多年来,研究人员花费了大量时间和精力来研究并发错误。早期的大部分工作都集中在死锁上,我们在过去的章节中已经讨论过这个主题,但现在将深入研究 [C+71]。最近的工作侧重于研究其他类型的常见并发错误(即非死锁错误)。在本章中,我们将简要介绍在实际代码库中发现的一些并发问题示例,以更好地了解需要注意哪些问题。因此,我们本章的核心问题是:
关键的问题:如何处理常见并发Bugs 并发性错误往往出现在各种常见模式中。要编写更健壮、正确的并发代码,第一步是知道要注意哪些代码。
32.1 存在哪些类型的Bugs What Types Of Bugs Exist?
第一个也是最明显的问题是:在复杂的并发程序中会出现哪些类型的并发错误?一般来说,这个问题很难回答,但幸运的是,有些人已经帮我们解决了这个问题。具体来说,我们依赖Lu等人[L+08]的一项研究,该研究详细分析了许多流行的并发应用程序,以了解在实践中会出现哪些类型的bug。
这项研究集中在四个主要且重要的开源应用上:MySQL(一个流行的数据库管理系统),Apache(一个著名的网络服务器),Mozilla(著名的网络浏览器)和OpenOffice(微软Office套件的免费版本,一些人正在使用)。在研究中,作者检查了在每个代码库中已经发现并修复的并发bug,将开发人员的工作变成了定量的bug分析;理解这些结果可以帮助您理解在成熟的代码库中实际发生的问题类型。
图32.1显示了Lu和同事研究的bug的总结。从图中可以看出,总共有105个错误,其中大部分不是死锁(74个);剩下的31个是死锁错误。此外,您可以看到每个应用程序研究的bug数量;而OpenOffice总共只有8个并发错误,而Mozilla有近60个。
现在我们更深入地研究这些不同类型的bug(非死锁、死锁)。对于第一类非死锁错误,我们使用研究中的示例来推动讨论。对于第二类死锁错误,我们将讨论在防止、避免或处理死锁方面所做的大量工作。
32.2 非死锁Bugs Non-Deadlock Bugs
根据Lu的研究,非死锁bugs占并发bugs的大部分。但是这些是什么类型的bug呢?它们是如何产生的?我们如何解决这些问题?我们现在讨论Lu等人发现的两种主要的非死锁错误:原子性冲突错误(atomicity violation bugs)和顺序冲突错误(order violation bugs)。
原子性违背错误 Atomicity-Violation Bugs
遇到的第一类问题称为原子性冲突。下面是一个简单的例子,可以在MySQL中找到。在阅读解释之前,试着找出问题所在。开始!
Thread 1::if (thd->proc_info) {fputs(thd->proc_info, ...);}Thread 2::thd->proc_info = NULL;
Figure 32.2: Atomicity Violation (atomicity.c)
在这个示例中,两个不同的线程访问结构thd中的字段proc_info。第一个线程检查值是否为非null,然后打印它的值;第二个线程将它设置为NULL。显然,如果第一个线程执行了检查,但在调用fputs之前被中断,则第二个线程可以在中间运行,从而将指针设置为NULL;当第一个线程恢复时,它将崩溃,因为一个NULL指针将被fputs解引用。
根据Lu等人的说法,原子性冲突的更正式定义是:“违背了多个内存访问之间所需的序列化性(例如,代码区域是原子性的,但在执行期间没有强制执行原子性)。”在上面的例子中,代码有一个原子性假设(atomicity assumption)(用Lu的话来说),关于检查proc_info的非null值和在fputs()调用中使用proc_info;当假设不正确时,代码将不能按预期工作。
找到这类问题的解决方案通常(但不总是)很简单。你能想到如何修复上面的代码吗?
