目录 | 上一节 (2.6 列表推导式) | 下一节 (3 程序组织)
2.7 对象
本节介绍有关 Python 内部对象模型的更多详细信息,并讨论一些与内存管理,拷贝和类型检查有关的问题。
赋值
Python 中的许多操作都与赋值或者存储值有关。
a = value # Assignment to a variables[n] = value # Assignment to a lists.append(value) # Appending to a listd['key'] = value # Adding to a dictionary
警告:赋值操作永远不是值拷贝。所有的赋值操作都是引用拷贝(如果你乐意,也可以说是指针拷贝)
赋值示例
考虑该代码片段:
a = [1,2,3]b = ac = [a,b]
以下是底层内存操作图。在此示例中,只有一个列表对象 [1,2,3],但是有四个不同的引用指向它。
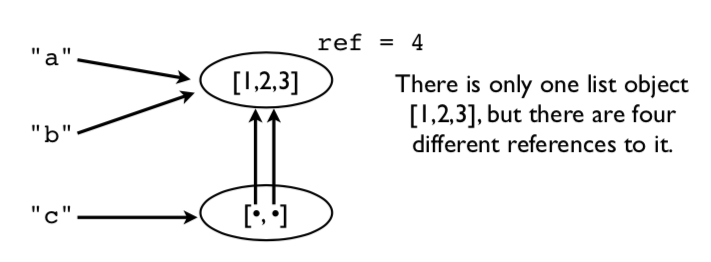
这意味着修改一个值会影响所有的引用。
>>> a.append(999)>>> a[1,2,3,999]>>> b[1,2,3,999]>>> c[[1,2,3,999], [1,2,3,999]]>>>
请注意,原始列表中的更改是如何在其它地方显示的。这是因为从未进行任何拷贝,所有的东西都指向同一个东西。
重新赋值
重新赋值永远不会重写之前的值所使用的内存。
a = [1,2,3]b = aa = [4,5,6]print(a) # [4, 5, 6]print(b) # [1, 2, 3] Holds the original value
切记:变量是名称,不是内存地址
风险
如果你不知道这种(数据)共享(的方式),那么在某些时候你会搬起石头砸自己的脚。典型情景,你修改了一些数据,以为它是自己的私有拷贝,但是它却意外地损破坏了程序其它部分的某些数据。
说明:这就是为什么原始数据类型是不可变(只读)的原因之一
标识值和引用
使用 is 操作符检查两个值是否真的是相同的对象。
>>> a = [1,2,3]>>> b = a>>> a is bTrue>>>
is 操作符比较对象的标识值(一个整数)。标识值可以使用 id() 函数获取。
>>> id(a)3588944>>> id(b)3588944>>>
注意:使用 == 检查对象是否相等几乎总是更好,is的结果通常会出乎意料:
>>> a = [1,2,3]>>> b = a>>> c = [1,2,3]>>> a is bTrue>>> a is cFalse>>> a == cTrue>>>
浅拷贝
列表和字典自身具有用于拷贝的方法。
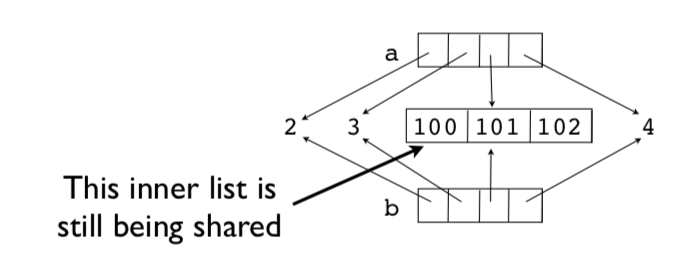
>>> a = [2,3,[100,101],4]>>> b = list(a) # Make a copy>>> a is bFalse
这是一个新列表,但是列表中的项是共享的。
>>> a[2].append(102)>>> b[2][100,101,102]>>>>>> a[2] is b[2]True>>>
例如,内部列表 [100, 101, 102] 正在共享。这就是众所皆知的浅拷贝。下面是图示:
深拷贝
有时候,需要拷贝一个对象及其中所包含的所有对象,为此,可以使用 copy 模块:
>>> a = [2,3,[100,101],4]>>> import copy>>> b = copy.deepcopy(a)>>> a[2].append(102)>>> b[2][100,101]>>> a[2] is b[2]False>>>
名称,值,类型
变量名称没有类型,仅仅是一个名字。但是,值确实具有一个底层的类型。
>>> a = 42>>> b = 'Hello World'>>> type(a)<type 'int'>>>> type(b)<type 'str'>
type() 函数将告诉你这是什么。类型名称通常用作创建或将值转换为该类型的函数。
类型检查
如何判断对象是否为特定类型?
