一 原理
scrapy调度系统
https://doc.scrapy.org/en/latest/topics/architecture.html#component-scheduler
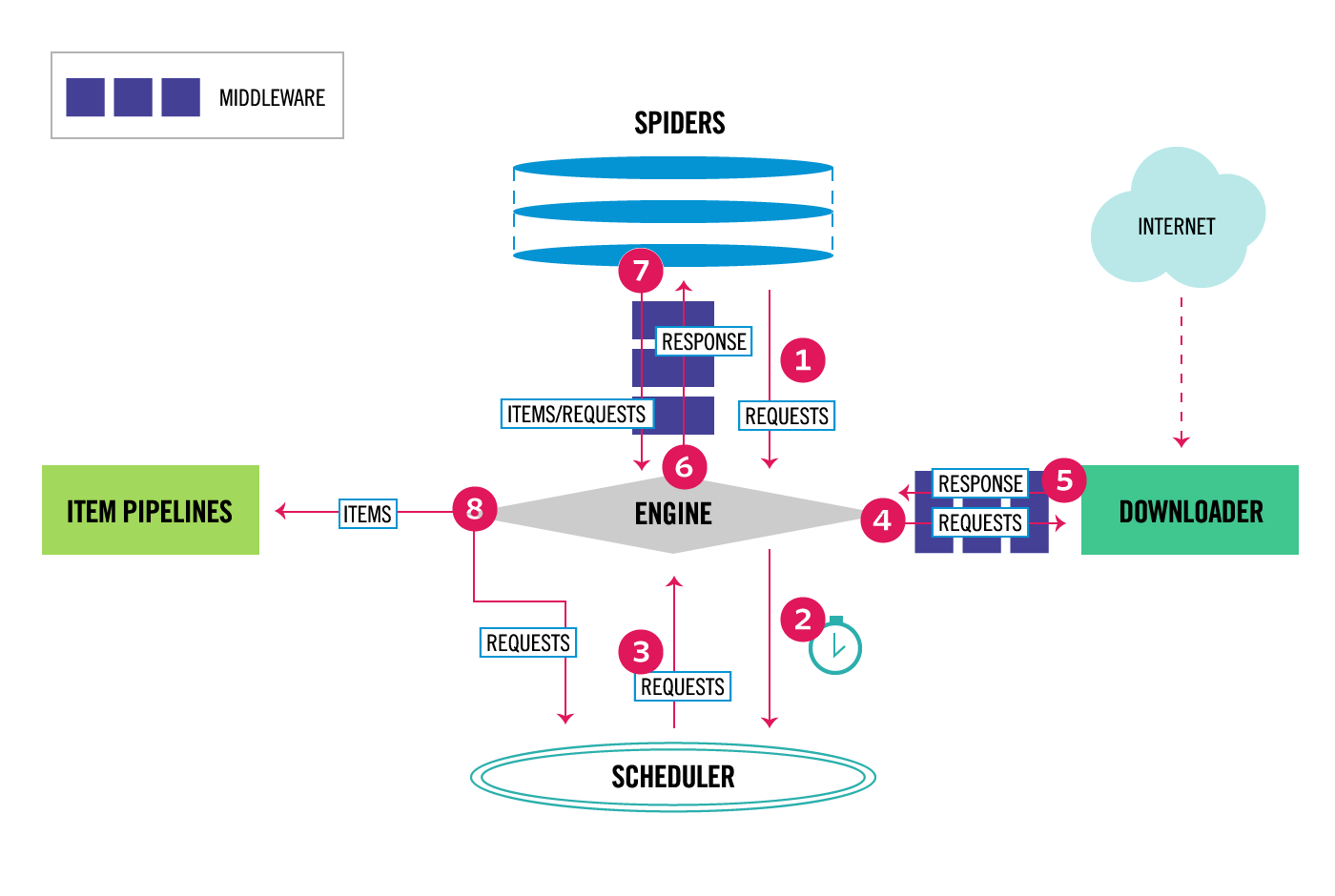
scrapy-redis调度系统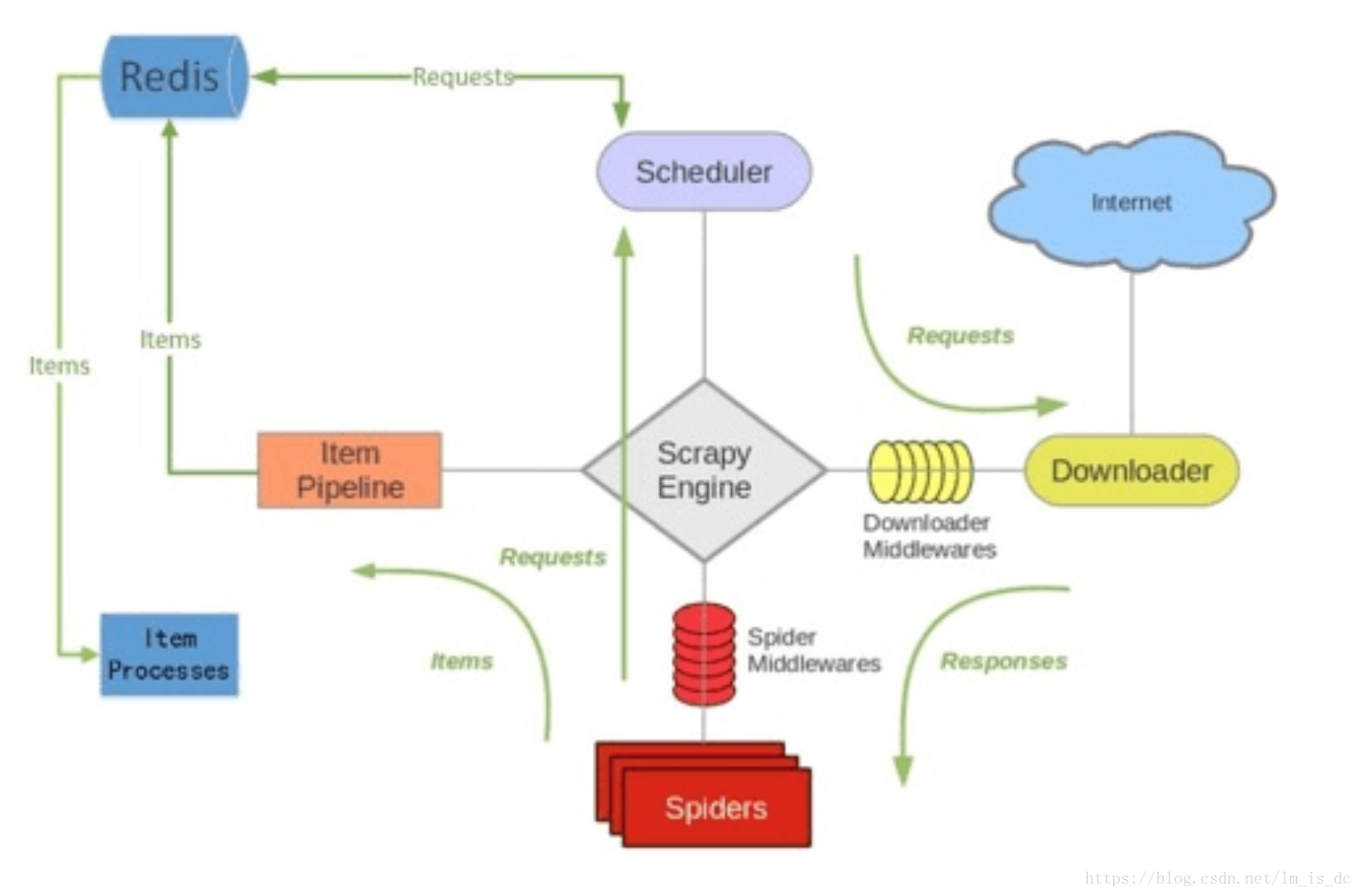
scrapy默认是使用队列来管理请求的URL(存在内存中)
scrapy-redis是使用redis数据库来替代队列,用于URL的管理,去重等
二 安装
1 安装scrapy-reids和redis(CentOS7环境)
redis可视化客户端:https://legacy.gitbook.com/book/fategithub/pythonspider/edit#
pip install scrapy-redis# 先安装remi软件源yum install -y http://rpms.famillecollet.com/enterprise/remi-release-7.rpm# 使用remi源安装最新版的redisyum --enablerepo=remi install redis
2 redis配置和开启
配置文件 /etc/redis.conf
bind 0.0.0.0 # 允许外网访问port 6379 # 默认端口 外网访问还需要配置防火墙requirepass xxx # 开启认证,默认不开启
开启服务
./redis-server
设置开机启动
chkconfig redis on# orsystemctl enable redis.service
三 示例
1 配置文件 settings.py
配置redis服务器 使用scrapy-redis的DUPEFILTER_CLASS和SCHEDULER代替scrapy自带的
# *** Redis连接REDIS_HOST = "xxx.xxx.xxx.xxx"REDIS_PORT = "6379"REDIS_PARAMS = {'password': 'your_password'} # 可选# REDIS_ENCODING = 'utf-8'# *** 