一、数据结构
1、String(字符串)
(1)、概述
1、value一定是字符串吗?
- 不一定,可以是字符串也可以是数值,小于一个长度是数值,超过一个长度是字符串
(2)、应用场景
- 放字符串或者对象,过期,分布式锁
- 要注意序列化反序列化问题
2、List(列表)
(1)、概述
- 一个双向链表或者队列,支持反向查找和遍历
(2)、应用场景
- 做缓冲队列
3、Hash(哈希表)
(1)、概述
- 当只有一个kv的时候,为了节省内存,会采用一维数组来紧凑存储,就是我们平时存的对象
- 当kv多的时候,会用HashMap
(2)、应用场景
- 存对象
4、Set(集合)
(1)、概述
- 不重复的列表,针对集合求交集、并集、差集
- 内部实现和java中的set一样,是一个value是null的HashMap
(2)、应用场景
- 相互关注啥的,共同好友啥的
5、Sorted Set(有序集合)
(1)、概述
- 在Set集合基础上,每个成员带有分数,可以用于排序
(2)、应用场景
- IP地址段,1.1.1.1是1分,1.1.1.254是2分,当进来的一个分数在1~2之间,说明是一个段的。
- 用户列表,优先级排序
- 用户A-1;用户B-2;用户C-3;离线-100;在线-200
(3)、补充
1、ZSet有序列表是怎么实现的?
1>.HashMap+跳跃表(SkipList),保证数据的存储与有序
- HashMap里存成员到score的映射,跳跃表存的是所有成员,可以保证很高的查询效率。
2、跳表实现原理
思想:多层链表。上层链表的节点个数是下层节点个数的一半。
第一层查询复杂度O(n),由于第二层的节点个数是第一层的一半,查找过程类似于二分查找,时间复杂度降低到O(log n)



2>.跳表是怎么插入和删除节点的?
