定义
人工智能:为机器赋予人的智能
早在1956年夏天那次会议,人工智能的先驱们就梦想着用当时刚刚出现的计算机来构造复杂的、拥有与人类智慧同样本质特性的机器。这就是我们现在所说的“强人工智能”(General AI)。这个无所不能的机器,它有着我们所有的感知(甚至比人更多),我们所有的理性,可以像我们一样思考。
我们目前能实现的,一般被称为“弱人工智能”(Narrow AI)。弱人工智能是能够与人一样,甚至比人更好地执行特定任务的技术。例如,Pinterest上的图像分类;或者Facebook的人脸识别。这些是弱人工智能在实践中的例子。这些技术实现的是人类智能的一些具体的局部。但它们是如何实现的?这种智能是从何而来?这就带我们来到下一层,机器学习。
机器学习:一种实现人工智能的方法
机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。机器学习是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。
机器学习最基本的做法,是使用算法来解析数据、从中学习,然后对真实世界中的事件做出决策和预测。与传统的为解决特定任务、硬编码的软件程序不同,机器学习是用大量的数据来“训练”,通过各种算法从数据中学习如何完成任务。
机器学习最成功的应用领域是计算机视觉,虽然也还是需要大量的手工编码来完成工作。人们需要手工编写分类器、边缘检测滤波器,以便让程序能识别物体从哪里开始,到哪里结束;写形状检测程序来判断检测对象是不是有八条边;写分类器来识别字母“STOP”。使用以上这些手工编写的分类器,人们总算可以开发算法来感知图像,判断图像是不是一个停止标志牌。
机器学习有三类:
第一类是无监督学习,指的是从信息出发自动寻找规律,并将其分成各种类别,有时也称”聚类问题”。
第二类是监督学习,监督学习指的是给历史一个标签,运用模型预测结果。如有一个水果,我们根据水果的形状和颜色去判断到底是香蕉还是苹果,这就是一个监督学习的例子。
最后一类为强化学习,是指可以用来支持人们去做决策和规划的一个学习方式,它是对人的一些动作、行为产生奖励的回馈机制,通过这个回馈机制促进学习,这与人类的学习相似,所以强化学习是目前研究的重要方向之一。
深度学习:一种实现机器学习的技术
机器学习同深度学习之间是有区别的,机器学习是指计算机的算法能够像人一样,从数据中找到信息,从而学习一些规律。虽然深度学习是机器学习的一种,但深度学习是利用深度的神经网络,将模型处理得更为复杂,从而使模型对数据的理解更加深入。
深度学习是机器学习中一种基于对数据进行表征学习的方法。深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。
同机器学习方法一样,深度机器学习方法也有监督学习与无监督学习之分。不同的学习框架下建立的学习模型很是不同。例如,卷积神经网络(Convolutional neural networks,简称CNNs)就是一种深度的监督学习下的机器学习模型,而深度置信网(Deep Belief Nets,简称DBNs)就是一种无监督学习下的机器学习模型。
数据挖掘:从大量的数据中通过算法搜索隐藏于其中信息的技术
