- java start 如何调用到run方法
- synchronized 关键字的底层原理,synchronize锁是如何实现的?
- wait
- notify 和 notifyAll区别
- synchronize锁优化锁膨胀过程?
- AQS原理
- ReentrantLock 和 synchronized 区别
- Lock 高级功能?
- 简述下CAS?
- CAS虽然高效的解决了原子操作问题,但仍然存在三大问题:
- 1.ABA问题:如果变量V初次读取的时候值是A,后来变成了B,然后又变成了A,你本来期望的值是第一个A才会设置新值,第二个A跟期望不符合,但却也能设置新值。
- 2.无限循环问题(自旋):看源码可知,Atomic类设置值的时候会进入一个无限循环,只要不成功,就会不停的循环再次尝试。在高并发时,如果大量线程频繁修改同一个值,可能会导致大量线程执行compareAndSet()方法时需要循环N次才能设置成功,即大量线程执行一个重复的空循环(自旋),造成大量开销。
- 3.多变量原子问题:只能保证一个共享变量的原子操作。一般的Atomic类,只能保证一个变量的原子性,但如果是多个变量呢?
- interrupt()方法 中断几种 区别
- Runnale 和 Callable 区别
- 线程的几种状态?
- 线程池几种状态?
- 线程池参数介绍?
- 线程池的分发
- 几种线程池
- 线程池的饱和策略
- submit() 和 execut()区别?
- 线程池是如何做到线程复用的?
- 空闲线程超时销毁如何实现的?
- FutureTask
- Threadlocal起什么作用?
- Threadlocal内部实现原理
- JMM
- 硬件层面原理
- 你知道Java内存模型中的原子性、有序性、可见性是什么吗?
- synchronized关键字,同时可以保证原子性、可见性以及有序性的
- volatile关键字有什么作用?
- double check单例实践
- 防止指令重排序有什么好处?如何实现防止指令重排序的?
java start 如何调用到run方法
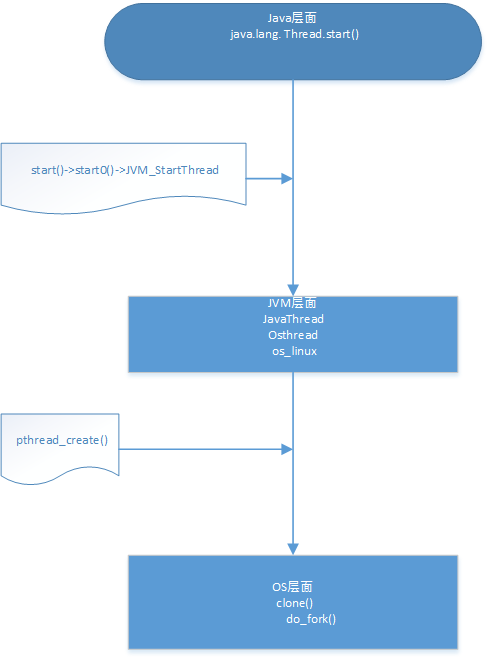
java层面: start -> start0() -> native start0()
C(jvm)层面: JVM_StartThread()
OS层面: pthread_create() 这里会回调jvm的run方法
java调用 native方法,native 方法对应着 头文件,头文件会动态链接到 c文件,c文件会调用 系统函数。
synchronized 关键字的底层原理,synchronize锁是如何实现的?
- 首先每个类都由Objec派生出,每个对象都有ObjectMonitor,当线程发生同步,会去尝试将ObjectMonitor 的 owner 设置为自己,如果没有获得就会进入entryList中。
- 获取锁,monitor 的计数器就会加1,owner 就指向当前线程。同时synchronized 是支持重入锁,也就是同一个线程对同一个对象多次加锁。每加锁一次,计数器就会加1。
- 获取锁,线程进入同步块,虚拟机就会设置 monitorenter进入同步块,退出同步就会设置为monitorexit,为了防止同步中出现异常,设置了第二个monitorexit。
- 当退出同步,计数器就变为 0,owner 设置为 null,entryList中线程就会CAS去竞争获取对象monitor关联的锁。只有一个线程可以获取到锁。
- 当遇到wait就将同步的线程放入waitSet中。
- 当对象调用notify,就会随机从waitSet取一个线程,放到entryList中,然后线程去竞争monitor。
- 当对象调用notifyAll,就会从waitSet将持有该对象的所有的线程,放到entryList中,然后线程去竞争monitor。
wait
wait 会将线程从entryList 放回到waitSet中。notify 和 notifyAll区别
notify 会从waitSet《等待队列》中随机拿取那一个线程放到entryList《阻塞队列》中
notifyAll 会将waitSet所有线程都放到entryList中,唤醒哪个不确定,因为不确定谁竞争到了monitor。synchronize锁优化锁膨胀过程?
