:::info
💡 根据 遗忘曲线:如果没有记录和回顾,6天后便会忘记75%的内容
读书笔记正是帮助你记录和回顾的工具,不必拘泥于形式,其核心是:记录、翻看、思考
:::
| 书名 | Mysql |
|---|---|
| 作者 | 程序员小曦 |
| 状态 | 已读完 已读完 已读完 |
| 简介 | mysql基础知识点 |
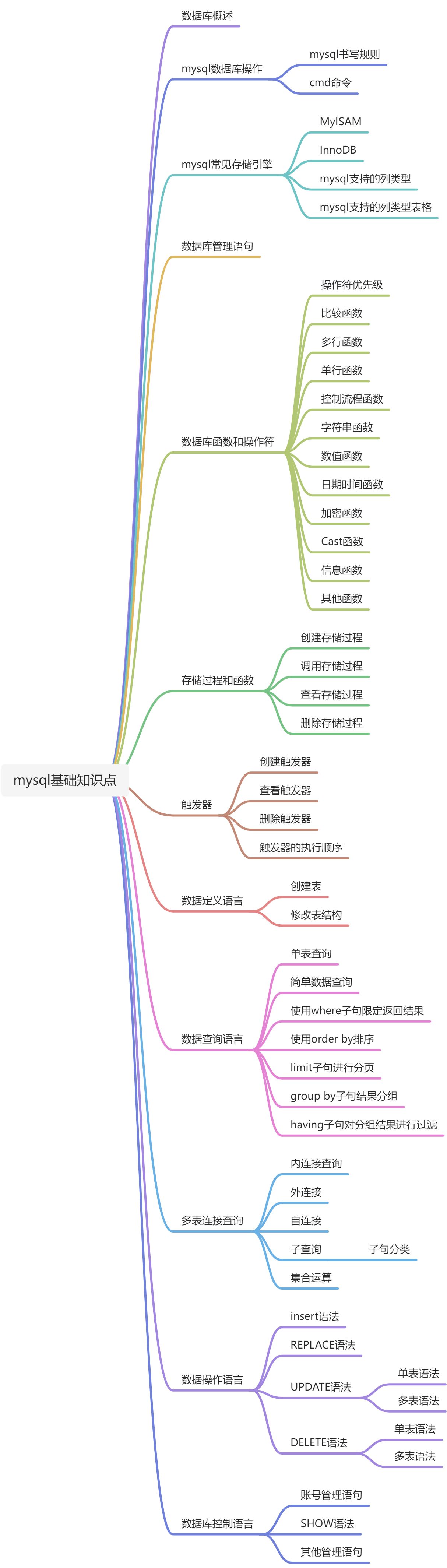
思维导图
用思维导图,结构化记录本书的核心观点。
1.数据库概述
1.1.数据库
- 按照数据结构来组织、存储和管理数据的仓库
- 数据库管理系统Database Management System(DBMS)
- 关系型数据库的三个范式(越高的范式数据库冗余越小)
- 第一范式(1NF):同一列中不能有多个值
- 第二范式(2NF):可以区分每一行的数据
- 第三范式(3NF):不包含其他表中已包含非主键信息
- SQL:结构化查询语言(Structured Query Lanuage),是操作和检索关系型数据库的标准语言
- 标准的SQL语言分类:
- 数据查询语言(DQL):从表中获得数据,关键字select
- 数据定义语言(DDL):创建、删除、修改数据库对象,关键字:create,alter,drop,truncat
- 数据操作语言(DML):添加、修改、删除表中的行,关键字:insert into,update,delete from
- 事务处理语言(TPL):确保被DML语句影响的表的所有的行得以及时的更新,关键字:commit,rollback,savepoint
- 数据控制语言(DCL):为数据库授权,或回收指定用户的权限,关键字:grant,revoke
- 指针控制语言(CCL):对一个或多个表单独行的操作
- 数据库对象:存储,管理,使用数据的不同结构形式
- 常见的数据库对象:表,索引,视图,函数,数据字典,约束,存储过程,触发器等
- 表具有固定的列数和任意的行数
二维表是同类实体的各种属性的集合,每个实体对应表中的一条数据,表中的列表示实体中的字段
2.MySql数据库操作
2.1.MySql书写规则
在Mysql中,SQL语句大小写不敏感
- SQL语句可单行也可写多行,以;或\g或\G作为每条命令的结束符
- 在SQL语句中,关键字不能跨多行或缩写
不能使用MySQL的关键字作为标识符,除非使用(``)引起了
2.2.cmd命令
启动服务:net start MYSQL
- 停止服务:net stop MYSQL
- 连接MySQL:mysql -u 用户名 -p 密码 -h 主机名 -P 端口
- 示例
- mysql -uroot -proot -h127.0.0.1 -P3306
- 示例
如果连接的是本地mysql服务,可简写为:mysql -uroot -proot
- 导出SQL脚本:mysqldump -u账号 -p密码 数据库名称 > 脚本文件存放地址
- 示例
- mysqldump -uroot -proot mysqldemo > F:/student.sql
- 示例
需要注意的是:对于全部是InnoDB引擎的库,建议使用mysqldump备份数据库时添加参数:single-transcation(在导出数据前会启动一个事务,来确保拿到一致性视图,由于MVCC(Multi-Version Concurrency Control 多版本并发控制)的支持,这个过程中数据可以正常更新)
- 导入SQL脚本:mysql -u账号 -p密码 数据库名称 < 脚本文件地址
- 示例
- mysql -uroot -proot mysqldemo > F:/student.sql
- 示例
MySql数据库自带的4个数据库不能被修改分别是:information_schema,mysql,performance_schema,sys
3.MySQL常见存储引擎
3.1.MyISAM
拥有较高的插入,查询速度,但不支持事务,不支持外键,不支持行级锁
3.2.InnoDB
支持事务,支持外键,支持行级锁,支持热备份,比MyISAM处理效率差,且会占用更多的磁盘空间以保留数据和索引
3.3.MySql支持的列类型
MySql记录行长度最大为64K(The maximum row size for the used table type, not counting BLOBs, is 65535)
- 整数类型(可分为有符号和无符号两种):tinyint,int或integer,bigint(可指定位宽)
