教程:chat with PDF
概述
检索增强生成(或RAG)已成为使用大型语言模型(或LLMs)构建智能应用程序的普遍模式,因为它可以将外部知识注入到模型中,而该模型未经过针对最新或专有信息的训练。下面的截图显示了新的Edge边栏中的Bing如何根据左侧页面内容(在本例中是PDF文件)回答问题。

请注意,新的Bing还会搜索网络以获取更多信息来生成答案,我们暂时忽略这一部分。
在本教程中,我们将尝试模仿从PDF中检索相关信息以生成答案的功能,使用GPT。
我们将引导您完成以下步骤:
- 创建一个名为“chat_with_pdf”的控制台聊天机器人,该机器人将一个PDF文件的URL作为参数,并基于PDF的内容回答问题。
- 为聊天机器人构建一个prompt flow,主要是重用第一步的代码。
- 创建一个包含多个问题的数据集,以便快速测试流程。
- 评估chat_with_pdf流程生成的答案的质量。
- 将这些测试和评估整合到您的开发周期中,包括单元测试和CI/CD。
- 将流程部署到Azure App Service和Streamlit以处理真实用户流量。
先决条件
要完成本教程,您应该:
- 安装依赖项
cd ../../flows/chat/chat-with-pdf/pip install -r requirements.txt
安装并配置Prompt flow的VS Code扩展,遵循快速入门指南。(此扩展是可选的,但强烈建议用于流程开发和调试。)
部署OpenAI或Azure OpenAI聊天模型(例如gpt4或gpt-35-turbo-16k)和一个嵌入模型(text-embedding-ada-002)。按照Azure OpenAI示例的操作说明进行操作。
控制台聊天机器人 chat_with_pdf
典型的RAG过程包括两个步骤:
- 检索:从外部系统(数据库、搜索引擎、文件等)检索上下文信息。
生成:使用检索到的上下文构建prompt并从LLMs获取响应。 检索步骤,更多的是一个搜索问题,可能会非常复杂。一个广泛使用的简单而有效的方法是矢量搜索,这需要一个索引构建过程。假设您有一个或多个包含上下文信息的文档,索引构建过程可能如下所示:
切块:将文档分解为多个文本块。
- 嵌入:然后,通过嵌入模型处理每个文本块,将其转换为一系列浮点数,也称为嵌入或向量。
- 索引:这些向量然后存储在支持矢量搜索的索引或数据库中。这允许从索引或数据库中检索与问题最相关或相似的前K个向量。 一旦建立了索引,检索步骤就简单地涉及将问题转换为一个嵌入/向量,并在索引上执行矢量搜索,以获取问题的最相关上下文。
好了,现在回到我们想构建的聊天机器人,一个简化的设计可能是:
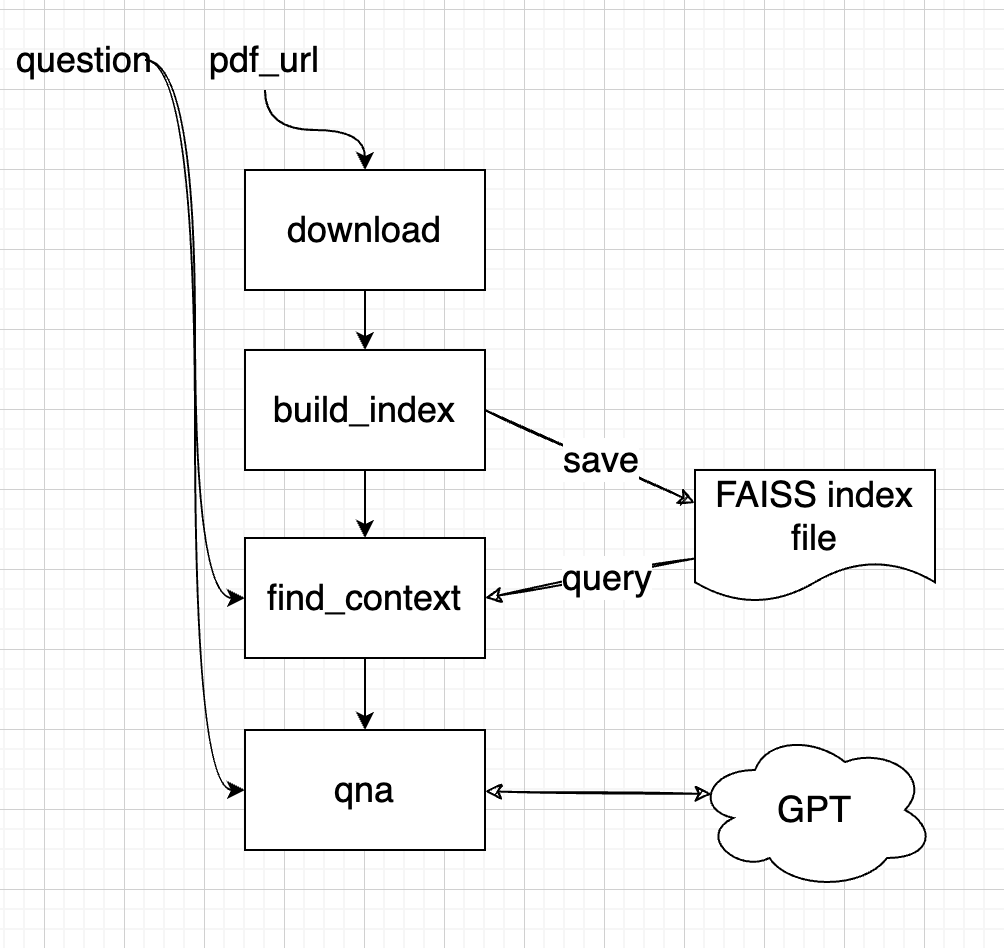
一个更健壮或实用的应用可能考虑使用外部矢量数据库来存储这些向量。对于这个简单的例子,我们使用了一个FAISS索引,它可以保存为一个文件。然而,一个更健壮或实用的应用应该考虑使用一个具有高级管理功能的外部矢量数据库来存储这些向量。对于这个示例的FAISS索引,为了防止对相同的PDF文件进行重复下载和索引构建,我们将添加一个检查,如果PDF文件已经存在,那么我们就不会下载,同样对于索引构建也是如此。
这种设计在问答方面非常有效,但在与聊天机器人进行多轮对话时可能会不足。考虑以下场景:
$User: 什么是BERT?
