初识String
String位于java.lang包中,从JDK1.0时期引入,不需要导包就可以直接使用。一个Java应用程序中使用最多的可能就是String对象了。由于其使用的广泛性,几乎在每一代的JDK优化升级中都存在对String的优化。
- JDK7中字符串常量池从方法区迁移到堆内存中,对字符串常量池容量进行扩容。
- JDK8前String底层存储为char[ ],在JDK9中开始使用byte[ ],减少了存储空间消耗。
接下来基于JDK1.8 HtoSpotVM从常见面试问题、源码、以及存储实现来一探String的原理。
对象创建方式
在Java中,String对象既可以使用字面量(literal)的形式创建,也可以使用new关键字调用构造方法来创建。
String s = new String("starsray");
使用字面量来创建对象,这也是使用最为广泛的一种形式。
String s = "starsray";s = "stars";
查看反编译后的字节码内容
L0LINENUMBER 17 L0LDC "starsray"ASTORE 1L1LINENUMBER 19 L1LDC "stars"ASTORE 1L2LINENUMBER 20 L2RETURN
- LDC Push item from run-time constant pool 如果运行时常量池的entry表示的是一个字符串字面量引用,ldc指令会将引用push到操作数栈中。
- ASTORE 1 Store reference into local variable 弹出栈顶元素,并将栈顶引用类型值保存到局部变量1中,也就是保存到变量 s 中。
- RETURN 执行 void 函数返回。
详情描述可以查看Java虚拟机规范,在HotSpotVM的实现中可能有细微差异,下面通过图示来表示这个过程的变化。
这里需要注意String的不可变性,重新给s赋值时,会产生一个新的String对象,并不会影响到原来的值。理解这一点,接下来看一些通常关于String对象的引用问题。
public static void main(String[] args) {String s1 = "starsray";String s2 = "starsray";String s3 = s1;String s4 = new String("starsray");String s5 = new String("starsray");System.out.println(s1 == s2);System.out.println(s1 == s3);System.out.println(s1 == s4);System.out.println(s4 == s5);System.out.println(s4.equals(s5));}
输出结果:
truetruefalsefalsetrue
输出结果是否和你预测的一样,这里还要补充一点Java中==和equals比较的区别。
- ==,基本数据类型比较的是值是否相等,引用数据类型比较的是引用值是否相等
equals(),该方法时Object中的方法,如果没有重写,则比较的是引用指向是否相等,String重写了该方法,先比较引用指向,如果不相等会继续比较存储的值是否相等。此外equals不能用于基本数据类型的比较,但是基本数据类型的包装类可以使用equals比较,包装类都重写了该方法。
public boolean equals(Object anObject) {if (this == anObject) {return true;}if (anObject instanceof String) {String anotherString = (String)anObject;int n = value.length;if (n == anotherString.value.length) {char v1[] = value;char v2[] = anotherString.value;int i = 0;while (n-- != 0) {if (v1[i] != v2[i])return false;i++;}return true;}}return false;}
源码初探
接下来查看String源码,String类实现了序列化、Comparable以及CharSequence接口
public final class Stringimplements java.io.Serializable, Comparable<String>, CharSequence {// 在JDK1.8中String的值使用char[]数组保存private final char value[];// 使用私有成员变量hash来缓存String的哈希值private int hash; // Default to 0// 构造方法public String(String original) {this.value = original.value;this.hash = original.hash;}public String(char value[]) {this.value = Arrays.copyOf(value, value.length);}...省略}