数据挖掘是人工智能和数据库领域研究的热点问题,所谓数据挖掘是指从数据库的大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的非平凡过程。数据挖掘是一种决策支持过程,它主要基于人工智能、机器学习、模式识别、统计学、数据库、可视化技术等,高度自动化地分析企业的数据,作出归纳性的推理,从中挖掘出潜在的模式,帮助决策者调整市场策略,减少风险,作出正确的决策。知识发现过程由以下三个阶段组成:①数据准备;②数据挖掘;③结果表达和解释。数据挖掘可以与用户或知识库交互。
自然语言处理
自然语言处理是指利用人类交流所使用的自然语言与机器进行交互通讯的技术。通过人为的对自然语言的处理,使得计算机对其能够可读并理解。自然语言处理的相关研究始于人类对机器翻译的探索。虽然自然语言处理涉及语音、语法、语义、语用等多维度的操作,但简单而言,自然语言处理的基本任务是基于本体词典、词频统计、上下文语义分析等方式对待处理语料进行分词,形成以最小词性为单位,且富含语义的词项单元。
发展阶段
- 早期自然语言处理:基于规则
- 统计自然语言处理:基于统计的机器学习
-
深度学习在NLP上的应用
文本分类
对于给定的文本例子,预测一个预先定义的类标签。文本分类的目标是对文档的主题或主旨进行分类。
情感分析是很流行的一个分类例子,其中类标签代表源文本的情感色调,如“积极的”或“消极的” 垃圾邮件过滤,将电子邮件文本分类为垃圾邮件或非垃圾邮件。
- 语言识别,对源文本的语言类型进行分类。
- 流派分类,对虚构故事的流派进行分类。
相关论文:
烂番茄电影评论的情感分析。
Deep Unordered Composition Rivals Syntactic Methods for Text Classification,2015。
亚马逊产品评论和 IMDB 电影评论的情感分析,以及新闻文章的话题分类。
Effective Use of Word Order for Text Categorization with Convolutional Neural Networks,2015。
电影评论的情绪分析,将句子分类为主观或客观,问题类型分类,产品评论的情绪分析,等等。
Convolutional Neural Networks for Sentence Classification,2014。
语言模型
语言模型是很多有趣的自然语言问题的子任务,特别是那些根据输入调节语言模型的问题。
这个问题是在已知前几个的单词的情况下预测下一个词。该任务对语音或光学字符识别非常重要,也被用于拼写检查、手写识别和统计机器翻译。
单独来看,语言模型可被用于文本或语音生成,譬如:
- 生成新的文章标题。
- 生成新的句子、段落或文档。
-
语音识别
语音识别的任务在于,将包含自然语言话语的声学信号映射到与说话者预期的相应的单词序列中。
给定发声的文本作为音频数据,该模型必须产生人类可读的文本。
鉴于该过程的自动性质,该问题也可被称为自动语音识别(ASR)。
语言模型被用于创建基于音频数据的文本输出。
英文语音到文字的论文 Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks,2006。
- Speech Recognition with Deep Recurrent Neural Networks,2013。
Exploring convolutional neural network structures and optimization techniques for speech recognition,2014。
