JavaSE
集合
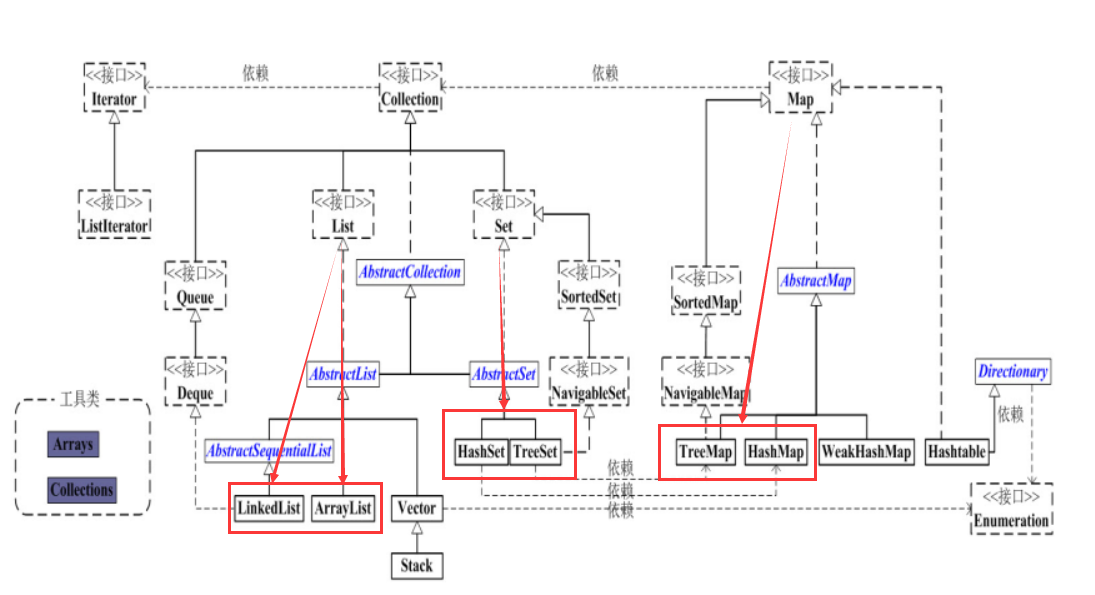
Map
hashmap底层原理
Jdk1.8之前:数组+链表 结合在一起使用的 也就是 链表散列,map通过key的hashcode经过扰动函数处理过后得到hash值,然后在通过(n-1)&hash 得到当前元素存放的位置,如果该位置存在元素或者链表结构,元素就判断hash和key的值是否相同。链表也是要循环判断,如果相同就覆盖,不同就通过链表的形式插入。
其中扰动函数:将计算的hash值异或hash值进行右移动十六位的二进制,使其高16位和低16位进行与运算,主要为了加大低16位的随机性。
(n-1)&hash:计算的前提n必须是偶数,这样计算的原因有两点:
1. hash%length==hash&(length-1) 这个公式在length是偶数情况下相等 位运算比较快。
2. 减少碰撞几率,比如长度是奇数 3&(9-1)=0 2&(9-1)=0 产生碰撞了,如果偶数3&(8-1)=3 2&(8-1)=2 不同位置了
& 与 (都是1时,结果才为1)
^ 异或 (只要一样结果就是0)
扩容机制:负载因子0.75 达到总长度*0.75时,扩容二倍 需要重新计算所有元素的下标。
Jdk1.8之后 首先添加了红黑树 当链表大于8的时候 添加一个红黑树,为了搜索更快,
对扩容有了优化 不提这个。不清楚这个。
红黑树哎!!!
ConcurrentHashMap
Jdk1.8:数据结构是 数组+链表+红黑树。使用Unsafe类的CAS自旋锁和synchronized和lockSupport进行同步并发的。
LinkedHashMap
TreeMap
有序的键值对存储,底层用的红黑树结构,插入的对象 必须实现Comparable接口,告诉比较的方式。
List
ArrayList
是Collection接口的子类,底层是Object的数组结构,默认大小是10
扩容机制:
创建新的数组大小 扩容一般是1.5倍大小的数组。可以通过下标直接获取元素。
添加元素需要搞顺移。
LinkedList
双向链表,元素存放在node对象中,每个node对象都有前一个和后一个的引用,抽象的讲 所有的node都连起来了,添加和删除元素时 改变前后的引用节点就可以,因为是连接起来的内存上不是连续的所以查询的时候就需要遍历了。
Set
HashSet
TreeSet
皮包公司TreeMap

若有收获,就点个赞吧
0 人点赞