- 为了避免或者缓解跳表插入删除改动过大问题,在插入和删除的时候,不要求上下层节点有严格的对应关系,插入和删除时每个节点层数是随机出来的。
- 因此插入删除只需要修改节点前后的指针即可。
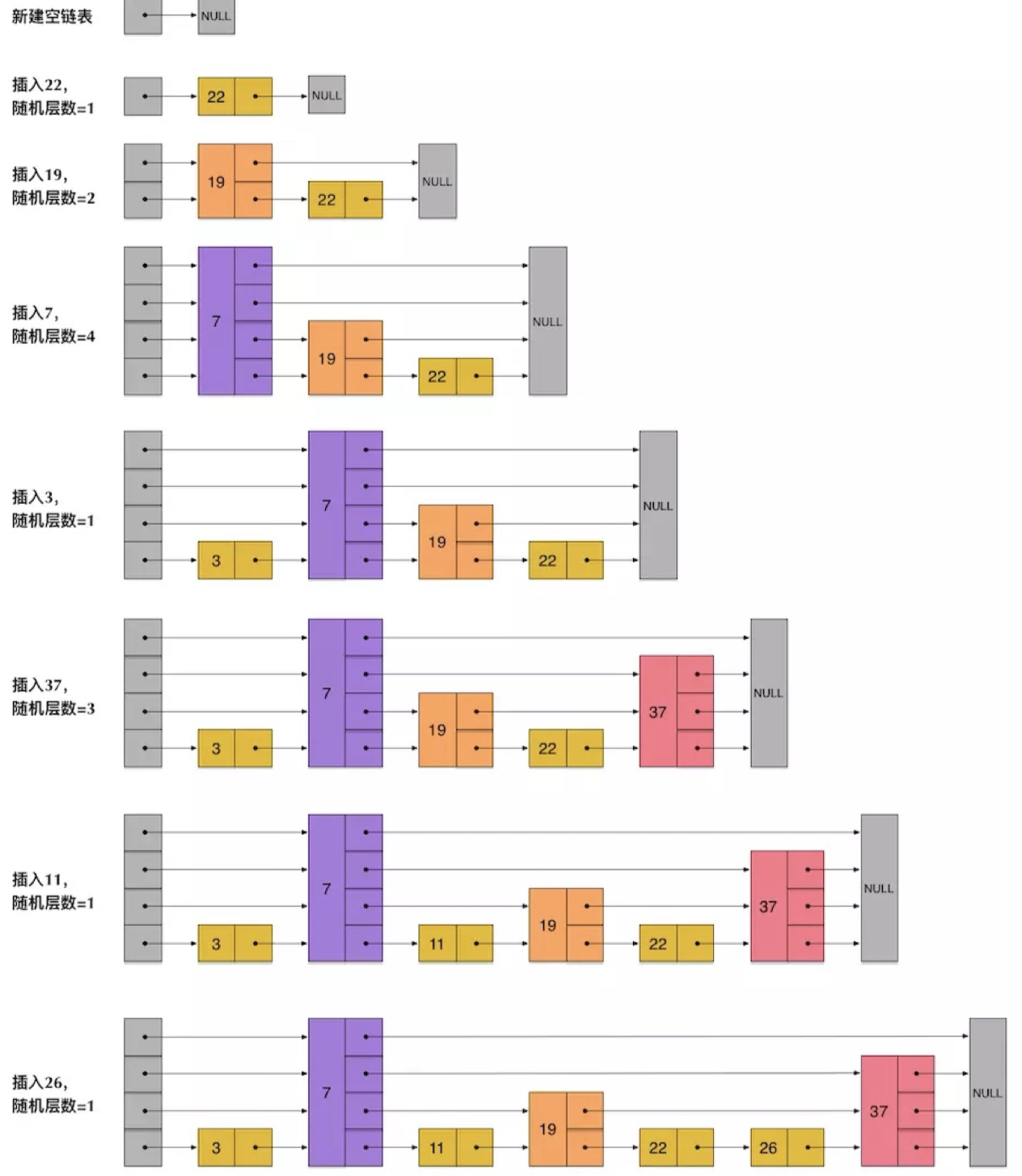
3>.跳表的优点?为什么用跳表?跳表与红黑树(平衡树)比较?
- 调试实现起来比较简单,查找新增效率都不错
- 插入删除的性能比跳表要好。在并发情况下,跳表有优势。
- 跳表:对插入和删除操作对整个多层链表结构改动较少,只改了节点的前后指针,锁定的节点少。
- 红黑树:插入和删除操作需要自动平衡,对整个数据结构的改动较大,锁定的节点多。但是红黑树的查找效率最坏时间复杂度为O(2log n),更加稳定可控。
二、持久化
1、RDB
- 描述:快照,把所有的数据,压缩成二进制文件
- 触发快照时机:save(同步)、bgsave(异步)
- 后台定时bgsave,主从复制,主库执行bgsave
- save 900 1 # 900秒(15分钟)内有1个写入
- save 300 10 # 300秒(5分钟)内有10个写入
- save 60 10000 # 60秒(1分钟)内有10000个写入
- fulushall清空服务器数据、shutdown关闭redis时,执行save
- 后台定时bgsave,主从复制,主库执行bgsave
2、AOF
- 描述:把写的操作追加到日志文件中。会降低redis性能。
- 同步策略:将aof_buf缓冲区内存写入AOF文件(磁盘)
appendfsync always:每个写命令执行写入磁盘。appendfsync everysec:启一个线程,每秒执行写入磁盘。appendfsync no:什么时候写入,由操作系统决定。
-
(1)、为什么需要rewrite?