- 浮点数类型(可分为有符号和无符号两种):float(p),float(M,D),double(M,D),decimal(M,D)
定点数类型(可分为有符号和无符号两种):decimal(M,D)
p表示精度(以位数表示)M表示该值得总位数(精度),D表示小数点后面的位数(标度)float和double在不指定精度时,默认会按照实际的精度来表示decimal在不指定精度时,默认整数为10,小数位0
字符类型:字符使用单引号引起来):char(字符数)、varchar(字符数) 、text 系列类型、json(使用json 列->’$.键’或json_extract(json 列 , ‘$.键’))(str 的字符个数:char_length(str))
- 日期时间类型:(允许“不严格”语法:任何标点符都可以用做日期部分或时间部分之间的间割符,或者没有间割符)date (值使用单引号括起来,检索和显示格式为 ‘YYYY-MM-DD’,如 ‘2017-01-01’)datetime (值使用引号括起来,检索和显示格式为 ‘YYYY-MM-DD HH:MM:SS’) ```sql current_timestamp:当要向表执行插入操作时,如果有个 timestamp 或 datetime 类型的字段的默认值为 current_timestamp,则无论这个字段有没有 set 值都插入当前系统时间
on update current_timestamp:使用 on update current_timestamp 放在 timestamp 或 datetime 类型的字段后面,在数据发生更新时该字段将自动更新时间
- 二进制类型:bit (一般用来存储 0 或 1,Java 中的 boolean/Boolean 类型的值)(可指定**位宽**)<a name="JAj2E"></a>## 3.4.MySQL支持的列类型| 列类型 | 说明 || --- | --- || tinyint/smallint/mediumint/int(integer)/bigint | 1字节/2字节/3字节/4字节/8字节整数,<br />又可分为有符号和无符号两种。整数类型的区别仅仅是表示数的范围不同 || float/double | 单精度,双精度浮点类型 || date | 精确小数类型,相对于float和double不会产生精度丢失问题(具体使用需根据业务选择) || time | 日期类型,不能保存时间,若把java.util,Date对象保存经date列时,时间部分将会丢失 || datetime | 时间类型,不能保存日期,若把java.util,Date对象保存经time列时,日期部分将会丢失 || timestamp | 日期,时间类型 || year | 时间戳类型 || char | 年类型,仅保存时间年份 || varchar | 定长字符串类型 || binary | 可变长度字符串类型 || varbinary | 定长二进制字符串类型,以二进制形式保存字符串 || tinyblob/blob/mediumblob/longblob | 可变长度的二进制字符串类型,以二进制形式保存字符串 || tinytext/text/mediumtext/longtext | 1字节/2字节/3字节/4字节的二进制大对象,可用于存储图片,音乐二进制数据,分别可存储:255B/64KB/16MB/4GB的大小 || enum('v1','v2','v3'...) | 枚举类型,该列的值只能是enum后括号里多个值中的一个 || set('v1','v2'...) | 集合类型,该列的值可以是set后括号里多个值得其中几个 |<a name="C5dfJ"></a># 4.数据库管理语句- 查看数据库服务器的所有数据库```sqlshow databases;
- 进入指定的数据库:use 数据库名;
- 创建指定名称的数据库:
- create table [if not exists] 数据库名[default chatset utf8mb4] [default collate utf8mb4_general_ci];
- 更改数据库的默认字符集:
- alter database 数据库名 default character set utf8mb4 default collate utf8mb4_general_ci;
- 删除数据库
- drop database 数据库名;
- 查看当前所有连接:
- +
- / div % mod
^
-(一元减号) ~(一元比特反转)
!
