1、Pod概述
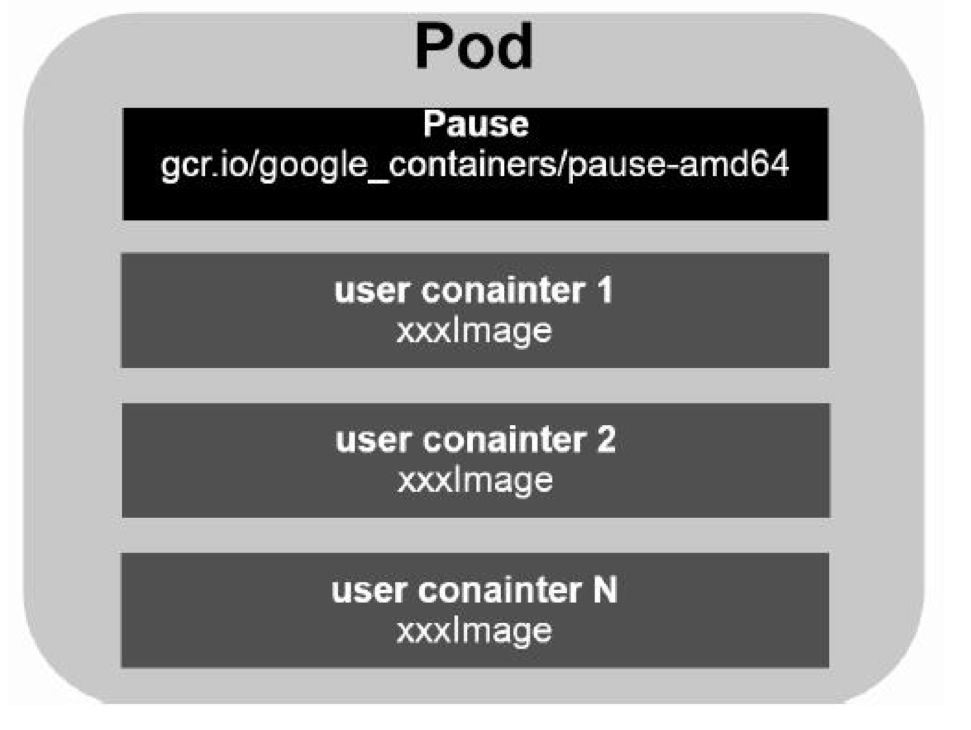
1.1 最小的部署单元
Pod 是 k8s 系统中可以创建和管理的最小单元,是资源对象模型中由用户创建或部署的最小资源对象模型,也是在 k8s 上运行容器化应用的资源对象,其他的资源对象都是用来支撑或者扩展 Pod 对象功能的,比如控制器对象是用来管控 Pod 对象的,Service 或者 Ingress 资源对象是用来暴露 Pod 引用对象的,PersistentVolume 资源对象是用来为 Pod 提供存储等等。
1.2 一组容器的集合
k8s 不会直接处理容器,而是处理Pod,Pod 是由一个或多个 container 组成。Pod是 Kubernetes 的最重要概念,每一个Pod 都有一个特殊的被称为”根容器“的 Pause 容器。Pause容器对应的镜像属于 Kubernetes 平台的一部分,除了 Pause 容器,每个 Pod 还包含一个或多个紧密相关的用户业务容器。
1.3 资源共享
一个 Pod 里的多个容器可以共享存储和网络,可以看作一个逻辑的主机。共享的如namespace,cgroups 或者其他的隔离资源。
1.3.1 共享网络空间
多个容器共享同一 network namespace,由此在一个 Pod 里的多个容器共享 Pod 的 IP 和端口 namespace,所以一个 Pod 内的多个容器之间可以通过 localhost 来进行通信,所需要注意的是不同容器要注意不要有端口冲突即可。不同的 Pod 有不同的 IP,不同 Pod 内的多个容器之前通信,不可以使用 IPC(如果没有特殊指定的话)通信,通常情况下使用 Pod的 IP 进行通信。
1.3.2 共享存储
一个 Pod 里的多个容器可以共享存储卷Volume,这个存储卷会被定义为 Pod 的一部分,并且可以挂载到该 Pod 里的所有容器的文件系统上。
1.4 生命周期短暂
Pod 属于生命周期比较短暂的组件,比如,当 Pod所在节点发生故障,那么该节点上的 Pod 会被调度到其他节点。但需要注意的是,被重新调度的 Pod 是一个全新的 Pod,跟之前的Pod 没有半毛钱关系。
1.5 平坦的网络
K8s 集群中的所有 Pod 都在同一个共享网络地址空间中,也就是说每个 Pod 都可以通过其他 Pod 的 IP 地址来实现访问。
2、Pod存在意义
- 为什么k8s不直接使用容器作为最小的计算单位?
