Service
官方文档:https://kubernetes.io/zh/docs/concepts/services-networking/service/ 运行于Pod中的部分容器化应用是向客户端提供服务的守护进程,例如,nginx、tomcat等,他们受控于控制器资源对象,存在生命周期,在自愿或非自愿中断后只能被重构的新Pod对象所取代,每个Pod都有自己的IP弟子,而重构的新的Pod资源的IP地址等网络属性信息并不会固定,属于非可再生类的组件。于是,在动态、弹性的管理模型下,Service资源用于为此类Pod对象提供一个固定、统一的访问接口及负载均衡的能力,并支持借助于新一代DNS系统的服务发现功能,解决客户端发现并访问容器化应用的难题 然而,Service及Pod对象的IP地址都仅在K8S集群内可达,它们无法接入集群外部的访问流量,解决此类问题的办法中,除了在单一节点上做端口暴漏及让Pod资源共享使用节点的网络名称空间(hostNetwork)之外,更推荐用户使用的是NodePort或LoadBanlancer类型的Service资源,或者是有着七层负载均衡能力的Ingress资源
Service及其实现模型
Service是K8S的核心资源类型之一,通常可看作微服务的一种实现。事实上它是一种抽象:通过规则定义出由多个Pod对象组合而成的逻辑组合,以及访问这组Pod的策略。Service关联Pod资源的规则要借助于标签选择器来完成,这一点类似于前面讲到的Pod控制器
官网的解释:Kubernetes Service 定义了这样一种抽象:逻辑上的一组 Pod,一种可以访问它们的策略 —— 通常称为微服务。 这一组 Pod 能够被 Service 访问到,通常是通过 selector 实现的。 举个例子,考虑一个图片处理 backend,它运行了3个副本。这些副本是可互换的 —— frontend 不需要关心它们调用了哪个 backend 副本。 然而组成这一组 backend 程序的 Pod 实际上可能会发生变化,frontend 客户端不应该也没必要知道,而且也不需要跟踪这一组 backend 的状态。 Service 定义的抽象能够解耦这种关联。(大概的意思就是:我们运行了一个图片处理的程序,跑了3个副本,并且这些副本很有可能发生变化。前端的调用Pod不必要知道和不需要跟踪这一组图片处理程序的Pod的状态信息,因为Service能够解耦这种关联)
Service资源概述
由Deployment等控制器管理的Pod资源对象中断后会由新建的资源对象所取代,而扩缩容后的停用则会带来Pod资源对象群体的变动,随之变化的还有Pod的IP地址访问接口等,这也是编排系统之上的应用程序必然要面临的问题。例如下图中的Nginx Pod作为客户端访问tomcat Pod中的应用时,IP的变动或者应用规模的缩减都会导致客户端访问出错,而Pod规模的扩容又会使得客户端无法有效的使用新增的Pod对象,从而影响达成规模扩张的目的。为此,K8S也特地设计了Service资源来解决此类问题
service资源基于标签选择器将一组Pod定义成一个逻辑组合,并通过自己的IP地址和端口调度代理请求至组内的Pod对象之上,如下图所示,它像客户端隐藏了真实的、处理用户请求的Pod资源,使得客户端的请求看上去像是由Service直接处理并进行相应的一样
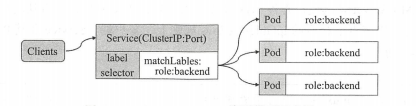
- Service对象的IP地址也称位ClusterIP,它位于为K8S集群指定专用IP地址的范围之内,而且是一种虚拟IP地址,它在Service对象创建后即保持不变,并且能够被同一集群中的Pod资源所访问。Service端口用于接收客户端请求并将其转发至后端的Pod中应用的相应端口,因此,这种代理机制也被称为“端口代理”或四层代理,它工作于TCP/IP协议栈的传输层
- 通过其标签选择器匹配匹配到的后端Pod资源不止一个时,Service资源能够以负载均衡的方式进行流量调度,实现了请求流量的分发机制。S二vice与Pod对象之间的关联关系也通过标签选择器以松耦合的方式建立,它可以先于Pod对象创建而不发生错误,于是,创建Service与Pod资源的任务可以由不同的用户分别完成,例如,服务架构的设计和创建由运维工程师进行,而填充其实现的Pod资源的任务则可由开发者进行。Service、控制器与Pod之间的关系图如下:
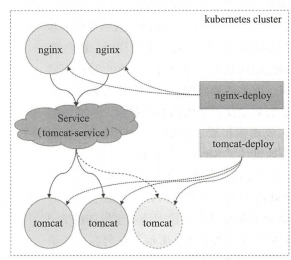