使用scrapy-redis组件的去重队列DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"# *** 使用scrapy-redis组件的调度器SCHEDULER = "scrapy_redis.scheduler.Scheduler"# 是否允许暂停(即不清空dupefilter队列)SCHEDULER_PERSIST = True# 等待时间SCHEDULER_IDLE_BEFORE_CLOSE = 5# DUPEFILTER_DEBUG = True
如果想把爬取的数据存到redis数据库中,可使用scrapy-redis的
scrapy_redis.pipelines.RedisPipeline组件
ITEM_PIPELINES = {'lovd.pipelines.LovdPipeline': 300,'scrapy_redis.pipelines.RedisPipeline': 301, # 数值越小,优先级越高}
2 编写爬虫
scrapy的Spider,例如:
class LovdSpiderSpider(scrapy.Spider):
name = 'lovd_spider'
allowed_domains = ['databases.lovd.nl']
方式1:开启爬虫后监听redis_key
from scrapy_redis.spiders import RedisCrawlSpider
class LovdSpiderSpider(RedisCrawlSpider):
name = 'lovd_variants_spider'
redis_key = "lovd_variants_spider:start_urls" # 触发条件, 默认为'spider_name:start_urls'
def parse(self, response):
pass
开启爬虫
scrapy crawl lovd_variants_spider
添加redis_key,爬虫会自动监听redis中key为redis_key的列表,并开始爬取第一个页面
lpush lovd_variants_spider:start_urls https://databases.lovd.nl/shared/variants/in_gene
方式2:重构start_requests函数,自动开始请求
