https://www.bilibili.com/video/BV1UJ411A7Fs?p=3&spm_id_from=pageDriver
#day1#03 Pandas数据结构#Series:一维数据#Dataframe: 多维数据import pandas as pdlj='C:/Users/Administrator/Documents/py/py_day3.xlsx'bk=pd.read_excel(lj)#修改列:把文本型改为数值型bk.loc[:,'Name']=bk['Name'].str.replace('student_','').astype('int32')#增加列 方式一#bk.loc[:,'neW']=bk['ID']-bk['Name']#df.apply axis=1/0 方式二#bk['Name'].value_counts() #查看类型的计数#df.assign 方式三 不会修改原数据#按条件选择分组分别赋值 方式四#print(bk)#04#unique()
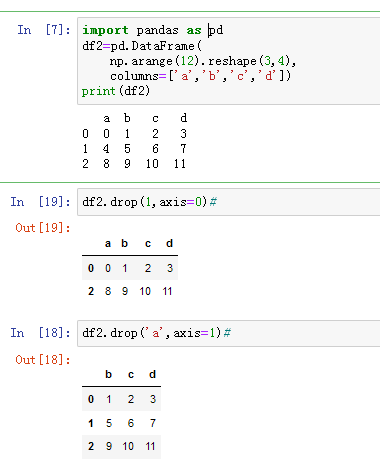
#day2import pandas as pddf2=pd.DataFrame(np.arange(12).reshape(3,4),columns=['a','b','c','d'])print(df2)

#class 14 数据额合并concat#合并方式,轴向,列表pandas.concat(objs,axis=0,join='outer',ignore_index=false)#objs 列表或者dataframe,join合并对齐方式,ignore_index忽略原索引#join='inner'#axis=1 添加列#append#低性能for i in range(5):df=df.appnd({A:1},ignore_index=True)#性能好 输入列表,避免多次输入pd.concat([pd.Dataframe([i],columns=['A']),for i in range(5)],ignore_index=True))

若有收获,就点个赞吧
0 人点赞