$Bot: BERT代表双向编码器转换器表示。
$User: 它比GPT好吗?
$Bot: …
你通常希望聊天机器人足够聪明,能够理解你第二个问题中的“它”是指BERT,你实际上的问题是“BERT是否比GPT更好”。然而,如果你将问题“它是否比GPT更好”呈现给嵌入模型,然后再呈现给矢量索引/数据库,它们将无法识别“它”代表BERT。因此,您将无法从索引中获取最相关的上下文。为解决这个问题,我们将寻求大型语言模型(LLM)的帮助,例如GPT,以根据先前的问题“重写”问题。更新后的设计如下:
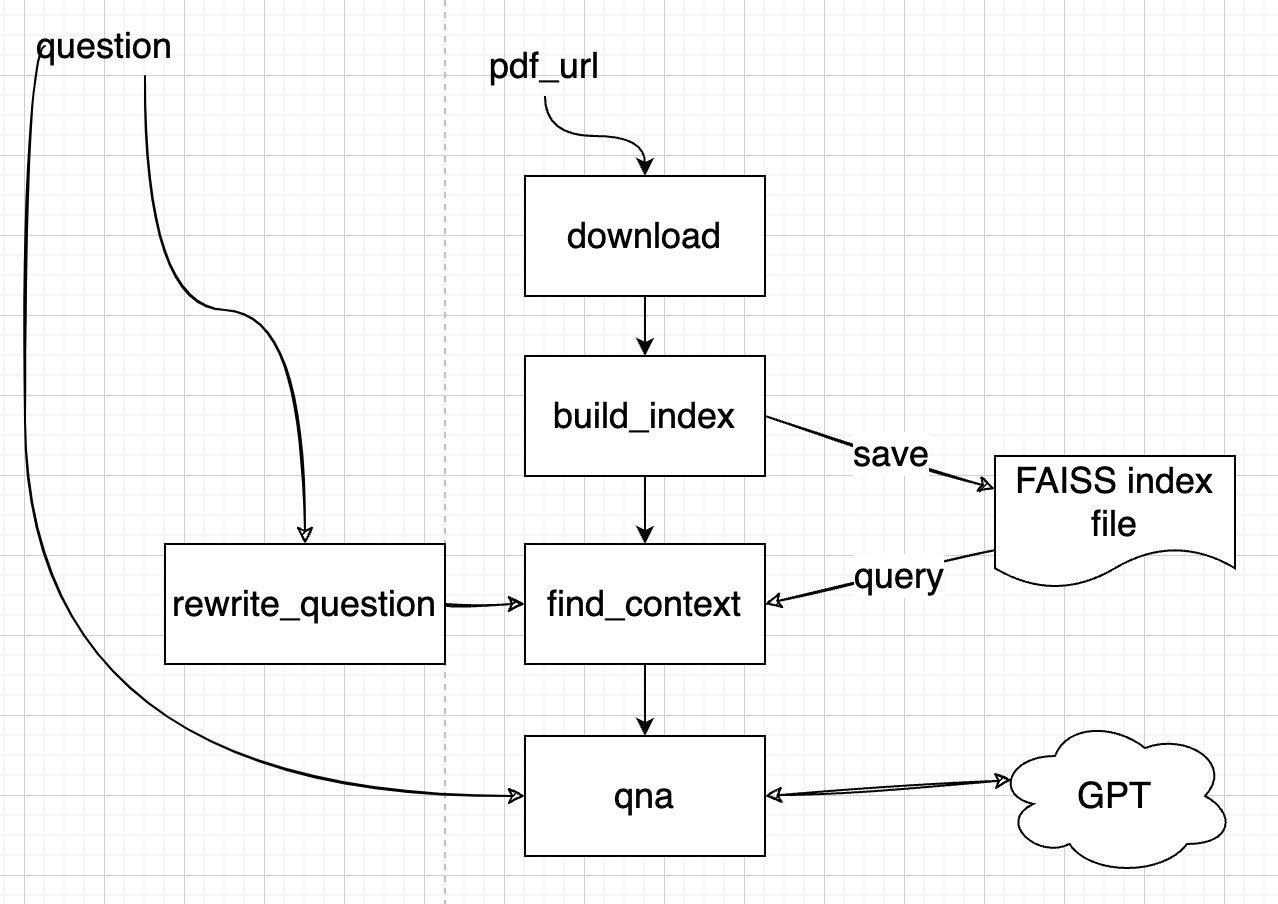
在将问题传递给“find_context”步骤之前,将执行“rewrite_question”步骤。
配置
尽管是一个最小化的 LLM 应用程序,但在将来我们可能想要调整或尝试的方面有很多。我们将这些存储在环境变量中,以便更轻松地访问和修改。在接下来的部分中,我们将指导您如何尝试这些配置,以提高聊天应用程序的质量。
在第二个 chat_with_pdf 目录中(与 main.py 位于同一目录中)创建一个 .env 文件,并将其填充为以下内容。我们可以使用 load_dotenv() 函数(从 python-dotenv 包中导入)稍后将其导入到我们的环境变量中。在讨论每个步骤如何实现时,我们将深入探讨这些变量代表什么。
将 chat_with_pdf 目录中的 .env.example 文件重命名并根据需要进行修改。
如果您使用OpenAI,您的.env应该如下所示:
OPENAI_API_KEY=<open_ai_key>EMBEDDING_MODEL_DEPLOYMENT_NAME=<text-embedding-ada-002>CHAT_MODEL_DEPLOYMENT_NAME=<gpt-4>PROMPT_TOKEN_LIMIT=3000MAX_COMPLETION_TOKENS=1024CHUNK_SIZE=256CHUNK_OVERLAP=64VERBOSE=False
注意:如果您有org id,可以通过OPENAI_ORG_ID=
如果您使用Azure OpenAI,您的.env应该如下所示:
OPENAI_API_TYPE=azureOPENAI_API_BASE=<AOAI_endpoint>OPENAI_API_KEY=<AOAI_key>OPENAI_API_VERSION=2023-05-15EMBEDDING_MODEL_DEPLOYMENT_NAME=<text-embedding-ada-002>CHAT_MODEL_DEPLOYMENT_NAME=<gpt-4>PROMPT_TOKEN_LIMIT=3000MAX_COMPLETION_TOKENS=1024CHUNK_SIZE=256CHUNK_OVERLAP=64VERBOSE=False
注意:CHAT_MODEL_DEPLOYMENT_NAME 应该指向像 gpt-3.5-turbo 或 gpt-4 这样的聊天模型,OPENAI_API_KEY应该使用部署密钥,EMBEDDING_MODEL_DEPLOYMENT_NAME 应该指向 text
-embedding-ada-002 这样的文本嵌入模型。
让我们看看聊天机器人的运行情况!您应该能够通过以下方式运行控制台应用程序:
python chat_with_pdf/main.py https://arxiv.org/pdf/1810.04805.pdf
注意:https://arxiv.org/pdf/1810.04805.pdf 是关于最著名的早期LLMs之一:BERT的论文。
如果一切正常,它应该像下面这样:
让我们深入了解实现聊天机器人的实际代码。
每个步骤的实现:
下载 PDF:download.py
- 下载的 PDF 文件将被存储在 temp 文件夹中。