- 存的是命令,通常会有一些冗余命令,rewrite就是对冗余的命令进行压缩精简,也减少了文件的体积
触发
rewrite期间,写时复制,服务器fork一个子进程创建一个新的临时aof文件,文件里保存了最新的aof文件内容重写期间,服务器进程继续处理命令请求,把命令先放到aof缓冲区,再等待触发刷新到aof文件中,这期间,如果有写入命令,把命令写到aof缓冲区和aof_rewrite缓冲区
- 子进程完成重写压缩整理之后,给父进程一个信号,父进程把aof_rewrite缓冲区内容写进新的临时文件中,再度新的AOF文件改名完成替换,即可保证新的AOF文件数据与当前数据库数据的一致性。
3、对比
- RDB:快照,存的是数据
- 优点:
- 压缩过的比较紧凑的文件,恢复大数据集会更快,保存着某个时间点的数据,适合做数据备份恢复。RDB比AOF要慢。
- 可以fork一个子进程异步备份,父进程不需要的等待
- 缺点:
- RDB全量复制数据,AOF是追加的方式。安全性不如AOF,可能会丢失数据
- 数据量较大时,fork子进程完成快照比较耗时、耗CPU
- 优点:
- AOF:存的是操作命令(rewrite对命令压缩精简),恢复的时候需要重放
- 优点:
- 安全性更高,妙极丢失数据
- 追加文件的方式,是以redis协议的格式保存的,内容是可读可修改的,适合误删除紧急恢复
- 缺点:
- 对于相同的数据集,文件可能会比RDB大,数据恢复较慢
- 优点:
4、数据恢复
- Redis4.0开始支持RDB和AOF混合持久化。
- 如果redis进程挂掉,重启进程即可,然后基于AOF文件恢复数据。
- 如果redis进程所在服务器挂掉,重启后,尝试基于AOF文件恢复数据,如果AOF文件损坏,那么用redis-check-aof fix命令恢复。
- 如果没有AOF文件则去加载RDB文件,恢复数据。
- 如果AOF文件和RDB文件都损坏了,可以基于历史的RDB文件快照进行数据恢复。
三、分布式锁
1、单redis分布式锁
(1)、需要考虑哪些问题哪些bug?怎么解决?
1.A获取到锁,B等待,A进程挂了,B永远获取不到锁。
- 设置过期时间。
2.过期时间30s,A业务执行了50s,第30sA获取的锁释放了,B获取到锁,之后A业务完成,将B获取的锁释放了(误解锁)
- v,标志当前线程的值,具有唯一性,释放锁的时候,根据k获取v,与获取锁生成的v相比较,相同则删除
3.>在删除的时候,A锁释放了线程结束,第二个任务拿到刚结束的A线程执行获取到锁,此时代码下一步会将刚执行A的线程获取到的锁释放。(误解锁)
- lua脚本,保证原子性执行
4.>如何保证过期时间大于业务的执行时间?
- 开启刷新过期时间线程
- 获取到锁的时候,开启刷新过期时间线程,直到释放锁,刷新关闭
(2)、怎么使用好分布式锁?
- 防止死锁,对锁设置过期时间
- 防止误解锁,获取锁生成的v(具有唯一性)和释放锁时通过k获取的v相比较,且要保证这个操作的原子性
- 保证在业务没执行完,锁不过期,定时刷新过期时间
2、集群redis分布式锁(redisson-redLock)
(1)、主从切换的时候锁丢失情况
1.过程:
- redis的master节点拿到了锁
- 这个加锁的key还没来得及同步到slave节点
- master故障,发生故障转移,slave节点升级为master节点
- 导致锁丢失
2.原理:
- 有5个master节点,各个节点完全独立,不存在主从复制,获取锁的时候,需要分别像这5个节点获取锁,当获取到(n/2+ 1)个锁的时候,且每个节点的获取锁时间的总和小于锁过期的时间,视为获取锁成功。
- 向每个节点获取锁的时候,会设置一个获取锁超时时间,该超时时间远小于锁失效的时间
- 通过key获取到的锁,真正的有效时间是 失效时间-获取锁所使用的时间
- 客户端会在各个节点上释放锁
四、常见问题
1、缓存更新
(1)、先更新数据库,再更新缓存
- 存在脏数据的情况
- 这个策略就有问题:
- 读操作只读缓存,玩意redis挂了,读操作永远读不到数据,会有问题
- 读操作一定是这样的逻辑,先读缓存,读不到缓存再读数据库,再把数据写入缓存,这种情况的话,更新完数据库之后就没必要更新缓存了,直接删就好了
- 如果先更新数据库,再更新缓存,会使得更新操作响应变慢,缓存是要读的关注命中率,可能更新了缓存,但是用户不访问不读,从这个角度来看,会造成资源的浪费,从而影响系统整体性能。
(2)、先删除缓存,再更新数据库
- 存在脏数据的情况
- A写操作,先删缓存
- B查缓存为空,B去数据库查旧数据,然后把这个旧的数据写入到缓存中
- A写操作,更新数据库
- 解决方案
- 更新完数据库再删除一次缓存,还不如直接用第三种方案。
- 如果更新完数据库立马删除缓存,如果是读写分离架构,又会出现读脏数据的情况
- 问题演示:写主库,读从库,读的时候,由于缓存数据再更新的时候删除了,这里读不到缓存,会读从库,主从复制存在延迟,可能依然是旧的数据。
- 问题解决:(异步双删策略),先立马删除缓存,写库完成以后,等个几秒钟再删除缓存。
(3)、先更新数据库,再删除缓存(最推荐)
- 存在脏数据的情况
- 缓存刚好失效
- A查库,得到一个旧值
- B将新值写入库并删缓存
- A将旧值写入缓存
(4)、缓存删除失败怎么办?