在这个解决方案中(图32.3),我们只是在共享变量引用周围添加锁,确保当任何一个线程访问proc_info字段时,它都持有一个锁(proc_info_lock)。当然,任何其他访问该结构的代码在这样做之前也应该获得这个锁。
pthread_mutex_t proc_info_lock = PTHREAD_MUTEX_INITIALIZER;Thread 1::pthread_mutex_lock(&proc_info_lock);if (thd->proc_info) {fputs(thd->proc_info, ...);}pthread_mutex_unlock(&proc_info_lock);Thread 2::pthread_mutex_lock(&proc_info_lock);thd->proc_info = NULL;pthread_mutex_unlock(&proc_info_lock);
Figure 32.3: Atomicity Violation Fixed (atomicity fixed.c)
顺序冲突错误 Order-Violation Bugs
Lu等人发现的另一种常见的非死锁错误称为顺序冲突(order violation)。这是另一个简单的例子;再一次,看看您能否找出为什么下面的代码会有错误。
Thread 1::void init() {mThread = PR_CreateThread(mMain, ...);}Thread 2::void mMain(...) {mState = mThread->State;}
Figure 32.4: Ordering Bug (ordering.c)
您可能已经发现,线程2中的代码似乎假设变量mThread已经初始化(并且不是NULL); 然而,如果线程2一旦创建就立即运行,那么mThread的值在线程2的mMain()中被访问时将不会被设置,并且很可能会因为空指针解引用而崩溃。注意,我们假设mThread的值最初是NULL;如果不是,当线程2通过解引用访问任意内存位置时,甚至会发生更奇怪的事情。
顺序冲突的更正式的定义如下:“颠倒两(组)内存访问之间的期望顺序(即,A应该总是在B之前执行,但在执行期间不强制执行)”[L+08]。
对这类错误的修复通常是强制排序。如前所述,使用条件变量(condition variables)是一种将这种同步风格添加到现代代码库中的简单而可靠的方法。在上面的例子中,我们因此可以重写代码,如图 32.5 所示。
pthread_mutex_t mtLock = PTHREAD_MUTEX_INITIALIZER;pthread_cond_t mtCond = PTHREAD_COND_INITIALIZER;int mtInit = 0;Thread 1::void init() {...mThread = PR_CreateThread(mMain, ...);// signal that the thread has been created...pthread_mutex_lock(&mtLock);mtInit = 1;pthread_cond_signal(&mtCond);pthread_mutex_unlock(&mtLock);...}Thread 2::void mMain(...) {...// wait for the thread to be initialized...pthread_mutex_lock(&mtLock);while (mtInit == 0)pthread_cond_wait(&mtCond, &mtLock);pthread_mutex_unlock(&mtLock);mState = mThread->State;...}
Figure 32.5: Fixing The Ordering Violation (ordering fixed.c)
在这个修复后的代码序列中,我们添加了一个条件变量(mtCond)和相应的锁(mtLock),以及一个状态变量(mtInit)。当初始化代码运行时,它将mtInit的状态设置为1,并发出信号表示已经这样做了。如果线程2在此之前运行过,它将等待这个信号和相应的状态变化;如果稍后运行,它将检查状态,并看到初始化已经发生(即,mtInit被设置为1),因此继续正常运行。注意,我们可以使用mThread本身作为状态变量,但为了简单起见,这里不要这样做。当线程之间进行排序时,条件变量(或信号量)可以发挥作用。