首先synchronize的锁的状态在对象头中。
64位jdk 对应的 对象头中一共128个字节。 64个字节为 mark word 64个字节为klass word。我们主要看 mark word 结构。
无锁:主要的头信息 lock(锁状态) : 01 2个字节,biased_lock(是否偏向锁)1个字节:0,年轻代年龄:4个字节(用于晋升到老年代阈值),indentity_hashcode:对象标识hash码 31个字节 剩下的 26字节没有用。
偏向锁:主要的头信息 lock: 01,biased_lock:1,thread:54位 当先线程id,age:4字节,剩下1字节没有用
轻量锁:主要的头信息 lock:00
重量锁:主要的头信息 lock:10
GC:主要的头信息 lock:11
对象头我们可以使用 openjdk 的 jol插件测试打印头信息。
- 从无锁到偏向锁
- 默认开启延迟偏向锁,jvm运行默认超过4s,那么对象就会开启偏向锁。
当第一个线程来访问它的时候,它会修改 ThreadId 改为当前线程的id,之后再访问这个对象时,只要对比ThreadID,一样就不会再CAS。
他默认第一次会调用os加锁。可以修改 os上锁函数 打印系统线程id,再修改C文件 打印 c的线程id。当开启一个线程,然后同步只打印一次 系统线程id和 c的线程id。而开启两个线程,对同一个对象加锁,会发现 系统线程id和c的线程id 同步打印。
多个线程通过CAS来获取锁,偏向上个拥有的线程,是乐观锁。
一般是单个线程执行
- 从偏向锁到轻量级锁
- 当前为无锁,直接修改为轻量级锁。
- 当前为偏向锁,并且偏向的线程不是当前线程,他会判断该锁的偏向线程是否存活,没有存活,将偏向锁变为无锁。然后变为轻量级锁。
多个线程,通过CAS来获取锁,是乐观锁。
一般是多个线程,交替执行。
- 从轻量级锁到重量级锁
- 轻量级锁自旋一定次数或者一个线程在持有锁,一个在自旋,另外一个线程来访时,轻量级膨胀为重量级锁。
- 对象调用了wait()也会变为重量级锁。
重量级锁,是调用了os函数加锁,使除了拥有锁的线程以外的线程都是阻塞,防止 CPU 空转,是悲观锁。
一般是多个线程,竞争执行。
AQS原理
AQS 全称 AbstractQueuedSynchronizer 抽象的队列同步器。他是一个抽象类。
AQS 通过 CLH 队列 一个带有虚拟头节点的双向链表,来唤醒线程是否可以竞争获取锁。
他主要有两种方式:一种是独占方式:只有一个线程能执行;一种是共享方式,多个线程可以同时执行。
我主要研究了独占方式的AQS 实现,ReentrantLock的实现方式。
ReentrantLock中 有个 内部类也就 sync 类,他继承了 AQS抽象类。
AQS 结构:head 头结点,tail 尾结点,state 加锁次数,exclusiveOwnerThread 当前占有锁的线程。
Node 结构: pre 上个节点,next 下个节点,waitState 节点等待状态,node当前线程。
lock加锁步骤:整体步骤 尝试加锁 tryAcquire(),封装线程为node 初始化队列,唤醒队列竞争锁,重置interrupt状态。
尝试加锁 tryAcquire()
- 首先调用tryAcquire ,主要判断 aqs 中的 state 是否 0 ,为0 两种情况一种是 长时间为自由锁状态,一种是 短暂刚释放锁到自由锁状态
- 如果为 0 ,判断是否有 head 和 head 是否有 next 节点 并且 node 线程是否是当前线程 。主要目的就是判断是否有队列,以及第二节点是否为当前节点。
- 如果没有队列或者下个node 当前线程,直接CAS 尝试获取锁。获取锁成功返回 true,失败返回fasle。
- 然后判断是否是重入锁,也就是判断当前线程是否是 aqs 中占有锁的线程。如果是重入锁 state +1 返回 true
- 其他情况,有队列且不是重入锁,且第二个节点线程不是当前线程,返回false。
封装线程为node 初始化队列
- 先将当前线程,封装成 node。
- 判断 head 是否为 null。
- 不为 null 说明已经存在队列,直接设置 node pre 为 tail,自己设置为新 tail。
