1、为什么要用分布式锁
单机应用:要对某一个共享变量进行多线程同步访问的时候,Java多线程进行处理。
业务发展,需要做集群,一个应用需要部署到几台机器上然后做负载均衡,
分布式、集群部署、负载均衡:
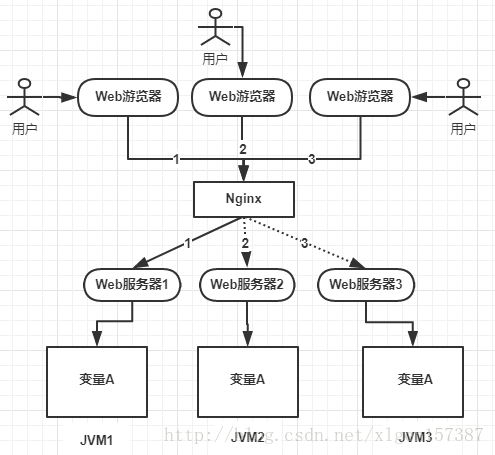
变量A存在三个服务器内存中(这个变量A主要体现是在一个类中的一个成员变量,是一个有状态的对象),如果不加任何控制的话,变量A同时都会在分配一块内存,三个请求发过来同时对这个变量操作,显然结果是不对的!即使不是同时发过来,三个请求分别操作三个不同内存区域的数据,变量A之间不存在共享,也不具有可见性,处理的结果也是不对的!
产生问题:多个服务器怎么对A变量维护,变量A之间不存在共享,也不具有可见性,处理的结果也是不对的!
引出分布式锁: 为了解决这个问题就需要一种跨JVM的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题!
2、分布式锁应该具备的几种条件
1、在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行;
2、高可用的获取锁与释放锁;
3、高性能的获取锁与释放锁;
4、具备可重入特性;
5、具备锁失效机制,防止死锁;
6、具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败。
3、分布式锁的三种实现方式
分布式的CAP理论告诉我们“任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),最多只能同时满足两项。”所以,很多系统在设计之初就要对这三者做出取舍。在互联网领域的绝大多数的场景中,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证“最终一致性”,只要这个最终时间是在用户可以接受的范围内即可。
[CAP: 一致性、可用性、分区容错性]
三种实现方式:
基于数据库实现分布式锁;
基于缓存(Redis等)实现分布式锁;
基于Zookeeper实现分布式锁;
3.1.基于数据库实现分布式锁:
3.1.1.基本操作步骤
1、建表:如method执行记录表2、对表中方法名字段增加一个UNIQUE KEY 唯一索引。3、由于我们对`method_name`做了**唯一性约束**,这里如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功,那么我们就可以认为操作成功的那个线程获得了该方法的锁,可以执行方法体内容。4、成功插入则获取锁,执行完成后删除对应的行数据释放锁。
3.1.2.问题待优化:
1、因为是基于数据库实现的,数据库的可用性和性能将直接影响分布式锁的可用性及性能,所以,数据库需要双机部署、数据同步、主备切换;2、不具备可重入的特性,因为同一个线程在释放锁之前,行数据一直存在,无法再次成功插入数据,所以,需要在表中新增一列,用于记录当前获取到锁的机器和线程信息,在再次获取锁的时候,先查询表中机器和线程信息是否和当前机器和线程相同,若相同则直接获取锁;3、没有锁失效机制,因为有可能出现成功插入数据后,服务器宕机了,对应的数据没有被删除,当服务恢复后一直获取不到锁,所以,需要在表中新增一列,用于记录失效时间,并且需要有定时任务清除这些失效的数据;4、不具备阻塞锁特性,获取不到锁直接返回失败,所以需要优化获取逻辑,循环多次去获取。5、在实施的过程中会遇到各种不同的问题,为了解决这些问题,实现方式将会越来越复杂;依赖数据库需要一定的资源开销,性能问题需要考虑。
3.2 基于Redis实现的分布式锁
3.2.1. 选择Redis实现分布式锁的原因
1、Redis有很高的性能;
2、Redis命令对此支持较好,实现起来比较方便
3.2.2. 处理方式和问题
(1)SETNX
SETNX key val:当且仅当key不存在时,set一个key为val的字符串,返回1;若key存在,则什么都不做,返回0。
(2)expire