非死锁粗无:总结 Non-Deadlock Bugs: Summary
Lu等人研究的大部分(97%)非死锁错误要么是原子性冲突,要么是顺序冲突。因此,通过仔细考虑这些类型的错误模式,程序员可能会更好地避免它们。此外,随着越来越多的自动化代码检查工具的开发,它们可能会关注这两种类型的错误,因为它们构成了部署中发现的很大一部分非死锁错误。
32.3 死锁Bugs Deadlock Bugs
除了上面提到的并发错误之外,在许多具有复杂锁定协议的并发系统中出现的一个经典问题是死锁。例如,当一个线程(比如线程1)持有一个锁(L1)并等待另一个锁(L2)时; 不幸的是,持有L2锁的线程(线程2)正在等待L1被释放,就会发生死锁。下面的代码片段演示了这种潜在的死锁:
Thread 1:pthread_mutex_lock(L1);pthread_mutex_lock(L2);Thread 2:pthread_mutex_lock(L2);pthread_mutex_lock(L1);
Figure 32.6: Simple Deadlock (deadlock.c)
请注意,如果此代码运行,并不是一定会发生死锁;相反,它只是可能发生,例如,如果线程 1 获取锁 L1,然后线程 2 发生上下文切换。此时,线程 2 获取 L2,并尝试获取 L1。因此,我们有一个死锁,因为每个线程都在等待另一个线程,并且都不能运行。有关图形描述,请参见图 32.7;图中循环(cycle)的存在表示死锁。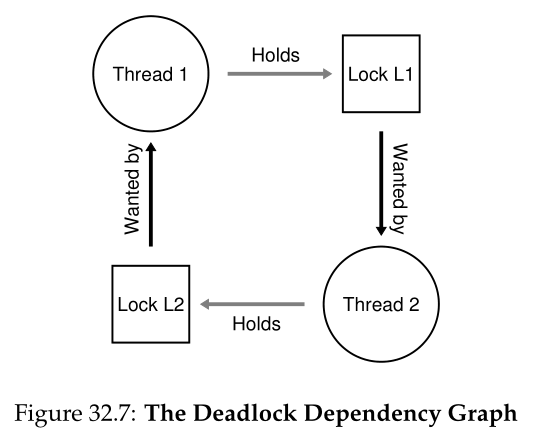
该图应该可以清楚地说明问题。程序员应该如何编写代码以便以某种方式处理死锁?
关键的问题:怎样处理死锁 我们应该如何构建系统来防止、避免或至少检测并从死锁中恢复?这在今天的系统中是一个真正的问题吗?
您可能会想,像上面这样的简单死锁似乎是可以避免的。例如,如果线程1和线程2都确保以相同的顺序获取锁,则不会出现死锁。那么为什么会发生死锁呢?
一个原因是,在大型代码库中,组件之间会出现复杂的依赖关系。以操作系统为例。虚拟内存系统可能需要访问文件系统才能从磁盘中分页;文件系统随后可能需要一页内存来将块读入并因此联系虚拟内存系统。因此,大型系统中锁定策略的设计必须谨慎进行,以避免在代码中可能自然发生的循环依赖的情况下发生死锁。
另一个原因是封装的性质。作为软件开发人员,我们被教导隐藏实现的细节,从而使软件更容易以模块化的方式构建。不幸的是,这种模块化不能很好地与锁相结合。正如Jula等人指出的[J+08],一些看似无害的接口几乎会导致死锁。例如,以Java Vector类和AddAll()方法为例。这个例程将被如下调用:
Vector v1, v2;v1.AddAll(v2);
在内部,因为该方法需要是多线程安全的,因此需要获取添加到 (v1) 的向量和参数 (v2) 的锁。该例程以某种任意顺序(比如 v1 然后 v2)获取所述锁,以便将 v2 的内容添加到 v1。如果某个其他线程几乎同时调用 v2.AddAll(v1),我们就有可能发生死锁,这对调用应用程序来说是相当隐藏的。
产生死锁的条件 Conditions for Deadlock
发生死锁需要满足以下四个条件:
- 互斥(Mutual exclusion): 线程要求对它们需要的资源进行独占控制(例如,线程获取锁)。
- 持有并等待(hold-and-wait): 线程在等待额外资源(例如,线程希望获取的锁)的同时,持有分配给它们的资源(例如,线程已经获得的锁)。
- 无抢占(No preemption): 资源(如锁)不能从持有它们的线程中强制移除。
- 循环等待(Circular wait): 存在一个循环的线程链,每个线程持有链中下一个线程请求的一个或多个资源(例如锁)。
如果没有满足这四个条件中的任何一个,就不会发生死锁。因此,我们首先探讨防止死锁的技术;这些策略都是为了防止出现上述情况之一,因此是处理死锁问题的一种方法。
防止 Prevention
循环等待 Circular Wait