原因在于容器的设计本身更适合一个容器内只运行一个进程,多个进程则需要手动实现管理孤儿进程的逻辑及健康状态。Pod作为一种更加高级的结构,它是多进程设计,可以运行多个应用程序,可以更好的适应当前的生产环境。
- Pod为亲密性应用而存在,主要场景有:
- 两个应用之间发生文件交互
- 两个应用需要通过127.0.0.1或socket通信
- 两个应用需要发生频繁的调用
3、Pod实现机制与设计模式
Pod本身是一个逻辑概念,没有具体存在,那究竟是怎么实现的呢?
容器之间是通过Namespace隔离的,Pod要想解决上述应用场景,那么就要让Pod里的容器之间高效共享。
具体分为两个部分:网络和存储
3.1 共享网络
kubernetes会在每个Pod里先创建一个Pause容器(infra container),然后让其他的容器连接进来这个网络命名空间,其他容器看到的网络视图就完全一样了,即网络设备、IP地址、Mac地址等,这就是解决网络共享问题。在Pod的IP地址就是infra container的IP地址。
3.2 共享存储
引入数据卷概念Volume,使用数据卷进行持久化存储。比如有两个容器,一个是nginx,另一个是普通的容器,普通容器要想访问nginx里的文件,就需要nginx容器将共享目录通过volume挂载出来,然后让普通容器挂载这个Volume,最后大家看到这个共享目录的内容一样。
# pod.yamlapiVersion: v1kind: Podmetadata:name: my-podspec:containers:- name: writeimage: centoscommand: ["bash","-c","for i in {1..100};do echo $i >> /data/hello;sleep 1;done"]volumeMounts:- name: datamountPath: /data- name: readimage: centoscommand: ["bash","-c","tail -f /data/hello"]volumeMounts:- name: datamountPath: /datavolumes:- name: dataemptyDir: {}
上述示例中有两个容器,write容器负责提供数据,read消费数据,通过数据卷Volume将写入数据的目录和读取数据的目录都放到了该卷中,这样每个容器都能看到该目录。
3.3 Pod中容器分类
- Infrastructure Container:基础容器,维护整个Pod网络空间,对用户不可见
- InitContainers:初始化容器,先于业务容器开始执行,一般用于业务容器的初始化工作
- Containers:业务容器,具体跑应用程序的镜像
4、Pod的分类
4.1 普通Pod
普通 Pod 一旦被创建,就会被放入到 etcd 中存储,随后会被 Kubernetes Master 调度到某个具体的 Node 上并进行绑定,随后该 Pod 对应的 Node 上的 kubelet 进程实例化成一组相关的 Docker 容器并启动起来。在默认情 况下,当 Pod 里某个容器停止时,Kubernetes 会自动检测到这个问题并且重新启动这个 Pod 里某所有容器, 如果 Pod 所在的 Node 宕机,则会将这个 Node 上的所有 Pod 重新调度到其它节点上。
4.2 静态Pod
静态 Pod 是由 kubelet 进行管理的仅存在于特定 Node 上的 Pod,它们不能通过 API Server进行管理,无法与 ReplicationController、Deployment 或 DaemonSet 进行关联,并且kubelet 也无法对它们进行健康检查。
5、Pod定义
apiVersion: v1 # 指定api版本,此值必须在kubectl apiversion中
kind: Pod # 指定创建资源的角色/类型
metadata: # 资源的元数据/属性
name: my-pod # 资源的名字,在同一个namespace中必须唯一
labels: # 设定资源的标签 http://blog.csdn.net/liyingke112/article/details/77482384
k8s-app: apache
version: v1
kubernetes.io/cluster-service: "true"
annotations: # 自定义注解列表
- name: String # 自定义注解名字
spec: # specification of the resource content 指定该资源的内容
restartPolicy: Always # 表明该容器一直运行默认k8s的策略,在此容器退出后,会立即创建一个相同的容器
