TreeMap没有扩容的概念;
(5)TreeMap的遍历不是采用传统的递归式遍历;
(6)TreeMap可以按范围查找元素,查找最近的元素;

若有收获,就点个赞吧
0 人点赞