从源码中可以得到一些关键信息整个String类是final的,存储String的数组也被设计为final的,在Java中使用final修饰类,意味着这个类不可被继承,而且所有的成员方法默认为final的,不可被重写,很多框架在设计时候关键类也都是final的,Java的双亲委派机制,一定程度上保证了代码的安全,使用final修饰成员变量,意味着引用不可变,这样说明了String是不可变的。
继续查看String一些常用的方法,String的截取、替换、拼接最终都会返回一个新的String对象,并且调用操作系统层面的Arrays copy方法拷贝数组,不会影响到原来的对象。
public String substring(int beginIndex) {if (beginIndex < 0) {throw new StringIndexOutOfBoundsException(beginIndex);}int subLen = value.length - beginIndex;if (subLen < 0) {throw new StringIndexOutOfBoundsException(subLen);}return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);}public String substring(int beginIndex, int endIndex) {if (beginIndex < 0) {throw new StringIndexOutOfBoundsException(beginIndex);}if (endIndex > value.length) {throw new StringIndexOutOfBoundsException(endIndex);}int subLen = endIndex - beginIndex;if (subLen < 0) {throw new StringIndexOutOfBoundsException(subLen);}return ((beginIndex == 0) && (endIndex == value.length)) ? this: new String(value, beginIndex, subLen);}public String replace(char oldChar, char newChar) {if (oldChar != newChar) {int len = value.length;int i = -1;char[] val = value; /* avoid getfield opcode */while (++i < len) {if (val[i] == oldChar) {break;}}if (i < len) {char buf[] = new char[len];for (int j = 0; j < i; j++) {buf[j] = val[j];}while (i < len) {char c = val[i];buf[i] = (c == oldChar) ? newChar : c;i++;}return new String(buf, true);}}return this;}public String concat(String str) {if (str.isEmpty()) {return this;}int len = value.length;int otherLen = str.length();char buf[] = Arrays.copyOf(value, len + otherLen);str.getChars(buf, len);return new String(buf, true);}
小结
String对象一旦创建就是不可变的,而且String对象的HashCode会被缓存起来,相关的操作都会产生一个新的不可变对象,新对象的操作不会影响到原来对象的值,这些特性也说明String天然合适作为HashMap的key。
存储原理
深入了解String的底层原理,首先要明确String对象创建方式的差异、类加载时机、以及常量池等相关的概念。《Java虚拟机规范》中明确了部分规定,但是并没有要求细节怎么实现,在不同厂商的Java虚拟机中实现也千差万别,相同厂家的不同版本中也在不停的演变,接下来的所有内容都是基于HotSpotVM JDK8进行分析。
基础准备
String对象的创建不同于其他对象,需要了解常量池、类加载过程、以及Class文件格式的基本知识,再去理解创建过程。
常量池
说到常量池,需要先说明一下Java虚拟机运行时的数据区,方法区(Method Area)与Java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据。它还有一个别名叫作“非堆”(Non-Heap),目的是与Java堆区分开来。此外还要明确永久代(Permanent Generation)的概念,容易把永久代和方法区混淆,JDK 7的HotSpot,已经把原本放在永久代的字符串常量池、静态变量等移出到堆内存,使用StringTable(本质是一个Hash表)来存储,而到了JDK 8,完全废弃了永久代的概念,改用与JRockit、J9一样在本地内存中实现的元空间(Meta-space)来代替。关于常量池还可以做如下细分:
- class文件常量池:在class文件中保存了一份常量池(Constant Pool),主要存储编译时确定的数据,包括代码中的字面量(literal)和符号引用。
- 运行时常量池:位于方法区中,全局共享,class文件常量池中的内容会在类加载后存放到方法区的运行时常量池中。除此之外,在运行期间可以将新的变量放入运行时常量池中,相对class文件常量池而言运行时常量池更具备动态性。
- 字符串常量池:位于堆中,全局共享,这里可以先认为它存储的是String对象的直接引用,而不是直接存放的对象,具体的实例对象是在堆中存放。
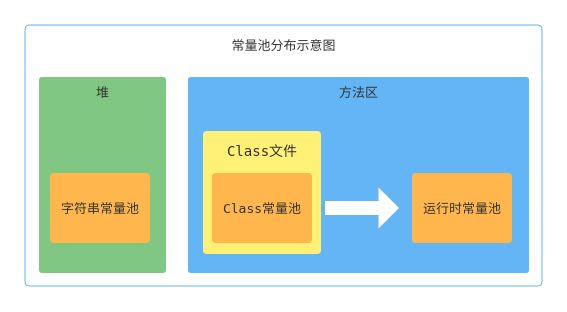
Class文件格式
Java虚拟机规范中严格定义了Class文件的格式,Class文件是一组以8个字节为基础单位的二进制流,各个数据项目严格按照顺序紧凑地排列在文件之中,整体结构也可以看作是一个繁琐的表。整个Class文件常量池中定义了String的表示方法,由CONSTANT_String_info来表示。
CONSTANT_String_info {u1 tag;u2 string_index;}
- tag 一个字节的标志位,value(8),表示这是一个CONSTANT_String_info结构的常量。
- string_index 必须是constant_pool表中包含的有效索引,常量池中此索引下的entry必须为 CONSTANT_Utf8_info结构体。
查看CONSTANT_Utf8_info结构体的具体内容,在HotSpotVM中,CONSTANT_Utf8_info可以表示Class文件的方法、字段等信息。
CONSTANT_Utf8_info {u1 tag;u2 length;u1 bytes[length];}
- u1 表示一个无符号字节,u2表示2个无符号字节,以此类推。
- tag 1个字节的标志位,value(1),表示这是一个CONSTANT_Utf8_info结构的常量。
- length 表示存储字符串内容的长度,有多少个字节,u2表示2个字节,因此字符串所能表示的最大长度为2^16-1=65535。
- bytes 表示存储字符串内容的字节数组,可能包含很多个字节。
通过IDEA插件jclasslib来查看编译后的字节码,可以看到编译后的常量池包含了两个CONSTANTString_info的结构体,对应在常量池中的索引位置分别为02、03,02和03又对应了索引为24和25的CONSTANT_Utf8_info结构体。

其在Class常量池中的存储结构如下图所示。
类加载过程
Java虚拟机在执行某个类的时候,必须经过加载、链接(验证、准备、解析)、初始化,在第一步加载的时候需要完成以下几个步骤
- 通过一个类的全限定名来获取定义此类的二进制字节流。
- 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
- 在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
加载阶段结束后,Java虚拟机外部的二进制字节流就按照虚拟机所设定的格式存储在方法区之中了,在进行2的时候会把Class文件常量池的数据存储到运行时常量池。多个Class文件的常量池共享一个运行时常量池,这也是一种优化。
对于String类型,字面量(literal)字符串什么时候会被放入到字符串常量池中?
通过查阅参考资料这里总结了一段结论,这一段结论可以记住,接下来会对此结论进行分析。
在HotSpot VM的实现中,源文件中的字面量字符串在编译期就已经确定会进入到Class文件常量池中,Class常量池中的字符串在类加载阶段会被加载到运行时常量池,并不会直接进入到字符串常量池,即在StringTable中并没有相应的引用,在堆中也没有对应的对象产生,但最终会在堆中实例化对象,并且维护这个字符串的引用到StringTable中,这个过程是lazy的;通过new关键字创建的对象,是在运行期才能确定,会在堆上创建对象并实例化。

上面图示简单描述了String对象两种创建方式在类加载阶段及运行过程中的处理方式,Java虚拟机规范中只是定义了Class文件格式,以及运行时数据区的数据布局,但是在具体的虚拟机实现中还是会存在差异。对于上述过程需要注意和了解的是:
- 在HotSpotVM实现中,CONSTANT_Utf8会在类加载的过程中就全部创建出来,CONSTANT_String则是lazy resolve的,在第一次引用该项的ldc指令被第一次执行到的时候才会resolve。在未resolve的时候,HotSpot VM把它的类型叫做JVM_CONSTANT_UnresolvedString,内容跟Class文件里一样只是一个index;当resolve过后这个项的常量类型就会变成最终的JVM_CONSTANT_String。