nodeSelector: # 节点选择先给主机打标签kubectl label nodes kube-node01 zone=node1
env_role: dev
containers:
- name: web04-pod # 容器的名字
image: web:apache # 容器使用的镜像地址
imagePullPolicy: Never # 三个选择Always、Never、IfNotPresent,每次启动时检查和更新(从registery)images的策略,
# Always,每次都检查
# Never,每次都不检查(不管本地是否有)
# IfNotPresent,如果本地有就不检查,如果没有就拉取
command: ['sh'] # 启动容器的运行命令,将覆盖容器中的Entrypoint,对应Dockefile中的ENTRYPOINT
args: ["$(str)"] # 启动容器的命令参数,对应Dockerfile中CMD参数
env: # 指定容器中的环境变量
- name: str # 变量的名字
value: "/etc/run.sh" # 变量的值
resources: # 资源管理
requests: # 容器运行时,最低资源需求,也就是说最少需要多少资源容器才能正常运行
cpu: 0.1 # CPU资源(核数),两种方式,浮点数或者是整数+m,0.1=100m,最少值为0.001核(1m)
memory: 32Mi # 内存使用量
limits: # 资源限制
cpu: 0.5
memory: 32Mi
ports:
- containerPort: 80 # 容器开发对外的端口
name: httpd # 名称
protocol: TCP
livenessProbe: # pod内容器健康检查的设置 http://blog.csdn.net/liyingke112/article/details/77531584
httpGet: # 通过httpget检查健康,返回200-399之间,则认为容器正常
path: / # URI地址
port: 80
#host: 127.0.0.1 #主机地址
scheme: HTTP
initialDelaySeconds: 180 # 表明第一次检测在容器启动后多长时间后开始
timeoutSeconds: 5 # 检测的超时时间
periodSeconds: 15 # 检查间隔时间
# 方法2
#exec: 执行命令的方法进行监测,如果其退出码为0,则认为容器正常
# command:
# - cat
# - /tmp/health
# 方法3
#tcpSocket: # 通过tcpSocket检查健康
# port: number
lifecycle: # 生命周期管理
postStart: # 容器运行之前运行的任务
exec:
command:
- 'sh'
- 'yum upgrade -y'
preStop: # 容器关闭之前运行的任务
exec:
command: ['service httpd stop']
volumeMounts: # 数据卷 http://blog.csdn.net/liyingke112/article/details/76577520
- name: volume # 挂载设备的名字,与volumes[*].name 需要对应
mountPath: /data # 挂载到容器的某个路径下
readOnly: True
volumes: # 定义一组挂载设备
- name: volume # 定义一个挂载设备的名字
#meptyDir: {}
hostPath:
path: /opt # 挂载设备类型为hostPath,路径为宿主机下的/opt,这里设备类型支持很多种
6、Pod镜像拉取策略
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: java
image: 1065/java-demo
imagePullPolicy: IfNotPresent
imagePullPolicy 字段有三个可选值:
- IfNotPresent:镜像在宿主机上不存在时才拉取
- Always:默认值,每次创建 Pod 都会重新拉取一次镜像
- Never: Pod 永远不会主动拉取这个镜像
如果拉取公开的镜像,直接按照上述示例即可,但要拉取私有的镜像,是必须认证镜像仓库才可以,即docker login,而在K8S集群中会有多个Node,显然这种方式是很不放方便的!为了解决这个问题,K8s 实现了自动拉取镜像的功能。 以secret方式保存到K8S中,然后传给kubelet。
7、Pod资源限制
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: java
