1 前置知识
1.1 集群模式-哈希槽分区进行亿级数据存储
问题:1~2亿条数据需要缓存,请问如何设计这个存储案例
回答:单机单台100%不可行,肯定是使用分布式存储,使用redis落地
- 哈希取余分区(小厂)
- 一致性哈希算法分区(中厂)
- 哈希槽分区(大厂)
1.2 哈希取余分区
用户的每次读写操作都是根据公式:hash(key) % N个机器台数,计算出哈希值,用来决定数据映射到那一个节点上。
优点
实现简单。常用于数据库分库分表规则,通常先预先根据数据数量规划好区数,保证可以支撑一段时间,再根据负载情况将数据迁移到其他数据库中,扩容时通常采用翻倍扩容,这样大约只需迁移一半的数据量,从而避免映射全部被打乱导致全量迁移的情况。
缺点
在节点的数量变化时,如扩容或收缩节点时,数据节点映射关系需要重新计算,会导致大量数据重新迁移。
1.3 一致性哈希算法分区
设计目的是为了解决分布式缓存数据变动相映射问题,某个机器宕机了,分母数量改变了,自然取余数就不ok了。
一致性哈希分区实现思路是为系统中的每个节点分配一个token,范围是0~232-1,这些token构成一个哈希环。数据读写执行节点查找操作时,先根据key计算出哈希值,然后顺时针找到第一个遇到的token节点。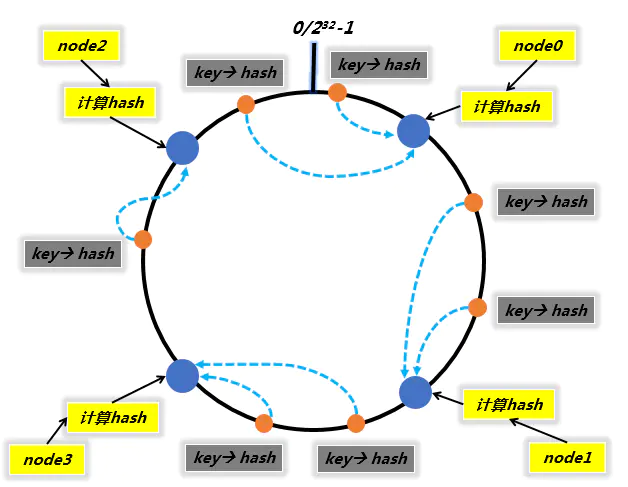
三大步骤
1 算法构建一致性哈希环
2 服务器ip节点映射
3 key落到服务器的落键规则
优点
- 容错性
- 扩张性
缺点
- 当使用少量节点时,节点变化将大范围的影响哈希环中的数据映射,因此这种方法不适合少量数据节点的分布式方案。
- 加减节点会造成哈希环中的部分数据无法命中,需要手动处理这部分数据。
- 由于哈希倾斜性(数据倾斜),当数据节点较少时,往往导致某个节点负载过大而其他节点负载过小,负载不均衡。
1.4 哈希槽分区
Redis Cluster采用的就是虚拟槽分区。虚拟槽分区巧妙的使用了哈希空间,使用分散度良好的哈希函数将所有的数据映射到一个固定范围的整数集合中,整数定义为槽(slot)。这个范围一般远远大于节点数,这是为了消除哈希的倾斜性,便于数据拆分和扩展。例如Redis Cluster槽的范围是0~16383。槽是集群内数据管理和迁移的基本单位,每个节点都会负责一定数量的槽。
由于采用了分散性较好的哈希函数,所有的数据大致均匀分布在0~16383各个槽中,计算公式为slot = CRC16(key) & 16383,当要操作数据时,只需要计算出相应的槽,并根据槽即可找到对应的节点。
特点
- 解耦数据和节点之间的关系,简化了节点的扩容和收缩。
- 解决了普通一致性哈希分区只有少量节点负载不均衡问题。
- 支持节点、槽、键之间的映射查询,用于数据路由。
2 docker实现哈希槽分区案例
// 1 启动6个redis容器实例// --net bridge、 none 、host:使用宿主机的ip和端口// --cluster-enabled 开启redis集群// --applyendonly 开启持久化// --port redis端口号docker run -d --name 容器名 --net 网络模式 -v 宿主机数据目录:/data --cluster-enabled yes --applyendonly yes --port 6381docker run -d --name redis-node-1 --net host -v /root/home/redis/node-1:/data redis --cluster-enabled yes --appendonly yes --port 6381docker run -d --name redis-node-2 --net host -v /root/home/redis/node-2:/data redis --cluster-enabled yes --appendonly yes --port 6382docker run -d --name redis-node-3 --net host -v /root/home/redis/node-3:/data redis --cluster-enabled yes --appendonly yes --port 6383docker run -d --name redis-node-4 --net host -v /root/home/redis/node-4:/data redis --cluster-enabled yes --appendonly yes --port 6384docker run -d --name redis-node-5 --net host -v /root/home/redis/node-5:/data redis --cluster-enabled yes --appendonly yes --port 6385docker run -d --name redis-node-6 --net host -v /root/home/redis/node-6:/data redis --cluster-enabled yes --appendonly yes --port 6386// 2 构建集群关系,三主三从// 2.1 进入容器/bin/bash,执行命令,构建集群// --cluster-replicas 1 表示为每个master创建一个slave节点,两两配对,一主一从redis-cli --cluster create [...宿主机ip:redis端口] --cluster-replicas 1;redis-cli --cluster create 192.168.203.166:6381 192.168.203.166:6382 192.168.203.166:6383 192.168.203.166:6384 192.168.203.166:6385 192.168.203.166:6386 --cluster-replicas 1;// 3 查看集群状态redis-cli -p 需要查看的端口redis > cluster info;redis > cluster nodes;// 4 主从容错切换迁移// 4.1 集群检查,查看集群信息--cluster check// 4.2 宕掉一个主机,从机自动上位docker stop 主机容器// 5 主从扩容案例// 5.1 启动2个redis容器实例docker run -d --name redis-node-7 --net host -v /root/home/redis/node-7:/data redis --cluster-enabled yes --appendonly yes --port 6387docker run -d --name redis-node-8 --net host -v /root/home/redis/node-8:/data redis --cluster-enabled yes --appendonly yes --port 6388// 5.2 进入7号机,将新增的6387节点作为master节点加入原集群redis-cli --cluster add-node ip:6387 ip:6381// 5.3 重新分配槽号redis-cli --cluster reshard ip:端口号// 5.4 集群检查redis-cli --cluster check ip:端口// 5.5 分配从节点6388给6387redis-cli --cluster add-node ip:6388 ip:6387 --cluster-slave --cluster-master-id 主机id// 6 主从缩容案例// 6.1 先删除从机,先获取从机节点idredis-cli --cluster del-node ip:端口 节点id// 6.2 重新分配槽号redis-cli --cluster reshard ip:端口号// 6.3 删除主机redis-cli --cluster del-node ip:端口号 节点id// 6.4 集群检查redis-cli --cluster check ip:端口
3 总结
弹性云的分配原理。

若有收获,就点个赞吧
0 人点赞