expire key timeout:为key设置一个超时时间,单位为second,超过这个时间锁会自动释放,避免死锁。
(3)delete
delete key:删除key
在使用Redis实现分布式锁的时候,主要就会使用到这三个命令。
1、(java)redisTemplate setIfAbsent == setNx 加锁
或 String result = jedis.set(lockKey, requestId, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, expireTime);
问题:获得锁后,有可能出现中断down,锁没删除,没释放解决: 设置expire问题: 设置超时和加锁不是同一个原子性操作解决:加锁时同时设置超时,一个原子性操作问题:超时后,别人获得我的锁,我处理完事情,把他的锁删掉了解决:加一次业务id校验问题:锁超时后被他人获取,最终可能造成锁失效,类同于不加锁并发操作解决:获得锁的线程,开一个新线程,去检测是否快过期,进行续命2、使用LUA脚本, 保证原子性(类似是一个锁,里面的所有语句都是在同一个锁下进行,保证别人不能插进来,保证这一段代码执行的原子性)
3.2.3 Redission
加锁:
尝试获得锁
tryLockInnerAsync方法是真正执行获取锁的逻辑,它是一段LUA脚本代码.
如果不存在 则设置 key 加锁 设置过期时间 加锁次数为1
如果存在 且等于当前线程 则加锁次数加1 且 刷新过期时间
如果存在 且不等于当前线程,则返回过期时间ttl
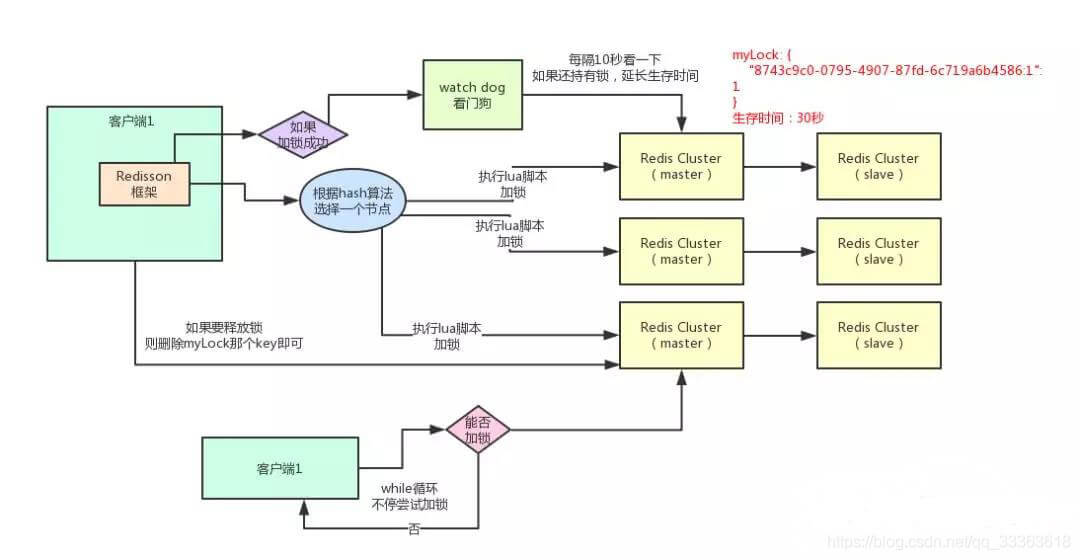
获得锁,增加FutureListener , 重写operationComplete,开启定时任务不断刷新该锁的过期时间
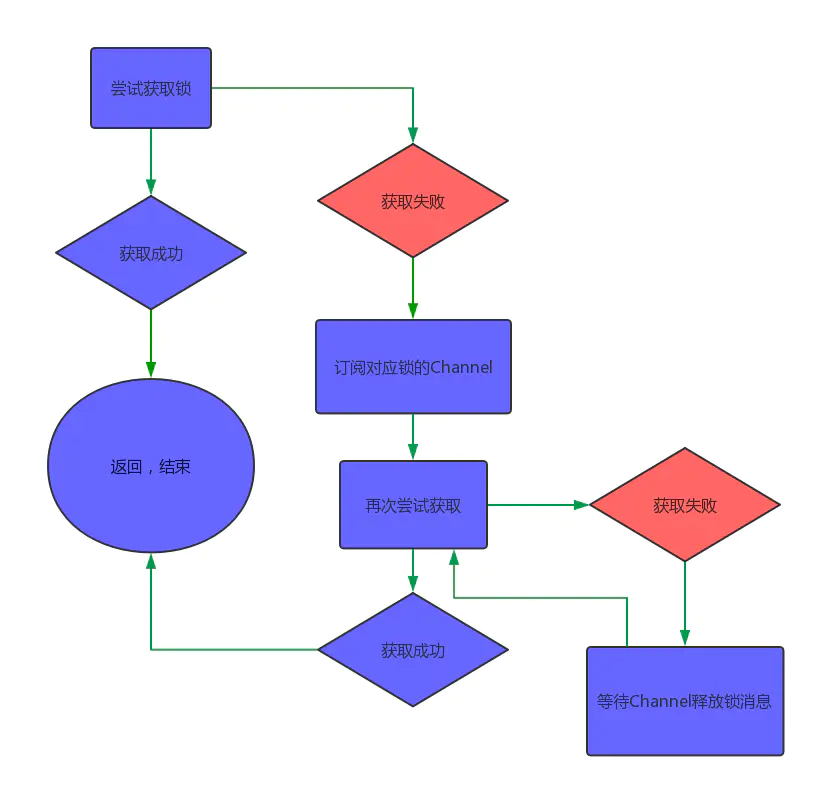
未获得锁的线程,订阅锁channel,
死循环轮训,去尝试获得锁, 如果获得锁返回,如果未获得锁,如果得到锁的过期时间,在锁过期时间到达时再次重试
如果没设置过期时间,则再次重试尝试获取
public void lockInterruptibly(long leaseTime, TimeUnit unit) throws InterruptedException {//当前线程IDlong threadId = Thread.currentThread().getId();//尝试获取锁Long ttl = tryAcquire(leaseTime, unit, threadId);// 如果ttl为空,则证明获取锁成功if (ttl == null) {return;}//如果获取锁失败,则订阅到对应这个锁的channelRFuture<RedissonLockEntry> future = subscribe(threadId);commandExecutor.syncSubscription(future);try {while (true) {//再次尝试获取锁ttl = tryAcquire(leaseTime, unit, threadId);//ttl为空,说明成功获取锁,返回if (ttl == null) {break;}//ttl大于0 则等待ttl时间后继续尝试获取if (ttl >= 0) {getEntry(threadId).getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);} else {getEntry(threadId).getLatch().acquire();}}} finally {//取消对channel的订阅unsubscribe(future, threadId);}//get(lockAsync(leaseTime, unit));}
