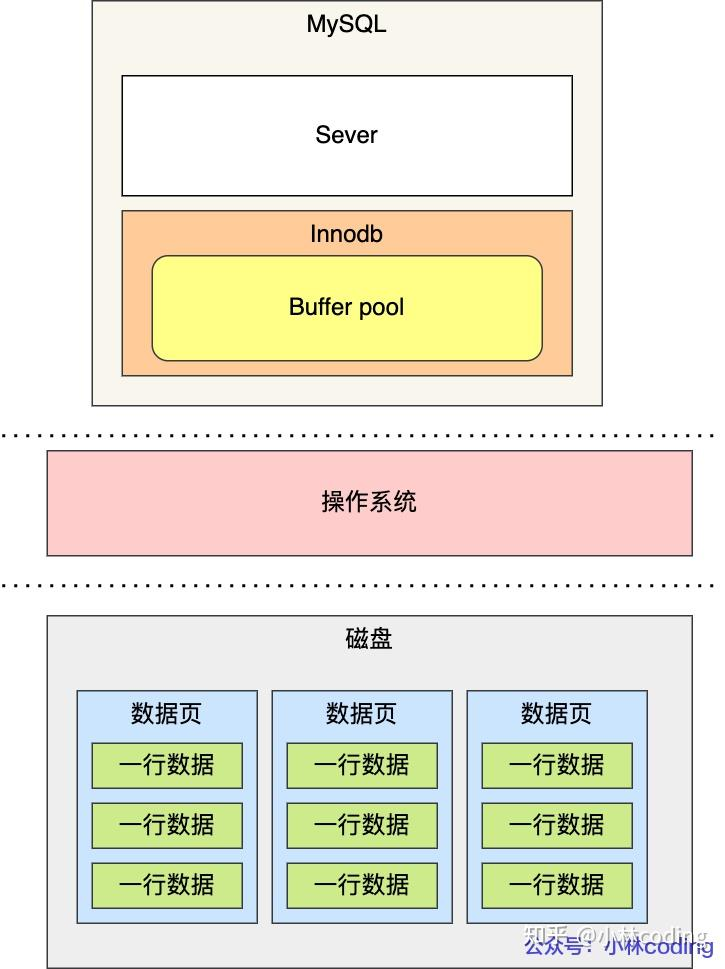
InnoDB
日志系统:一条SQL更新语句是如何执行的?
WAL
WAL与脏页
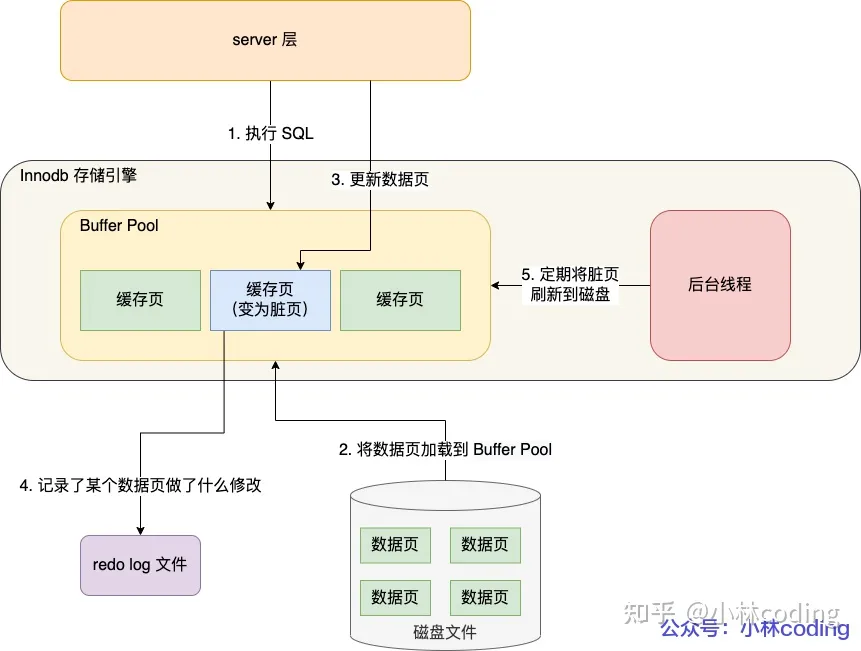
具体来说,当有一条记录需要更新的时候,InnoDB引擎就会先把记录写到redo log里面,并更新内存,这个时候更新就算完成了。
- 内存与磁盘不一致时, 内存中的Page叫做脏页
内存与磁盘一致时, 内存中的page是干净页 (脏页FLUSH之后就变成干净页了)
FLUSH
同时,InnoDB引擎会在适当的时候,将这个操作记录更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做 (FLUSH)
啥时候FLUSH
- Redo Log 满了
- 系统内存不足: 需要从磁盘读入PAGE时, 内存不足, 那么需要淘汰掉内存中老的Page, 如果淘汰的是脏页, 那么就需要FLUSH
- 系统空闲, 无事可做, 不如FLUSH
- 关闭MSQL
内存中的脏页比例