- 为 null 说明不存在队列,直接死循环进行以下步骤
- 先判断 tail 是否为null,为 null 通过 CAS 设置一个空节点, 赋值给 head。同时 tail = head。
- 如果 tail 不为 null ,将 node 的 pre 设置为 tail,同时 CAS 将 node 设置为 新 tail。跳出循环
唤醒队列竞争锁
- 死循环,判断当前节点 pre 是否是 head ,目的是判断自己是否为 队列的第二个节点。
- 如果是 队列的第二个节点,就CAS 尝试获取锁,走 tryAcquire()方法。
- 获取锁成功,aqs 就是当前node的线程,设置 当前 node 为head ,旧的 head 断开连接,方便 gc回收。
- 获取失败走下面步骤。
- 获取失败 或者 不是第二个节点
- 首先将 上个节点 设置为 waitState 为 -1,默认waitState 为 0。目的是为了解锁用。
- 然后再次循环到这里,执行LockSupport.park(),等待被唤醒。
- 如果被唤醒,会调用 Thread.interrupted()返回false 到循环中。
- 被唤醒后继续走,循环逻辑尝试获取锁。
- 出现异常,会走 finally 取消当前线程获取锁。
重置 interrupt,当Thread.interrupted 为false,主要目的是为了保持线程的 interrupt 的状态一致。
非公平锁会上来就尝试获取锁,获取锁失败就走公平锁逻辑,也就是一朝排队,永久排队。
unlock解锁步骤:公平锁和非公平锁一致。
- unLock(),调用AQS的 release(1),解锁。
- 尝试解锁,tryRelease(),该方法返回 true 解锁成功,false 解锁失败。
- 首先 state -1 得到 c。
- 当前线程不是 AQS 中占有锁的线程,直接抛异常。
- c = 0 解锁成功。将 AQS 的 站有锁的线程设置为null,其他情况 返回 false。(比如重入锁 state -1 可能大于 0)
- 解锁成功,则需要判断是否需要唤醒其他节点。
- 通过 是否有 head 判断是否存在队列,因为只有一个线程 可能不会初始化队列。没有队列不需要唤醒。
- 有队列,再判断 head 的waitState 是否为 0,不等于 0 说明 队列还有其他节点需要唤醒, 等于 0, head 为 tail ,队列不需要唤醒。
- 在判断head next 节点正常情况是 next node 不为 null,且waitState 为 <= 0 ,直接LockSupport.unPack()唤醒下个一个节点。
- 极端情况 next node 可能为 null 或者 next node 的 > 0(比如放弃索取线程。),那么我们可以通过从链表尾往前遍历,找到离当前 node 后面最近的节点,且该node 的 waitState <= 0;
ReentrantLock 和 synchronized 区别
- 相同点
- 都实现了多线程同步和内存可见性语义。
- 都是可重入锁。
- 不同点
- 同步实现机制不同
synchronized通过 Java 对象头锁标记和 Monitor 对象实现同步。- ReentrantLock 通过CAS、AQS(AbstractQueuedSynchronizer)和 LockSupport(用于阻塞和解除阻塞)实现同步。
- 使用方式不同
synchronized可以修饰实例方法(锁住实例对象)、静态方法(锁住类对象)、代码块(显示指定锁对象)。- ReentrantLock 显示调用 tryLock 和 lock 方法,需要在
finally块中释放锁。
- 功能丰富程度不同
synchronized不可设置等待时间、不可被中断(interrupted)。- ReentrantLock 提供有限时间等候锁(设置过期时间)、可中断锁(lockInterruptibly)、condition(提供 await、signal 等方法)等丰富功能
- 锁类型不同
synchronized只支持非公平锁。- ReentrantLock 提供公平锁和非公平锁实现。
Lock 高级功能?