private <T> RFuture<Long> tryAcquireAsync(long leaseTime, TimeUnit unit, final long threadId) {//如果带有过期时间,则按照普通方式获取锁if (leaseTime != -1) {return tryLockInnerAsync(leaseTime, unit, threadId, RedisCommands.EVAL_LONG);}//先按照30秒的过期时间来执行获取锁的方法RFuture<Long> ttlRemainingFuture = tryLockInnerAsync(commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout(),TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);//如果还持有这个锁,则开启定时任务不断刷新该锁的过期时间ttlRemainingFuture.addListener(new FutureListener<Long>() {@Overridepublic void operationComplete(Future<Long> future) throws Exception {if (!future.isSuccess()) {return;}Long ttlRemaining = future.getNow();// lock acquiredif (ttlRemaining == null) {scheduleExpirationRenewal(threadId);}}});return ttlRemainingFuture;}
tryLockInnerAsync方法是真正执行获取锁的逻辑,它是一段LUA脚本代码。在这里,它使用的是hash数据结构。
<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit,long threadId, RedisStrictCommand<T> command) {//过期时间internalLockLeaseTime = unit.toMillis(leaseTime);return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,//如果锁不存在,则通过hset设置它的值,并设置过期时间"if (redis.call('exists', KEYS[1]) == 0) then " +"redis.call('hset', KEYS[1], ARGV[2], 1); " +"redis.call('pexpire', KEYS[1], ARGV[1]); " +"return nil; " +"end; " +//如果锁已存在,并且锁的是当前线程,则通过hincrby给数值递增1"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +"redis.call('pexpire', KEYS[1], ARGV[1]); " +"return nil; " +"end; " +//如果锁已存在,但并非本线程,则返回过期时间ttl"return redis.call('pttl', KEYS[1]);",Collections.<Object>singletonList(getName()),internalLockLeaseTime, getLockName(threadId));}
这段LUA代码看起来并不复杂,有三个判断:
- 通过exists判断,如果锁不存在,则设置值和过期时间,加锁成功
- 通过hexists判断,如果锁已存在,并且锁的是当前线程,则证明是重入锁,加锁成功
- 如果锁已存在,但锁的不是当前线程,则证明有其他线程持有锁。返回当前锁的过期时间,加锁失败
加锁成功后,在redis的内存数据中,就有一条hash结构的数据。Key为锁的名称;field为随机字符串+线程ID;值为1。如果同一线程多次调用lock方法,值递增1。
127.0.0.1:6379> hgetall lock11) "b5ae0be4-5623-45a5-8faa-ab7eb167ce87:1"2) "1"