构建索引:build_index.py
- 在此步骤中使用了几个库来构建索引:
- PyPDF2 用于从 PDF 文件中提取文本。
- OpenAI Python 库用于生成嵌入。
- 使用 FAISS 库构建矢量索引并将其保存到文件中。重要的是要注意,使用附加的字典来维护从矢量索引到实际文本片段的映射。这是因为当我们尝试查询最相关的上下文时,我们需要定位文本片段,而不仅仅是嵌入或矢量。在此步骤中使用的环境变量:
- OPENAIAPI* 和 EMBEDDING_MODEL_DEPLOYMENT_NAME:用于访问 Azure OpenAI 嵌入模型。
- CHUNK_SIZE 和 CHUNK_OVERLAP:控制如何将 PDF 文件拆分为用于嵌入的块。
- 在此步骤中使用了几个库来构建索引:
重写问题:rewrite_question.py
- 使用 ChatGPT/GPT4 重写问题,以更好地适应从矢量索引中查找相关上下文。重写问题的 prompt 文件 rewrite_question.md 应该能够给您更好的了解它是如何工作的。
查找上下文:find_context.py
- 在此步骤中,我们加载了在“构建索引”步骤中构建的 FAISS 索引和字典。然后,我们使用与构建索引步骤中相同的嵌入函数将问题转换为矢量。在此步骤中有一个小技巧,以确保上下文不会超过模型输入提示的令牌限制(aoai 模型的最大请求令牌,OpenAI 有类似的限制)。此步骤的输出是 QnA 步骤将发送到聊天模型的最终提示。PROMPT_TOKEN_LIMIT 环境变量决定上下文有多大。
问答:qna.py
- 使用 OpenAI 的 ChatGPT 或 GPT4 模型和 ChatCompletion API,获取带有先前对话历史和来自 PDF 的上下文的答案。
主循环:main.py
- 这是聊天机器人的主入口,其中包括一个循环,从用户输入中读取问题,并随后调用上述步骤提供答案。
为了简化这个示例,我们将下载的文件和构建的索引存储为本地文件。虽然存在利用缓存文件/索引的机制,但加载索引仍然需要一定的时间,会导致用户可能会注意到的延迟。此外,如果聊天机器人托管在服务器上,为了有效使用缓存,需要对相同的 PDF 文件进行的请求击中相同的服务器节点。在实际应用中,最好将索引存储在一个集中的服务或数据库中。有许多这样的数据库可用,例如 Azure Cognitive Search、Pinecone、Qdrant 等。
Prompt flow:当您开始考虑您的 LLM 应用程序的质量时
拥有一个功能齐全的聊天机器人是一个很好的开始,但这只是旅程的开始。与基于机器学习的任何应用程序一样,开发高质量的LLM应用通常涉及大量的调整。这可能包括尝试不同的提示,比如重写问题或QnAs,调整各种参数,如块大小、重叠大小或上下文限制,甚至重新设计工作流程(例如,决定是否在我们的例子中包含rewrite_question步骤)。
对于通过 Prompt flow 进行实验和微调过程而言,适当的工具至关重要。这就是 Prompt flow 概念发挥作用的地方。它使您能够通过以下方式测试LLM应用:
- 运行一些示例并手动验证结果。
- 使用正式的方法(使用度量标准)运行更大规模的测试,以评估应用程序的质量。
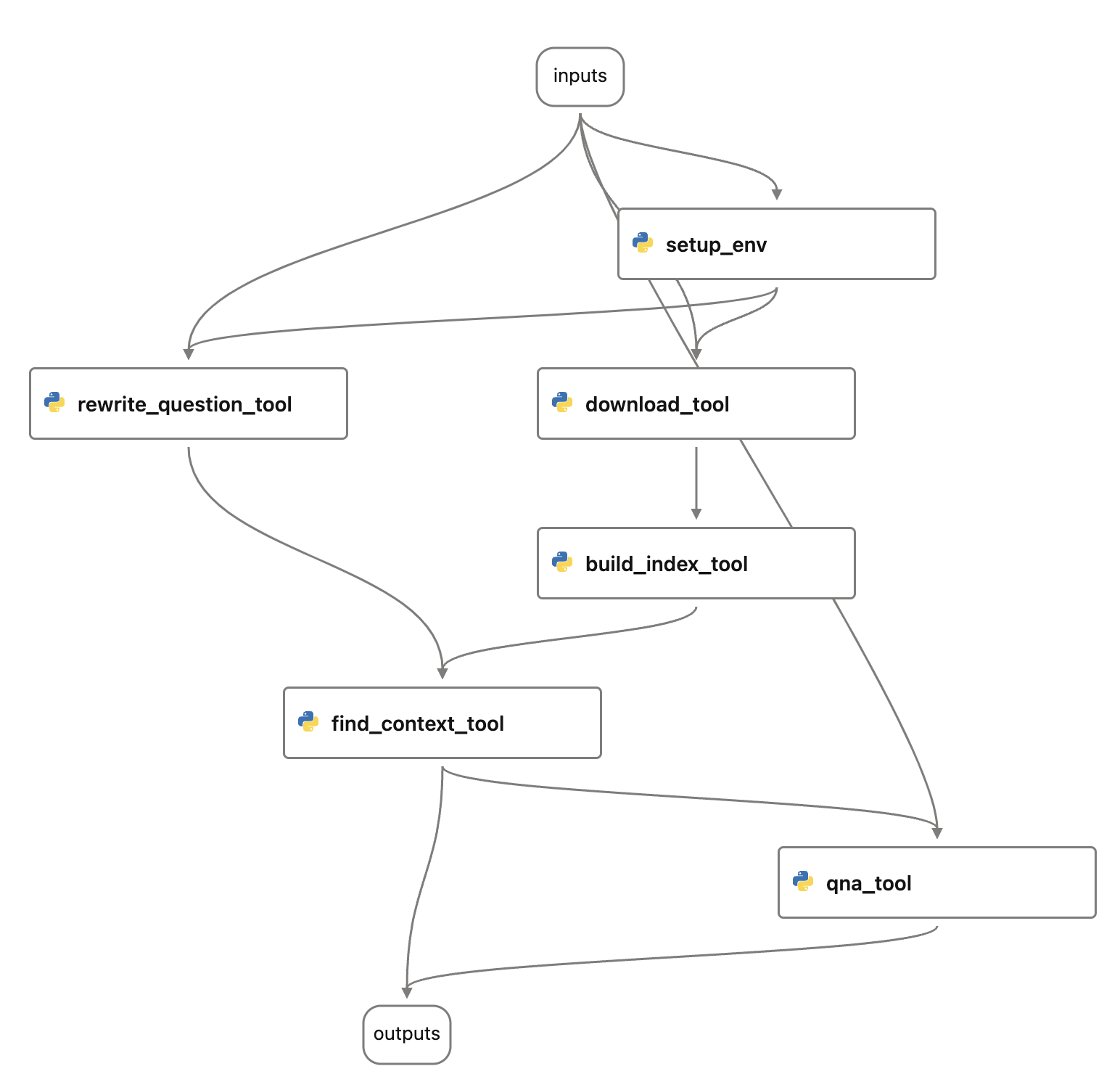
您可能已经学会如何从头开始创建 Prompt flow。从现有代码构建 Prompt flow 也很简单。您可以通过组合YAML文件或使用 Visual Studio Code 扩展的可视编辑器创建聊天流,并为现有代码创建一些包装器。
查看以下内容:
- flow.dag.yaml
- setup_env.py
- download_tool.py
- build_index_tool.py
- rewrite_question_tool.py