- 重试机制
- 将需要删除的key放到队列里,然后消费队列删除缓存,失败就重试,但是对业务代码造成大量侵入。
- 监听binlog日志,提取需要删除的key,再放到队列中。
2、缓存击穿、穿透、雪崩、热点key
(1)、缓存穿透
- 问题描述:每次请求绕过了redis直接打到数据库上
- 产生原因:查询库中不存再的数据,由于数据不存在,缓存为null,每次查询都走一遍数据库
- 解决方法
- 缓存空值:
- 每个key从库中查不到数据,再缓存中设置一个null值,并加上过期时间。
- 存储层更新数据了,该key可以命中了,需要每次更新完,删除缓存。
- 布隆过滤器(类似于位图bitmap):
- 将数据库所有的查询条件,id和key,放到布隆过滤器中,当一个请求来的时候,先经过布隆过滤器检查,如果存在则执行,不存在则直接返回。
- 缓存空值:
(2)、缓存击穿(缓存雪崩)
- 问题描述:缓存集中一段时间内失效,发生大量的缓存穿透,所有请求都打在数据库上,并且查询出来结果去构建缓存。
- 解决方法:
- 缓存失效后,加锁或者队列来控制访问数据库和写缓存的线程数量。比如对于某个key只允许一个线程查询和写缓存。
- 在即将发生大并发访问前,主动更新所有的缓存
- 不同的key设置不同的过期时间
(3)、热点key
- 问题描述:某个key访问量特别大,当缓存失效时,有大量的线程构建缓存,造成后端负载过大,系统崩溃。
- 解决方法:
- 互斥锁(不太好):只让一个线程去构建缓存,其他线程等待,然后直接从缓存获取就好了。