使用LUA,保证原子性加锁成功后,周期1/3时间 watchdog检查续命具有可重入性,判断是同一个客户端,则修改锁的hash数据结构中,加锁次数+1**解锁:**
public RFuture<Void> unlockAsync(final long threadId) {final RPromise<Void> result = new RedissonPromise<Void>();//解锁方法RFuture<Boolean> future = unlockInnerAsync(threadId);future.addListener(new FutureListener<Boolean>() {@Overridepublic void operationComplete(Future<Boolean> future) throws Exception {if (!future.isSuccess()) {cancelExpirationRenewal(threadId);result.tryFailure(future.cause());return;}//获取返回值Boolean opStatus = future.getNow();//如果返回空,则证明解锁的线程和当前锁不是同一个线程,抛出异常if (opStatus == null) {IllegalMonitorStateException cause =new IllegalMonitorStateException("attempt to unlock lock, not locked by current thread by node id: "+ id + " thread-id: " + threadId);result.tryFailure(cause);return;}//解锁成功,取消刷新过期时间的那个定时任务if (opStatus) {cancelExpirationRenewal(null);}result.trySuccess(null);}});return result;}
protected RFuture<Boolean> unlockInnerAsync(long threadId) {return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, EVAL,//如果锁已经不存在, 发布锁释放的消息"if (redis.call('exists', KEYS[1]) == 0) then " +"redis.call('publish', KEYS[2], ARGV[1]); " +"return 1; " +"end;" +//如果释放锁的线程和已存在锁的线程不是同一个线程,返回null"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " +"return nil;" +"end; " +//通过hincrby递减1的方式,释放一次锁//若剩余次数大于0 ,则刷新过期时间"local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " +"if (counter > 0) then " +"redis.call('pexpire', KEYS[1], ARGV[2]); " +"return 0; " +//否则证明锁已经释放,删除key并发布锁释放的消息"else " +"redis.call('del', KEYS[1]); " +"redis.call('publish', KEYS[2], ARGV[1]); " +"return 1; "+"end; " +"return nil;",Arrays.<Object>asList(getName(), getChannelName()),LockPubSub.unlockMessage, internalLockLeaseTime, getLockName(threadId));}
如上代码,就是释放锁的逻辑。同样的,它也是有三个判断:
- 如果锁已经不存在,通过publish发布锁释放的消息,解锁成功
