上一节我讲了冒泡排序、插入排序、选择排序这三种排序算法,它们的时间复杂度都是 O(n2),比较高,适合小规模数据的排序。今天,我讲两种时间复杂度为 O(nlogn) 的排序算法,归并排序和快速排序。这两种排序算法适合大规模的数据排序,比上一节讲的那三种排序算法要更常用。
归并排序和快速排序都用到了分治思想,非常巧妙。我们可以借鉴这个思想,来解决非排序的问题,比如:如何在 O(n) 的时间复杂度内查找一个无序数组中的第 K 大元素? 这就要用到我们今天要讲的内容。
1. 归并排序的原理
- 我们先来看归并排序(Merge Sort)。
归并排序的核心思想还是蛮简单的。如果要排序一个数组,我们先把数组从中间分成前后两部分,然后对前后两部分分别排序,再将排好序的两部分合并在一起,这样整个数组就都有序了。
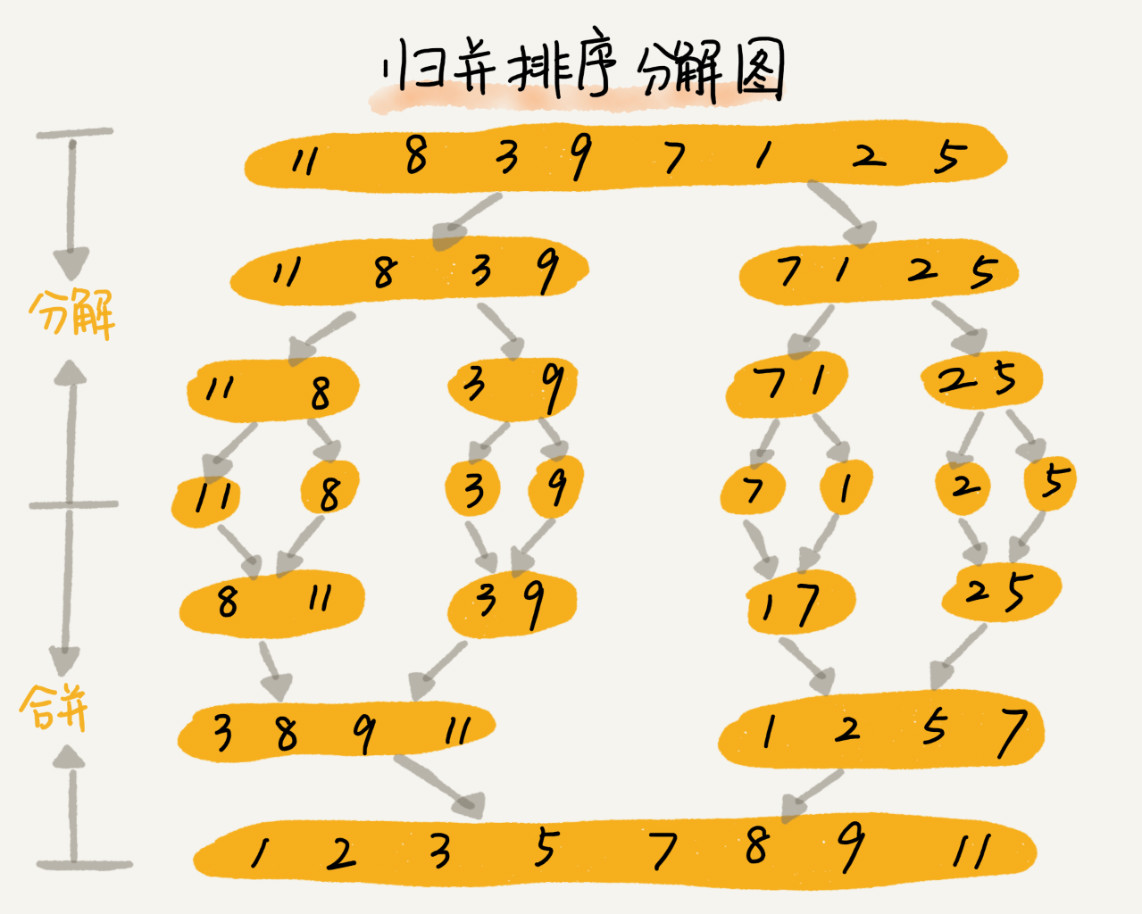
归并排序使用的就是分治思想。分治,顾名思义,就是分而治之,将一个大问题分解成小的子问题来解决。小的子问题解决了,大问题也就解决了。
从我刚才的描述,你有没有感觉到,分治思想跟我们前面讲的递归思想很像。是的,分治算法一般都是用递归来实现的。分治是一种解决问题的处理思想,递归是一种编程技巧,这两者并不冲突。分治算法的思想我后面会有专门的一节来讲,现在不展开讨论,我们今天的重点还是排序算法。
前面我通过举例让你对归并有了一个感性的认识,又告诉你,归并排序用的是分治思想,可以用递归来实现。我们现在就来看看如何用递归代码来实现归并排序。
递归代码的编写技巧你还记得吗?写递归代码的技巧就是,分析得出递推公式,然后找到终止条件,最后将递推公式翻译成递归代码。所以,要想写出归并排序的代码,我们先写出归并排序的递推公式。
递推公式:merge_sort(p…r) = merge(merge_sort(p…q), merge_sort(q+1…r))终止条件:p >= r 不用再继续分解
我来解释一下这个递推公式。
merge_sort(p…r) 表示,给下标从 p 到 r 之间的数组排序。我们将这个排序问题转化为了两个子问题,merge_sort(p…q) 和 merge_sort(q+1…r),其中下标 q 等于 p 和 r 的中间位置,也就是 (p+r)/2。当下标从 p 到 q 和从 q+1 到 r 这两个子数组都排好序之后,我们再将两个有序的子数组合并在一起,这样下标从 p 到 r 之间的数据就也排好序了。
有了递推公式,转化成代码就简单多了。为了阅读方便,我这里只给出伪代码,你可以翻译成你熟悉的编程语言。