最实用的预防技术(当然也是经常使用的技术)可能是编写锁定代码,这样就不会引发循环等待。最简单的方法是提供获取锁的总顺序(total ordering)。例如,如果系统中只有两个锁(L1和L2),您可以通过总是在L2之前获取L1来防止死锁。如此严格的排序确保不会出现循环等待; 因此,没有死锁。
当然,在更复杂的系统中,将存在两个以上的锁,因此总锁顺序可能很难实现(而且可能是不必要的)。因此,为了避免死锁,部分排序(partial ordering)是一种有用的获取锁的方法。在Linux [T+94] (v5.2)的内存映射代码中可以看到部分锁排序的一个很好的真实示例;源代码顶部的注释揭示了10组不同的锁获取顺序,包括简单的顺序,如“i_mutex在i_mmap_rwsem之前”,以及更复杂的顺序,如“i_mmap_rwsem在private_lock之前,private_lock在swap_lock之前,swap_lock在i_pages_lock之前”。
可以想象,完全排序和部分排序都需要仔细设计锁定策略,并且必须非常小心地构造。此外,排序只是一种约定,粗心的程序员很容易忽略锁定协议,并可能导致死锁。最后,锁顺序需要对代码库以及各种例程的调用有深入的了解;只要一个错误就可能导致“D”字。
提示: “D”代表“Deadlock”。
Tip:根据锁地址强制锁顺序 在某些情况下,一个函数必须获取两个(或更多)锁;因此,我们知道我们必须小心,否则可能会出现僵局。想象这样一个函数:do_something(mutex_t m1, mutex_t m2)。如果代码总是在m2之前抓取m1(或者总是在m1之前抓取m2),它可能会死锁,因为一个线程可以调用do_something(L1, L2),而另一个线程可以调用do_something(L2, L1)。 为了避免这个问题,聪明的程序员可以使用每个锁的地址作为获取锁的顺序。通过以从高到低或从低到高的地址顺序获取锁,do_something()可以保证它总是以相同的顺序获取锁,而不管传入的顺序是什么。代码看起来像这样:
通过使用这种简单的技术,程序员可以确保多锁获取的简单和高效的无死锁实现。
持有并等待 Hold-and-wait
通过一次性原子地获取所有锁,可以避免死锁的持有并等待要求。在实践中,这可以通过以下方式实现:
pthread_mutex_lock(prevention); // begin acquisitionpthread_mutex_lock(L1);pthread_mutex_lock(L2);...pthread_mutex_unlock(prevention); // end
通过首先获取锁prevention,这段代码确保在获取锁的过程中不会发生不合时宜的线程切换,从而再次避免死锁。当然,它要求任何线程在获取锁时,首先获取全局prevention锁。例如,如果另一个线程试图以不同的顺序获取锁L1和L2,这是可以的,因为它在这样做时将持有prevention锁。<br />请注意,**由于许多原因,该解决方案存在问题**。和以前一样,封装对我们不利:当调用例程时,这种方法要求我们确切地知道必须持有哪些锁并提前获取它们。这种技术还可能降低并发性,因为所有锁都必须在早期(立即)获得,而不是在真正需要它们的时候。
无抢占 No Preemption
因为我们通常认为锁是持有的,直到解锁被调用,多次获取锁经常让我们陷入麻烦,因为当等待一个锁时,我们持有另一个锁。许多线程库提供了一组更灵活的接口来帮助避免这种情况。具体来说,例程pthread_mutex_trylock()要么获取锁(如果它是可用的)并返回成功,要么返回一个表示锁被持有的错误代码;在后一种情况下,如果您想获取该锁,可以稍后再试一次。
这样的接口可以像下面这样用来构建一个无死锁、有序健壮的锁获取协议:
top:pthread_mutex_lock(L1);if (pthread_mutex_trylock(L2) != 0) {pthread_mutex_unlock(L1);goto top;}