数据可通过meta来传输
base_url = 'https://databases.lovd.nl/shared/variants/in_gene#'
def start_requests(self):
params = {'page': 1}
yield scrapy.Request(self.base_url, meta={'params': params})
def parse(self, response):
if response.meta['params']['page'] < 10: # 结束条件
response.meta['params']['page'] += 1 # 下一页
url = self.base_url + str(response.meta['params']['page'])
response.follow(url, meta=response.meta)
PS: 如果要输出的数据需要通过第一个页面跳转,第一个页面可以不用过滤,dont_filter=True
3 分布式
- 所谓分布式,就是可以把爬虫放到不同的地方启动,多个爬虫共用一个redis,获取要爬取的URL
- 已爬取的URL会转成hash后,存到redis中的一个set中(redis_key:dupefilter),从而实现去重的效果
4 结果数据
不同主机上的爬取结果,如果没有配置ITEM_PIPELINES,只能通过-o的方式输出到各自的主机上
如果想统一输出的一个地方,可以:
- 使用scrapy-redis提供的RedisPipeline,这样每个爬虫都会把结果输出到redis的列表(scrapy_key:items)中,不过这种方式不适合爬取较大的数据(redis是运行在内存的)
- 自己配置Pipeline,如使用MongoDB进行配置
四 问题
scrapy-reids爬虫不能自动停止?
机制就是爬虫监听redis_key,获取到URL就爬 https://stackoverflow.com/questions/45540569/the-scrapy-redis-program-does-not-close-automatically
大数据量下的过滤解决方案?
可以考虑使用bloom filter或者ssdb来进行过滤

若有收获,就点个赞吧
0 人点赞