// 归并排序算法, A是数组,n表示数组大小merge_sort(A, n) {merge_sort_c(A, 0, n-1)}// 递归调用函数merge_sort_c(A, p, r) {// 递归终止条件if p >= r then return// 取p到r之间的中间位置qq = (p+r) / 2// 分治递归merge_sort_c(A, p, q)merge_sort_c(A, q+1, r)// 将A[p...q]和A[q+1...r]合并为A[p...r]merge(A[p...r], A[p...q], A[q+1...r])}
你可能已经发现了,merge(A[p…r], A[p…q], A[q+1…r]) 这个函数的作用就是,将已经有序的 A[p…q]和 A[q+1…r]合并成一个有序的数组,并且放入 A[p…r]。那这个过程具体该如何做呢?
如图所示,我们申请一个临时数组 tmp,大小与 A[p…r]相同。我们用两个游标 i 和 j,分别指向 A[p…q]和 A[q+1…r]的第一个元素。比较这两个元素 A[i]和 A[j],如果 A[i]<=A[j],我们就把 A[i]放入到临时数组 tmp,并且 i 后移一位,否则将 A[j]放入到数组 tmp,j 后移一位。
继续上述比较过程,直到其中一个子数组中的所有数据都放入临时数组中,再把另一个数组中的数据依次加入到临时数组的末尾,这个时候,临时数组中存储的就是两个子数组合并之后的结果了。最后再把临时数组 tmp 中的数据拷贝到原数组 A[p…r]中。
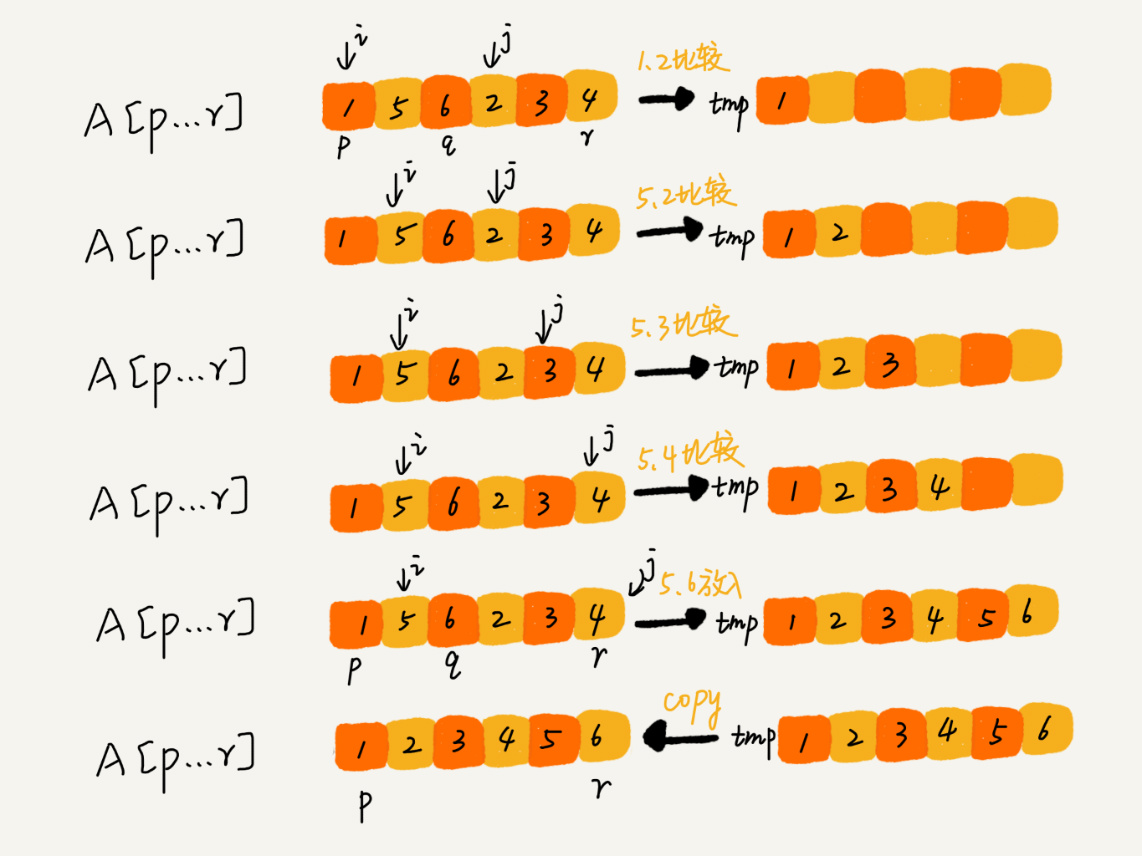
我们把 merge() 函数写成伪代码,就是下面这样:
merge(A[p...r], A[p...q], A[q+1...r]) {var i := p,j := q+1,k := 0 // 初始化变量i, j, kvar tmp := new array[0...r-p] // 申请一个大小跟A[p...r]一样的临时数组while i<=q AND j<=r do {if A[i] <= A[j] {tmp[k++] = A[i++] // i++等于i:=i+1} else {tmp[k++] = A[j++]}}// 判断哪个子数组中有剩余的数据var start := i,end := qif j<=r then start := j, end:=r// 将剩余的数据拷贝到临时数组tmpwhile start <= end do {tmp[k++] = A[start++]}// 将tmp中的数组拷贝回A[p...r]for i:=0 to r-p do {A[p+i] = tmp[i]}}
你还记得第 7 讲讲过的利用哨兵简化编程的处理技巧吗?merge() 合并函数如果借助哨兵,代码就会简洁很多,这个问题留给你思考。
2. 归并排序的性能分析
这样跟着我一步一步分析,归并排序是不是没那么难啦?还记得上节课我们分析排序算法的三个问题吗?接下来,我们来看归并排序的三个问题。
第一,归并排序是稳定的排序算法吗?
结合我前面画的那张图和归并排序的伪代码,你应该能发现,归并排序稳不稳定关键要看 merge() 函数,也就是两个有序子数组合并成一个有序数组的那部分代码。