binary collate
```
5.2.比较函数
```sql expr is null isnull(expr):判断expr是否为null,如果为null则返回1,否则返回0 expr is not null:检验一个值是否为null expr not between min and max expr between min and max:expr大于或等于min且expr小于或等于max,TRUE返回1,否则返回0 expr in (value….) expr not in (value…) coalesce(value,…):返回值为列表中的第一个非null值,在没有非null值得情况下返回值为null greatest(v1,v2…):当有2个或以上的参数时,返回值为最大参数,若任意一个自变量为null,则greatest()的返回值为null least(v1,v2…):当有2个或以上的参数时,返回值为最小的参数(假如任意一个自变量为 null,则 least() 的返回值为 null)
注意: null与任何值比较都为null
<a name="Gqd1I"></a>## 5.3.多行函数```sql多行函数(聚合函数、分组函数):对多行输入值(一组记录)整体计算,最后只会得到一个结果分组函数在计算时忽略列中的空值不能在 where 子句中使用分组函数expr 可以是变量、常量或数据列当某一列的值全是 NULL 时,count(col) 的返回结果为 0,但 sum(col) 的返回结果为 NULLcount(expr):统计某个列值不为 NULL 的数量,用 * 表示统计该表内的所有行数(包括为 NULL 的行),注意:在 Java 中必须使用 long 接收avg(expr):计算多行 expr 的平均值sum(expr):计算多行 expr 的总和,需注意 NPE 问题:ifnull(sum(col), 0)max(expr):计算多行 expr 的最大值min(expr):计算多行 expr 的最小值group_concat([distinct] expr [, expr …] [order by {unsigned_integer | col_name | expr} [asc | desc] [, col_name …]] [separator str_val]):用 str_val(默认“,”)连接一个组内的 expr 指定的非 null 值的字符串,可用 col_name 进行组内排序
5.4.单行函数
单行函数:对每行输入值单独计算,每行得到一个计算结果
5.5.控制流程函数
case value when compare-valus then result [when compare-value then result ...] [else result] end:返回compare-value匹配的结果值,如果没有匹配的结果值,则返回结果值为else后的结果,如果没有else部分,则返回值为nullase when condition then result [when condition then result …] [else result] end:返回第一种情况的真实结果,如果没有匹配的结果值,则返回结果为 else 后的结果,如果没有 else 部分,则返回值为 nullif[expr1, expr2, expr3):如果 expr1 为 true(expr1 不等于 0 且不等于 null),则返回值为 expr2,否则返回值为 expr3ifnull(expr1, expr2):如果 expr1 为 null,则返回 expr2,否则返回 expr1nullif(expr1, expr2):如果 erpr1 和 expr2 相等,则返回 null,否则返回 expr1isnull(expr1):判断 expr1 是否为 null,如果为 null 则返回 true,否则返回 false
5.6.字符串函数
lower(str):将 str 中的字母全部变为小写upper(str):将 str 中的字母全部变为大写concat(str1, str2, …):字符串连接(若有任何一个参数为 null,则返回值为 null)concat_ws(separator, str1, str2, …):第一个参数是其它参数的分隔符,用分隔符连接字符串,如果分隔符为 null,则结果为 null,函数会忽略任何分隔符参数后的 null 值repeat(str, count):重复的 str 字符串 count 次char_length(str):求 str 的字符个数length(str):求 str 的字节个数lpad(str, len, padstr):用 padstr 左填补 str 使其字符长度 len(若 str 的长度大于 len,则缩短 str 至 len 个字符)rpad(str, len, padstr):用 padstr 右填补 str 使其字符长度 len(若 str 的长度大于 len,则缩短 str 至 len 个字符)ltrim(str):删除 str 左边空格rtrim(str):删除 str 右边空格trim(str):删除 str 左右两边空格replace(str, from_str, to_str):将 str 中的 from_str 全部替换为 to_str(大小写敏感)left(str, len):返回从字符串 str 最左开始的长度为 len 的子字符串right(str, len):返回从字符串 str 最右开始的长度为 len 的子字符串substring(str, pos):从 str 返回一个子字符串,起始于位置 pos(若 pos 为负数,从 str 尾部开始计算),至 str 最后substring(str, pos, len):从 str 返回一个字符长度为 len 的子字符串,起始于位置 pos,同义词:mid(str, pos, len)find_in_set(str, strlist):strlist 是一个由一些被“,”符号分开的子链组成的字符串,假如字符串 str 在由 N 子链组成的字符串列表 strlist 中,则返回值的范围在 1 到 N 之间instr(str, substr):返回字符串 str 中子字符串 substr 的第一个出现位置locate(substr, str) , locate(substr, str, pos):返回字符串 str 中子字符串 substr 的第一个出现位置,可指定起始位置在 pos
5.7.数值函数
abs(x):求 x 的绝对值mod(n, m):求 n 除以 m 的余数ceil(x):求大于 x 的最小整数(向上取整)floor(x):求小于 x 的最大整数(向下取整)round(x) :用四舍五入对 x 取整round(x, d):用四舍五入对 x 值保留到小数点后 d 位;若 d 为负数,表示对 x 的整数部位truncate(x, d):截去 x 值第 d 位小数后的数字;若 d 为负数,截去(归零)小数点左起第 d 位开始后面所有低位的值rand()、rand(n):返回一个随机浮点值,其范围为 0 ≤ v ≤ 1.0,若已指定一个整数参数 n,则它被用作种子值,用来产生重复序列;若要在 i ≤ r ≤ j 范围得到一个随机整数 r,需要用到表达式 floor(i + rand() (j – i + 1)) 或 round(i + rand() (j – i))-- 随机选取一条记录select * from 'A' ajoin (select round(rand() * (select max(id) from 'B' b)))as where a.id >= b.idorder by a.id = b.id asc limit 1;