- find_context_tool.py
- qna_tool.py
例如,构建索引工具的包装器:
from promptflow import toolfrom chat_with_pdf.build_index import create_faiss_index@tooldef build_index_tool(pdf_path: str) -> str:return create_faiss_index(pdf_path)
setup_env 节点需要一些解释:您可能记得我们使用环境变量来管理不同的配置,包括控制台聊天机器人中的 OpenAI API 密钥,在 Prompt flow 中,我们使用 Connection 来管理对外部服务(如 OpenAI)的访问,并支持将配置对象传
递到流中,以便您可以更轻松地进行实验。setup_env 节点是将连接和配置对象中的属性写入环境变量的目的。这使得聊天机器人的核心代码保持不变。
在此示例中,我们使用 Azure OpenAI,以下是用于此目的的 shell 命令:
# create connection needed by flowif pf connection list | grep open_ai_connection; thenecho "open_ai_connection already exists"elsepf connection create --file ../../../connections/azure_openai.yml --name open_ai_connection --set api_key=<your_api_key> api_base=<your_api_base>fi
如果您计划使用 OpenAI,可以改用以下内容:
# create connection needed by flowif pf connection list | grep open_ai_connection; thenecho "open_ai_connection already exists"elsepf connection create --file ../../../connections/openai.yml --name open_ai_connection --set api_key=<your_api_key>fi
这个流看起来像:
Prompt Flow Evaluations:
现在已经创建了 chat_with_pdf 的 Prompt flow,您可能已经通过 Visual Studio Code 扩展运行/调试了流程。现在是进行一些测试和评估的时候,它始于:
- 创建一个包含一些问题和 pdf_url 对的测试数据集。
- 使用现有的评估流程或开发新的评估流程生成度量标准。
一个小数据集可以在这里找到:bert-paper-qna.jsonl,其中包含约 10 个关于 BERT 论文的问题。
评估是通过“批次运行”来执行的。从概念上讲,它们是一个评估流的批次运行,使用前一次运行作为输入。
以下是如何使用测试数据集和手动审查输出为 chat_with_pdf 流创建批次运行的示例。这可以通过 Visual Studio Code 扩展、CLI 或 Python SDK 完成。
batch_run.yaml
name: chat_with_pdf_default_20230820_162219_559000flow: .data: ./data/bert-paper-qna.jsonl#run: <Uncomment to select a run input>column_mapping:chat_history: ${data.chat_history}pdf_url: ${data.pdf_url}question: ${data.question}config:EMBEDDING_MODEL_DEPLOYMENT_NAME: text-embedding-ada-002CHAT_MODEL_DEPLOYMENT_NAME: gpt-35-turboPROMPT_TOKEN_LIMIT: 3000MAX_COMPLETION_TOKENS: 1024VERBOSE: trueCHUNK_SIZE: 256CHUNK_OVERLAP: 64