脏页刷太慢会怎么样? 生成脏页的速度大于FLUSH脏页的速度
无论是你的查询语句在需要内存的时候可能要求淘汰一个脏页,还是由于刷脏页的逻辑会占用IO资源并可能影响到了你的更新语句,都可能是造成你从业务端感知到MySQL“抖”了一下的原因。
要尽量避免这种情况,你就要合理地设置innodb_io_capacity的值,并且平时要多关注脏页比例,不要让它经常接近75%。
Redo Log VS Bin log
区别
| Redo Log | Bin Log |
|---|---|
| 实现了事务中的持久性,主要用于掉电等故障恢复; | 主要用于数据备份和主从复制 |
| InnoDB引擎特有 | MySQL的Server层实现的,所有引擎都可以使用 |
| redo log 是物理日志,记录的是 “在某个数据页上做了什么修改” | bin log 是逻辑日志,记录的是这个语句的原始逻辑,比如 “给 id = 1 这一行的 age 字段加 1” |
| redo log是循环写的,空间固定会用完 | “追加写”是指binlog文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。 |
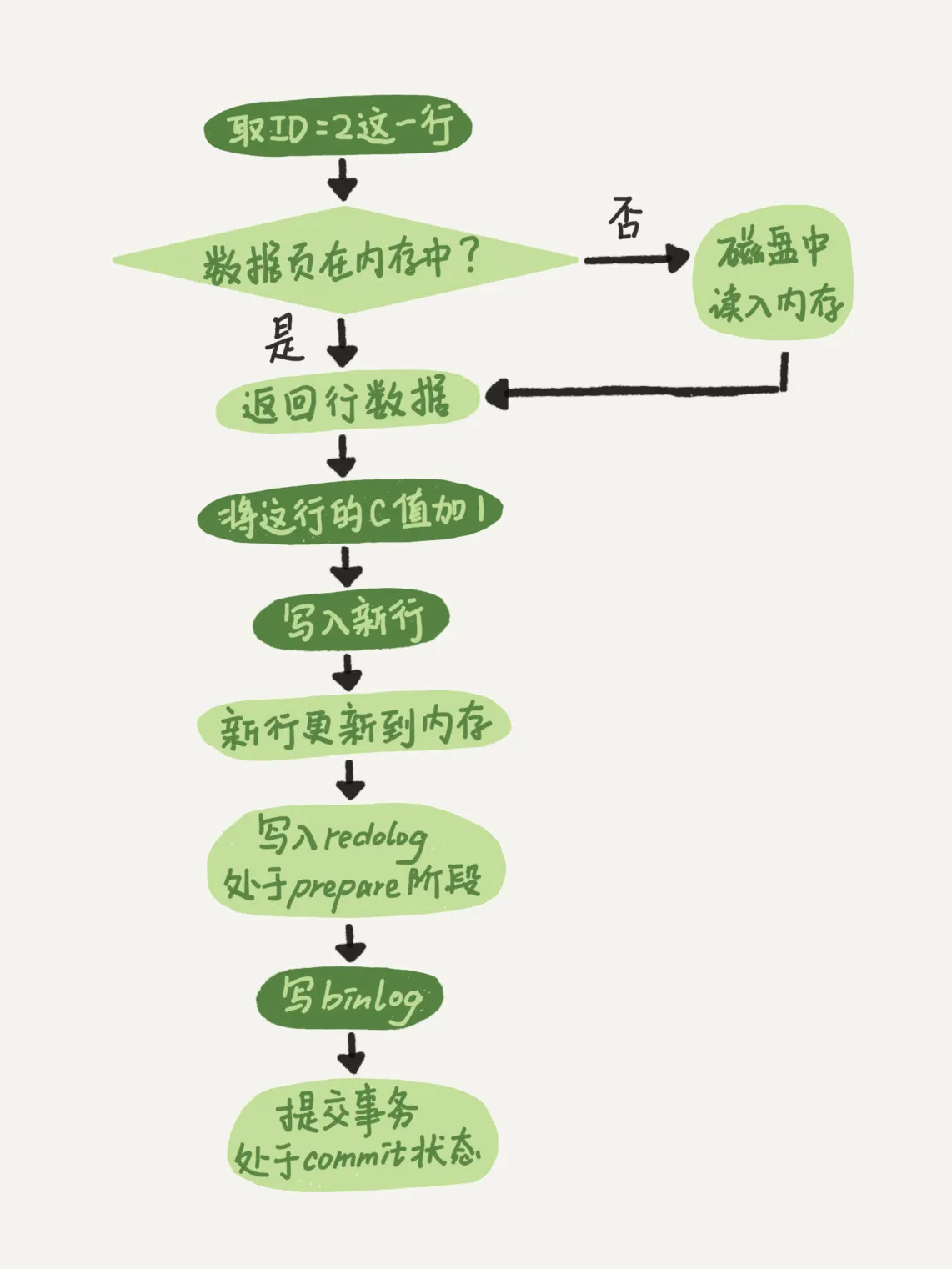
两阶段提交日志
Commit之前, 先写Redo Log, 再写BinLog
两阶段提交就是为了给所有人一个机会,当每个人都说“我ok”的时候,再一起提交。
按照Crash时机来探讨事务恢复: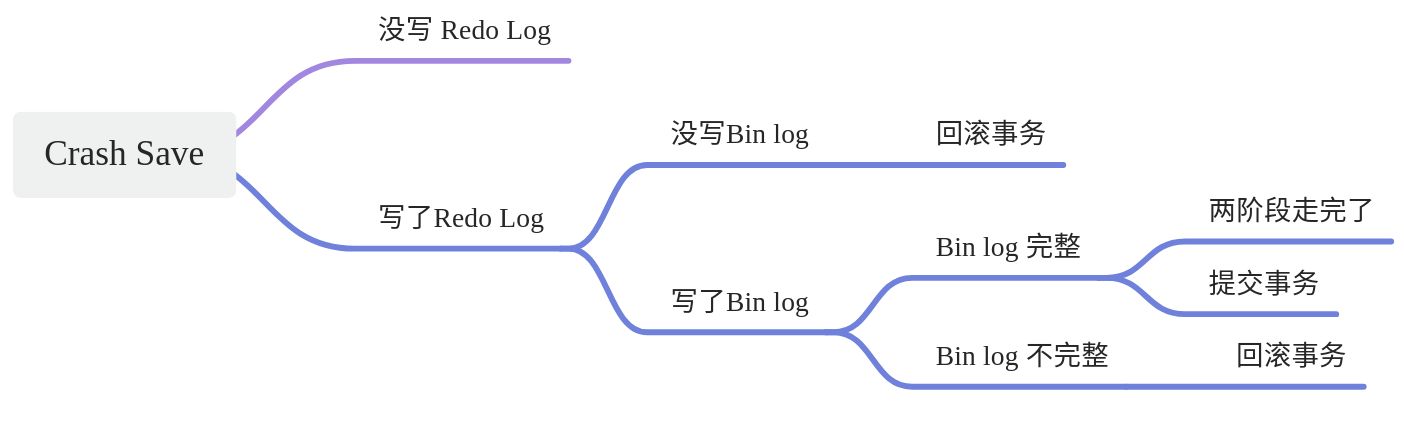
:::info
两阶段提交是如何保证binlog 与redo log一致的:
比如在redo log commit阶段之前(binlog落盘时/后)crash-recovery有两种逻辑,
- 一种是如果binlog是完整的,则commit;否则rollback。
- 判断binlog 是否完整,则是在binlog里面标记了一个全局唯一的xid,如果xid与redo log中的xid一致,就说明是完整的。
:::
Redo / Undo
:::info
redo log 和 undo log 区别在哪?