CountDownLatch
减法计数器,减为0,执行本线程任务
场景: 某个线程,需要等其他线程执行完,再继续执行。(当设置了await时间,那么时间到了主线程就继续执行了。)CyclicBarrier
加分计数器,循环屏障
场景:当前线程任务,需要等其他线程全部到达,再一起执行。Semaphore
停车场
场景: 同一时间可执行固定数量的线程。(acquire()是并发执行,如果是tryAcquire()则不一定是并发执行,可能会串行执行)读写锁
不同线程,读读不互斥,其他都互斥。简述下CAS?
CAS有三个参数,第一个参数是指针(原来的值),第二参数是预期值,第三个参数是新值。
首先拿到旧值,然后比较交换的时候,判断预期值是不是旧值,如果一样就赋值为新值,否则就不交换。
因为CAS在主要是 MESI协议,将高速缓存区的对应要修改的条目加独占锁,通过总线通知其他的处理器,然后来比较修改。CAS虽然高效的解决了原子操作问题,但仍然存在三大问题:
1.ABA问题:如果变量V初次读取的时候值是A,后来变成了B,然后又变成了A,你本来期望的值是第一个A才会设置新值,第二个A跟期望不符合,但却也能设置新值。
针对这种情况,java并发包中提供了一个带有标记的原子引用类AtomicStampedReference,它可以通过控制变量值的版本号来保证CAS的正确性,比较两个值的引用是否一致,如果一致,才会设置新值。 打一个比方,如果有一家蛋糕店,为了挽留客户,绝对为贵宾卡里余额小于20元的客户一次性赠送20元,刺激消费者充值和消费。但条件是,每一位客户只能被赠送一次。此时,如果很不幸的,用户正好正在进行消费,就在赠予金额到账的同时,他进行了一次消费,使得总金额又小于20元,并且正好累计消费了20元。使得消费、赠予后的金额等于消费前、赠予前的金额。这时,后台的赠予进程就会误以为这个账户还没有赠予,所以,存在被多次赠予的可能,但使用 AtomicStampedReference 就可以很好的解决这个问题。2.无限循环问题(自旋):看源码可知,Atomic类设置值的时候会进入一个无限循环,只要不成功,就会不停的循环再次尝试。在高并发时,如果大量线程频繁修改同一个值,可能会导致大量线程执行compareAndSet()方法时需要循环N次才能设置成功,即大量线程执行一个重复的空循环(自旋),造成大量开销。
解决无线循环问题可以使用java8中的LongAdder, 有点像1.8的ConcurrentHashMap。高并发情况,new 一个 2的幂次方的数组,最大为cpu的核数。采用对数组分段CAS的方式,进行修改每个数组下标值。获取总数的时候采用原值 + 数组每个下标值的累加。3.多变量原子问题:只能保证一个共享变量的原子操作。一般的Atomic类,只能保证一个变量的原子性,但如果是多个变量呢?
可以用AtomicReference,这个是封装自定义对象的,多个变量可以放一个自定义对象里,然后他会检查这个对象的引用是不是同一个。如果多个线程同时对一个对象变量的引用进行赋值,用AtomicReference的CAS操作可以解决并发冲突问题。 但是如果遇到ABA问题,AtomicReference就无能为力了,需要使用AtomicStampedReference来解决。interrupt()方法 中断几种 区别
- 同步实现机制不同
- interrupt() 线程标记为中断,抛异常.
- Interrupted() 判断线程是否中断,并且重置为false.
-
Runnale 和 Callable 区别
callable 执行的 call,runnable 执行的是 run
- callable 可以获取future 对象,可以获取返回值。run 方法不行。
线程的几种状态?
- 新建(new)新建一个线程对象
- 可运行(runnable)调用 start 的方法,但是没有获取 cpu 使用权。
- 运行(running)调用run方法,获得cpu使用权
- 阻塞(blocked)调用了sleep(),wait()或者运行时 等待获取锁。
死亡(dead)线程执行完了,或者异常退出了 run()方法。
线程池几种状态?
running 新建线程池
- shutdown 调用 shutdown()不在接受新任务,但是会继续执行已经添加的任务。
- stop 调用 shutdownNow()不在接受新任务,同时不会执行已添加任务,并且终止正在执行的线程。
- tidying 任务线程停止 和 队列为空的状态。
- terminated 在 tidying 状态调用 terminated()方法,线程池销毁。
线程池参数介绍?