image: 1065/java-demo
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
- 申请配额:调度时使用,是否有节点满足该配置
- spec.containers[].resources.requests.cpu
- spec.containers[].resources.requests.memory
- 限制配额:容器能使用的最大配置
- spec.containers[].resources.limits.cpu
- spec.containers[].resources.limits.memory
其中cpu值可以这么理解:1核=1000m 0.5核=500m
8、Pod生命周期和重启策略
8.1 Pod状态
| 状态值 | 描述 |
|---|---|
| Pending | API Server已经创建了该Pod,但Pod中的一个或多个容器的镜像还没有创建,包括镜像的下载过程 |
| Running | Pod内所有容器已创建,且至少一个容器处于运行状态、正在启动状态或正在重启状态 |
| Completed | Pod内所有容器均成功执行退出,且不会再重启 |
| Failed | Pod内所有容器均已退出,但至少一个容器退出失败 |
| Unknown | 由于某种原因无法获取Pod状态,例如网络通信不畅 |
8.2 Pod重启策略
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: java
image: 1065/java-demo
restartPolicy: Always
restartPolicy字段有三个可选值:
- Always:当容器终止退出后,总是重启容器,默认策略。
- OnFailure:当容器异常退出(退出状态码非0)时,才重启容器。适于job
- Never:当容器终止退出,从不重启容器。适于job
9、Pod健康检查
默认情况下,kubelet 根据容器状态作为健康依据,但不能判断容器中应用程序状态,例如程序假死。这就会导致无法提供服务,丢失流量。因此引入健康检查机制确保容器健康存活。
9.1 健康检查类型
- livenessProbe:如果检查失败,将杀死容器,根据Pod的restartPolicy来操作
- readinessProbe:如果检查失败,Kubernetes会把Pod从service endpoints中剔除
9.2 健康检查方法
- httpGet:通过发送http请求检查服务是否正常,返回200-399状态码则表明容器健康
- exec:通过执行命令来检查服务是否正常,回值为0则表示容器健康
- tcpSocket:通过容器的IP和Port执行TCP检查,如果能够建立TCP连接,则表明容器健康
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 60
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
上述示例:启动容器第一件事创建文件,停止30s,删除该文件,再停止60s,确保容器还在运行中。
验证现象:容器启动正常,30s后异常,会根据restartPolicy策略自动重建,容器继续正常,反复现象。
10、调度策略
10.1 创建Pod流程
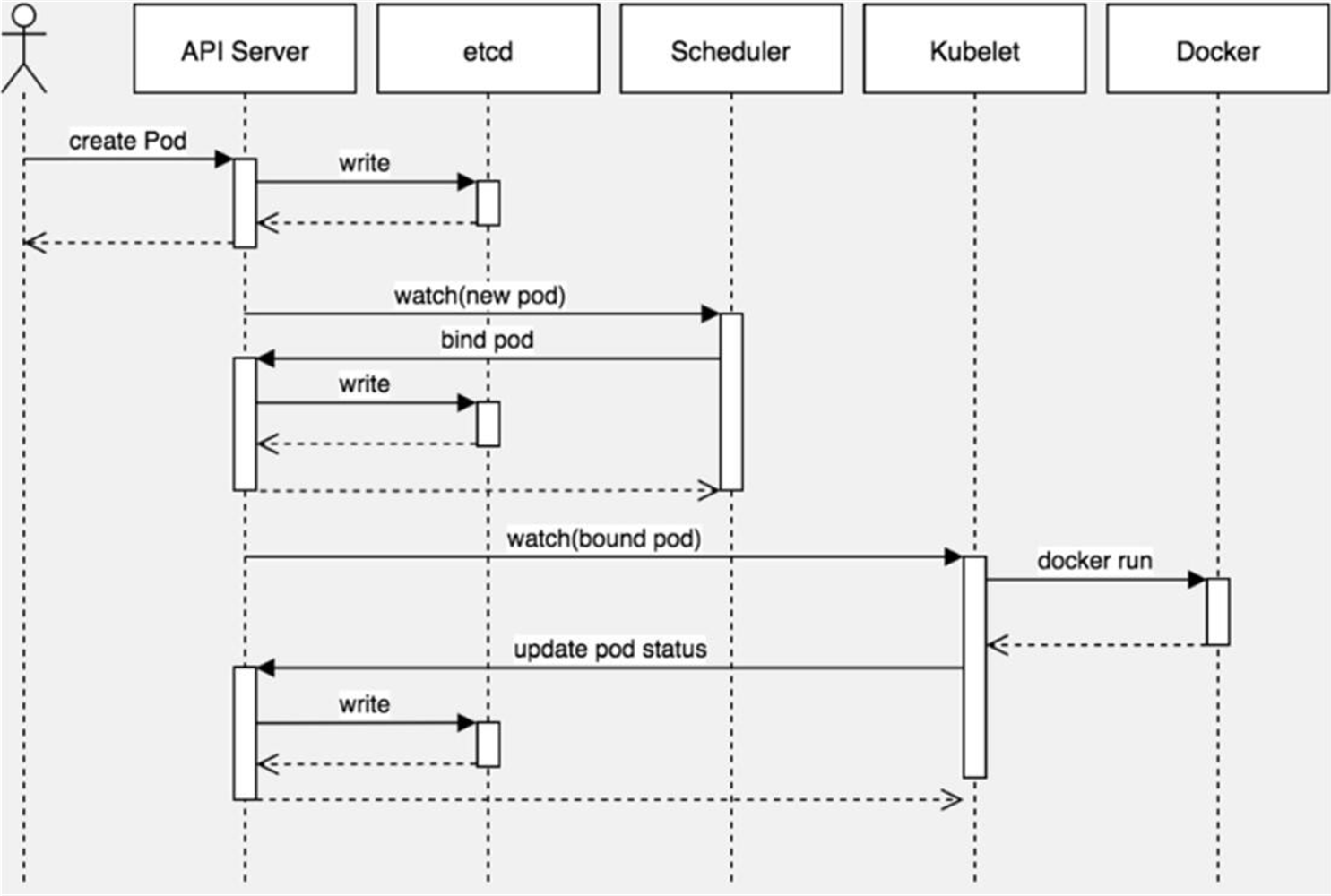
- 用户通过kubectl客户端提交Pod Spec给API Server
- API Server尝试将Pod对象的相关信息存储到etcd中,等待写入操作完成,API Server返回确认信息到客户端
- API Server开始反映etcd中的状态变化
- 所有的Kubernetes组件通过”watch”机制跟踪检查API Server上的相关信息变动
- kube-scheduler(调度器)通过其”watch”检测到API Server创建了新的Pod对象但是没有绑定到任何工作节点
- kube-scheduler为Pod对象挑选一个工作节点并将结果信息更新到API Server
- 调度结果新消息由API Server更新到etcd,并且API Server也开始反馈该Pod对象的调度结果
- Pod被调度到目标工作节点上的kubelet尝试在当前节点上调用docker engine进行启动容器,并将容器的状态结果返回到API Server
- API Server将Pod信息存储到etcd系统中
- 在etcd确认写入操作完成,API Server将确认信息发送到相关的kubelet
一个pod的完整创建,通常会伴随着各种事件的产生,kubernetes事件的种类总共只有4种:
- Added EventType = “ADDED”