这两种日志是属于 InnoDB 存储引擎的日志,它们的区别在于:
redo log 记录了此次事务「完成后」的数据状态,记录的是更新之「后」的值;
undo log 记录了此次事务「开始前」的数据状态,记录的是更新之「前」的值;
事务提交之前发生了崩溃,重启后会通过 undo log 回滚事务,事务提交之后发生了崩溃,重启后会通过 redo log 恢复事务 :::
数据恢复
:::info Bin log可以做数据恢复吗?
bin log 是追加日志,保存的是全量的日志。这就会导致一个问题,那就是没有标志能让 InnoDB 从 bin log 中判断哪些数据已经刷入磁盘了,哪些数据还没有。举个例子,bin log 记录了两条日志:
记录 1:给 id = 1 这一行的 age 字段加 1
记录 2:给 id = 1 这一行的 age 字段加 1
假设在记录 1 刷盘后,记录 2 未刷盘时,数据库崩溃。重启后,只通过 bin log 数据库是无法判断这两条记录哪条已经写入磁盘,哪条没有写入磁盘,不管是两条都恢复至内存,还是都不恢复,对 id = 1 这行数据来说,都是不对的。但 redo log 不一样,只要刷入磁盘的数据,都会从 redo log 中被抹掉,数据库重启后,直接把 redo log 中的数据都恢复至内存就可以了。这就是为什么说 redo log 具有崩溃恢复的能力,而 bin log 不具备。
mysql 为什么不能用binlog来做数据恢复? - 飞天小牛肉的回答 - 知乎
https://www.zhihu.com/question/463438061/answer/2280710259
:::
:::info
如果不小心整个数据库的数据被删除了,能使用 redo log 文件恢复数据吗?
不可以使用 redo log 文件恢复,只能使用 binlog 文件恢复。
因为 redo log 文件是循环写,是会边写边擦除日志的,只记录未被刷入磁盘的数据的物理日志,已经刷入磁盘的数据都会从 redo log 文件里擦除。
binlog 文件保存的是全量的日志,也就是保存了所有数据变更的情况,理论上只要记录在 binlog 上的数据,都可以恢复,所以如果不小心整个数据库的数据被删除了,得用 binlog 文件恢复数据。 :::
参考:
事务隔离
MVCC
:::info 回滚日志总不能一直保留吧,什么时候删除呢?