核心线程数
最大线程数
线程空闲时间
阻塞队列
饱和策略
线程工厂线程池的分发
- 新任务,先判断核心线程数是否全部再执行,没有就新建一个执行。
- 核心线程数全部在执行,那么就去判断队列中是否已满,未满添加到队列中
- 已满,就判断是否达到了最大线程数,没有达到就新建线程去执行当前线程。
- 已经达到了,就调用线程池的饱和策略
几种线程池
一般是使用 ThreadPoolExecutor 自己根据业务,CPU核数设置。
CPU 密集型,一般是 核心线程数和CPU核数+1,因为 CPU一直在运行,CPU 利用率高。
IO 密集型,一般是 2倍核数+1,CPU 利用低,其他线程可以继续使用CPU,提高CPU利用率。
- 固定核心线程数,无线队列,没有空闲时间的。适合压力较大的服务器,可以控制线程数,合理利用资源。
- 单一线程,无线队列,没有空闲时间。适合串型任务,按顺序执行的任务。
- 没有核心线程数,只有 maxInteger 大的 最大核心线程数,无线队列,有较短的空闲时间。适合并发高,周期短的任务。
- 定时线程,固定线程数,采用延迟或定时的方式来执行任务。
线程池的饱和策略
- 不处理,抛异常
- 不处理,不抛异常
- 让调用者的线程处理任务
- 丢弃队列头消息,接下来直接执行当前任务
自己实现 rejectExcutionHandler 接口,自定义策略。
submit() 和 execut()区别?
接受参数不同,execut 参数为 runnable,submit 可用时 runnable,callable
- submit 可以通过 futureTask 获取返回值,execut 是没有返回值的
-
线程池是如何做到线程复用的?
通过 Work 的 runWork 方法。
- 该方法 第一次 通过 Work 的 firstTask 获取任务,
- 之后会 循环通过 getTask 从 workQueue 中不停地获取任务
- 并直接调用task的( task 是实现了runnable ) run 方法来执行任务,这样就保证了每个线程都始终在一个循环中,反复获取任务,然后执行任务,从而实现了线程的复用。
- 当 getTask 返回 null,就会销毁线程。
空闲线程超时销毁如何实现的?
- 首先线程池会将 新建的 work 放进 一个 set集合里,works。
- getTask时候,先判读 works大小 是否超过核心线程数
- 超过核心线程数,使用 poll() + 空闲时间,去获取 task,poll()他是非阻塞的。
- 没用超过核心线程数,使用的是 take() take 是阻塞的,一直等待回去线程。
- 当 poll 空闲时间到了也没有获取到任务,返回null。
runWork 循环条件不成立,跳出循环,最终会调用 销毁 work 逻辑。
FutureTask
FutureTask是Future接口的一个唯一实现类。
FutureTask实现了Runnable,因此它既可以通过Thread包装来直接执行,也可以提交给ExecuteService来执行。
FutureTask实现了Futrue可以直接通过get()函数获取执行结果,该函数会阻塞,直到结果返回。Threadlocal起什么作用?
Threadlocal内部实现原理
每个 Thread 都有 ThreadLocalMap。
- ThreadLocalMap 内部为 entry数组,entry 对象 key 为ThreadLocal 变量,value 是存的变量的值。
- entry 的 key 也就是 ThreadLocal 为 弱引用。
- 那么也就是说 ThreadLocal,容易被GC 回收掉。
- set 会判断是否初始化了 map,没有就初始化,同时将当前 threadLocal 作为 key, 变量值作为 value 存入。同时可能会触发回收 失效的值。
- 如果 set 的时候 tab[i] 有冲突,那么通过线性探测法(netIndex)去依次找到空闲的 位置,插入key,value。
- get key,tab[i]与key相同返回value。 tab[i] 有冲突,通过线性探测法(netIndex)去依次找到等于key的tab[i]。
初始化 默认 entry 长度为 16。阈值为 2/3 长度。
ThreadLocal 引发的内存泄漏问题?