- Modified EventType = “MODIFIED”
- Deleted EventType = “DELETED”
- Error EventType = “ERROR”
10.2 影响Pod调度-资源限制和节点选择器
10.2.1 资源限制
resources:
requests:
cpu: “0.1”
memory: “32Mi”
Pod资源限制对Pod调用产生影响,根据requests找到满足条件的node节点进行调度
10.2.2 节点选择器
nodeSelector用于将Pod调度到匹配Label的Node上。
先给规划node用途,然后打标签,例如将两台node划分给不同环境使用
- 对节点创建标签
# 查看所有节点
[root@k8s-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready master 2d2h v1.18.0
k8s-node01 Ready <none> 2d2h v1.18.0
k8s-node02 Ready <none> 2d2h v1.18.0
# 为k8s-node01节点打标签 key=value
[root@k8s-master ~]# kubectl label node k8s-node01 env_role=dev
node/k8s-node01 labeled
# 查看标签
[root@k8s-master ~]# kubectl get nodes k8s-node01 --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s-node01 Ready <none> 2d2h v1.18.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,env_role=dev,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node01,kubernetes.io/os=linux
- 通过nodeSelector选择符合条件的node
spec:
restartPolicy: Always
nodeSelector:
env_role: dev
10.3 影响Pod调度-节点亲和性
节点亲和性nodeAffinity和之前nodeSelector基本一样,根据节点上标签约束来决定Pod调度到哪些节点上。
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requireDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- key: env_role
operator: In
values:
- dev
- test
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: group
operator: In
values:
- otherprod
operator操作符有:
- In
- NotIn
- Exists
- Gt
- Lt
- DoesNotExists
10.3.1 硬亲和性
约束条件必须满足
requireDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- key: env_role
operator: In
values:
- dev
- test
10.3.2 软亲和性
约束条件尝试满足,但不保证
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: group
operator: In
values:
- otherprod
10.4 影响Pod调度-污点和污点容忍
10.4.1 污点基本介绍
nodeSelector和nodeAffinity:Pod调度到某些节点上,是Pod的属性,在调度时实现
Taint污点:节点不做普通分配调度,是节点属性
10.4.2 应用场景
- 专用节点:如针对特定用户分配的节点
- 配置特定硬件节点:做固态硬盘
- 基于Taint驱逐:污点值配置为NoExecute
10.4.3 操作
# 创建命令
kubectl taint node [node] key=value:[effect]
# 删除命令
kubectl taint node [node] key:[effect]-
# 查看节点污点情况
[root@k8s-master ~]# kubectl describe node k8s-node01 | grep Taint