答案是,在不需要的时候才删除。也就是说,系统会判断,当没有事务再需要用到这些回滚日志时,回滚日志会被删除。什么时候才不需要了呢?就是当系统里没有比这个回滚日志更早的read-view的时候。 :::
索引模型
- 哈希表
- 索引的范围查询很慢
- 有序数组
- 查询快
- 更新成本高
为了维持O(log(N))的查询复杂度,你就需要保持这棵树是平衡二叉树。为了做这个保证,更新的时间复杂度也是O(log(N))。
- 索引“覆盖了”我们的查询需求,我们称为覆盖索引
- 由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
- 前缀索引
- 索引下推优化(index condition pushdown)
- 可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
普通索引 change buffer
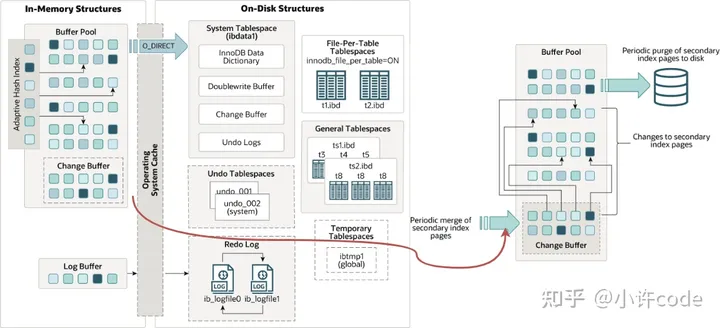
在做数据更新时
- 如果要更新的数据页还没读到内存中,那可以先把更新操作先存到change buffer中,节约到磁盘读取数据页的成本
- 将 change buffer 的操作更新到数据页,得到最新结果的过程叫做 merge
为啥唯一索引不用change buffer
- 新增一条唯一索引的记录,需要先把数据从磁盘查到内存,那直接再内存里更新数据就好了,不需要多走一道change buffer
change buffer 适用场景
- 适合写多读少
- 因为读少,所以数据页已经在内存中的概率也比较小,所以change buffer有用武之地
- 不适合先更新然后马上读
- 因为反正要从磁盘读数据页到内存,本可以直接操作数据页,而不用走change buffer绕远路,这也是唯一索引所在的场景
Redo log VS changer buffer
- change buffer减少的是随机读磁盘的消耗
- 存的是更新的这个操作,允许不读磁盘到内存,就可以记录更新
- 之后也还是要靠Redo做持久化的
- Redo log 减少的是随机写的消耗
- Redo Log是要持久化写磁盘的,只是说顺序写磁盘成本低
- 在事务提交的时候刷盘
- Redo Log满的时候会触发 changeBuffer Merge的逻辑