- 在HotSpot VM的实现中,类加载时,字符串字面量会进入到当前类的运行时常量池,不会进入全局的字符串常量池(即在StringTable中并没有相应的引用,在堆中也没有对应的对象产生),在执行ldc指令时,触发lazy resolution这个动作。
- 关于ldc指令,在Java虚拟机规范中的描述比较简约,不同虚拟机实现有所不同,HotSpot实际的执行语义是:到当前类的运行时常量池(HotSpot VM里是ConstantPool + ConstantPoolCache)去查找该index对应的项,如果该项尚未resolve则resolve之,并返回resolve后的内容。在遇到String类型常量时,resolve的过程如果发现StringTable已经有了内容匹配的java.lang.String的引用,则直接返回这个引用,反之,如果StringTable里尚未有内容匹配的String实例的引用,则会在Java堆里创建一个对应内容的String对象,然后在StringTable记录下这个引用,并返回这个引用出去。可见,ldc指令是否需要创建新的String实例,全看在第一次执行这一条ldc指令时,StringTable是否已经记录了一个对应内容的String的引用。
实际问题分析
上面引申了一些列关于JVM相关的内容,接下来回到String创建对象的两种方式,针对具体的案例进行实际分析。String对象最大长度是多少
查看String源代码返回长度的方法,int类型所能表示的最大范围为[0, 2^31-1],实际根据String的两种创建方式还有所不同。
/*** Returns the length of this string.* The length is equal to the number of <a href="Character.html#unicode">Unicode* code units</a> in the string.** @return the length of the sequence of characters represented by this* object.*/public int length() {return value.length;}
使用字面量方式创建对象时javac编译会校验字符串的长度,0xFFFF所能表示的最大长度为2^16=65536,因此这种方式创建的字符串长度会小于65536。而且CONSTANT_Utf8_info型常量的最大长度是是65535 - 1 = 65534个字节,若是中文字符,长度为65535 / 3字节。如果运行时方法区设置的比较小,实际长度可能达不到理论字节。
/** Max number of char in a string constant. */public static final int MAX_STRING_LENGTH = 0xFFFF;.../** Check a constant value and report if it is a string that is* too large.*/private void checkStringConstant(DiagnosticPosition pos, Object constValue) {if (nerrs != 0 || // only complain about a long string onceconstValue == null ||!(constValue instanceof String) ||((String)constValue).length() < PoolWriter.MAX_STRING_LENGTH)return;log.error(pos, Errors.LimitString);nerrs++;}
使用new关键字创建对象时,对象在堆内存中分配空间,调用系统的copyOf(),方法,所支持的理论最大长度为Integer.MAX_VALUE,2^31-1;实际情况受虚拟机和堆内存的大小限制。
接下来对上面两种方式进行验证长度。
public static void main(String[] args) {char [] str = new char[Integer.MAX_VALUE];new String(str);}
输出结果
Exception in thread "main" java.lang.OutOfMemoryError: Requested array size exceeds VM limitat Hello.main(Hello.java:9)
创建了几个对象
场景1
String s1 = new String("starsray");
查看反编译字节码
L0LINENUMBER 5 L0NEW java/lang/StringDUPLDC "starsray"INVOKESPECIAL java/lang/String.<init> (Ljava/lang/String;)VASTORE 1L1LINENUMBER 6 L1RETURNL2LOCALVARIABLE args [Ljava/lang/String; L0 L2 0LOCALVARIABLE s Ljava/lang/String; L1 L2 1MAXSTACK = 3MAXLOCALS = 2