CLI:
run_name="chat_with_pdf_"$(openssl rand -hex 12)pf run create --file batch_run.yaml --stream --name $run_name
输出将包含类似以下内容:
{"name": "chat_with_pdf_default_20230820_162219_559000","created_on": "2023-08-20T16:23:39.608101","status": "Completed","display_name": "chat_with_pdf_default_20230820_162219_559000","description": null,"tags": null,"properties": {"flow_path": "/Users/<user>/Work/azure-promptflow/scratchpad/chat_with_pdf","output_path": "/Users/<user>/.promptflow/.runs/chat_with_pdf_default_20230820_162219_559000"},"flow_name": "chat_with_pdf","data": "/Users/<user>/Work/azure-promptflow/scratchpad/chat_with_pdf/data/bert-paper-qna.jsonl","output": "/Users/<user>/.promptflow/.runs/chat_with_pdf_default_20230820_162219_559000/flow_outputs/output.jsonl"}
查找 CLI 中未提供列映射的默认行为的参考资料。我们还开发了两个评估流,一个用于“接地性”,另一个用于“感知智能”。这两个流程使用 GPT 模型(ChatGPT 或 GPT4)来“评分”答案。阅读提示将使您更好地了解这两个指标:
以下示例创建了一个评估流。
eval_run.yaml:
flow: ../../evaluation/eval-groundednessrun: chat_with_pdf_default_20230820_162219_559000column_mapping:question: ${run.inputs.question}answer: ${run.outputs.answer}context: ${run.outputs.context}
CLI:
eval_run_name="eval_groundedness_"$(openssl rand -hex 12)pf run create --file eval_run.yaml --run $run_name --name $eval_run_name
注意:此假设您已经按照先前的步骤创建了名为 “open_ai_connection” 的 OpenAI/Azure OpenAI 连接。
运行完成后,您可以使用以下命令获取运行的详细信息:
pf run show-details --name $eval_run_namepf run show-metrics --name $eval_run_namepf run visualize --name $eval_run_name
实验!