注意,另一个线程可以遵循同样的协议,但以另一种顺序(L2然后L1)获取锁,并且程序仍然是无死锁的。然而,一个新的问题出现了:**livelock(活锁)**。**有可能(尽管可能不太可能)两个线程都在重复尝试这个序列,但都无法获得这两个锁。在这种情况下,两个系统都一次又一次地运行这个代码序列(因此它不是死锁),但是没有进展,因此命名为livelock。也有解决活锁问题的方法:例如,可以在返回并再次尝试整个过程之前添加一个随机延迟,从而降低竞争线程之间重复干扰的几率。**<br />**关于此解决方案的一点是:它绕过了使用 trylock 方法的困难部分。由于封装,可能会再次出现的第一个问题是:如果这些锁中的一个被埋在某个被调用的例程中,则跳转回开始的实现会变得更加复杂。如果代码在此过程中获得了一些资源(L1 以外的资源),则必须确保也小心地释放它们;例如,如果在获取 L1 后,代码分配了一些内存,则必须在获取 L2 失败时释放该内存,然后再跳回顶部以再次尝试整个序列。然而,在有限的情况下(例如,前面提到的 Java 的 vector 方法),这种类型的方法可以很好地工作**。<br />您可能还注意到,这种方法并没有真正添加抢占(从拥有锁的线程中获取锁的强制操作),而是使用trylock方法来允许开发人员以一种优雅的方式退出锁的所有权(即抢占自己的所有权)。**然而,这是一种实际的做法,因此我们将它列入这里,尽管它在这方面有缺陷**。
互斥 Mutual Exclusion
最后的预防技术是完全避免互斥的需要。一般来说,我们知道这很困难,因为我们希望运行的代码确实有临界区。所以,我们能做些什么?
Herlihy的想法是,人们可以在没有锁的情况下设计各种数据结构[H91, H93]。这里这些无锁(lock-free)(和相关的无等待(wait-free))方法背后的思想很简单:使用强大的硬件指令,您可以以不需要显式锁定的方式构建数据结构。
作为一个简单的例子,让我们假设我们有一个比较并交换指令,您可能还记得,这是一个由硬件提供的原子指令,执行以下操作:
int CompareAndSwap(int *address, int expected, int new) {if (*address == expected) {*address = new;return 1; // success}return 0; // failure}
想象一下,现在我们想使用比较并交换来原子地增加一个值一定数量。我们可以通过以下简单的函数来实现:
void AtomicIncrement(int *value, int amount) {do {int old = *value;} while (CompareAndSwap(value, old, old + amount) == 0);}
我们不是获取一个锁,执行更新,然后释放它,而是构建了一种方法,反复尝试将值更新为新的量,并使用比较并交换来实现这一点。通过这种方式,不会获得锁,也不会出现死锁(尽管仍然存在活锁的可能性,因此健壮的解决方案将比上面的简单代码段更复杂)。<br />让我们考虑一个稍微复杂一点的示例: 链表插入。下面是插入链表head的代码:
void insert(int value) {node_t *n = malloc(sizeof(node_t));assert(n != NULL);n->value = value;n->next = head;head = n;}
这段代码执行一个简单的插入操作,但是如果被多个线程同时调用,就会出现竞争条件。你能找出原因吗?(画一幅图,说明如果发生两个并发插入,链表会发生什么情况,一如既往地假设发生了恶意的调度交错)。当然,我们可以通过使用获取和释放锁来解决这个问题:
void insert(int value) {node_t *n = malloc(sizeof(node_t));assert(n != NULL);n->value = value;pthread_mutex_lock(listlock); // begin critical sectionn->next = head;head = n;pthread_mutex_unlock(listlock); // end critical section}
在这个解决方案中,我们以传统的方式使用锁注释1。相反,让我们尝试**使用比较并交换指令以无锁的方式执行插入操作**。以下是一种可能的方法:
注释1:精明的读者可能会问,为什么我们这么晚才获得锁,而不是在输入insert()时获得锁; 机敏的读者,你能找出为什么这句话可能是正确的吗?例如,代码对malloc()的调用做了什么假设?