- Service资源会通过API Server持续监视着(watch)标签选择器匹配到的后端Pod对象,并实时跟踪各对象的变动,例如,IP地址变动,对象增加或者缺少等。不过,需要特别说明的是,Service并不直接链接至Pod对象,他们之间还有一个中间层——endpoints资源对象,它是一个由IP地址和端口组成的列表,这些IP地址和端口则来自于由Service的标签选择器匹配到的Pod资源。这也是很多场景中会使用service的后端端点(endpoints)这一术语的原因,创建Service资源对象时,其关联的endpoints对象会自动创建
虚拟IP和服务代理
简单来讲,一个Service对象就是工作节点上的一些iptables或ipvs规则,用于将到达Service对象IP地址的流量调度转发至相应的Endpoints对象指向的IP地址和端口之上。由于每个工作节点的kube-proxy组件通过API Server持续监控着各Service及与其关联的Pod对象,并将其创建或变动实时反映至当前工作节点上相应的iptables或ipvs规则上 Service IP事实上是用于生成iptables或ipvs规则时使用的ip地址,它仅用于实现K8S集群内部的网络通信,并且仅能够将规则中定义的转发服务的请求作为目标地址予以响应,这也是它被称为虚拟IP的原因之一。kube-proxy将请求代理至响应端点的方式有三种
- userspace:
- 此处的userspace是指linux操作的用户空间。这种模型中,kube-proxy负责跟宗API Server上的Service和Endpoint对象的变动(创建或删除),并根据此跟踪结果调整Service和Endpoint对象的定义。对于每个Service对象,它会随机打开一个本地端口(运行于用户空间的kube-proxy进程负责监听),任何到达此代理端口的连接请求都将被代理至当前Service资源后端的各Pod对象之上,至于会选中哪个Pod对象则取决于当前Service资源的调度方式,默认的调度算法是轮询。另外,此类的Service对象还会创建iptables规则以捕获任何到达clusterIP和端口的流量,在K8S 1.1版本之前userspace是默认的代理模型
- 这种代理模型中,请求流量到达内核空间后经由套接字送往用户空间的kube-proxy,而后再由它送回内核空间,并调度至后端Pod。这种方式中,请求在内核空间和用户空间来回转发必然会导致效率不高
- iptables代理模型
- 同前一种代理模型类似,iptables代理模型中,kube-proxy负责跟踪API Server上Service和Endpoints对象的变动(创建或删除),并根据此变动做出Service资源定义的变动。同时,对于每个Service,它都会创建iptables规则直接捕获到达clusterIP和port的流量,并将其重定向至当前Service的后端。对于每个Endpoints对象,Service资源会为其创建iptables规则并关联至挑选的后端Pod资源,默认算法是随机调度。iptables代理模式从1.1版本引入。使用 iptables 处理流量具有较低的系统开销,因为流量由 Linux netfilter 处理,而无需在用户空间和内核空间之间切换。 这种方法也可能更可靠。
- 在创建Service资源时,集群中每个节点上的kube-proxy都会收到通知并将其定义为当前节点上的iptables规则,用于转发工作接口接收到的与此Service资源的ClusterIP和端口的相关流量。客户端发来的请求都被相关的iptables规则进行调度和目标地址转换后再转发至集群内的Pod对象之上
- 相当于用户空间模型来说,iptables模型无须将流量在用户空间和内核空间来回切换,因为流量由Linux netfilter直接处理,因而更加高效和可靠。不过,其缺点是iptables代理模型不具备健康检测,iptables规则不会在被挑中的后端Pod资源无响应时自动进行重定向,而userspace模型则可以
- ipvs代理模型
- 此种模型中,kube-proxy跟踪API Server上Service和Endpoints对象的变动,并据此来调用netlink接口创建ipvs规则,并定期将ipvs规则确保与API Server中的变动保持同步。它与iptables规则的不同之处仅在请求流量的调度功能由ipvs实现,余下的其他功能任由iptables完成
- 类似于iptables模型,ipvs构建于netfilter的钩子函数之上,但它使用hash表作为底层数据结构并工作于内核空间,因此具有流量转发速度快,规则同步性能好的特性,与其他代理模式相比,IPVS 模式还支持更高的网络流量吞吐量。另外,ipvs还支持众多的调度算法,例如,rr,lc,dh,sh,sed和nq等

若有收获,就点个赞吧
0 人点赞