说明生成
说明生成指的是描述图片内容的一类问题。即,给定一个数字图像,如图片,生成关于该图像内容的文字描述。语言模型被用于创建基于图像的说明。
例子包括:描述场景内容
- 为图片生成说明
- 描述视频
相关论文:
为图片生成说明
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention,2016
为图片生成说明
Show and tell: A neural image caption generator,2015
为视频生成字幕
Sequence to Sequence – Video to Text,2015
机器翻译
机器翻译解决将一种语言的源文本转换为另一种语言的问题。
机器翻译将文本或语音从一种语言自动翻译成另一种语言,它是 NLP 最重要的应用之一。
鉴于使用了深层神经网络,该领域被称为神经机器翻译。
在机器翻译任务中,输入已经由某种语言的符号序列组成,计算机程序必须将其转换为另一种语言的一系列符号。这通常适用于自然语言,譬如从英语翻译成法语。深度学习最近开始对这种任务产生重要影响。
基于源文本,语言模型用于输出以第二语言表示的目标文本。
机器翻译软件在世界各地使用,尽管有限制。在某些领域,翻译质量不好。为了改进结果,研究人员尝试不同的技术和模型,包括神经网络方法。《Neural-based Machine Translation for Medical Text Domain》研究的目的是检查不同训练方法对用于,采用医学数据的,波兰语-英语机器翻译系统的影响。采用The European Medicines Agency parallel text corpus来训练基于神经网络和统计机器翻译系统。证明了神经网络需要较少的训练和维护资源。另外,神经网络通常用相似语境中出现的单词来替代其他单词。
相关论文:
将英文文字翻译成法文
Sequence to Sequence Learning with Neural Networks,2014
Neural Machine Translation by Jointly Learning to Align and Translate,2014
Joint Language and Translation Modeling with Recurrent Neural Networks,2013
文本摘要
文本摘要的任务是为文本文档创建短的描述。
如上所述,应用一个语言模型来输出对全文档的总结。
文本摘要的例子包括:
为文档创建标题
为文档创建摘要
相关论文:
总结新闻文章中的句子
A Neural Attention Model for Abstractive Summarization,2015
Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond,2016
Neural Summarization by Extracting Sentences and Word,2016
问答系统
分为任务驱动的问答系统(如siri,医疗辅助问答系统等)和基于知识的开放型问答系统(如聊天机器人)
语义分析
任何对语言的理解都可以归为语义分析的范畴。一段文本通常由词、句子和段落来构成,根据理解对象的语言单位不同, 语义分析又可进一步分解为词汇级语义分析、句子级语义分析以及篇章级语义分析。语义分析的目标就是通过建立有效的模型和系统, 实现在各个语言单位 (包括词汇、句子和篇章等) 的自动语义分析,从而实现理解整个文本表达的真实语义。