void insert(int value) {node_t *n = malloc(sizeof(node_t));assert(n != NULL);n->value = value;do {n->next = head;} while (CompareAndSwap(&head, n->next, n) == 0);}
这里的代码更新了指向当前head的next指针,然后尝试将新创建的节点交换为列表的新head。但是,如果在此期间其他线程成功地交换了新的head,则此操作将失败,导致该线程再次使用新head重试。<br />当然,构建一个有用的链表需要的不仅仅是链表插入,构建一个可以插入、删除和以无锁方式执行查找的链表并不简单。阅读关于**无锁和无等待同步(lock-free and wait-free synchronization)**的丰富文献以了解更多[H01, H91, H93]。
通过调度避免死锁 Deadlock Avoidance via Scheduling
在某些情况下,避免(avoidance)死锁比防止(prevention)死锁更可取。要避免这种情况,需要全局地了解各个线程在执行过程中可能获取哪些锁,然后以确保不会发生死锁的方式调度这些线程。
例如,假设我们有两个处理器和四个线程,它们必须被调度。进一步假设我们知道线程1 (T1)获取锁L1和L2(在执行过程中的某个点上,按照某种顺序),T2也获取L1和L2, T3只获取L2, T4根本不获取锁。我们可以用表格的形式显示线程的锁获取需求:
| | T1 | T2 | T3 | T4 | | —- | —- | —- | —- | —- | | L1 | yes | yes | no | no | | L2 | yes | yes | yes | no |
因此,智能调度器可以计算出,只要T1和T2没有同时运行,就不会出现死锁。这里有一个这样的调度:<br />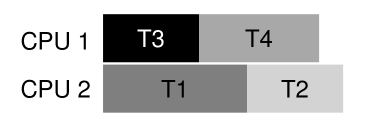<br />注意,(T3和T1)或(T3和T2)重叠是可以的。即使T3捕获L2锁,它也不会因为与其他线程并发运行而导致死锁,因为它只捕获一个锁。<br />让我们再看一个例子。在这个例子中,相同的资源有更多的争用(同样是锁L1和L2),如下争用表所示:
| | T1 | T2 | T3 | T4 | | —- | —- | —- | —- | —- | | L1 | yes | yes | yes | no | | L2 | yes | yes | yes | no |
特别是,线程T1、T2和T3都需要在执行期间的某个点获取锁L1和L2。以下是一种可能的时间表,可以保证不会发生死锁:<br />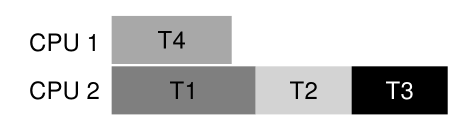<br />可以看到,静态调度导致了一种保守的方法,即T1、T2和T3都在同一个处理器上运行,因此完成作业的总时间大大延长了。尽管并发地运行这些任务是可能的,但是对死锁的恐惧阻止了我们这样做,并且代价是性能。<br />这种方法的一个著名例子是Dijkstra的银行家算法[D64],在文献中已经描述了许多类似的方法。不幸的是,**它们只在非常有限的环境中有用**,例如,在嵌入式系统中,您完全了解必须运行的整个任务集以及所需的锁。而且,正如我们在上面的第二个例子中看到的,这种方法可以限制并发性。**因此,通过调度来避免死锁并不是一个广泛使用的通用解决方案**。
Tip:不要总是做得很完美(汤姆·韦斯特定律)(DON’T ALWAYS DO IT PERFECTLY (TOM WEST’S LAW)) 作为计算机行业经典著作《新机器的灵魂》(Soul of a New Machine [K81])的主题而闻名的汤姆•韦斯特(Tom West)有句名言:“不是每件值得做的事都值得做好”,这是一个了不起的工程格言。如果一件坏事很少发生,人们当然不应该花大量的努力去阻止它,特别是当坏事发生的成本很小的时候。另一方面,如果你正在建造一架航天飞机,而出错的代价是航天飞机爆炸,那么,也许你应该忽略这条建议。 一些读者反对说:“这听起来像是你在建议用平庸来解决问题!”也许他们是对的,我们应该谨慎提出这样的建议。然而,我们的经验告诉我们,在工程世界中,伴随着紧迫的截止日期和其他现实世界的问题,人们总是不得不决定系统的哪些方面要做好,哪些要放到另一天去做。困难的部分是知道什么时候该做什么,只有通过经验和对手头任务的投入才能获得一点洞察力。
检测并恢复 Detect and Recover