Entry 的 key 是弱引用,那么就是说 ThreadLocal 容易被 GC 回收掉。
当 key 被 GC 为 null,但是 Entry 本身被 Map 引用着,而 Entry 又 引用着 不为null 的 Value。
我们线程一直存活,且一直不调用 get,set, remove 方法,那么这条链一直存在,不会被 GC 回收,导致内存泄漏。
所以最好一旦数据不使用,最好直接 remove 掉。
其实,ThreadLocalMap的设计中已经考虑到这种情况,也加上了一些防护措施:在ThreadLocal的get(),set(),remove()的时候都会清除线程ThreadLocalMap里所有 key为null的value。ThreadLocal 什么时候可能会出现线程不安全问题。
当 Entry 的 value ,为共享变量的时候,比如加了 static 。那么就会出现不安全问题。
JMM
Java的内存模型是分为主内存和线程的工作内存两部分进行工作的,
工作内存从主内存read数据,
load到工作内存中,
线程对数据进行use,
然后将数据assign到工作内存,
从工作内存store处理过的数据,
最后将新数据write进主内存。硬件层面原理
主内存
CPU寄存器:
CPU写缓冲器:暂存修改的变量,发送消息给总线通知就完事。等到总线通知其他处理器全部返回了收到ack,它会修改高速缓存。优化了CPU不需要串行等待其他CPU返回 ack,再写入高速缓存。
CPU无效队列:缓存失效变量,立刻返回ack给总线收到消息。优化了CPU不需要串行等待变更高速缓存,再发送ack通知到总线。
CPU高速缓存:缓存着主内存的数据
总线:接受发送通知每个处理器
工作流程某个CPU 对本地内存数据需要修改,先在写缓存器修改,然后发送 invalidate 消息到总线。其他CPU处理器会不停的嗅探总线,当嗅探到变量需要变更,会将变量放到无效队列里,返回 invalidate ack 消息给总线。之后会根据无效队列,将对应高速缓存变量标记为失效标记 I。
- 当 CPU 收到所有其他的CPU发来的 invalidate ack 消息,就会从 写缓冲器 取出数据,锁定高速缓存中的条目 标记 E 独占锁,然后将写缓存器的数据写到 高速缓存(主内存),标记为 M。
解决可见性:
Load屏障(refresh操作):从高速缓存中读取数据的时候,如果发现无效队列里面有一个 invalidate 消息,此时会立马强制根据那个 invalidate 消息把自己本地高速缓存的数据,设置为 I(过期),然后就可以强制从其他处理器的高速缓存中加载最新的值。
Store屏障(flush操作):强制要求写操作必须阻塞等待到其他的处理器返回 invalidate ack 之后,加锁,然后修改数据到 高速缓存。效果就是,要求flush操作必须刷到高速缓存(或者主内存),不能停留在写缓存中。
解决有序性:
Acquire屏障(StoreStore屏障):会强制让写数据的操作全部按照顺序写入写缓冲器里,他不会让你第一个写到写缓冲器去,第二个写直接修改高速缓存。
Resource屏障(StoreLoad屏障):他会强制先将写缓冲器里的数据写入高速缓存中,接着读数据的时候强制清空无效队列,对里面的 validate 消息全部过期掉高速缓存中的条目,然后强制从主内存里重新加载数据。
你知道Java内存模型中的原子性、有序性、可见性是什么吗?