现在我们已经探讨了如何进行 prompt flow 的测试和评估。此外,我们已经定义了两个指标来衡量 chat_with_pdf 流的性能。通过尝试各种设置和配置,运行评估,然后比较指标,我们可以确定用于生产部署的最佳配置。
我们可以进行实验的几个方面,包括但不限于:
- 更改 rewrite_question 和/或 QnA 步骤的提示。
- 在构建索引过程中调整块大小或块重叠。
- 修改上下文限制。
这些元素可以通过流程输入中的 “config” 对象进行管理。如果您希望尝试第一点(变化的提示),您可以向 config 对象添加属性以控制此行为 - 简单地将其定向到不同的提示文件。
查看下面测试中我们如何对 #3 进行实验:tests/chat_with_pdf_test.py 中的 test_eval。这个测试总共会创建 6 个运行:
- chat_with_pdf_2k_context
- chat_with_pdf_3k_context
- eval_groundedness_chat_with_pdf_2k_context
- eval_perceived_intelligence_chat_with_pdf_2k_context
- eval_groundedness_chat_with_pdf_3k_context
- eval_perceived_intelligence_chat_with_pdf_3k_context
正如您可能从名称中看出的那样:运行 #3 和 #4 生成了运行 #1 的指标,运行 #5 和 #6 生成了运行 #2 的指标。您可以比较这些指标来决定哪个性能更好 - 2K 上下文还是 3K 上下文。
注意: azure_chat_with_pdf_test 执行相同的测试,但使用 Azure AI 作为后端,这样您就可以在一个漂亮的 Web 门户中看到所有运行的所有日志和指标对比等。
更多阅读:
将 prompt flow 集成到 CI/CD 工作流程中