5.8.日期时间函数
now():返回当前系统日期及时间curdate()、current_date():返回当前系统日期curtime()、current_time():返回当前系统时间adddate(date, interval expr type)、date_add(date, interval expr type):将 date 值添加指定的时间间隔值subdate(date, interval expr type)、date_sub(date, interval expr type):将 date 值减去指定的时间间隔值(说明:expr 是一个字符串表达式,用来指定从起始日期添加或减去的时间间隔值;type 为关键词,它指示了表达式被解释的方式,常见 type 值:year、quarters、month、week、day、hour、minute、second)datediff(expr1, expr2):求 expr1 减去 expr2 得到的天数period_add(p, n):将 n 个月添加到时段 p(格式为 YYMM 或 YYYYMM)上,返回值格式为 YYYYMMperiod_diff(p1, p2):返回时段 P1 和 P2 之间的月份差值,P1 和 P2 的格式应为 YYMM 或 YYYYMM获取日期时间中某个段date(expr) :提取日期或时间日期表达式 expr 中的日期部分year(date):返回 date 对应的年份,范围是从1000 到9999quarter(date):返回 date 所对应的年中某季度,取值范围为 1 到 4month(date):返回 date 对应的月份,范围时从 1 到 12week(date[, mode]):返回 date 所对应的星期序号yearweek(date[, mode]):返回 date 的年份及星期序号(mode 参数可以指定每星期起始日究竟是星期天还是星期一,以及返回值范围究竟是 0-53,还是从 1-53,如果忽略 mode 参数,就采用 default_week_format 系统变量值,默认为 0,即第一天是周日,返回值范围 0-53)day(date)、dayofmonth(date):返回 date 参数所对应的一月中的第几天dayofweek(date):返回 date 参数所对应的一年中的某一天,取值范围从 1 到 366hour(time):返回 time 对应的小时数,范围是从 0 到 23minute(time):返回 time 对应的分钟数,范围是从 0 到 59last_day(date):返回该月最后一天对应的日期值unix_timestamp(date):date 值距离 '1970-01-01 00:00:00' gmt 的秒数from_unixtime(unix_timestamp) :返回 'yyyy-mm-dd hh:mm:ss' 格式的日期from_unixtime(unix_timestamp, format):返回指定 format 的日期,如 '%Y-%m-%d %H:%i:%s'date_format(date, format):把日期转换为指定 format 格式的字符串,如 '%Y-%m-%d %T'str_to_date(str, format):把字符串按 format 格式转换为日期,如 '%Y-%m-%d %H:%i:%s'to_days(date):给定一个日期 date,返回一个天数(从年份 0 开始的天数)from_days(n):给定某日 n,返回一个 date 值
示例:
-- 今天select * from 表名 where to_days(时间字段名) = to_days(curdate());-- 昨天select * from 表名 where to_days(时间字段名) = to_days(curdate()) - 1;-- 近 7 天select * from 表名 where to_days(时间字段名) > to_days(curdate()) - 7;select * from 表名 where date(时间字段名) > date_sub(curdate(), interval 7 day);-- 本周select * from 表名 where yearweek(时间字段名) = yearweek(curdate());-- 上周select * from 表名 where yearweek(时间字段名) = yearweek(curdate()) - 1;-- 本月select * from 表名 where date_format(时间字段名, '%y%m') = date_format(curdate(), '%y-%m');-- 上个月select * from 表名 where date_format(时间字段名, '%y%m') = date_format(date_sub(curdate(), interval 1 month), '%y%m');select * from 表名 where period_diff(date_format(curdate(), '%y%m'), date_format(时间字段名, '%y%m')) = 1;-- 本季度select * from 表名 where quarter(时间字段名) = quarter(curdate());-- 上季度select * from 表名 where quarter(时间字段名) = quarter(date_sub(curdate(), interval 1 quarter));-- 本年select * from 表名 where year(时间字段名) = year(curdate());-- 上年select * from 表名 where year(时间字段名) = year(date_sub(curdate(), interval 1 year));
5.9.加密函数
aes_encrypt(str, key_str)aes_decrypt(crypt_str, key_str)采用的是对称加密算法 ASE128注意:加密后的二进制数据应使用 blob 类型存储
5.10.Cast函数
cast(expr as type)、convert(expr, type)、convert(expr using transcoding_name)可用来获取一个类型的值,并产生另一个类型的值type 可以是以下值其中的一个:binary[(n)]、char[(n)]、date、datetime、decimal、signed [integer]、time、unsigned [integer]如:convert('abc' using utf8mb4):将服务器的默认字符集中的字符串 'abc' 转化为 utf8 字符集中相应的字符串
5.11.信息函数
database()、schema():当前数据库名user():当前 MySQL 用户名和机主名version():MySQL 服务器版本
5.12.其他函数
format(x, d):将数字 x 的格式写为 '#,###,###.##' 形式的字符串,以四舍五入的方式保留小数点后 d 位inet_aton(expr):将一个作为字符串的网络地址(如 '127.0.0.1')转换为一个代表该地址数值的整数(2130706433),使用 int unsigned 列存储(Java 中须使用 long 接收)inet_ntoa(expr):将一个数字网络地址(4 或 8 比特)转换为一个作为字符串的网络地址sleep(duration):睡眠(暂停)时间为 duration 参数给定的秒数,然后返回 0,若 SLEEP() 被中断,返回 1uuid():返回一个通用唯一标识符(UUID)