- Redo Log满会触发 FLUSH
- FLUSH就是要把脏页写入到磁盘
- 那肯定要先把change buffer的数据merge到内存Page里面才行
前缀索引
前缀索引
好处:
- 节省存储空间
坏处:
- 损失部分区分度来节省空间
- 无法使用覆盖索引
- 覆盖索引: 索引中包含了查询所需要的全部信息, 不用再索引回查
其他索引
身份证: 正序的前缀区分度较小:
- 倒序索引
- 落库的时候就倒序落库, 每次查询的时候先调用reverse函数
- Hash索引
- 表里面单独建一个储存hash值的字段
锁
全局锁
表级锁
- lock tables … read/write
MDL(metadata lock)
行锁的加锁时机
- 在InnoDB事务中,行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。这个就是两阶段锁协议
- 优化思路: 如果你的事务中需要锁多个行,要把最可能造成锁冲突、最可能影响并发度的锁的申请时机尽量往后放,这样占用这行的行锁的时间最短。
- 死锁
- 两个事务请求互相等待锁
- 这个互相等待也是因为,行锁是在需要的时候才加上,因此两个事务在一开始并不知道可能会互相等待锁
- 解法
- 超时自动释放锁: innodb_lock_wait_timeout
- 死锁检测: 强制回滚其中一个事务
- 两个事务请求互相等待锁
表的存储
数据的删除
行删除 / 页删除
- 行删除, 但页空间仍然占着, 下一个符合条件的数据可以插入这个空间
-
数据空洞
行删除之后的行空间可能永远不会再被写入数据
- 页分裂之后, 也可能出现永远不会被插入数据的空间
重建表
可以新建一个与表A结构相同的表B,然后按照主键ID递增的顺序,把数据一行一行地从表A里读出来再插入到表B中。由于表B是新建的表,所以表A主键索引上的空洞,在表B中就都不存在了。显然地,表B的主键索引更紧凑,数据页的利用率也更高。
alter table t engine=InnoDB
锁表 DDL
重建表时不允许数据写入
重建表的过程
- 原表A copy 到临时表tmp
- 将临时表作为新的表
ONLINE DDL
- 重建表的过程中,将所有对原表的操作记录在一个日志文件(row log)中
- 此时对表A上了一把MDL读锁