通过 CLI 或 SDK 将这些流程集成到您的 CI/CD 工作流程中也是简单的。在这个例子中,我们有各种单元测试来运行 chat_with_pdf 流的测试/评估。
检查 test 文件夹。
# 运行所有测试python -m unittest discover -s tests -p '*_test.py'
部署
该流程可以部署在多个平台上,例如本地开发服务、Docker 容器内、Kubernetes 集群等。
以下部分将引导您完成将流程部署到 Docker 容器的过程,有关其他选择的详细信息,请参阅流程部署文档。
构建流程作为 Docker 格式应用
使用以下命令将流程构建为 Docker 格式应用:
pf flow build --source . --output dist --format docker
使用 Docker 部署
构建 Docker 镜像
与其他 Dockerfile 一样,您需要首先构建镜像。您可以使用任何您想要的名称为图像打标签。在这个例子中,我们使用 promptflow-serve。
运行以下命令构建图像:
docker build dist -t chat-with-pdf-serve
运行 Docker 镜像
运行 docker 镜像将启动一个服务,以在容器内部提供流程。
连接
如果服务涉及连接,所有相关的连接将被导出为 yaml 文件并在容器中重新创建。连接中的机密将不会直接导出。相反,我们将它们导出为对环境变量的引用:
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/OpenAIConnection.schema.jsontype: open_ainame: open_ai_connectionmodule: promptflow.connectionsapi_key: ${env:OPEN_AI_CONNECTION_API_KEY} # env reference