if isinstance(a, list):print('a is a list')
检查是否是多种类型中的一种:
if isinstance(a, (list,tuple)):print('a is a list or tuple')
注意:不要过度使用类型检查。这会导致过度的代码复杂性。通常,如果这样做能够阻止其他人在使用你的代码时犯常见错误,那么就使用类型检查。
一切皆对象
数字,字符串,列表,函数,异常,类,实例等都是对象。这意味着所有可以命名的对象都可以作为数据传递、放置到容器中,而没有任何限制。没有特殊的对象。有时,可以这样说,所有的对象都是“一等对象”。
一个简单的例子:
>>> import math>>> items = [abs, math, ValueError ]>>> items[<built-in function abs>,<module 'math' (builtin)>,<type 'exceptions.ValueError'>]>>> items[0](-45)45>>> items[1].sqrt(2)1.4142135623730951>>> try:x = int('not a number')except items[2]:print('Failed!')Failed!>>>
在这里,items 是一个包含函数,模块和异常的列表。可以直接使用列表中的项代替原始名称。
items[0](-45) # absitems[1].sqrt(2) # mathexcept items[2]: # ValueError
权利越大,责任越大。只是因为你可以做,但并不意味着你应该这样做。
练习
在这组练习中,我们来看看来自一等对象的威力。
练习 2.24:一等数据
在 Data/portfolio.csv 文件中,我们把有组织的数据读取为列,如下所示:
name,shares,price"AA",100,32.20"IBM",50,91.10...
在之前的代码中,我们使用 csv 模块读取文件,但是仍必须手动执行类型转换。例如:
for row in rows:name = row[0]shares = int(row[1])price = float(row[2])
也可以使用一些列表基本操作以更巧妙的方式来执行这种转换。
创建一个包含转换函数名称的 Python 列表,这些函数用来把每一列转换成适当的类型。
>>> types = [str, int, float]>>>
可以创建这样的列表是因为在 Python 中一切皆一等对象。所以,如果想创建一个函数列表,也是可以的。列表中创建的项用于将值 x 转换为给定的类型(如:str(x), int(x), float(x))。
现在,从上面文件的数据中读取一行:
>>> import csv>>> f = open('Data/portfolio.csv')>>> rows = csv.reader(f)>>> headers = next(rows)>>> row = next(rows)>>> row['AA', '100', '32.20']>>>
如前所述,该行不足以进行计算,因为类型是错误的。例如:
>>> row[1] * row[2]Traceback (most recent call last):File "<stdin>", line 1, in <module>TypeError: can't multiply sequence by non-int of type 'str'>>>
但是,也许数据可以与在 types 中指定的类型配对。例如:
>>> types[1]<type 'int'>>>> row[1]'100'>>>
尝试转换其中一个值:
>>> types[1](row[1]) # Same as int(row[1])100>>>
尝试转换另一个值:
>>> types[2](row[2]) # Same as float(row[2])32.2>>>
尝试使用转换后的值进行计算:
>>> types[1](row[1])*types[2](row[2])3220.0000000000005>>>
使用 zip() 函数将字段组合到一起,并且查看结果:
>>> r = list(zip(types, row))>>> r[(<type 'str'>, 'AA'), (<type 'int'>, '100'), (<type 'float'>,'32.20')]>>>
注意看,这会将类型转换函数名称与值配对。例如,int 和 '100'配对。
如果要一个接一个地对所有值进行转换,那么合并后的列表很有用。请尝试:
>>> converted = []>>> for func, val in zip(types, row):converted.append(func(val))...>>> converted['AA', 100, 32.2]>>> converted[1] * converted[2]3220.0000000000005>>>
确保你理解上述代码中所发生的事情。在循环中,func 变量是类型转换函数(如str, int等 )之一且 val 变量是值('AA', '100')之一。表达式 func(val)转换一个值(类似于类型转换)。
上面的代码可以转换为单个列表推导式。
>>> converted = [func(val) for func, val in zip(types, row)]>>> converted['AA', 100, 32.2]>>>
练习 2.25:创建字典
还记得如果有一个键和值的序列,如何使用dict() 函数轻松地创建字典吗?让我们从列标题创建一个字典吧:
>>> headers['name', 'shares', 'price']>>> converted['AA', 100, 32.2]>>> dict(zip(headers, converted)){'price': 32.2, 'name': 'AA', 'shares': 100}>>>
当然,如果你精通列表推导式,则可以使用字典推导式一步完成整个转换。
>>> { name: func(val) for name, func, val in zip(headers, types, row) }{'price': 32.2, 'name': 'AA', 'shares': 100}>>>
练习 2.26:全局
使用本练习中的技术,可以编写语句,轻松地将几乎任何面向列的数据文件中的字段转换为 Python 字典。
为了说明,假设你像下面这样从不同的数据文件读取数据,如下所示:
>>> f = open('Data/dowstocks.csv')>>> rows = csv.reader(f)>>> headers = next(rows)>>> row = next(rows)>>> headers['name', 'price', 'date', 'time', 'change', 'open', 'high', 'low', 'volume']>>> row['AA', '39.48', '6/11/2007', '9:36am', '-0.18', '39.67', '39.69', '39.45', '181800']>>>
让我们使用类似的技巧来转换字段:
>>> types = [str, float, str, str, float, float, float, float, int]>>> converted = [func(val) for func, val in zip(types, row)]>>> record = dict(zip(headers, converted))>>> record{'volume': 181800, 'name': 'AA', 'price': 39.48, 'high': 39.69,'low': 39.45, 'time': '9:36am', 'date': '6/11/2007', 'open': 39.67,'change': -0.18}>>> record['name']'AA'>>> record['price']39.48>>>
附加题:如何修改本示例以进一步解析 date 条目到元组中,如(6, 11, 2007)?
请花一些时间仔细思考你在练习中所做的事情。我们稍后会再次讨论这些想法。

若有收获,就点个赞吧
0 人点赞