6.存储过程和函数
- 存储过程和函数是经过预先编译并存储在数据库中的一些SQL语句的集合
- 存储过程和函数可以避免开发人员重复的编写相同的SQL语句
- 存储过程和函数是在MySQL服务器存储和执行的,可以减少客户端和服务端的数据传输
6.1.创建存储过程和函数
```sql CREATE PROCEDURE sp_name([[IN | OUT | INOUT] param_name type[,…]]) [characteristic …] routine_body
CREATE FUNCTION sp_name ([param_name type [,…]]) RETURNS type [characteristic …] routine_body
说明:- sp_name:存储过程或函数的名称- proc_paramter:存储过程的参数列表,proc_parameter 中的每个参数由 3 部分组成:输入输出类型、参数名称、参数类型。其中,IN 表示输入参数;OUT 表示输出参数;INOUT 表示既可以是输入,也可以是输出;param_name 参数是存储过程的参数名称;type 参数指定存储过程的参数类型,该类型可以是 MySQL 数据库的任意数据类型- func_parameter:存储函数的参数列表- RETURNS type:指定返回值的类型- characteristic:指定存储过程的特性,其取值如下:LANGUAGE SQL、[NOT] DETERMINISTIC、{ CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }、SQL SECURITY { DEFINER | INVOKER }、COMMENT 'string'- routine_body:SQL 代码的内容,可以用 BEGIN…END 来标志 SQL 代码的开始和结束```sql-- 存储过程名称为 num_from_employee,输入变量为 emp_id,输出变量为 count_num-- select 语句从 employee 表查询 d_id 值等于 emp_id 的记录,并用 count(*) 计算 d_id 值相同的记录的条数,最后将计算结果存入 count_num 中delimiter $create procedure num_from_employee (in emp_id int, out count_num int)reads sql databeginselect count(*) into count_numfrom employeewhere d_id=emp_id ;end$delimiter ;-- 存储函数的名称为 name_from_employee,参数为 emp_id,返回值是 varchar 类型- select 语句从 employee 表查询 num 值等于 emp_id 的记录,并将该记录的 name 字段的值返回delimiter $create function name_from_employee (emp_id int)returns varchar(20)beginreturn (select namefrom employeewhere num=emp_id);end$delimiter ;
- 变量
- 定义变量:DECLARE var_name[, …] type [DEFAULT value](没有使用 DEFAULT 子句时,默认值为 NULL)
- 为变量赋值:SET var_name = expr [, var_name = expr]
流程控制
-- IF 语句IF search_condition THEN statement_list[ELSEIF search_condition THEN statement_list] ...[ELSE statement_list]END IF-- CASE 语句CASE case_valueWHEN when_value THEN statement_list[WHEN when_value THEN statement_list] ...[ELSE statement_list]END CASECASEWHEN search_condition THEN statement_list[WHEN search_condition THEN statement_list] ...[ELSE statement_list]END CASE-- WHILE 语句WHILE search_condition DOstatement_listEND WHILE
6.2.调用存储过程和函数
调用存储过程:CALL sp_name([parameter[, …]]) ;
调用存储函数:存储函数的使用方法与 MySQL 内部函数的使用方法相同
6.3.查看存储过程和函数
查看存储过程和函数的状态:SHOW { PROCEDURE | FUNCTION } STATUS [ LIKE ‘pattern’ ]
查看存储过程和函数的定义:SHOW CREATE { PROCEDURE | FUNCTION } sp_name
6.4.删除存储过程和函数
DROP { PROCEDURE| FUNCTION } sp_name
7.触发器
触发器是与表有关联的数据库对象,在满足定义条件时触发,并执行触发器中定义的语句集合
7.1.创建触发器
CREATE TRIGGER trigger_nametrigger_timetrigger_event ON tb1_nameFOR EACH ROWtrigger_stmt
trigger_name:标识触发器名称,用户自行指定
- trigger_time:标识触发时机,取值为 BEFORE 或 AFTER
- trigger_event:标识触发事件,取值为 INSERT、UPDATE 或 DELETE
- INSERT:插入某一行时激活触发器,可能通过 INSERT、LOAD DATA、REPLACE 语句触发
- UPDATE:更改某一行时激活触发器,可能通过 UPDATE 语句触发
- DELETE:删除某一行时激活触发器,可能通过 DELETE 或 REPLACE 语句触发
- tb1_name:标识建立触发器的表名,即在哪张表上建立触发器
- trigger_stmt:触发器程序体,可以是一句 SQL 语句,或者用 BEGIN 和 END 包含的多条语句
- BEGIN [statement_list] END,其中 statement_list 代表一个或多个语句的列表,列表内的每条语句都必须用分号(;)来结尾,在 MySQL 中分号是语句结束的标识符,因此需用DELIMITER new_delemiter设置新的分隔符
- MySQL 中定义了 NEW 和 OLD,用来表示触发器的所在表中触发了触发器的那一行数据
- 在 INSERT 型触发器中,NEW 用来表示将要(BEFORE)或已经(AFTER)插入的新数据
- 在 UPDATE 型触发器中,OLD 用来表示将要或已经被修改的原数据,NEW 用来表示将要或已经修改为的新数据
- 在 DELETE 型触发器中,OLD 用来表示将要或已经被删除的原数据
- 使用方法:NEW.columnName(columnName 为相应数据表某一列名)
- OLD 是只读的,而 NEW 则可以在触发器中使用 SET 赋值,此时不会再次触发触发器
- 一个表上最多建立可以建立 6 种触发器,即:BEFORE INSERT、BEFORE UPDATE、BEFORE DELETE、AFTER INSERT、AFTER UPDATE、AFTER DELETE
示例:
-- 创建触发器来使班级表中的班内学生数随着学生的添加自动更新delimiter $create trigger ins_stu after inserton student for each rowbegindeclare c int;set c = (select stu_count from class where class_id = new.class_id);update class set stu_count = c + 1 where class_id = new.class_id;end$delimiter ;
7.2.查看触发器
SHOW TRIGGERS [FROM database_name];
7.3.删除触发器
DROP TRIGGER [IF EXISTS] [database_name.]trigger_name
7.4.触发器的执行顺序
- 对于InnoDB的表,若SQL语句或触发器执行失败,mysql会回滚事务,即:
— 复制表结构(不包括外键约束) create table student_bak like student;
— 只复制数据到新表 create table student_bak select * from student;
<a name="mmtX7"></a>## 8.2.修改表结构```sql-- 增加列定义alter table 表名 add (新列名 列类型 [默认值],...);-- 修改列定义alter table 表名modify 列名 列类型 [默认值];-- 删除列alter table 表名drop 列名;
- 看当前数据库中存在哪些表:show tables;
- 查看表结构:desc 表名;
- 查看表的详细定义(定义表的 SQL 语句):show create table 表名;
- 删除表:drop table 表名;
- 截断表(删除表里的全部数据,但保留表结构):truncate 表名;
- 修改表的存储引擎:alter table 表名 ENGINE=’InnoDB’;
表的约束(列级约束),关键字之间不用加逗号
- default ‘值’:默认值
- not null:非空约束,该列的内容不能为空
- unique:唯一约束,在该表中,该列的内容必须唯一,但可以出现多个 null 值
- primary key:主键约束,相当于非空约束和唯一约束
- auto_increment[=值]:自增长,只能用于指定整型主键列,默认从 1 开始,步长为 1,向该表插入记录时可不为该列指定值,或指定为 null 或 0(可以通过设置 sql_mode = ‘NO_AUTO_VALUE_ON_ZERO’ 将自增值设置为 0)(只能有一个自增列,且必须被定义为主键)
- foreign key (外键列) references 主表 (参考列):外键约束从表外键列的值必须在主表被参照列的值范围之内,或者为 null,要求从表和主表的存储引擎都为 InnoDB
9.数据查询语言(DQL)
DQL操作会返回一个结果集
注意:
- 字符串和字符串之间的日期要用单引号扩起来
- 数字类型直接书写
- 字符串是大小写敏感的,可在需要区分大小写的字符串前添加binary关键字
- 日期值是格式敏感的
9.1.单表查询
(8)select (9)distinct select_list -- 确定选择的列(1)from left_table -- 确定查询哪一张表(3)join_tpye join right_table(2)on join_condition(4)where where_condition -- 确定选择的行(不能使用 select 中定义的别名)(5)group by group_by_list -- 对结果集分组(MySQL 中对查询做了加强,可以使用 select 中定义的别名)(6)with cube|rollup(7)having having_condition -- 对分组过滤(10)order by order_by_list -- 对结果集按照某列排序(11)limit start_number, limit_number -- 对结果集分页
SQL 的执行顺序
- form:对 from 的左边的表和右边的表计算笛卡尔积,产生虚表 VT1
- on:对虚表 VT1 进行 on 筛选,只有那些符合 join_condition 的行才会被记录在虚表 VT2 中
- join:如果指定了 outer join(比如 left join、right join),那么保留表中未匹配的行就会作为外部行添加到虚拟表 VT2 中,产生虚拟表 VT3;如果 from 子句中包含两个以上的表的话,那么就会对上一个 join 连接产生的结果 VT3 和下一个表重复执行步骤 1~3 这三个步骤,一直到处理完所有的表为止
- where:对虚拟表 VT3 进行 where 条件过滤,只有符合 where_condition 的记录才会被插入到虚拟表 VT4 中
- group by:根据 group by 子句中的列,对 VT4 中的记录进行分组操作,产生 VT5
- cube | rollup:对表 VT5 进行 cube 或者 rollup 操作,产生表 VT6
- having:对虚拟表 VT6 应用 having 过滤,只有符合 having_condition 的记录才会被 插入到虚拟表 VT7 中
- select:执行 select 操作,选择指定的列,插入到虚拟表 VT8 中
- distinct:对 VT8 中的记录进行去重,产生虚拟表 VT9
- order by:将虚拟表 VT9 中的记录按照 order_by_list 进行排序操作,产生虚拟表 VT10
- limit:取出指定行的记录,产生虚拟表 VT11,并将结果返回
9.2.简单数据查询
select {*, 列 [[as] 别名], ...}from 表名;-- 如果列别名中使用关键字,或强制区分大小写,或有空格时,需使用 "" 或 '' 括起来-- 使用 distinct 关键字从査询结果中清除重复行,必须放在要查询字段的开头select distinct 列名, ...from 表名;-- 实现数学运算查询-- 对数值型数据列可以使用算算术运算符(+ - * /)创建表达式-- 两个日期之间可以进行减法运算,日期和数值之间可以进行加、减运算-- 包括空值的任何算术表达式都等于空
9.3.使用where子句限定返回的记录
select <selectList>from 表名where 条件表达式;-- 优先级:所有的比较运算符、not(!)、and(&&)、or(||)-- 可以使用 >、>=、<、<=、= 和 <> 等基本的比较运算符比较数值、字符串、日期之间的大小-- SQL 中判断两个值是否相等的比较运算符是单等号,判断不相等的运算符是 <> 或 !=,SQL 中的赋值运算符是冒号等号(:=)-- 特殊的比较运算符:between、in、is null、like-- between 比较运算符,选出某一值域范围(闭区间)的记录where 列名 between val1 and val2;-- in 比较运算符,判断列的值是否在指定的集合中where 列名 in (值1, 值2, ...);-- is null 比较运算符、is not null 比较运算符,判断列的值是否为空where 列名 is null;-- like 比较运算符,执行通配查询/模糊查询-- % 表示零或多个任意的字符-- _ 表示一个任意的字符where 列名 like '_%';
9.4.使用order by子句将结果集进行排序
asc:升序,缺省;desc:降序
- 注意:当 order by 子句中有使用了带引号的别名时,无法排序
