上一篇我们讨论了如何利用 SQL 集合运算符(UNION [ALL]、INTERSECT 以及 EXCEPT)将多个查询结果合并成一个结果。
接下来我们介绍 SQL 中一个非常强大的功能:通用表表达式(Common Table Expression)。
表即变量
在编程语言中,通常会定义一些变量和函数(方法);变量可以被重复使用,函数(方法)可以将代码模块化并且提高程序的可读性与可维护性。
与此类似,SQL 中的通用表表达式能够实现查询结果的重复利用,简化复杂的连接查询和子查询;并且可以完成数据的递归处理和层次遍历。
以下是第 17 篇中的一个示例,利用子查询返回每个部门的平均月薪:
SELECT d.deptname AS “部门名称”, ds.avg_salary AS “平均月薪” FROM department d LEFT JOIN (SELECT dept_id, AVG(salary) AS avg_salary FROM employee GROUP BY dept_id) ds ON (d.dept_id = ds.dept_id); 复制
其中,子查询的结果 ds 相当于一个临时表。该查询的结果如下: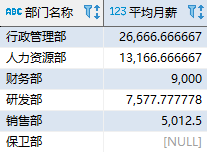
我们可以利用一个通用表表达式将该示例改写如下:
WITH ds(dept_id, avg_salary) AS ( SELECT dept_id, AVG(salary) AS avg_salary FROM employee GROUP BY dept_id ) SELECT d.dept_name AS “部门名称”, ds.avg_salary AS “平均月薪” FROM department d LEFT JOIN ds ON (d.dept_id = ds.dept_id); 复制
其中,WITH 关键字用于定义通用表表达式(CTE);它实际上是定义了一个临时结果集(表),名称为 ds;AS 关键字指定了 ds 的结构和数据,在这个示例中包含了每个部门的编号和平均月薪;最后在连接查询的 JOIN 子句中使用了临时表 ds。该语句的结果与上面的子查询示例相同,但是在逻辑上更加清晰。
WITH 子句相当于定义了一个变量,变量的值是一个表,所以称为通用表表达式。CTE 和子查询类似,可以用于 SELECT、INSERT、UPDATE 以及 DELETE 语句中。Oracle 中称之为子查询因子(subquery factoring)。
CTE 与子查询类似,只在当前语句中有效;一个语句中可以定义多个 CTE,而且 CTE 被定义之后可以多次引用。下面的示例中定义了 2 个 CTE:
WITH t1(n) AS ( SELECT 2 FROM employee WHERE emp_id = 1 ), t2(n) AS ( SELECT n + 1 FROM t1 ) SELECT t1.n, t2.n, t1.n t2.n FROM t1, t2; n|n|t1.n t2.n| -|-|—————-|_ 2|3| 6| 复制
第一个 CTE 名称为 t1,包含了一条记录(2);第二个 CTE 名称为 t2,引用了 t1 生成了一条记录(3);每个 CTE 之间使用逗号进行分隔;最后的 SELECT 语句使用前面定义的 2 个 CTE 进行连接查询,返回了所有的数据。这种使用临时表的方法和编程语言中的变量非常类似。