在合并的过程中,如果 A[p…q]和 A[q+1…r]之间有值相同的元素,那我们可以像伪代码中那样,先把 A[p…q]中的元素放入 tmp 数组。这样就保证了值相同的元素,在合并前后的先后顺序不变。所以,归并排序是一个稳定的排序算法。第二,归并排序的时间复杂度是多少?
归并排序涉及递归,时间复杂度的分析稍微有点复杂。我们正好借此机会来学习一下,如何分析递归代码的时间复杂度。
在递归那一节我们讲过,递归的适用场景是,一个问题 a 可以分解为多个子问题 b、c,那求解问题 a 就可以分解为求解问题 b、c。问题 b、c 解决之后,我们再把 b、c 的结果合并成 a 的结果。
如果我们定义求解问题 a 的时间是 T(a),求解问题 b、c 的时间分别是 T(b) 和 T( c),那我们就可以得到这样的递推关系式:
T(a) = T(b) + T(c) + K
其中 K 等于将两个子问题 b、c 的结果合并成问题 a 的结果所消耗的时间。
从刚刚的分析,我们可以得到一个重要的结论:不仅递归求解的问题可以写成递推公式,递归代码的时间复杂度也可以写成递推公式。
套用这个公式,我们来分析一下归并排序的时间复杂度。
我们假设对 n 个元素进行归并排序需要的时间是 T(n),那分解成两个子数组排序的时间都是 T(n/2)。我们知道,merge() 函数合并两个有序子数组的时间复杂度是 O(n)。所以,套用前面的公式,归并排序的时间复杂度的计算公式就是:
T(1) = C; n=1时,只需要常量级的执行时间,所以表示为C。T(n) = 2*T(n/2) + n; n>1
通过这个公式,如何来求解 T(n) 呢?还不够直观?那我们再进一步分解一下计算过程。
T(n) = 2*T(n/2) + n= 2*(2*T(n/4) + n/2) + n = 4*T(n/4) + 2*n= 4*(2*T(n/8) + n/4) + 2*n = 8*T(n/8) + 3*n= 8*(2*T(n/16) + n/8) + 3*n = 16*T(n/16) + 4*n......= 2^k * T(n/2^k) + k * n......
通过这样一步一步分解推导,我们可以得到 T(n) = 2^kT(n/2^k)+kn。当 T(n/2^k)=T(1) 时,也就是 n/2^k=1,我们得到 k=log2n 。我们将 k 值代入上面的公式,得到 T(n)=Cn+nlog2n 。如果我们用大 O 标记法来表示的话,T(n) 就等于 O(nlogn)。所以归并排序的时间复杂度是 O(nlogn)。
从我们的原理分析和伪代码可以看出,归并排序的执行效率与要排序的原始数组的有序程度无关,所以其时间复杂度是非常稳定的,不管是最好情况、最坏情况,还是平均情况,时间复杂度都是 O(nlogn)。
- 第三,归并排序的空间复杂度是多少?