如果数据量小则在内存中进行,如果数据量大则需要使用磁盘
select <selectList>from table_name-- order by field(列名, val1, val2, val3) [asc|desc]:将获取出来的数据根据指定的顺序排序,即该列的其它值(视为相等) < val1 < val2 < val3,其中列名后面的参数自定义,不限制参数个数order by 列1 [asc|desc], 列2 [asc|desc], field(列3, 值1, 值2, 值3, ...) [asc|desc], ...;
9.5.使用limit子句进行分页查询
limit {[offset,] row_count] 或 limit row_count OFFSET offset}
- 使用两个自变量时,offset 指定返回的第一行的偏移量(初始行的偏移量为 0),row_count 指定返回的行数的最大值
使用一个自变量时,row_count 指定从结果集合的开头返回的行数,即 limit n 与 limit 0, n 等价
-- MySQL 特有-- limit 子句中不能进行数学运算-- beginIndex:从结果集中的哪一条索引开始显示(beginIndex 从 0 开始)-- beginIndex = (当前页数 - 1) * pageSize-- pageSize:页面大小(每页最多显示多少条记录)select <selectList>from 表名[where condition]limit beginIndex, pageSize;
9.6.使用group by 子句对结果集进行显示分组
将查询结果按某个字段或多个字段进行分组
- 分组后的结果集隐式按升序排列
- with rollup 关键字将会在所有记录的最后加上一条记录,该记录是上面所有记录的总和
如果查询列表中使用了聚合函数,或者 select 语句中使用了 group by 子句,则要求出现在 select 列表中的字段,要么使用聚合函数或 group_concat() 包起来,要么必须出现在 group by 子句中
9.7.使用having子句对分组进行过滤
select [distinct] *|分组字段1[, 分组字段2, …] | 统计函数from 表名[where 条件]group by 分组字段1[, 分组字段2, …] [with cube|rollup][having 过滤条件(可以使用统计函数)]
10.多表连接查询
如果表有别名,则不能在使用表的真名
MySQL执行关联查询的过程:MySQL现在一个表中循环取出多个数据,然后再嵌套循环到下一个表中去选择匹配的行,依次下去,直到找到所有表中匹配的行为为止。然后根据各个表匹配的行,返回查询中需要的各个列(嵌套循环关联)
10.1.内连接查询
-- 1. 隐式内连接:使用 where 指定连接条件,如等值连接(如果没有连接条件,会得到笛卡尔积)select <selectList>from A, Bwhere 连接条件;-- 2. 显式内连接查询select <selectList>from A [inner] join B on 连接条件;-- 在做等值连接的时候,若 A 表中和 B 表中的列名相同,则可以简写:select <selectList>from A [inner] join B using(同名列);
10.2.外连接
左外连接(left [outer] join):查询出 join 左边表的全部数据,右边的表不能匹配的数据使用 null 来填充数据
- 右外连接(right [outer] join):查询出 join 右边表的全部数据,左边的表不能匹配的数据使用 null 来填充数据
全外连接(full [outer] join):MySQL 不支持,可以通过 union + 左右连接查询来完成
select <selectList>from A left|right [outer] join B on 连接条件;
10.3.自连接
如果同一个表中的不同记录之间存在主、外键约束关联,则需要使用自连接查询
-
10.4.子查询
子查询必须要位于圆括号中
标量子查询:子查询返回的结果是一个数据(一行一列),当成一个标量值使用,可以使用单行记录比较运算符
列子查询:返回的结果是一列(一列多行),当成一个值列表,需要使用 in、any 和 all 等关键字,any 和 all 可以与 >、>=、<、<=、<>、= 等运算符结合使用 in:与列表中的任意一个值相等 any:与列表中的任意一个值比较,=any、>any、all、
10.5.集合运算
对两个 select 查询得到的结果集进行交(intersect)、并(union)和差(minus)运算
- 须满足:两个结果集所包含的数据列的数量必须相等,且数据列的数据类型也必须兼容
MySQL 不支持 intersect、minus 运算
-- union/union all 用于把表纵向连接select column_name(s) from table_name1union|union all -- union all 表示允许重复的行(性能高),而 union 会去掉重复的行select column_name(s) from table_name2
11.数据操作语言(DML)
-
11.1.INSERT语法
-- 空值用 null 表示-- MySQL 特有的语法:用一条 insert 语句插入多条数据记录-- 如果使用了 ignore,在执行语句时出现的错误被当作警告处理,例如,一个要插入的行复制了原有的 unique 索引或 primary key 值,则该行不被插入,且不会出现错误-- 如果指定了 on duplicate key update,并且插入行后会导致在一个 unique 索引或 primary key 中出现重复值,则执行旧行 update(如果行作为新记录被插入,则受影响行的值为 1;如果原有的记录被更新,则受影响行的值为 2)-- values() 函数只在 insert...update 语句中有意义,其它时候会返回 nullinsert [ignore] into tb1_name (col_name, ...)values ({expr | default}, ...), (...), ...[ on duplicate key update col_name = expr, ... ][ on duplicate key update col_name = expr | values(col_name) , ... ]insert into tb1_nameset col_name = {expr | default}, ...[ on duplicate key update col_name = expr, ... ]-- 插入查询结果insert into tb1_name (col_name, ...)select ...[ on duplicate key update col_name = expr, ... ]
11.2.REPLACE语法
-- 如果表中的一个旧记录与一个用于 primary key 或一个 unique 索引的新记录具有相同的值,则在新记录被插入之前,旧记录被删除-- 返回被删除和被插入的行数的和replace [into] tbl_name [(col_name, ...)]values ({expr | default}, ...), (...), ...replace [into] tbl_nameset col_name = {expr | default}, ...-- 替换查询结果replace [into] tbl_name [(col_name,...)]select ...