最后一个通用策略是允许死锁偶尔发生,然后在检测到死锁后采取一些行动。例如,如果一个操作系统每年冻结一次,你只需重新启动它,然后愉快地(或暴躁地)继续工作。如果死锁很少见,那么这种不解决方案(non-solution)确实相当实用。
许多数据库系统采用死锁检测和恢复技术。死锁检测器定期运行,构建资源图并检查它的循环。如果出现循环(死锁),则需要重新启动系统。如果首先需要对数据结构进行更复杂的修复,则可能需要人工来简化该过程。
关于数据库并发性、死锁和相关问题的更多细节可以在其他地方找到[B+87, K87]。阅读这些作品,或者更好的是,参加数据库课程,了解更多关于这个丰富而有趣的话题。
32.4
总结 Summary
在本章中,我们研究了并发程序中出现的错误类型。第一种类型是非死锁错误,非常常见,但通常更容易修复。它们包括原子性冲突,其中应该一起执行的指令序列没有执行,以及顺序冲突,其中两个线程之间所需的顺序没有执行。
我们还简要地讨论了死锁:为什么会发生死锁,以及可以做些什么。这个问题和并发本身一样古老,关于这个主题的论文已经有几百篇了。实践中最好的解决方案是谨慎地开发锁获取顺序,从而从一开始就防止死锁的发生。无等待方法也有前景,因为一些无等待数据结构现在正在寻找进入常用库和关键系统的方法,包括Linux。然而,它们缺乏通用性,而且开发一种新的无等待数据结构的复杂性可能会限制这种方法的整体效用。也许最好的解决方案是开发新的并发编程模型:在像MapReduce(来自谷歌)[GD02]这样的系统中,程序员可以在不使用任何锁的情况下描述某些类型的并行计算。锁本身就是有问题的;也许我们应该设法避免使用它们,除非我们真的必须这样做。
References
[B+87] “Concurrency Control and Recovery in Database Systems” by Philip A. Bernstein, Vassos Hadzilacos, Nathan Goodman. Addison-Wesley, 1987.
数据库管理系统并发性的经典著作。正如您所知,了解并发性、死锁和数据库世界中的其他主题本身就是一个世界。研究它,为自己找出答案。
[C+71] “System Deadlocks” by E.G. Coffman, M.J. Elphick, A. Shoshani. ACM Computing
Surveys, 3:2, June 1971.
概述死锁的条件和如何处理它的经典论文。当然有一些关于这个主题的早期论文;详见本文的参考文献。
[D64] “Een algorithme ter voorkoming van de dodelijke omarming” by Edsger Dijkstra. 1964.
http://www.cs.utexas.edu/users/EWD/ewd01xx/EWD108.PDF
事实上,Dijkstra不仅提出了许多解决死锁问题的方法,而且是第一个注意到死锁存在的人,至少是书面形式的。然而,他称之为“致命拥抱”,(谢天谢地)并没有流行起来。
[GD02] “MapReduce: Simplified Data Processing on Large Clusters” by Sanjay Ghemawhat,
Jeff Dean. OSDI ’04, San Francisco, CA, October 2004.
MapReduce论文开创了大规模数据处理时代,并提出了一个框架,用于在通常不可靠的机器集群上执行此类计算。
[H01] “A Pragmatic Implementation of Non-blocking Linked-lists” by Tim Harris. International Conference on Distributed Computing (DISC), 2001.
这是一个相对现代的例子,说明了构建像没有锁的并发链表这样简单的东西是多么困难。
[H91] “Wait-free Synchronization” by Maurice Herlihy . ACM TOPLAS, 13:1, January 1991.
Herlihy的工作开创了编写并发程序的无等待方法背后的思想。这些方法往往是复杂和困难的,通常比正确使用锁更困难,这可能限制了它们在现实世界中的成功。
[H93] “A Methodology for Implementing Highly Concurrent Data Objects” by Maurice Herlihy. ACM TOPLAS, 15:5, November 1993.
