为什么要编码
计算机被设计为把字节 byte 作为最小的存储单位,即 8 个 bit,那么一个字节最多能表示 2 的 8 次方即 256 个字符。
世界上有各种各样的语言,256 个字符肯定不能代表所有的字符,那么就需要一种规范来表示不同的字符,这样就产生了从字符 char 到字节 byte 编码 和从字节 byte 到字符 char 解码 的转换,这就是编码和解码。
编码规范(或者叫编码格式)大致有以下几种:
- ASCII 编码,共有 128 个字符
- ISO-8859-1,共有 256 个字符
- GB2312,共有 682 个符号,6763 个汉字
- GBK,扩展了 GB2312,能表示 21003 个汉字。兼容 GB2312
- GB18030,国标,兼容 GB2312
- Unicode 统一码,包含世界所有语言,主要有以下两种编码:
- UTF-16,固定两个字节表示一个字符,不适用于网络传输,容易丢失。(Java 在内存中默认使用 UTF-16 编码)
- UTF-8,采用变长字节来表示不同字符,可以减少网络带宽和存储空间
编码并不是一种保证安全的技术,它只是为了使数据保持一致,对不同语言的人都是可视的。如果使用不当,那么就会产生乱码,这是我们不想见到的。
为了统一,我们建议使用 Unicode 统一编码;而对于使用到的一些旧的基于非统一编码的技术,我们要了解其默认编码,并通过配置或者程序来避免编码不一致产生的乱码。
场景及应用
字符转换
根据编码和解码的定义,Java 中存在字符和字节之间进行转换的场景主要有以下几种:
- Java IO 中字节流(Stream)和字符流 (Reader / Writer)之间的转换
主要由 StreamEncoder 类和 StreamDecoder 类进行编码和解码。 Java 字符串(String)和字节(Byte)的转换
主要由 StringCoding 类进行编码和解码。URL 编码
网络标准规定 URL 网址只能使用 26 个英文字母和数字,以及一些特殊字符。所以如果 URL 中含有其他字符,需要先 UTF-8 编码为 % 前缀的字符后再发送到服务器。
注意:由于不同的浏览器自动编码受网页编码设置等影响编码结果不同,我们不能依赖浏览器进行编码,而是应该使用 JavaScript 先统一进行编码后交给浏览器。JavaScript 编码
encodeURI方法,对 URL 的 path 和query 部分进行 URL 编码,不会对协议域名端口编码encodeURIComponent方法,对传入的字符串都会进行 URL 编码,该方法适合传入参数进行编码escape方法,对字符串编码,不适用于 URL 编码!
Java 标准库编码
- 编码
URLEncoder.encode(str, StandardCharsets.UTF_8); - 解码
URLDecoder.decode(str, StandardCharsets.UTF_8);:::success 一次 HTTP 请求中的编解码配置:
- 编码
对客户端请求编解码
- 设置 Ajax 请求 Content Type 编码为 charset=UTF-8
- 使用 encodeURIComponent() 对 URL 参数编码
- 服务端接收请求编解码
- Tomcat 服务器设置
<Connector URIEncoding="UTF-8">解码 URI - Tomcat 服务器设置
<connector URIEncoding="UTF-8" useBodyEncodingForURI="true">解码 Query String 参数 - 设置
request.setCharacterEncoding(charset)解码 POST 表单 - 使用 URLEncoder 类对请求头信息(HTTP Header 、Cookies)编解码
- Tomcat 服务器设置
服务端响应请求编解码
- 设置
response.setCharacterEncoding(charset)编码返回 BODY :::Base64 编码
标准的 Base64 编码使用 64 个字符依次是:A-Za-z0-9,再加上 + 和 /。他是一种将二进制数据转成文本数据的方案。
对于非二进制数据,先将其转换成二进制形式,然后每连续 6 比特(2 的 6 次方 = 64)计算其十进制值,根据该值在上面的索引表中找到对应的字符,最终得到一个文本字符串。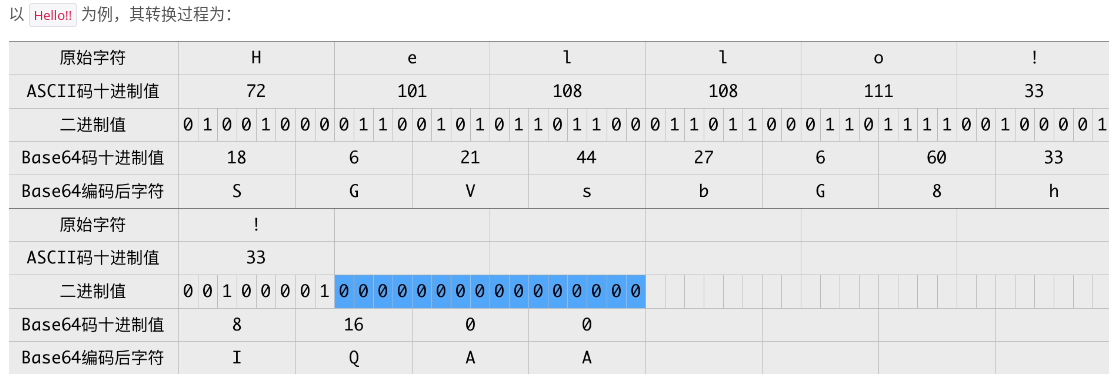
Base64 编码是每 3 个原始字符编码成 4 个字符,如果原始字符串长度不能被 3 整除,就使用 0 来补充原始字符串。编码后长度变为原来的 4/3,这个比较平衡的比例使得 Base64 应用广泛。
注意:
- 设置
长度不够时补充的无意义的 0 通常转为 = 表示
- 解码时长度不够则补充 =,之后将 = 转为 A 解码
- 标准的 Base64 编码不能用于 URL 编码,因为他含有字符 + / =
- Java 标准库编码
Base64.getEncoder().encodeToString(bytes); - Java 标准库解码
Base64.getDecoder().decode(str);
- Java 标准库编码
- 有一种针对 URL 的 Base64 编码,他把 + 变为 -,把 / 变为了 _
- Java 标准库编码
Base64.getUrlEncoder().encodeToString(bytes); - Java 标准库解码
Base64.getUrlDecoder().decode(str);
- Java 标准库编码
常见应用:
- 将二进制图片或者文件进行 Base64 编码后作为字符串嵌入网页 现代浏览器支持 Data URLs
- 电子邮件中传输二进制文件
Base62 编码
只使用 A-Za-z0-9 62 个字符的编码,常用于短网址生成。
参考文献
- 《深入分析 Java Web 技术内幕》(修订版) 许令波 著 电子工业出版社
- 阮一峰的网络日志
- 廖雪峰的官方网站
- Base64编码原理与应用 有趣的技术

若有收获,就点个赞吧
0 人点赞
