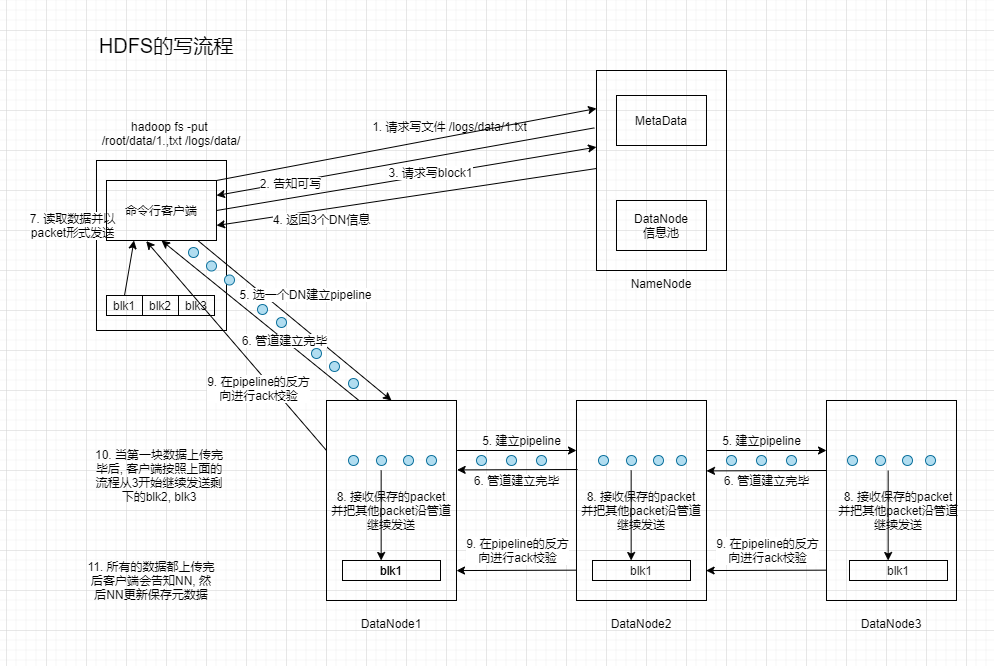
- Client与NameNode通信请求写文件, NameNode检查文件/目录与父目录是否存在
- NameNode返回信息确认是否可以上传
- Client确认上传的第一个Block该上传到哪些DataNode上
- NameNode返回A, B, C3个DataNode节点(3个副本). [1]
- Client请求3个DataNode的一个节点(A节点)来上传数据(本质是调用RPC建立Pipline), 接下来节点收到信息后调用B节点, 然后B调用C, 逐级建立Pipline, 真个Pipline建立后返回客户端.
- Client向A发送第一个Block(先从磁盘到本地缓存), 然后以Package为单位, A收到一个Package就会传给B, 然后B传给C, 每传一个Package都会放到一个队列里应答.
- 当一个Block传输完成后, Client再次请求NameNode上传第二个Block
- 重复上述步骤完成后, 关闭输出流, 发送完成信号给NameNode
[1] HDFS的三副本机制
第一个副本: 优先考虑Client所在的机器是否有DN, 如果有第一个就放本地, 如果不可用则选择一个距离客户端最近的机器.
第二个副本: 排除第一个副本所在机架的其他机架中随机选择一个可用的
第三个副本: 跟第二个相同机架的不同机器随机选个可用的
如果没有机架概念则进行策略降级: 第一个副本跟之前一样, 其他副本随机选择可用机器.

若有收获,就点个赞吧
0 人点赞