普通的通用表表达式可以将 SQL 语句进行模块化,便于阅读和理解;而递归形式的通用表表达式可以非常方便地遍历具有层次结构或者树状结构的数据,例如组织结构遍历和航班中转信息查询。
递归查询
通用表表达式支持在定义中调用自己,也就是实现编程中的递归调用。接下来我们就介绍一些常用的递归 CTE 案例。
生成数字序列
以下是一个简单的递归查询示例,该语句用于生成一个 1 到 10 的数字序列:
— MySQL 以及 PostgreSQL 实现 WITH RECURSIVE t(n) AS ( SELECT 1 UNION ALL SELECT n + 1 FROM t WHERE n < 10 ) SELECT n FROM t; — Oracle 以及 SQL Server 实现 WITH t(n) AS ( — Oracle 可以使用 SELECT 1 FROM dual SELECT 1 UNION ALL SELECT n + 1 FROM t WHERE n < 10 ) SELECT n FROM t; 复制
其中,RECURSIVE 关键字表示递归,Oracle 和 SQL Server 中不需要该关键字;递归 CTE 包含两部分,UNION ALL 中的第一个查询语句用于生成初始化数据,第二个查询语句引用了 CTE 自身( t )。该语句的执行过程如下:
- 运行初始化语句,生成数字 1;
- 第 1 次运行递归部分,此时 n 等于 1,返回数字 2( n+1 );
- 第 2 次运行递归部分,此时 n 等于 2,返回数字 3( n+1 );
- 第 9 次运行递归部分,此时 n 等于 9,返回数字 10( n+1 );
- 第 10 次运行递归部分,此时 n 等于 10;由于查询不满足条件( WHERE n < 10 ),不返回任何结果,并且递归结束;
- 最后的查询语句返回 t 中的全部数据,也就是一个 1 到 10 的数字序列。
该查询的结果如下:
显然,递归 CTE 非常合适用于生成具有某种规律的数字序列,例如斐波那契数列(Fibonacci series)。
斐波那契数列指的是这样一个数列:0、1、1、2、3、5、8、13、…。从数字 0 和 1 开始,每个数字都等于它前面的两个数字之和。如果递归查询中的每一行都基于前面的两个数值求和,就能生成一个斐波那契数列:
— MySQL 以及 PostgreSQL 实现 WITH RECURSIVE fibonacci (n, fibn, next_fib_n) AS ( SELECT 1, 0, 1 UNION ALL SELECT n + 1, next_fib_n, fib_n + next_fib_n FROM fibonacci WHERE n < 10 ) SELECT *FROM fibonacci; — Oracle 以及 SQL Server 实现 WITH fibonacci (n, fib_n, next_fib_n) AS ( — Oracle 使用 SELECT 1, 0, 1 FROM dual_ SELECT 1, 0, 1 UNION ALL SELECT n + 1, next_fib_n, fib_n + next_fib_n FROM fibonacci WHERE n < 10 ) SELECT *FROM fibonacci; 复制