归并排序的时间复杂度任何情况下都是 O(nlogn),看起来非常优秀。(待会儿你会发现,即便是快速排序,最坏情况下,时间复杂度也是 O(n2)。)但是,归并排序并没有像快排那样,应用广泛,这是为什么呢?因为它有一个致命的“弱点”,那就是归并排序不是原地排序算法。
这是因为归并排序的合并函数,在合并两个有序数组为一个有序数组时,需要借助额外的存储空间。这一点你应该很容易理解。那我现在问你,归并排序的空间复杂度到底是多少呢?是 O(n),还是 O(nlogn),应该如何分析呢?
如果我们继续按照分析递归时间复杂度的方法,通过递推公式来求解,那整个归并过程需要的空间复杂度就是 O(nlogn)。不过,类似分析时间复杂度那样来分析空间复杂度,这个思路对吗?
实际上,递归代码的空间复杂度并不能像时间复杂度那样累加。刚刚我们忘记了最重要的一点,那就是,尽管每次合并操作都需要申请额外的内存空间,但在合并完成之后,临时开辟的内存空间就被释放掉了。在任意时刻,CPU 只会有一个函数在执行,也就只会有一个临时的内存空间在使用。临时内存空间最大也不会超过 n 个数据的大小,所以空间复杂度是 O(n)。
3. 快速排序的原理
我们再来看快速排序算法(Quicksort),我们习惯性把它简称为“快排”。快排利用的也是分治思想。乍看起来,它有点像归并排序,但是思路其实完全不一样。我们待会会讲两者的区别。现在,我们先来看下快排的核心思想。
快排的思想是这样的:如果要排序数组中下标从 p 到 r 之间的一组数据,我们选择 p 到 r 之间的任意一个数据作为 pivot(分区点)。
我们遍历 p 到 r 之间的数据,将小于 pivot 的放到左边,将大于 pivot 的放到右边,将 pivot 放到中间。经过这一步骤之后,数组 p 到 r 之间的数据就被分成了三个部分,前面 p 到 q-1 之间都是小于 pivot 的,中间是 pivot,后面的 q+1 到 r 之间是大于 pivot 的。