# 创建Pod 名称为web image为nginx
[root@k8s-master ~]# kubectl create deployment web --image=nginx
# 创建多个Pod,查看Pod在节点分布情况(随机分配)
[root@k8s-master ~]# kubectl scale deployment web --replicas=5
[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-f89759699-7h9pr 1/1 Running 1 2d2h 10.244.2.3 k8s-node02 <none> <none>
web-5dcb957ccc-2v55h 1/1 Running 0 111s 10.244.1.6 k8s-node01 <none> <none>
web-5dcb957ccc-5mhh7 1/1 Running 0 59s 10.244.1.8 k8s-node01 <none> <none>
web-5dcb957ccc-l46bg 1/1 Running 0 59s 10.244.2.4 k8s-node02 <none> <none>
web-5dcb957ccc-ltpcq 1/1 Running 0 59s 10.244.1.7 k8s-node01 <none> <none>
web-5dcb957ccc-xwdhp 1/1 Running 0 59s 10.244.2.5 k8s-node02 <none> <none>
# 删除Pod
[root@k8s-master ~]# kubectl delete deployment web
deployment.apps "web" deleted
# 为节点添加污点
[root@k8s-master ~]# kubectl taint node k8s-node01 env_role=yes:NoSchedule
node/k8s-node01 tainted
# 查看节点污点情况
[root@k8s-master ~]# kubectl describe node k8s-node01 | grep Taint
Taints: env_role=yes:NoSchedule
# 创建多个Pod,查看Pod在节点分布情况(全部集中在k8s-node02)
[root@k8s-master ~]# kubectl create deployment web --image=nginx
deployment.apps/web created
[root@k8s-master ~]# kubectl scale deployment web --replicas=5
deployment.apps/web scaled
[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-5dcb957ccc-dfvhg 1/1 Running 0 80s 10.244.2.10 k8s-node02 <none> <none>
web-5dcb957ccc-fbccx 1/1 Running 0 80s 10.244.2.8 k8s-node02 <none> <none>
web-5dcb957ccc-hzxq8 1/1 Running 0 80s 10.244.2.7 k8s-node02 <none> <none>
web-5dcb957ccc-l7k95 1/1 Running 0 105s 10.244.2.6 k8s-node02 <none> <none>
web-5dcb957ccc-s8gbs 1/1 Running 0 80s 10.244.2.9 k8s-node02 <none> <none>
# 删除污点
[root@k8s-master ~]# kubectl taint node k8s-node01 env_role:NoSchedule-
node/k8s-node01 untainted
# 查看
[root@k8s-master ~]# kubectl describe node k8s-node01 | grep Taint
Taints: <none>
污点值effect有三个:
- NoSchedule :一定不能被调度
- PreferNoSchedule:尽量不要调度
- NoExecute:不仅不会调度,还会驱逐Node上已有的Pod
10.4 污点容忍
节点虽然加了污点,设置一定不被调度,可以通过以下配置使节点可能被调度到,达到一种软亲和的效果。
spec:
tolerations
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule "
key、value为设置的污点的key和value

若有收获,就点个赞吧
0 人点赞
