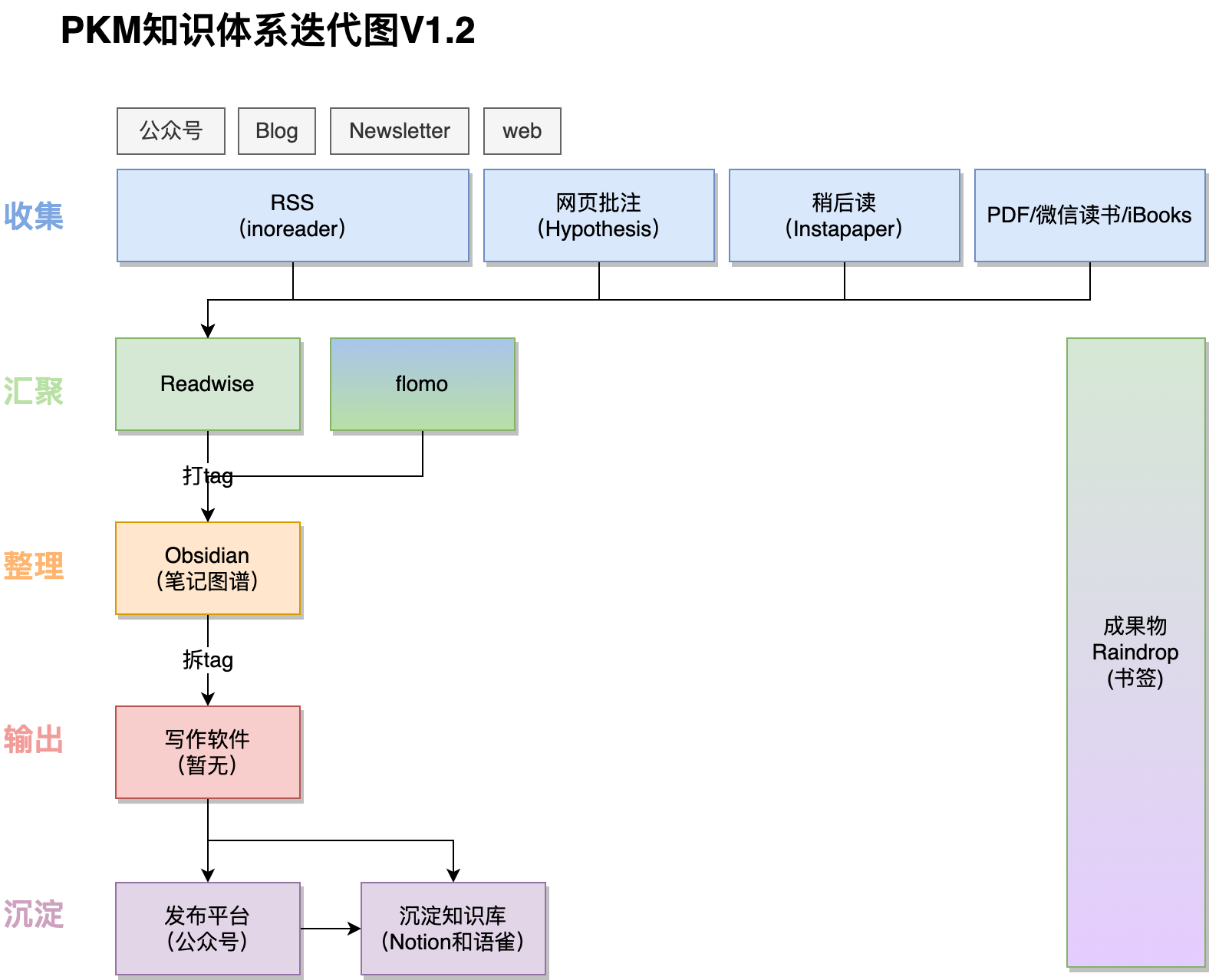
V1.2版本最大的变化是增加了整理(打tag和拆tag)的过程
( V1.0及0.X是我的脑袋中和草图中完成,此处省略
有必要花时间来打造和磨合一套PKM知识流体系吗
我认为有必要,知识对于任何时间的我们都非常重要,而搭建并磨合一套适合自己的体系
- 相当于构建了一个适合自己的机器学习模型,这个模型最终会形成一种“自洽”的状态,只要我们不断的给模型(体系)喂数据,它就会源源不断产出,将极大满足我们的爽感;
相当于构建了知识体系的SOP(标准化操作流程),这个流程将会使我们更加专注于提高信息源的质量和产出的转化,极大提升我们的效率。
当前的这个体系有什么不足,下一步方向是什么
其实下一步方向,也是这次V1.2改版的初因,缺乏「全局标签管理」。
标签的应用分别散落在收集和flomo临时笔记阶段,缺少「全局标签管理」,不利于知识的最终沉淀;
- V1.2版本相当于加了一层“中台”,把readwise变成数据采集和数据处理平台,完成打tag和拆tag动作,但是不足在于还没有把readwise和flomo及文件系统等标签对应起来。(等完全对应起来就可称之为「全局标签管理」
V1.2没有直接做起来的原因是我认为现在的内容和标签系统不够成熟,下一步
- 首先需要“起量”,催化加速发生;
- 然后适当参考“P.A.R.A”和“GTD”等理论,需要形成适合我的标签系统;
- 最后应用总结,让这一切发生
个人PKM知识流体系的搭建过程也让我明白了,很多问题没有合适的解决,可能很大的原因就是“量不够大”,在任何方面,量大了,都明白了。

若有收获,就点个赞吧
0 人点赞