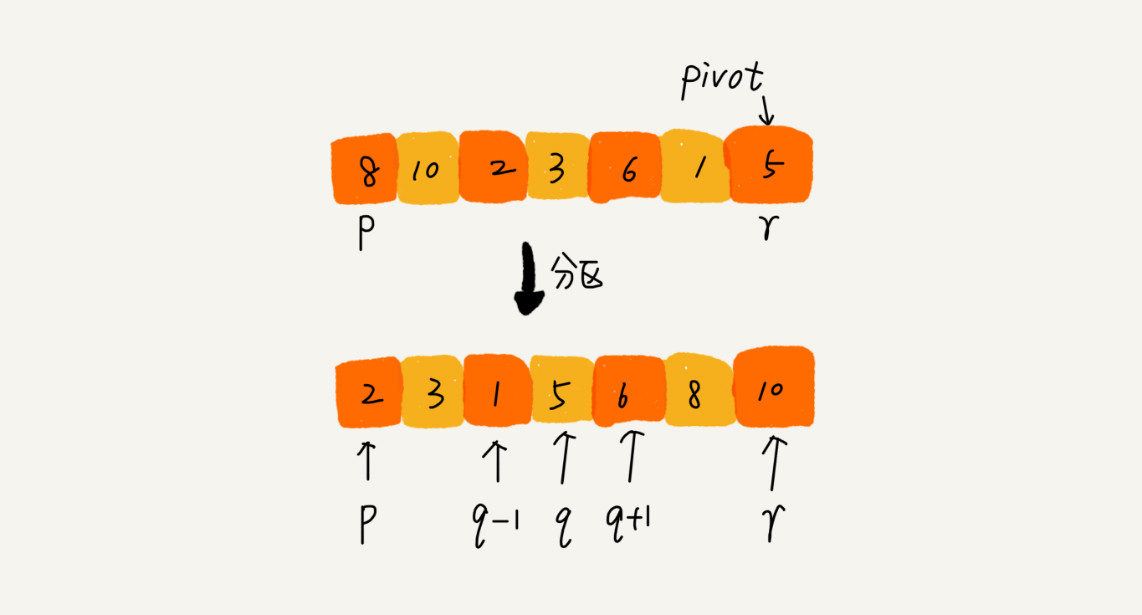
根据分治、递归的处理思想,我们可以用递归排序下标从 p 到 q-1 之间的数据和下标从 q+1 到 r 之间的数据,直到区间缩小为 1,就说明所有的数据都有序了。
如果我们用递推公式来将上面的过程写出来的话,就是这样:
递推公式:quick_sort(p…r) = quick_sort(p…q-1) + quick_sort(q+1… r)终止条件:p >= r
我将递推公式转化成递归代码。跟归并排序一样,我还是用伪代码来实现,你可以翻译成你熟悉的任何语言。
// 快速排序,A是数组,n表示数组的大小quick_sort(A, n) {quick_sort_c(A, 0, n-1)}// 快速排序递归函数,p,r为下标quick_sort_c(A, p, r) {if p >= r then returnq = partition(A, p, r) // 获取分区点quick_sort_c(A, p, q-1)quick_sort_c(A, q+1, r)}
归并排序中有一个 merge() 合并函数,我们这里有一个 partition() 分区函数。partition() 分区函数实际上我们前面已经讲过了,就是随机选择一个元素作为 pivot(一般情况下,可以选择 p 到 r 区间的最后一个元素),然后对 A[p…r]分区,函数返回 pivot 的下标。
如果我们不考虑空间消耗的话,partition() 分区函数可以写得非常简单。我们申请两个临时数组 X 和 Y,遍历 A[p…r],将小于 pivot 的元素都拷贝到临时数组 X,将大于 pivot 的元素都拷贝到临时数组 Y,最后再将数组 X 和数组 Y 中数据顺序拷贝到 A[p…r]。
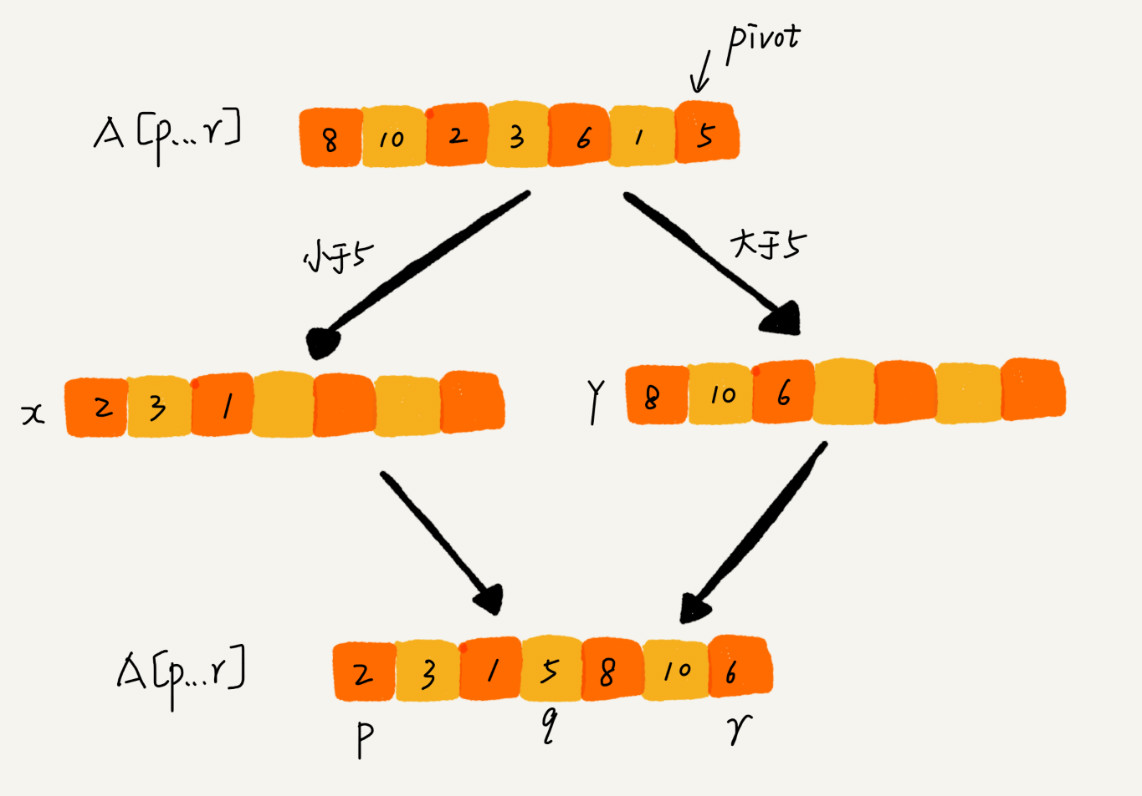