该语句的执行过程如下:
- 初始化第一个斐波那契数列值。字段 fib_n 表示第 n 个斐波那契数列值,第 1 个值为 0;字段 next_fib_n 表示下一个斐波那契数列值,第 2 个数列值为 1;
- 第一次运行递归部分,字段 n 等于 2(1 + 1);字段 fib_n 的值为 1(上一次的 next_fib_n);字段 next_fib_n 的值为 1(0 + 1);
- 继续执行递归部分,字段 n 加上 1;使用上一条记录中的 next_fib_n 作为此次的斐波那契数列值,并且使用 fib_n + next_fib_n 作为下一个斐波那契数列值;
- 不断迭代该过程,当 n 到达 10 之后结束递归过程;
- 最后的查询语句返回所有的数列值。
该查询的结果如下: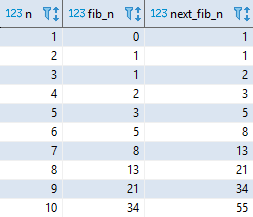
除了生成数字序列,递归 CTE 更实用的一个场景就是遍历层次结构或树状结构的数据。
遍历组织结构
我们知道,员工表(employee)中存储了员工的各种信息,包括员工编号、姓名以及员工经理的编号。公司的老板“刘备”没有上级,对应的经理为空。该公司的组织结构图如下: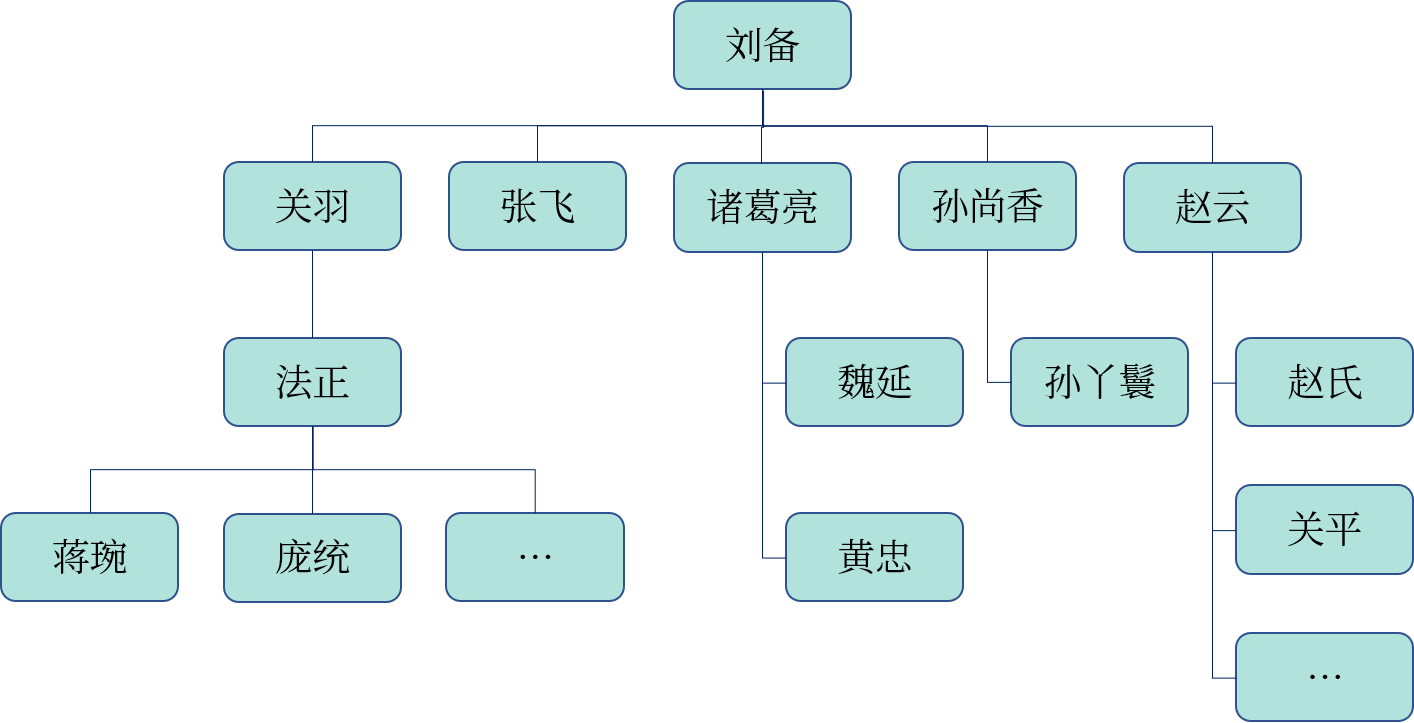
以下语句可以生成一个组织结构图,显示每个员工的从上到下的管理路径:
— MySQL 实现 WITH RECURSIVE employeepath (emp_id, emp_name, path) AS ( SELECT emp_id, emp_name, CAST(emp_name AS CHAR(1000)) AS path FROM employee WHERE manager IS NULL UNION ALL SELECT e.emp_id, e.emp_name, CAST(CONCAT(ep.path, ‘->’, e.emp_name) AS CHAR(1000)) FROM employee_path ep JOIN employee e ON ep.emp_id = e.manager ) SELECT FROM employee_path ORDER BY emp_id; 复制
employee_path 是一个递归的通用表表达式;其中的初始化部分用于查找上级经理为空的员工,也就是公司的老板:
SELECT emp_id, emp_name, cast(emp_name as CHAR(1000)) AS path FROM employee WHERE manager *IS NULL; emp_id|emp_name|path| ———|————|——|_ 1|刘备 |刘备 | 复制
“刘备”是公司的老板。以上语句中的 CAST 函数用于将 path 字段的长度修改为 1000,用于存储从上到下的管理路径。然后,第一次执行递归部分,将初始化的结果(employee_path)与员工表进行连接查询,找出“刘备”的所有直接下属员工: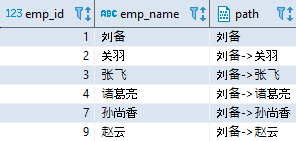
其中 CONCAT 连接函数用于将之前的管理路径加上当前员工的姓名,生成新的管理路径。