- 如果解锁的线程和当前锁的线程不是同一个,解锁失败,抛出异常
通过hincrby递减1,先释放一次锁。若剩余次数还大于0,则证明当前锁是重入锁,刷新过期时间;若剩余次数小于0,删除key并发布锁释放的消息,解锁成功
执行lock.unlock(),就可以释放分布式锁。每次都对myLock数据结构中的那个加锁次数减1。发现加锁次数是0了,说明这个客户端已经不再持有锁了,此时就会用:
“del myLock”命令,从redis里删除这个key。
然后呢,另外的客户端2就可以尝试完成加锁了。
优点:支持redis单实例、redis哨兵、redis cluster、redis master-slave等各种部署架构,基于Redis, 所以具有Redis 功能使用的封装,功能齐全。许多公司试用后可以用到企业级项目中,社区活跃度高。
缺点:最大的问题,就是如果你对某个redis master实例,写入了myLock这种锁key的value,此时会异步复制给对应的master slave实例。
但是这个过程中一旦发生redis master宕机,主备切换,redis slave变为了redis master。
接着就会导致,客户端2来尝试加锁的时候,在新的redis master上完成了加锁,而客户端1也以为自己成功加了锁。
此时就会导致多个客户端对一个分布式锁完成了加锁。
这时系统在业务语义上一定会出现问题,导致脏数据的产生。
所以这个就是redis cluster,或者是redis master-slave架构的主从异步复制导致的redis分布式锁的最大缺陷:在redis master实例宕机的时候,可能导致多个客户端同时完成加锁。
Redission操作步骤:
// 引入依赖// 1. Create config objectConfig = ...// 2. Create Redisson instanceRedissonClient redisson = Redisson.create(config);// 3. Get Redis based object or service you needRMap<MyKey, MyValue> map = redisson.getMap("myMap");RLock lock = redisson.getLock("myLock")lock.lock();//业务代码lock.unlock();
扩展链接:Redis主从复制原理总结
3.3 基于zookeeper实现的分布式
zookeeper的临时顺序节点
(1)ZooKeeper的每一个节点,都是一个天然的顺序发号器。
(2) ZooKeeper节点的递增有序性,可以确保锁的公平
(3)ZooKeeper的节点监听机制,可以保障占有锁的传递有序而且高效
(4)ZooKeeper的节点监听机制,能避免羊群效应
所谓羊群效应就是一个节点挂掉,所有节点都去监听,然后做出反应,这样会给服务器带来巨大压力,所以有了临时顺序节点,当一个节点挂掉,只有它后面的那一个节点才做出反应。
ZooKeeper的内部优越的机制,能保证由于网络异常或者其他原因,集群中占用锁的客户端失联时,锁能够被有效释放。一旦占用Znode锁的客户端与ZooKeeper集群服务器失去联系,这个临时Znode也将自动删除。排在它后面的那个节点,也能收到删除事件,从而获得锁。正是由于这个原因,在创建取号节点的时候,尽量创建临时znode
节点。
缺点:ZooKeeper实现的分布式锁,性能并不太高。为啥呢?
因为每次在创建锁和释放锁的过程中,都要动态创建、销毁瞬时节点来实现锁功能。大家知道,ZK中创建和删除节点只能通过Leader服务器来执行,然后Leader服务器还需要将数据同不到所有的Follower机器上,这样频繁的网络通信,性能的短板是非常突出的。
总之,在高性能,高并发的场景下,不建议使用ZooKeeper的分布式锁。而由于ZooKeeper的高可用特性,所以在并发量不是太高的场景,推荐使用ZooKeeper的分布式锁。
3.3.1 curator
参考链接:分布式锁的几种使用方式

若有收获,就点个赞吧
0 人点赞