但是,如果按照这种思路实现的话,partition() 函数就需要很多额外的内存空间,所以快排就不是原地排序算法了。如果我们希望快排是原地排序算法,那它的空间复杂度得是 O(1),那 partition() 分区函数就不能占用太多额外的内存空间,我们就需要在 A[p…r]的原地完成分区操作。
原地分区函数的实现思路非常巧妙,我写成了伪代码,我们一起来看一下。
partition(A, p, r) {pivot := A[r]i := pfor j := p to r-1 do {if A[j] < pivot {swap A[i] with A[j]i := i+1}}swap A[i] with A[r]return i
这里的处理有点类似选择排序。我们通过游标 i 把 A[p…r-1]分成两部分。A[p…i-1]的元素都是小于 pivot 的,我们暂且叫它“已处理区间”,A[i…r-1]是“未处理区间”。我们每次都从未处理的区间 A[i…r-1]中取一个元素 A[j],与 pivot 对比,如果小于 pivot,则将其加入到已处理区间的尾部,也就是 A[i]的位置。
数组的插入操作还记得吗?在数组某个位置插入元素,需要搬移数据,非常耗时。当时我们也讲了一种处理技巧,就是交换,在 O(1) 的时间复杂度内完成插入操作。这里我们也借助这个思想,只需要将 A[i]与 A[j]交换,就可以在 O(1) 时间复杂度内将 A[j]放到下标为 i 的位置。
文字不如图直观,所以我画了一张图来展示分区的整个过程。
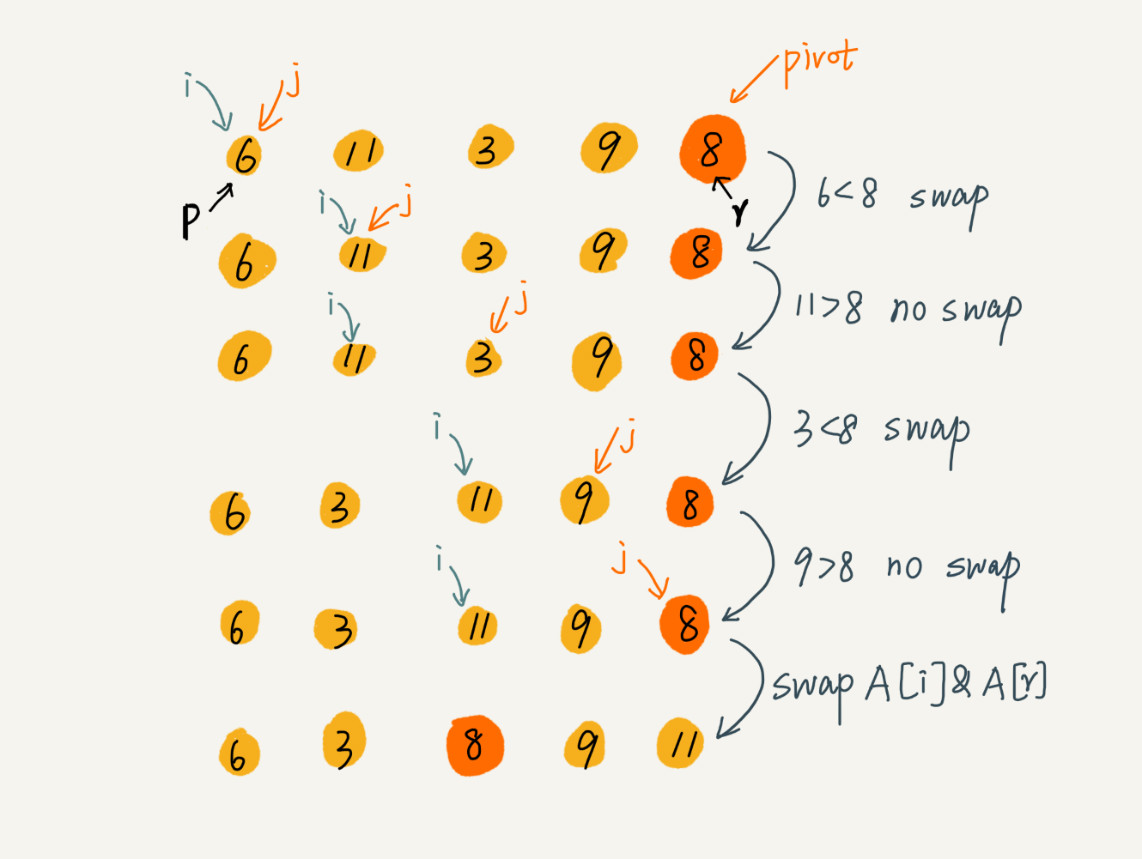
因为分区的过程涉及交换操作,如果数组中有两个相同的元素,比如序列 6,8,7,6,3,5,9,4,在经过第一次分区操作之后,两个 6 的相对先后顺序就会改变。所以,快速排序并不是一个稳定的排序算法。
到此,快速排序的原理你应该也掌握了。现在,我再来看另外一个问题:快排和归并用的都是分治思想,递推公式和递归代码也非常相似,那它们的区别在哪里呢?