对无锁和无等待结构的一个很好的概述。这两种方法都避免了锁,但无等待方法更难实现,因为它们试图确保并发结构上的任何操作都将在有限的步骤中终止(例如,没有无限循环)。
[J+08] “Deadlock Immunity: Enabling Systems To Defend Against Deadlocks” by Horatiu
Jula, Daniel Tralamazza, Cristian Zamfir, George Candea. OSDI ’08, San Diego, CA, December
2008.
最近一篇关于死锁和如何避免在特定系统中一次又一次陷入相同死锁的优秀论文。
[K81] “Soul of a New Machine” by Tracy Kidder. Backbay Books, 2000 (reprint of 1980 version).
这是任何系统构建者或工程师的必读书籍,详细描述了Data General (DG)内部由Tom West领导的团队如何在早期工作以生产“新机器”。基德尔的其他著作也很优秀,包括“Mountains beyond Mountains”。或者你不同意我们的观点,逗号?
[K87] “Deadlock Detection in Distributed Databases” by Edgar Knapp. ACM Computing Surveys, 19:4, December 1987.
对分布式数据库系统中死锁检测的极好概述。还指出了一些其他相关的作品,因此是一个很好的地方开始你的阅读。
[L+08] “Learning from Mistakes — A Comprehensive Study on Real World Concurrency Bug
Characteristics” by Shan Lu, Soyeon Park, Eunsoo Seo, Yuanyuan Zhou. ASPLOS ’08, March
2008, Seattle, Washington.
第一次深入研究了实际软件中的并发bug,是本章的基础。看看Y.Y. Zhou或Shan Lu的网页,你会发现更多关于bugs的有趣论文。
[T+94] “Linux File Memory Map Code” by Linus Torvalds and many others.
http://lxr.free-electrons.com/source/mm/filemap.c
感谢纽约大学的Michael Walfish指出了这个宝贵的例子。现实世界,正如你在这个文件中看到的,可能比教科书中简单明了的世界要复杂一点……
Homework (Code)
本作业允许您研究一些死锁(或避免死锁)的实际代码。不同版本的代码对应于在简化的vector_add()例程中避免死锁的不同方法。有关这些程序及其公共子程序的详细信息,请参阅README。
Questions
- 首先,让我们确保您了解程序通常是如何工作的,以及一些关键选项。研究vector-deadlock.c中的代码,以及main-common.c和相关文件中的代码。
现在,运行 ./vector-deadlock -n 2 -l 1 -v,它实例化两个线程(-n 2),每个线程执行一个vector_add (-l 1),并且在verbose模式下执行(-v)。确保你理解了输出。每次运行的输出如何变化?
- 现在添加-d标志,并将循环数(-l)从1更改为更大的数。会发生什么呢?代码(总是)死锁吗?
- 改变线程数(-n)如何改变程序的结果?是否有-n的值确保不会发生死锁?
- 现在检查vector-global-order.c中的代码。首先,确保您理解代码试图做什么;你知道为什么代码会避免死锁吗?另外,当源vectors和目标vectors相同时,为什么vector_add()例程会出现特殊情况?
- 现在用以下标志运行代码:-t -n 2 -l 100000 -d。完成代码需要多长时间?当你增加循环的数量或线程的数量时,总时间是如何变化的?
- 如果打开并行标志(-p)会发生什么?当每个线程都在添加不同的vectors(这是-p所启用的)而不是在相同的vectors上工作时,您希望性能有多大的变化?
- 现在让我们研究vector-try-wait.c。首先确保您理解代码。真的需要第一次调用pthread_mutex_trylock()吗?现在运行代码。与global order方法相比,它的运行速度有多快?代码计算的重试次数如何随着线程数量的增加而改变?
- 现在让我们看看vector-avoid-hold-wait.c。这种方法的主要问题是什么?当同时运行-p和不运行时,它的性能与其他版本相比如何?
- 最后,让我们看看vector-nolock.c。这个版本根本不使用锁;它是否提供与其他版本完全相同的语义?为什么或为什么不?
- 现在将其性能与其他版本进行比较,当线程在相同的两个vectors上工作时(没有 -p),以及当每个线程在不同的vectors上工作时(-p)。这个无锁版本的性能如何?

若有收获,就点个赞吧
0 人点赞