不断执行该过程继续返回其他的员工,直到不再返回新的员工为止。最终的查询结果如下(显示部分内容):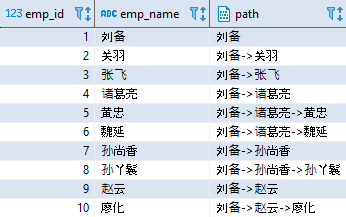
在 PostgreSQL 中需要将 CAST 函数里的 CHAR(1000) 改为 VARCHAR(1000);在 Oracle 以及 SQL Server 中需要将 CHAR(1000) 改为 VARCHAR(1000),同时省略 RECURSIVE 关键字。大家可以自行尝试编写相应的查询语句。
递归限制
通常来说,递归 CTE 的定义中需要包含一个终止递归的条件;否则的话,递归将会进入死循环。递归终止的条件可以是遍历完表中的所有数据,不再返回结果;或者是一个 WHERE 终止条件。
以下语句删除了上文生成数字序列的示例中的 WHERE 终止条件:
— MySQL 以及 PostgreSQL 实现 WITH RECURSIVE t (n) AS ( SELECT 1 UNION ALL SELECT n + 1 FROM t ) SELECT n FROM t; — Oracle 以及 SQL Server 实现 WITH t (n) AS ( — Oracle 使用 SELECT 1 FROM dual SELECT 1 UNION ALL SELECT n + 1 FROM t ) SELECT n FROM t; 复制
执行该语句时,Oracle 能够检测到查询语句中的问题并提示错误;MySQL 默认递归 1000 次后提示错误;SQL Server 默认递归 100 次后提示错误;PostgreSQL 没有进行控制,而是进入死循环。
小结
SQL 中的通用表表达式(CTE)相当于定义了一个表的变量,能够将复杂的查询结构化,并且实现结果集的重复利用。CTE 比子查询更易阅读和理解,递归 CTE 则提供了遍历层次数据和树状结构图的编程功能。
练习题 1:如何利用递归通用表表达式实现九九乘法表?
练习题 2:假如存在以下销售数据表 sales:
CREATE TABLE sales( id INT NOT NULL PRIMARY KEY, — 主键 saledate DATE NOT NULL, — 销售日期 amount INT NOT NULL — 销量 ); — 只有 Oracle 需要执行以下 alter 语句 — alter session set nls_date_format = ‘YYYY-MM-DD’; INSERT INTO sales VALUES(1, ‘2019-01-01’, 100); INSERT INTO sales VALUES(2, ‘2019-01-03’, 120); INSERT INTO sales VALUES(3, ‘2019-01-04’, 90); INSERT INTO sales VALUES(4, ‘2019-01-06’, 80); INSERT INTO sales VALUES(5, ‘2019-01-08’, 110); INSERT INTO sales VALUES(6, ‘2019-01-10’, 150); 复制
其中 2019 年 1 月 2 日、5 日、7 日以及 9 日没有销量。如何让查询的结果中显示出这些缺少的日期(销量显示为 0)?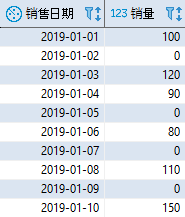

若有收获,就点个赞吧
0 人点赞
