2.4.0 数据存储
Prometheus 的数据存储分为本地存储和远程存储两种方式,下面针对这两种方式进行详细讲解。
2.4.1 本地存储
Prometheus 的本地存储经历了两个版本的重要演进,从 Prometheus V1 版本升级到 V2 版本,又升级为现在的 V3 版本。从 V2 版本开始,Prometheus 的本地存储便充分借鉴了 Facebook Gorilla 的设计思想及 Facebook 内部的长期经验,总结了时序数据的以下特点:
◎ 相邻数据点时间戳的差值相对固定,即使有变化,也仅在一个很小的范围内浮动;
◎ 相邻数据点的值的变化幅度很小,甚至无变化;
◎ 对热数据的查询频率远远超出对非热点数据的查询频率,并且数据距离现在越近,热度越高。
在 Facebook 上发表的关于 Gorilla 的文章(http://www.vldb.org/pvldb/vol8/p1816-teller.pdf)中提出了一种压缩算法,可以将 16 字节的样本数据压缩到 1.37 字节,并且通过块(chunk)保存,如图 2-8 所示。
图 2-8
其原理非常简单,首先是对时间戳采用两次去差值的方式,加入 t0=10:00:00、t1=10:01:02 和 t2=10:02:02 三个时间点。在第 1 次压缩时,t1−t0=62,t2−t1=60;在第 2 次压缩时,60−62=−2。采用保存差值的方式来大幅度降低存储空间,采样的频率通常也是固定的,这样的差值几乎都是 0。对于指标值,则对相邻指标进行异或(XOR)操作,如果前后两个采样值相等,二者异或的结果为 0,则只需保存一个 0,而且监控数据通常都变化不大,异或的结果将会很小,便于保存。
但 Prometheus V2 的存储设计存在很大的问题,如下所述。
(1)每个序列都有一个文件,这样会耗尽文件系统的 Inode,并且同时随机读写了这么多的文件,磁盘的性能会大大降低,对于 SSD 还会存在写放大的问题。
(2)被监控对象不停更新。例如,在 Kubernetes 容器监控方面,容器的生命周期比较短暂,指标不停变化,会形成「时序流失」。随着时间的推移,虽然有 LevelDB 负责时序的索引,但这些时间序列会形成线性增长,导致内存积压过多,如图 2-9 所示。
图 2-9
(3)无法预测容量。数据首先在内存中缓慢构建,在被保存到磁盘中后,内存中的数据会被回收,这样发生时序流失时,内存的消耗就会增加。如果要查询已经存储到磁盘的历史数据,则会再次将相关数据全部加载到内存中,此时很容易发生内存溢出(OOM),导致 Prometheus 被「杀掉」,给运维人员造成很大的压力。
经过一些系列的参数调整后,Prometheus 内存溢出的问题仍然没有得到解决。在 2017 年,Prometheus 的存储迎来了 V3 版本。Prometheus V3 保留了高压缩比的块保存,将多个块保存到一个文件中,并通过一个 index 文件去索引,从而避免产生大量的文件;并且为了防止数据丢失,引入了 WAL。
如图 2-10 所示,Prometheus V3 将整个存储空间按照时间水平拆分成很多独立区间,每个区间就相当于一个独立的数据库。
图 2-10
V3 版本的优点如下:
◎ 从 V2 版本的每个时序一个文件改进到 V3 版本的一段时间一个文件,可以有效避免时序流失的问题,还可以任意组织多个块的数据到一个文件中;
◎ 每个文件块最大支持 512MB,可避免 SSD 写放大;
◎ 在删除数据的时候更简单,直接删除分区即可;
◎ 在查询历史数据时,由于已经按照时间排序,所以可以将内存数据和此磁盘数据合并,通过懒加载的方式载入数据,而不需要将所有磁盘数据加载内存,避免发生 OOM。
如图 2-11 所示为 V3 版本的存储结构。其中 wal 目录记录的是监控数据的 WAL;每个 block 是一个目录,该目录下的 chunks 用来保存具体的监控数据,meta.json 用来记录元数据,index 则记录索引。具体内容会在有关存储的章节中详细介绍。
图 2-11
2.4.2 远程存储
为了提高对大量历史数据持久化存储的能力,Prometheus 在 1.6 版本后支持远程存储,Adapter 需要实现 Prometheus 的 read 接口和 write 接口,并且将 read 和 write 转化为每种数据库各自的协议,如图 2-12 所示。
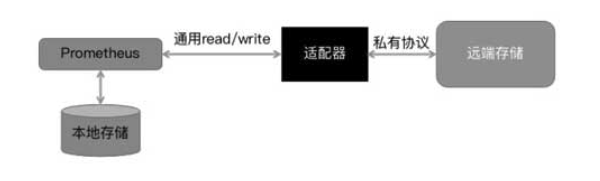
图 2-12
在用户查询数据时,Prometheus 会通过配置的查询接口发送 HTTP 请求,查询开始时间、结束时间及指标属性等,Adapter 会返回相应的时序数据;相应地,在用户写入数据时,HTTP 请求 Adapter 的消息体会包含时序数组(样本数据)。

若有收获,就点个赞吧
0 人点赞