可见性:是指线程之间的可见性,一个线程修改的状态对另一个线程是可见的,也就是一个线程修改的结果,另一个线程马上就能看到。(加 Load屏障执行 refresh指令,加Store屏障执行 flush操作。)
原子性:线程必须是独立执行的,没有人影响我的,一定是我自己执行成功之后,别人才可以执行。(ObjectMonitor对象 加锁)
有序性:
java ->javac(静态编译)->class -> jit(动态编译)-> 机器码指令 -> 处理器。 (为了加速程序的执行速度,在一定规则的情况下发生指令重排序。 javac, jit ,处理器 三个层次都会发生指令重排。)
代码必须是按顺序执行的,不能重排序。(在进入代码加Acquire屏障和之后加Release屏障,保证代码块的不和屏障之外的代码发送指令重排)
synchronized关键字,同时可以保证原子性、可见性以及有序性的
原子性:加锁和释放锁的机制,ObjectMonitor,保证只有一个线程能进入同步块。(加锁和释放锁)
可见性,在monitorenter 之后 Load 屏障, monitorexit 之后加 Store 屏障,他在同步代码块对变量做的写操作,都会在释放锁的时候,全部强制执行flush操作,在进入同步代码块的时候,对变量的读操作,全部会强制执行refresh的操作。(内存屏障+MESI协议。)
有序性,同步开始加 Acquire 屏障 ,同步之后加 Release 屏障,通过内存屏障来保证同步代码内部的指令可以重排,但是同步代码块内部的指令和外面的指令是不能重排的。(内存屏障)
volatile关键字有什么作用?
先说jmm抽象原理 -> 硬件原理 -> MESI协议 -> 内存屏障保证了可见性(load屏障 refresh操作,store屏障 flush操作),有序性(acquire,release屏障 保证指令之间不能重排)-> 原子性(ObjectMonitor 结构,加锁原理。)
讲清楚volatile关键字,直接问你volatile关键字的理解,对前面的一些问题,这个时候你就应该自己去主动从内存模型开始讲起,原子性、可见性、有序性的理解,volatile关键字的原理
volatile关键字是用来解决可见性和有序性,大量用在开源项目。主要用在有读有写的多线程场景。可见性:volatile 读之前加 Load 屏障, 写 之后加 Store 屏障,保证读之前 MESI缓存一致性协议执行 refresh操作,写之后执行 flush 操作。
有序性:volatile修饰的变量读写前面加 Acquire 屏障和之后加 Release 屏障,保证代码块的不和屏障之外的代码发送指令重排,避免前后的读写操作发生指令重排。
double check单例实践
线程1: MyObject myObj = new MyObject(); => 这个是我们自己写的一行代码
步骤1:以MyObject类作为原型,给他的对象实例分配一块内存空间,objRef就是指向了分配好的内存空间的地址的引用,指针
objRef = allocate(MyObject.class);
步骤2:就是针对分配好内存空间的一个对象实例,执行他的构造函数,对这个对象实例进行初始化的操作,执行我们自己写的构造函数里的一些代码,对各个实例变量赋值,初始化的逻辑
invokeConstructor(objRef);
步骤3:上两个步骤搞定之后,一个对象实例就搞定了,此时就是把objRef指针指向的内存地址,赋值给我们自己的引用类型的变量,myObj就可以作为一个类似指针的概念指向了MyObject对象实例的内存地址
myObj = objRef;
有可能JIT动态编译为了加速程序的执行速度,因为步骤2是在初始化一个对象实例,这个步骤是有可能很耗时的,比如说你可能会在里面执行一些网络的通信,磁盘文件的读写,都有可能JIT动态编译,指令重排,为了加速程序的执行性能和效率,可能会重排为,步骤1 -> 步骤3 -> 步骤2
线程1,刚刚执行完了步骤1和步骤3,步骤2还没执行,此时myObj已经不是null了,但是MyObject对象实例内部的resource是null
线程2,直接调用myObj.execute()方法, 此时内部会调用resource.execute()方法,但是此时resource是null,直接导致空指针
如果加了 Volatile 关键字,步骤1,2,3是需要一起完成。其他线程才可使用。
防止指令重排序有什么好处?如何实现防止指令重排序的?
防止指令重排序好处:保证代码的有序性。规则制定了在一些特殊情况下,不允许编译器、指令器对你写的代码进行指令重排,必须保证你的代码的有序性。(这句话要说,然后找个几条happen-before 原则说说就可以了。)
happen-before 原则
- 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作
- 锁定规则:一个unLock操作先行发生于后面对同一个锁的lock操作,比如说在代码里有先对一个lock.lock(),lock.unlock(),lock.lock()
- volatile变量规则:对一个volatile变量的写操作先行发生于后面对这个volatile变量的读操作,volatile变量写,再是读,必须保证是先写,再读
- 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C
- 线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作,thread.start(),thread.interrupt()
- 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生
- 线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行
- 对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始

若有收获,就点个赞吧
0 人点赞