您需要在容器中设置环境变量,以使连接工作。
使用 docker run 运行
您
可以直接运行 docker 镜像,通过以下命令设置:
# 启动的服务将监听 8080 端口。您可以将端口映射到主机机器上的任何端口。docker run -p 8080:8080 -e OPEN_AI_CONNECTION_API_KEY=<secret-value> chat-with-pdf-serve
测试端点
启动服务后,您可以在 http://localhost:8080/ 打开测试页面并进行测试。
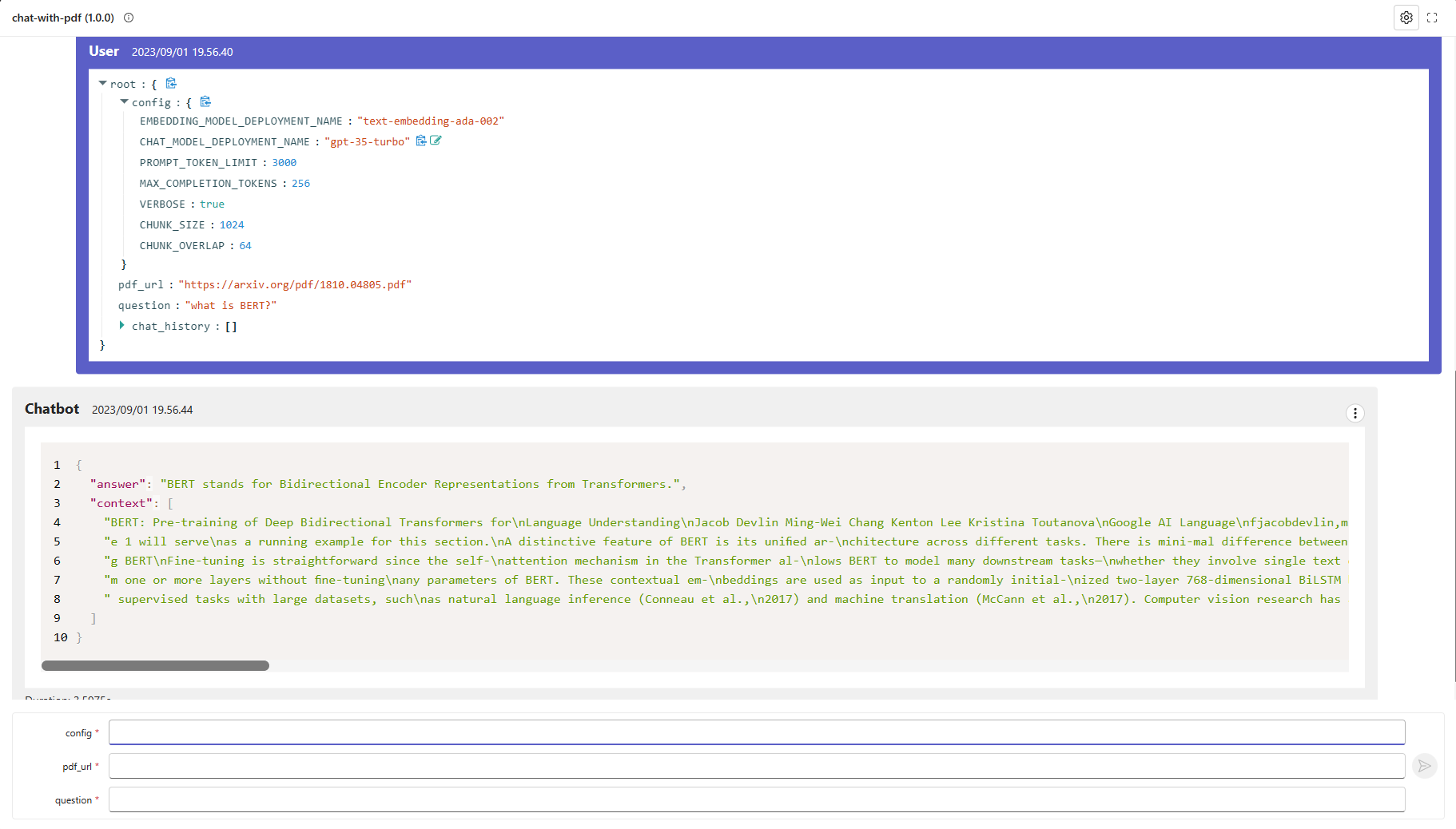
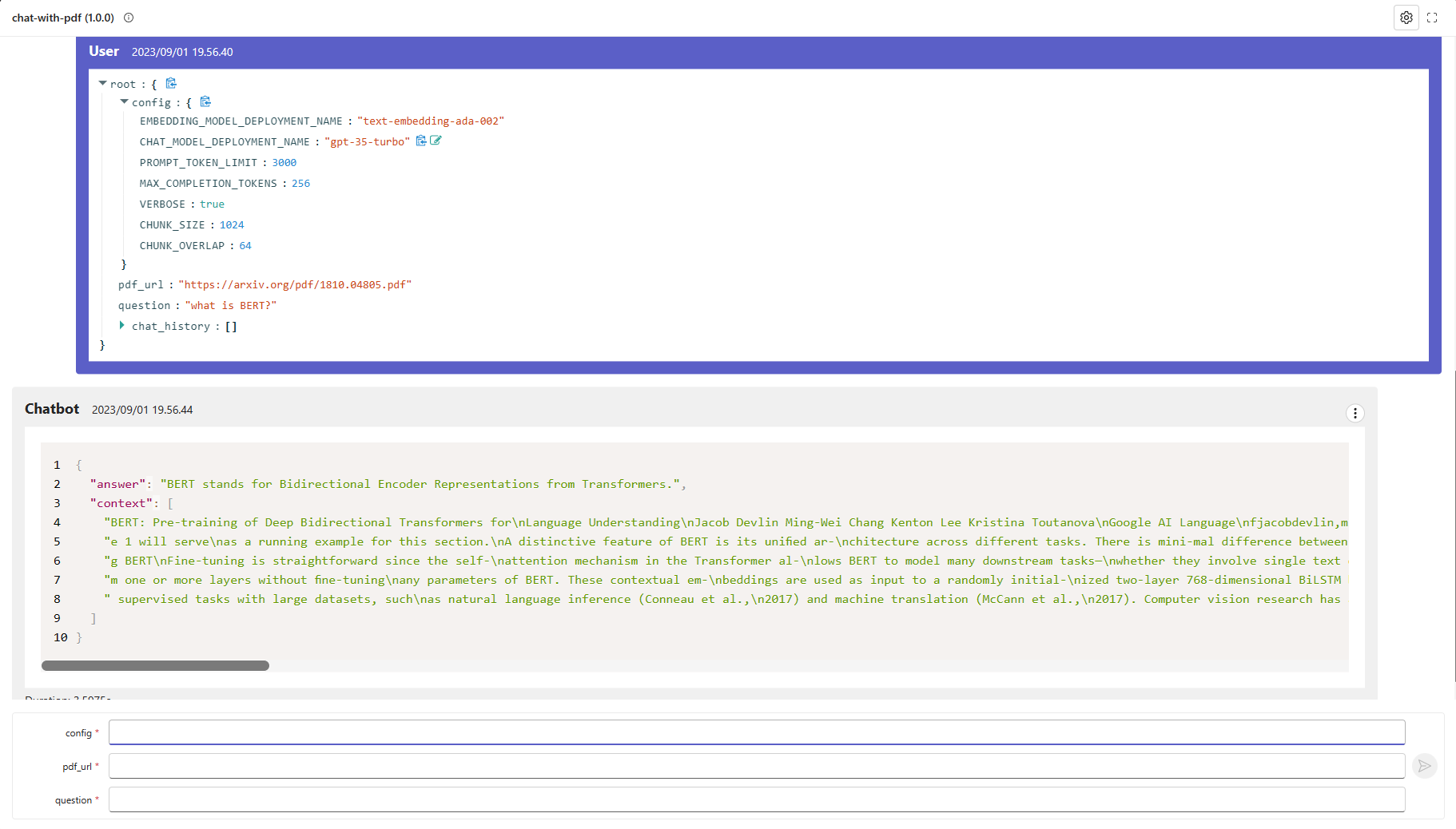
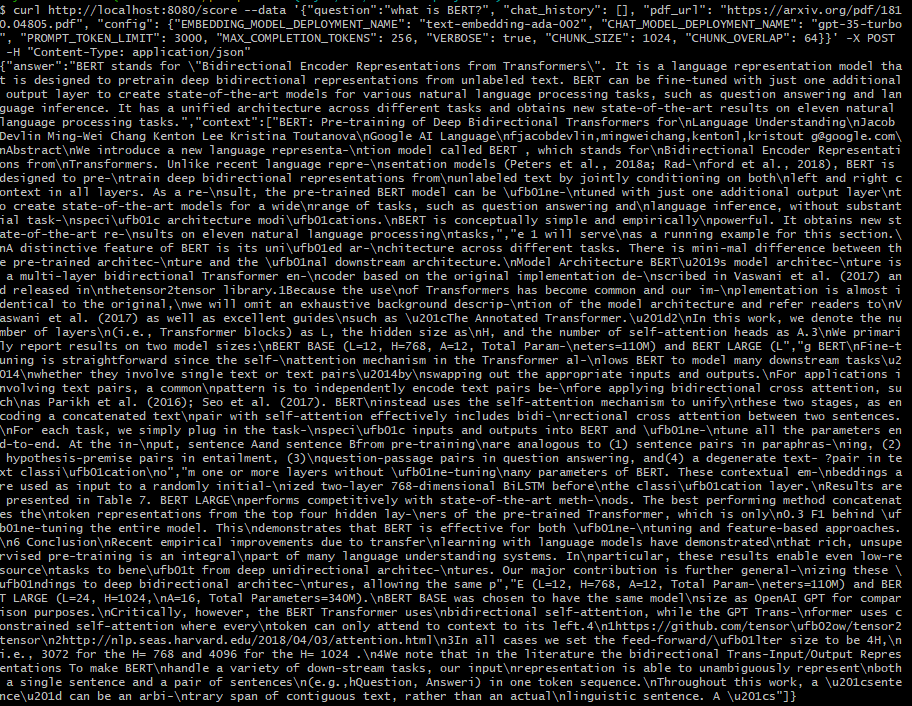
或者在命令行中通过 CURL 来测试它
curl http://localhost:8080/score --data '{"question":"what is BERT?", "chat_history": [], "pdf_url": "https://arxiv.org/pdf/1810.04805.pdf", "config": {"EMBEDDING_MODEL_DEPLOYMENT_NAME": "text-embedding-ada-002", "CHAT_MODEL_DEPLOYMENT_NAME": "gpt-35-turbo", "PROMPT_TOKEN_LIMIT": 3000, "MAX_COMPLETION_TOKENS": 256, "VERBOSE": true, "CHUNK_SIZE": 1024, "CHUNK_OVERLAP": 64}}' -X POST -H "Content-Type: application/json"

若有收获,就点个赞吧
0 人点赞