- 永不过期(不实用),因为热点key是没发预判的。
- 将热点key分散多个子key,打到集群不同的机子上去,做负载,但还是有局限性。
- 预测热点key,怎么预测?不好搞。
3、一致性哈希算法
假设有1000w条记录,100个存储节点。
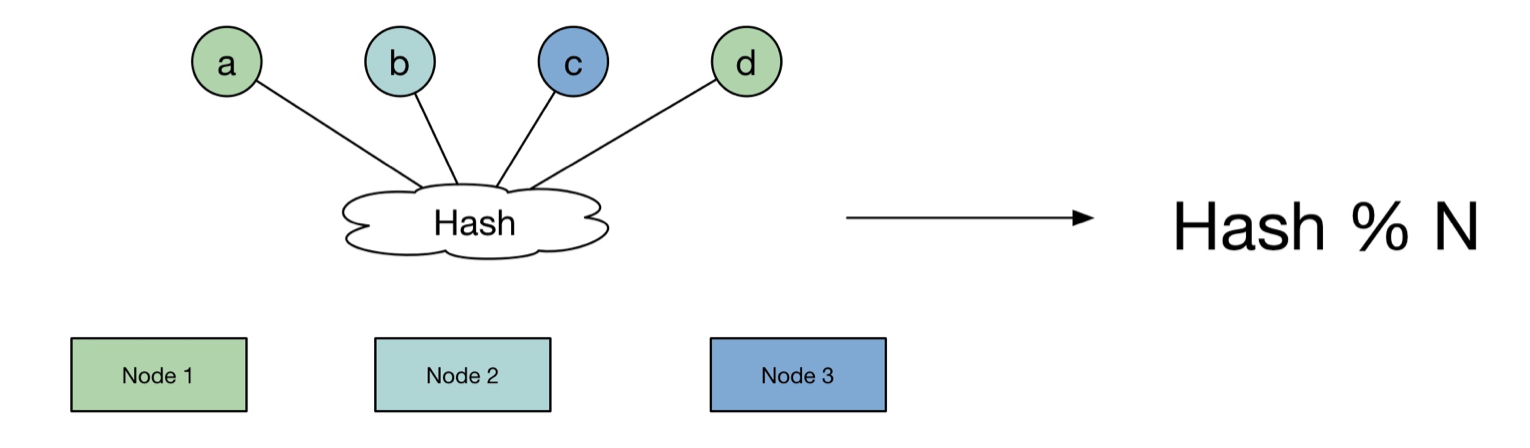
(1)、普通的Hash算法原理
- 算法实现:哈希取余,hash%n
- 产生问题:当node数量变化,需要考虑很多节点的数据迁移。
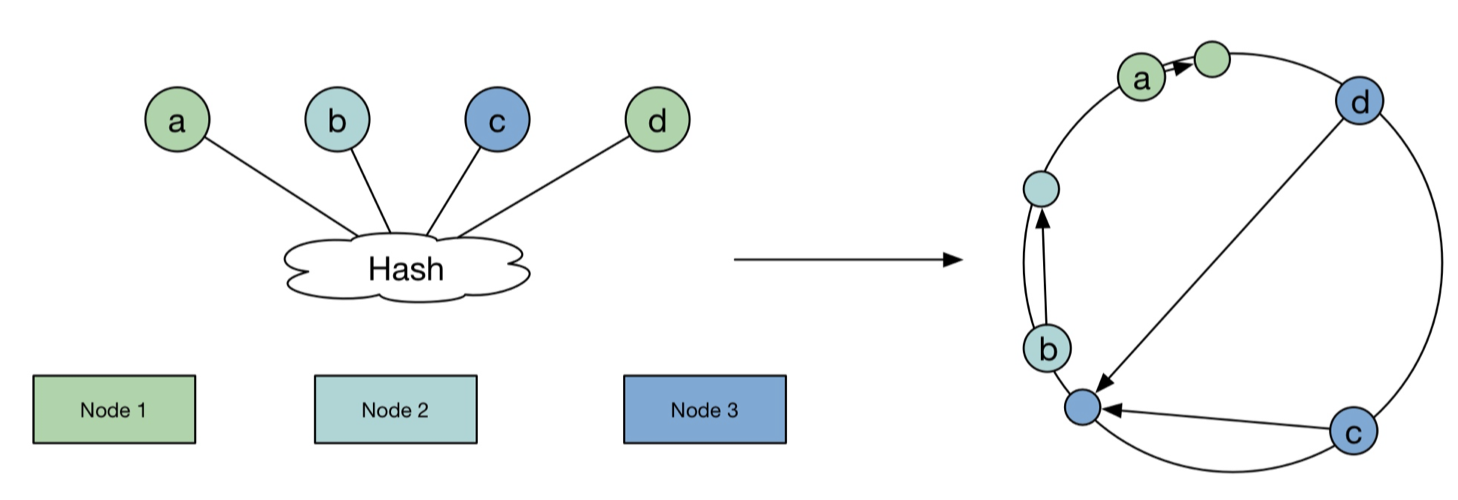
(2)、一致性Hash算法好处&原理
- 解决了什么问题?当node数量变化,对于大多数的数据,保证还是分配到原来的node上,将数据迁移量降到最低。
- 原理:
- 想象一个环,节点在环上,对于数据哈希打在边上,边上的节点顺时针存储在下一个节点上,或者找距离最近的节点上。这样如果新增或减少节点,只要迁移一个边的节点就好了,不用迁移很多。
- 虚拟节点,也可以减少数据迁移的工作。

4、redis为什么快?
- 完全基于内存,数据类似于hashMap,查找时间复杂度O(1)
- 数据结构简单,对数据的操作简单。
- 采用单线程,不用考虑线程上下文切换和竞争条件,不用考虑锁的问题,也没有死锁问题
- I/O多路复用模型(多个连接一个线程操作)
- redis自己构建了VM机制。

若有收获,就点个赞吧
0 人点赞