其实单纯的针对这种问题回答创建了几个对象,并没有太多实际意义,更合理的应该说关联了几个对象引用,这个时候一般是说2个,一个是字符串字面量”starsray”所对应的、驻留(intern)在一个全局共享的字符串常量池中的实例,另一个是通过new String(“starsray”)创建并初始化的、内容与”starsray”相同的实例。
具体可以查看上面图示,结合字节码的内容也可以看出LDC会检索在字符串常量池中是否存在相同内容的引用,如果没有会创建一个实例,并将引用维护在StringTable中,其次INVOKESPECIAL会通过构造方法创建一个与字符串常量池内容相同的新的对象实例。场景2
String s1 = "starsray";
查看编译后的字节码
L0LINENUMBER 5 L0LDC "starsray"ASTORE 1L1LINENUMBER 6 L1RETURNL2LOCALVARIABLE args [Ljava/lang/String; L0 L2 0LOCALVARIABLE s Ljava/lang/String; L1 L2 1MAXSTACK = 1MAXLOCALS = 2
这种场景就不多解释了,LDC指令在检索常量池中是否存在需要创建的字符串,如果没有就创建,因此这里只会创建一个对象。
场景3
String s1 = "starsray";String s2 = new String("starsray");
先查看编译后的字节码
L0LINENUMBER 5 L0LDC "starsray"ASTORE 1L1LINENUMBER 6 L1NEW java/lang/StringDUPLDC "starsray"INVOKESPECIAL java/lang/String.<init> (Ljava/lang/String;)VASTORE 2L2LINENUMBER 7 L2RETURNL3LOCALVARIABLE args [Ljava/lang/String; L0 L3 0LOCALVARIABLE s1 Ljava/lang/String; L1 L3 1LOCALVARIABLE s2 Ljava/lang/String; L2 L3 2MAXSTACK = 3MAXLOCALS = 3
这种场景下,就考验对上述结论的应用了,字节码中可以看到进行了2次LDC指令和INVOKESPECIAL指令操作,L0中LDC是针对s1的,这次操作没有在常量池检索到字符串starsray,因此会在堆中创建一个对象,而L1中LDC时已经检索到了,因此就不会再创建对象,结果应该是创建了两个对象。
String::intern方法
String的intern()是一个本地方法,可以强制将String驻留进入字符串常量池,可以分为两种情况:
如果字符串常量池中已经驻留了一个等于此String对象内容的字符串引用,则返回此字符串在常量池中的引用。
- 如果未驻留,在常量池中创建一个引用指向这个String对象,然后返回常量池中的这个引用。
使用下面一段代码验证
public static void main(String[] args) {String s1 = new String("starsray");String s2 = s1.intern();System.out.println(s1 == s2);System.out.println(s1 == "starsray");System.out.println(s2 == "starsray");}
输出结果
falsefalsetrue
“a”+”b”+”c”问题
这个问题是关于字符串拼接的问题,前面已经说到了String的不可变性,再结合字面量创建对象的特点。
String s = "s"+"t"+"a"+"r"+"s";
查看反编译后的内容
public class Hello {public Hello() {}public static void main(String[] args) {String s = "stars";}}
在HotSpotVM的实现中针对这种情况,编译器使用了一种叫做常量折叠(Constant Folding)的优化技术。
常量折叠会将编译期常量的加减乘除的运算过程在编译过程中折叠。编译器通过语法分析,会将常量表达式计算求值,并用求出的值来替换表达式,而不必等到运行期间再进行运算处理,从而在运行期间节省处理器资源。
编译期常量的特点就是它的值在编译期就可以确定,并且需要完整满足下面的要求,才可能是一个编译期常量:
- 被声明为final
- 基本类型或者字符串类型
- 声明时就已经初始化
- 使用常量表达式进行初始化
这里就不再深入研究了,有兴趣的可以查看Oracle官网关于常量的定义。
总结
这篇文章主要对String的基本使用,存储原理,常见问题进行了简单分析,实际使用中可能不需要关注这些细节,而且在不同的JDK版本实现中也是有很大差别的,比如JDK7以前字符串常量池在永久代,JDK6之前字符串常量池存储的是对象实例,而JDK8字符串常量池又被迁移到堆内存,永久代被元空间取而代之,Java的变更日新月异,如今已经发展到JDK17,有时候在网上查到的东西没有绝对的对错,关键是抱有一颗试错、探索、求证的心态。
参考资料:

若有收获,就点个赞吧
0 人点赞

{kind=link}