11.3.UPDATE语法
update 语句只支持更新前多少行,不支持从某行到另一行,即只能 limit 30,不能 limit 20, 10
11.3.1.单表语法
update tb1_nameset col_name1 = expr1 [, col_name2 = expr2 ...][where where_definition][order by ...][limit row_count]
11.3.2.多表语法
update table_referencesset col_name1 = expr1 [, col_name2 = expr2 ...][where where_definition]update items, monthset items.price = month.pricewhere items.id = month.id;-- 多表 update 语句可以使用在 select 语句中允许的任何类型的联合,比如 left join-- order by 或 limit 不能与多表 update 同时使用
11.4.DELETE语法
11.4.1.单表语法
delete from tb1_name[where where_definition][order by ...][limit row_count]
11.4.2.多表语法
-- 只删除列于 from 子句之前的表中的对应的行delete tb1_name [, tb2_name, ...]from table_references[where where_definition]-- 只删除列于 from 子句之中(在 using 子句之前)的表中的对应的行delete from tb1_name [, tb2_name, ...]using table_references[where where_definition]delete t1, t2 from t1, t2, t3 where t1.id = t2.id and t2.id = t3.id;delete from t1, t2 using t1, t2, t3 where t1.id = t2.id and t2.id = t3.id;-- 多表 delete 语句除了使用逗号操作符的内部联合外,还可以使用 select 语句中允许的所有类型的联合,比如 left join
12.数据库控制语言(DCL)
12.1.账号管理语句
``sql -- 创建用户 create user 'guest'@'localhost' identified by '1234'; -- 修改用户密码 alter user 'guest'@'localhost' identified by '123'; -- 授予用户权限 -- 注意:在授权操作之后,需要使用 flush privileges 命令刷新权限 grant 权限 on 数据库.数据库对象 to 用户名@'主机' identified by '密码' -- 创建用户,设置密码 with grant option; -- 允许用户继续授权 grant all [privileges] on *.* to guest@'localhost' identified by '1234' with grant option; -- 创建一个超级管理员,用户名为 dev,密码为 1234,只能在 192.168.%.% 登陆,可以给别人授权 grant all privileges onedu-crm`. to dev@’192.168.%.%’ identified by ‘1234’ with grant option; flush privileges; — 查看用户的权限 show grants [for root@localhost] — 回收对用户的授权 revoke 权限 on 数据库对象 from 用户; revoke all on .* from guest@localhost;删除用户 drop user 用户名@’主机’; drop user guest@’%’; ```
12.2.SHOW语法
提供有关数据库、表、列或服务器状态的信息
- show [full] processlist:查看哪些线程正在运行,如果不使用 full 关键词,则只显示每个查询的前 100 个字符(如果有 process 权限,可以看到所有线程,否则只能看到自己的线程)
- User:发送 sql 语句到当前 MySQL 使用的是哪个用户
- Host: 发送 sql 语句到当前 MySQL 的主机 ip 和端口
- Db: 连接哪个数据库
- Command: 连接状态,一般是 sleep(休眠空闲)、query(查询)、connect(连接)
- Time: 连接执行时间
- State: 当前 sql 语句的执行状态,如 Checking table(正在检查数据表)、Sending data(正在处理 select 查询的记录,返回数据)、Sorting for group(正在为 group by 做排序)、Sorting for order(正在为 order by 做排序)、Updating(正在搜索匹配的记录,并且修改它们)、Locked(被其它查询锁住了)
- show [global | session] variables [like ‘pattern’]:查看服务器系统变量的值,如 ‘%query_cache%’、’validate_password%’
show [global | session] status [like ‘pattern’]:查看服务器状态信息,如 ‘Qcache%’、’Innodbbuffer_pool%’
12.3.其他管理语句
kill [connection | query] thread_id:终止线程,kill connection 与不含修改符的 kill 一样,它会终止与给定的 thread_id 有关的连接;kill query 会终止连接当前正在执行的语句,但是会保持连接的原状(如果有 super 权限,可以终止所有线程和语句,否则只能终止自己的线程)

若有收获,就点个赞吧
0 人点赞