- 排斥其他DDL语句 Data Definition Language
- 但允许DML语句 Data Manipulation Language
- 此时对表A上了一把MDL读锁
- 新表建成之后, 将Row Log应用到新表上 (本质还是WAL的逻辑 )
ONLINE & INPLACE
整个DDL过程都在InnoDB内部完成。对于server层来说,没有把数据挪动到临时表,是一个“原地”操作,这就是“inplace”名称的来源。
SQL功能详解
Count()方法
:::info count(字段)<count(主键id)<count(1)≈count(*) :::
- count(字段)
- 遍历整张表, 取出这个字段
- 判断 字段 != null 的行数
- 非空字段 < 可空字段
- count(主键id)
- 遍历整张表, 取出主键ID
- 判断主键ID不为空的行数
- 主键ID是非空字段, 所以可以直接累加
- Count(1)
- 遍历整张表, 不用取任何值, 直接判断 1 != null
- Count(*)
- 不取值。count(*)肯定不是null,按行累加
Order BY
select city,name,age from t where city='杭州' order by name limit 1000 ;-- CITY 为索引, name 和 age 是普通字段
- 按照索引查询
- 到city的索引上取到id, 用于下一步的主键索引回查
- 索引自带顺序
- 假如有一个索引
city,name, name在索引中本来就是有序的, 那就不需要到sort_buffer 中排序了, 但还是要走一次主键索引回查
- 假如有一个索引
- 索引覆盖
- 假如有一个索引
city,name,age, 甚至都不需要主键索引回查了, 三个字段都索引覆盖了
- 假如有一个索引
- 主键索引回查, 获取select所需的所有信息
- max_length_for_sort_data定义了用于排序字段的长度
- 如果 city,name,age 加起来小于 max_length_for_sort_data, 则都取出来放到sort_buffer中
- 否则只取 name和ID, 到sort_buffer 中排序, 然后再多走一次主键索引回查取全量信息 (row_id排序)