对于不同的语言单位,语义分析的任务各不相同。在词的层次上,语义分析的基本任务是进行词义消歧(WSD),在句子层面上是语义角色标注(SRL),在篇章层面上是指代消歧,也称共指消解。
词义消歧
由于词是能够独立运用的最小语言单位,句子中的每个词的含义及其在特定语境下的相互作用构成了整个句子的含义,因此,词义消歧是句子和篇章语义理解的基础,词义消歧有时也称为词义标注,其任务就是确定一个多义词在给定上下文语境中的具体含义。词义消歧的方法也分为有监督的消歧方法和无监督的消歧方法,在有监督的消歧方法中,训练数据是已知的,即每个词的词义是被标注了的;而在无监督的消歧方法中,训练数据是未经标注的。 多义词的词义识别问题实际上就是该词的上下文分类问题,还记得词性一致性识别的过程吗,同样也是根据词的上下文来判断词的词性。有监督词义消歧根据上下文和标注结果完成分类任务。而无监督词义消歧通常被称为聚类任务,使用聚类算法对同一个多义词的所有上下文进行等价类划分,在词义识别的时候,将该词的上下文与各个词义对应上下文的等价类进行比较,通过上下文对应的等价类来确定词的词义。此外,除了有监督和无监督的词义消歧,还有一种基于词典的消歧方法。
在词义消歧方法研究中,我们需要大量测试数据,为了避免手工标注的困难,我们通过人工制造数据的方法来获得大规模训练数据和测试数据。其基本思路是将两个自然词汇合并,创建一个伪词来替代所有出现在语料中的原词汇。带有伪词的文本作为歧义原文本,最初的文本作为消歧后的文本。
相关论文:
Semantic Parsing via Staged Query Graph Generation Question Answering with Knowledge Base
相关技术
神经网络语言模型(NNLM)
神经网络语言模型(Neural Network Language Model,NNLM)最早由 Bengio 等人[27]提出,其核心思路是用一个 K 维的向量来表示词语,被称为词向量( Word Embedding),使得语义相似的词在向量空间中处于相近的位置,并基于神经网络模型将输入的上下文词向量序列转换成成固定长度的上下文隐藏向量,使得语言模型不必存储所有不同词语的排列组合信息,从而改进传统语言模型受词典规模限制的不足。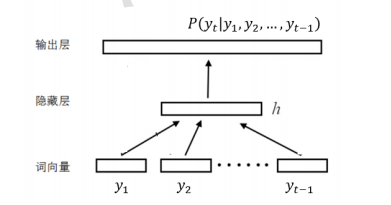
自编码器(AE)
自编码器(Autoencoder, AE)是一种无监督的学习模型,由 Rumelhart 等人[28]最早提出。自编码器由编码器和解码器两部分组成,先用编码器对输入数据进行压缩,将高维数据映射到低维空间,再用解码器解压缩,对输入数据进行还原,从而来实现输入到输出的复现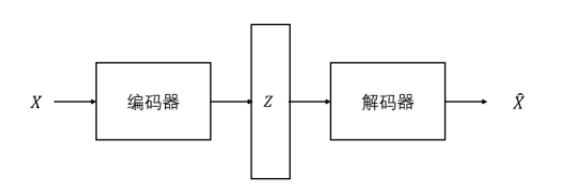
卷积神经网络(CNN)
核心思想是设计局部特征抽取器运用到全局,利用空间相对关系共享参数,来提高训练性能。
卷积层和池化层是卷积神经网络的重要组成部分。其中,卷积层的作用是从固定大小的窗口中读取输入层数据,经过卷积计算,实现特征提取。卷积神经网络在同一层共享卷积计算模型来控制参数规模,降低模型复杂度。池化层的作用是对特征信号进行抽象,用于缩减输入数据的规模,按一定方法将特征压缩。池化的方法包括加和池化、最大池化、均值池化、最小值池化和随机池化。最后一个池化层通常连接到全连接层,来计算最终的输出。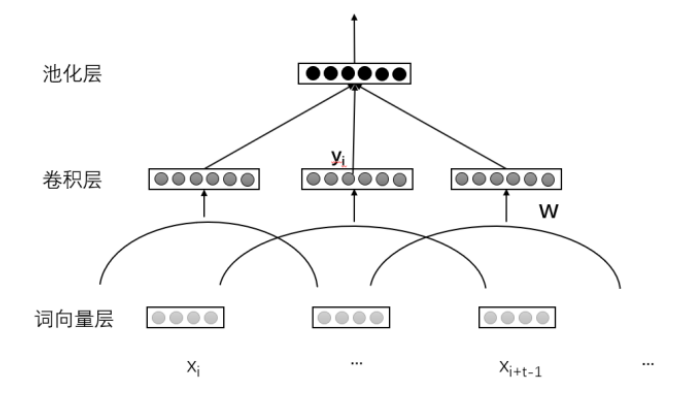