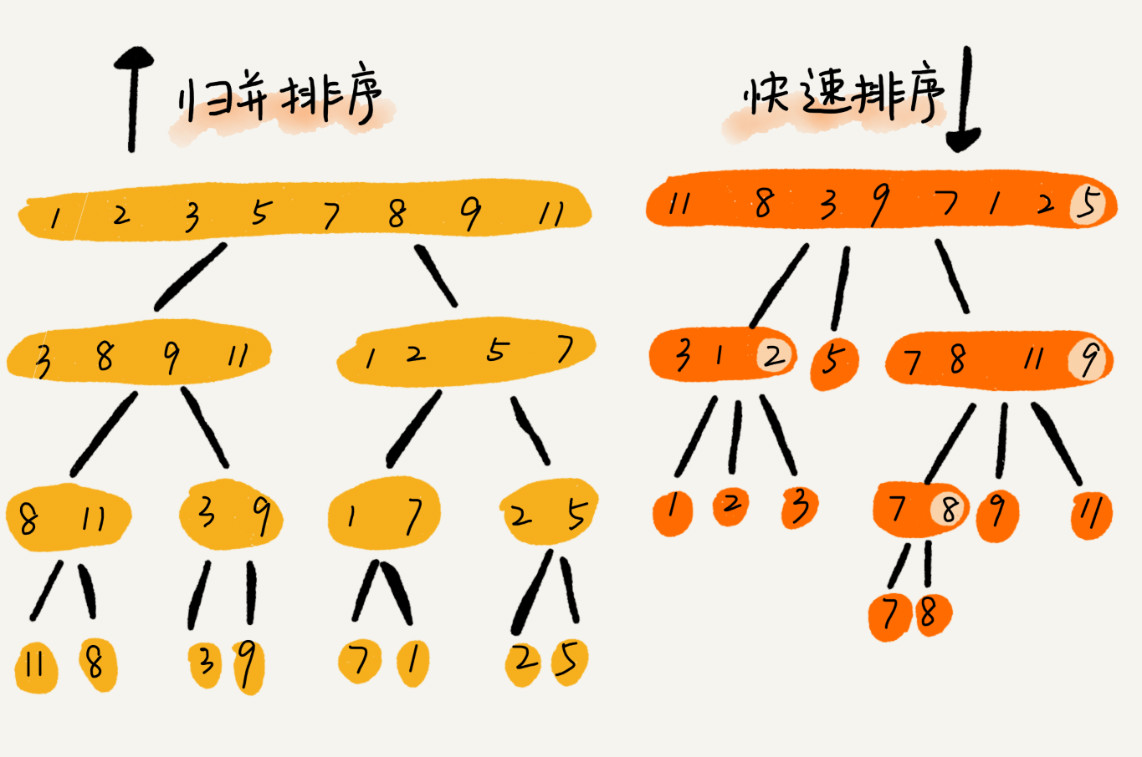
可以发现,归并排序的处理过程是由下到上的,先处理子问题,然后再合并。而快排正好相反,它的处理过程是由上到下的,先分区,然后再处理子问题。归并排序虽然是稳定的、时间复杂度为 O(nlogn) 的排序算法,但是它是非原地排序算法。我们前面讲过,归并之所以是非原地排序算法,主要原因是合并函数无法在原地执行。快速排序通过设计巧妙的原地分区函数,可以实现原地排序,解决了归并排序占用太多内存的问题。
4. 快速排序的性能分析
现在,我们来分析一下快速排序的性能。我在讲解快排的实现原理的时候,已经分析了稳定性和空间复杂度。快排是一种原地、不稳定的排序算法。现在,我们集中精力来看快排的时间复杂度。
快排也是用递归来实现的。对于递归代码的时间复杂度,我前面总结的公式,这里也还是适用的。如果每次分区操作,都能正好把数组分成大小接近相等的两个小区间,那快排的时间复杂度递推求解公式跟归并是相同的。所以,快排的时间复杂度也是 O(nlogn)。
T(1) = C; n=1时,只需要常量级的执行时间,所以表示为C。T(n) = 2*T(n/2) + n; n>1
但是,公式成立的前提是每次分区操作,我们选择的 pivot 都很合适,正好能将大区间对等地一分为二。但实际上这种情况是很难实现的。
我举一个比较极端的例子。如果数组中的数据原来已经是有序的了,比如 1,3,5,6,8。如果我们每次选择最后一个元素作为 pivot,那每次分区得到的两个区间都是不均等的。我们需要进行大约 n 次分区操作,才能完成快排的整个过程。每次分区我们平均要扫描大约 n/2 个元素,这种情况下,快排的时间复杂度就从 O(nlogn) 退化成了 O(n2)。
我们刚刚讲了两个极端情况下的时间复杂度,一个是分区极其均衡,一个是分区极其不均衡。它们分别对应快排的最好情况时间复杂度和最坏情况时间复杂度。那快排的平均情况时间复杂度是多少呢?