- max_length_for_sort_data定义了用于排序字段的长度
- sort_buffer 中排序
- 内存够就在内存中排序
- 内存中不够就在磁盘文件中排序
如何从表里随机取三行
mysql> CREATE TABLE `words` (`id` int(11) NOT NULL AUTO_INCREMENT,`word` varchar(64) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB;
Words表中有10000个单词 随机取三个
order by rand()
mysql> select word from words order by rand() limit 3;
- 建一个内存临时表,
- 有两列,R(DOUBLE):代表随机生成的一个数字,W(String):代表单测
- 对Words表全表扫描,把所有行写进临时内存表
- 初始化Sort buffer
- 也有两列R:临时内存表中的随机数字那一列,POS(INT):代表这一行在临时内存表的位置信息,也就是行数
- 对内存临时表全表扫描,把所有行写进sort buffer
- 在sort buffer 中排序
- 去前三个结果信息,到临时内存表中取结果,返回客户端
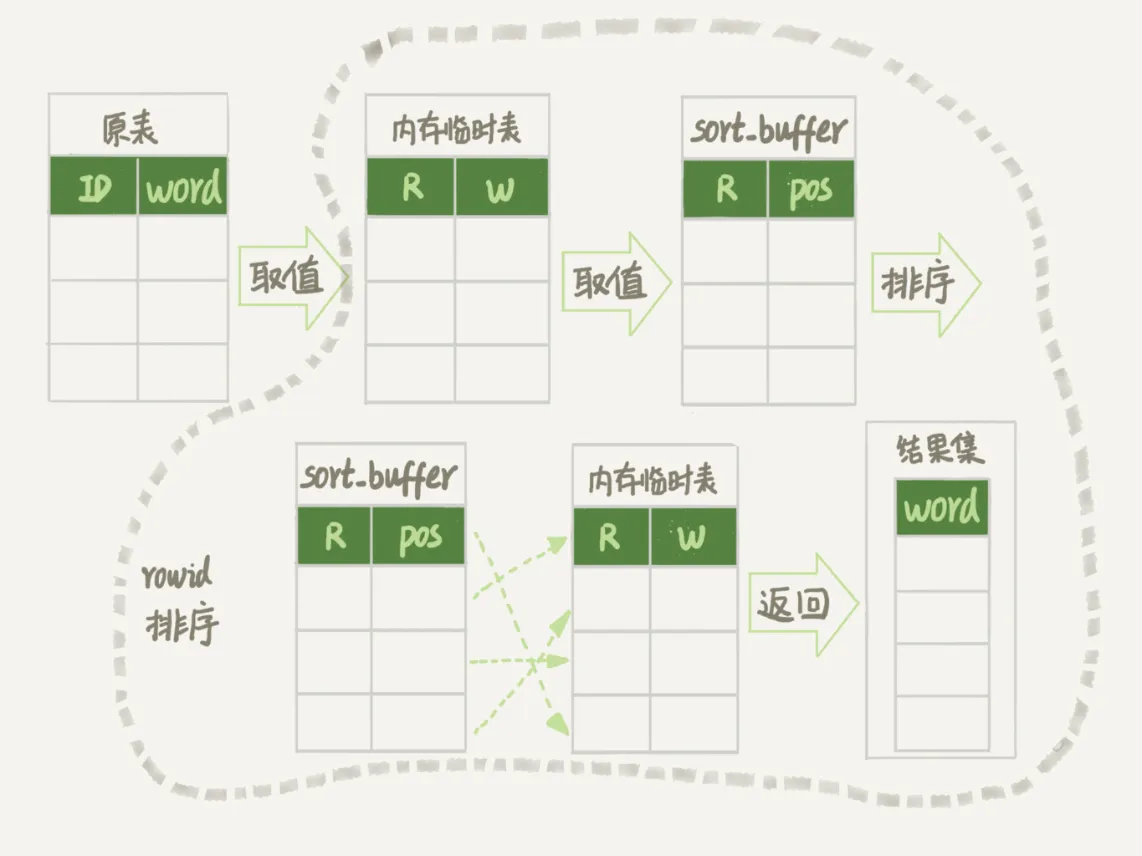
磁盘临时表 VS 内存临时表
tmp_table_size这个配置限制了内存临时表的大小,默认值是16M。如果临时表大小超过了tmp_table_size,那么内存临时表就会转成磁盘临时表。
优先队列排序算法 VS 归并排序算法
这个算法其实很没有必要,因为我们只要随机取三个,却做了两次全表扫描,而且对全表进行了排序,但实际上后面9997行的排序完全没有必要
可以使用优先队列算法,维护三个元素的堆,遍历一遍内存临时表,用堆里的最大值和每一个行的R做比较,如果这一行的R更小,就换到堆里面来。这样遍历完之后,R最小的三行就在这个堆里面了
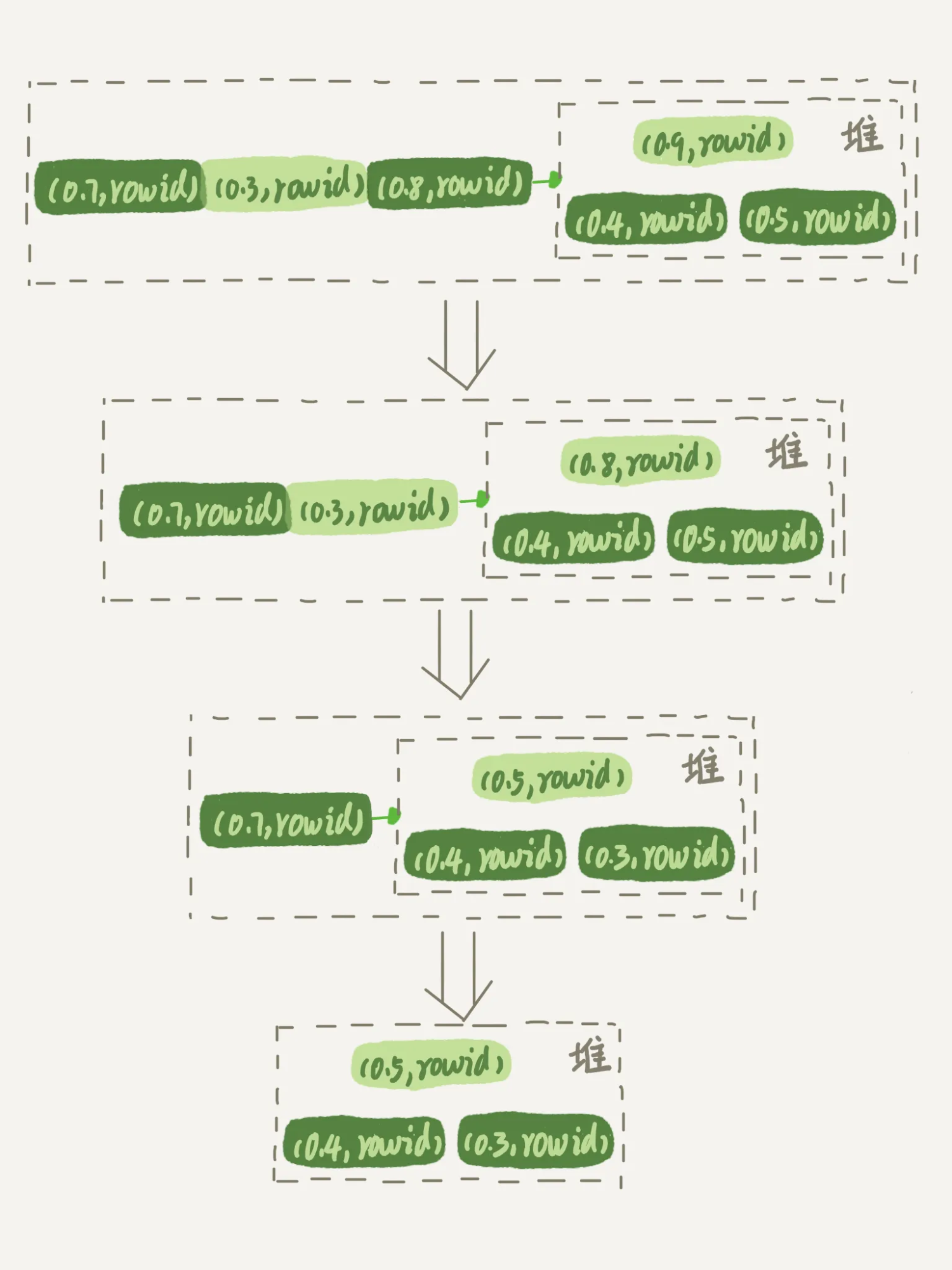
但是还是不推荐用数据库做随机算法:
在实际应用的过程中,比较规范的用法就是:尽量将业务逻辑写在业务代码中,让数据库只做“读写数据”的事情。因此,这类方法的应用还是比较广泛的。

若有收获,就点个赞吧
0 人点赞