循环神经网络(RNN)
自环的网络对前面 的信息进行记忆并应用于当前输出的计算中,即当前时刻隐藏层的输入包括输入层变量和上一时刻的隐藏层变量。
由于可以无限循环,所以理论上循环神经网络能够对任何长度的序列数据进行处理。
循环神经网络在实际应用时有梯度消失等问题。后来提出了LSTM和GRU解决这一问题。
Seq2Seq
编码器-解码器模型
输入一个序列,输出另一个序列。
基本模型利用两个RNN:一个循环神经网络作为编码器,将输入序列转换成定长的向量,将向量视为输
入序列的语义表示;另一个循环神经网络作为解码器,根据输入序列的语义表示生成输出序列。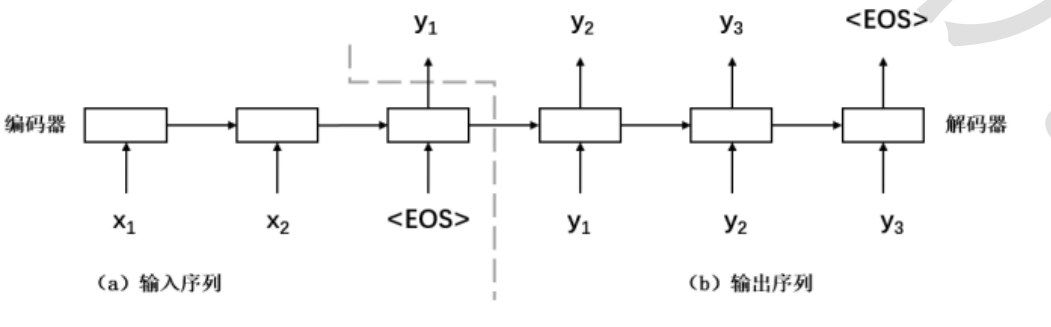
注意力机制
注意力机制可以理解为回溯策略。它在当前解码时刻,将解码器 RNN 前一个时刻的隐藏向量与输入序列关联起来,计算输入的每一步对当前解码的影响程度作为权重。通过 softmax 函数归一化,得到概率分布权重对输入序列做加权,重点考虑输入数据中对当前解码影响最大的输入词。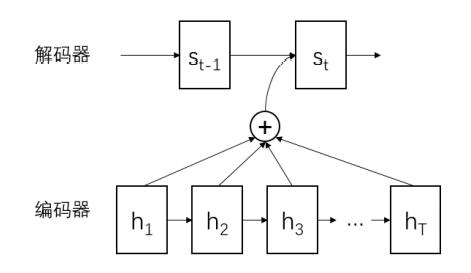
自注意力机制,多头注意力机制
强化学习
观察值,奖励,动作一起构成智能体的经验数据。
智能体的目标是依据经验获取最大累计奖励。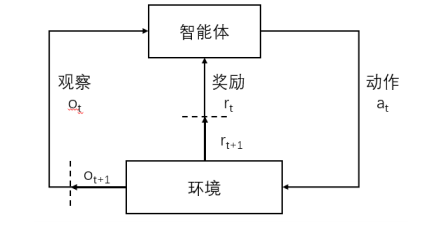
Transformer模型
Paper List
机器学习
对话系统
- Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. In Advances in neural information processing systems (pp. 3104-3112).
- Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
自然语言处理发展及其综述
自然语言处理发展及应用综述.pdf
Natural Language Processing Advancements By Deep Learning:A Survey.pdf
对话系统发展综述
cc-2019328162246.pdf
让机器具备与人交流的能力是人工智能领域的一项重要工作,同时也是一项极具挑战的任务。1951 年图灵在《计算机与智能》一文中提出用人机对话来测试机器智能水平,引起了研究者的广泛关注。此后,学者们尝试了各种方法研究建立对话系统。按照系统建设的目的,对话系统被分为任务驱动的限定领域对话系统和无特定任务的开放领域对话系统。限定领域对话系统是为了完成特定任务而设计的,例如网站客服、车载助手等。开放领域对话系统也被称为聊天机器人,是无任务驱动,为了纯聊天或者娱乐而开发的,它的目的是生成有意义且相关的回复。
推荐系统研究综述
思考:
为什么深度学习能高效促进NLP发展?
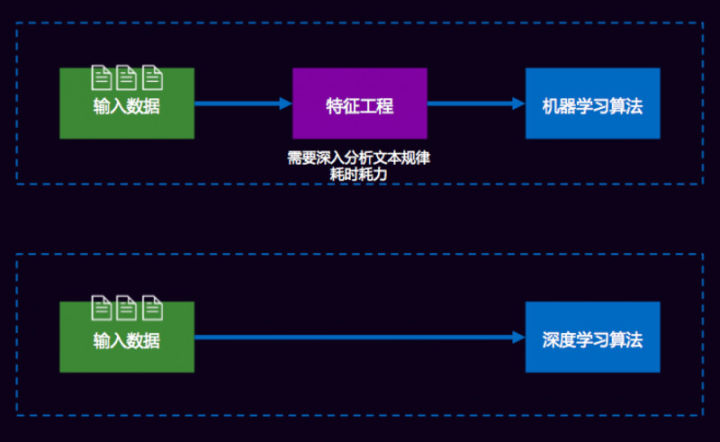
比如做一个分类的问题,这两个分类问题唯一的区别就是特征工程的区别。我们用经典的机器学习算法是上面这条路,输入数据后大家就开始(包括打比赛也)做各种各样的特征工程。有了这样的特征,我们还要根据TF-IDF、互信息、信息增益等各种各样的方式去算特征值,或对特征进行过滤排序。传统机器学习或经典机器学习90%的时间都会花在特征工程上。