我们假设每次分区操作都将区间分成大小为 9:1 的两个小区间。我们继续套用递归时间复杂度的递推公式,就会变成这样:
T(1) = C; n=1时,只需要常量级的执行时间,所以表示为C。T(n) = T(n/10) + T(9*n/10) + n; n>1
这个公式的递推求解的过程非常复杂,虽然可以求解,但我不推荐用这种方法。实际上,递归的时间复杂度的求解方法除了递推公式之外,还有递归树,在树那一节我再讲,这里暂时不说。我这里直接给你结论:T(n) 在大部分情况下的时间复杂度都可以做到 O(nlogn),只有在极端情况下,才会退化到 O(n2)。而且,我们也有很多方法将这个概率降到很低,如何来做?我们后面章节再讲。
5. 解答开篇
快排核心思想就是分治和分区,我们可以利用分区的思想,来解答开篇的问题:O(n) 时间复杂度内求无序数组中的第 K 大元素。比如,4, 2, 5, 12, 3 这样一组数据,第 3 大元素就是 4。
我们选择数组区间 A[0…n-1]的最后一个元素 A[n-1]作为 pivot,对数组 A[0…n-1]原地分区,这样数组就分成了三部分,A[0…p-1]、A[p]、A[p+1…n-1]。
如果 p+1=K,那 A[p]就是要求解的元素;如果 K>p+1, 说明第 K 大元素出现在 A[p+1…n-1]区间,我们再按照上面的思路递归地在 A[p+1…n-1]这个区间内查找。同理,如果 K
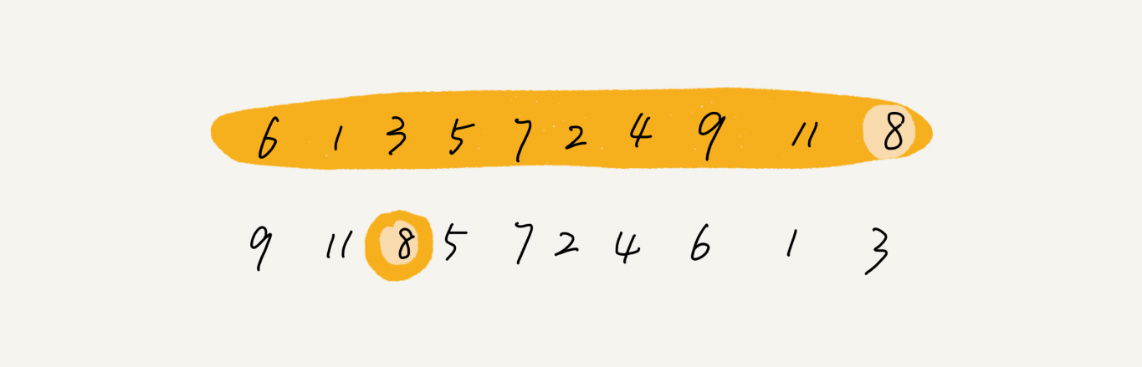
我们再来看,为什么上述解决思路的时间复杂度是 O(n)?
第一次分区查找,我们需要对大小为 n 的数组执行分区操作,需要遍历 n 个元素。第二次分区查找,我们只需要对大小为 n/2 的数组执行分区操作,需要遍历 n/2 个元素。依次类推,分区遍历元素的个数分别为、n/2、n/4、n/8、n/16.……直到区间缩小为 1。
如果我们把每次分区遍历的元素个数加起来,就是:n+n/2+n/4+n/8+…+1。这是一个等比数列求和,最后的和等于 2n-1。所以,上述解决思路的时间复杂度就为 O(n)。
你可能会说,我有个很笨的办法,每次取数组中的最小值,将其移动到数组的最前面,然后在剩下的数组中继续找最小值,以此类推,执行 K 次,找到的数据不就是第 K 大元素了吗?
不过,时间复杂度就并不是 O(n) 了,而是 O(K n)。你可能会说,时间复杂度前面的系数不是可以忽略吗?O(K n) 不就等于 O(n) 吗?
这个可不能这么简单地划等号。当 K 是比较小的常量时,比如 1、2,那最好时间复杂度确实是 O(n);但当 K 等于 n/2 或者 n 时,这种最坏情况下的时间复杂度就是 O(n2) 了。
6. 内容小结
归并排序和快速排序是两种稍微复杂的排序算法,它们用的都是分治的思想,代码都通过递归来实现,过程非常相似。理解归并排序的重点是理解递推公式和 merge() 合并函数。同理,理解快排的重点也是理解递推公式,还有 partition() 分区函数。
归并排序算法是一种在任何情况下时间复杂度都比较稳定的排序算法,这也使它存在致命的缺点,即归并排序不是原地排序算法,空间复杂度比较高,是 O(n)。正因为此,它也没有快排应用广泛。
快速排序算法虽然最坏情况下的时间复杂度是 O(n2),但是平均情况下时间复杂度都是 O(nlogn)。不仅如此,快速排序算法时间复杂度退化到 O(n2) 的概率非常小,我们可以通过合理地选择 pivot 来避免这种情况。

若有收获,就点个赞吧
0 人点赞