而Deep learning颠覆了这个过程,不需要做特征工程。需要各种各样的特征,比如需要一些长时间依赖的特征,那可以用RNN、LSTM这些,让它有个序列的依赖;可以用局部的特征,用各种各样的N元语法模型,现在可以用CNN来提取局部的文本特征。
深度学习节省的时间是做特征工程的时间,这也是非常看重深度学习的原因:
第一,特征工程做起来很累。
第二,很多实际场景是挖掘出一个好的特征或者对我们系统贡献很大的特征,往往比选择算法影响还大。用基本的特征,它的算法差距不会特别大,最多也就10个点,主要还是特征工程这块,而深度学习很好的解决了这个问题。
有了深度学习之后,对文本挖掘就有了统一处理的框架,达观把它定义为五个过程: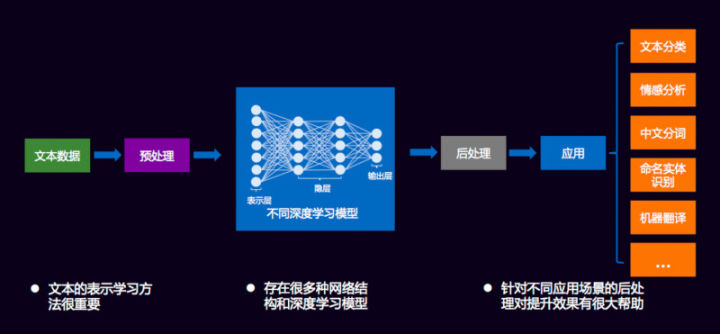
为什么深度学习在NLP的应用不像在计算机视觉的应用那么成功?
目前cv领域有很多工业化应用,而nlp很多处于实验室toy的阶段。相比之下,在工业界应用较少。
1) 过去几年CV领域爆点,与NLP领域的主攻问题相比,是不同的智能认知阶段;
2) 而过去几年促使整个AI领域迈了一大步的深度神经网络技术,更适用于先前CV领域的认知阶段和问题范式。
nlp发展的历史非常早,因为人从计算机发明开始,就有对语言处理的需求。各种字符串算法都贯穿于计算机的发展历史中。伟大的乔姆斯基提出了生成文法,人类拥有的处理语言的最基本框架,自动机(正则表达式),随机上下文无关分析树,字符串匹配算法KMP,动态规划。nlp任务里如文本分类,成熟的非常早,如垃圾邮件分类等,用朴素贝叶斯就能有不错的效果。20年前通过纯统计和规则都可以做机器翻译了。相比,在cv领域,那时候mnist分类还没搞好呢。90年代,信息检索的发展提出BM25等一系列文本匹配算法,Google等搜索引擎的发展将nlp推向了高峰。相比CV领域暗淡的一些。
早期的计算机视觉领域受困于特征提取的困难,无论是HOG还是各种手工特征提取,都没办法取得非常好的效果。大规模商业化应用比较困难。而同期nlp里手工特征➕svm已经搞的风生水起了。
深度学习的崛起- 自动特征提取近些年,非常火爆的深度学习模型简单可以概括为:深度学习 = 特征提取器➕分类器一下子解决cv难于手工提取特征的难题,所以给cv带来了爆发性的进展。深度学习的思路就是让模型自动从数据中学习特征提取,从而生成了很多人工很难提取的特征。很多文本分类任务,你用一个巨复杂的双向LSTM的效果,不见得比好好做手工feature + svm好多少,而svm速度快、小巧、不需要大量数据、不需要gpu,很多场景真不见得深度学习的模型就比svm、gbdt等传统模型就好用。而nlp更大的难题在于知识困境。不同于cv的感知智能,nlp是认知智能,认知就必然涉及到知识的问题,而知识却又是最离散最难于表示的。
总而言之,从认知阶段的角度解读,不是CV领先于NLP,相反,恰恰是因为之前的CV技术搞不定感知,CV是“落后”于NLP所关心的认知范式的。当CV跨过感知的门槛之后,CV和NLP问题殊途同归,两者未来面临的挑战其实是一回事,就是理解这个世界背后的逻辑,它具体可以反映在对常识(common sense)的理解,如何进行因果推断(causal inference),对抽象概念的理解等等。
为什么Transformer会这么成功?

若有收获,就点个赞吧
0 人点赞
