如果你遇到了全球为数不多的MySQL顾问之一,并要求他/她审查您的查询和/或模式,我相信他/她会告诉你有关良好主键设计的重要性,尤其是InnoDB,我相信他们开始向你解释索引合并和页面拆分。这两个概念和性能密切相关,并且在你设计任何索引(不仅仅是主键)时,都应该考虑这种关系。
那对你来说听起来像是胡言乱语,你可能是对的。这不是一件容易的事情,尤其是在讨论内部原理的时候。这不是你经常处理的事情,通常你根本不想处理它。
但有时这是必要的,如果是这样,这篇文章适合你。
在这篇文章中,我想解释一下InnoDB中一些最不清晰的内部操作:页面索引创建、页面合并和页面拆分。
InnoDB中所有数据即索引,你可能也听说过这句话,对吧? 但这到底意味着什么呢?
文件表组件(File-Table Components)
假设你己经安装了MySQL 5.7的最新版本(比如:Percona Server for MySQL),并且在你的模式 windmills 中有一张命名为 wmills 的表,在数据目录(默认是/var/lib/mysql目录)中,你将看到它包含:
data/windmills/wmills.ibdwmills.frm
这是因为从MySQL 5.6开始参数 innodb_file_per_table 设置成1的结果,使用该设置,模式中的每个表都由一个文件表示(如果表是分区的,则由多个文件表示)。
这里重要的是,物理容器是一个名为 wmills.ibd 的文件。这个文件被分成N个段。每个段都与一个索引相关联。
虽然文件的大小不会因为行删除而收缩,但是段本身可以相对于名为区段的子元素增长或收缩。区段只能存在于段中,并且具有1MB的固定大小(在默认页面大小的情况下)。页面是区段的子元素,默认大小为16KB。
因此,一个区段最多可以包含64页,一个页可以包含两到N行。一个页面可以包含的行数和行大小相关,这由表模式定义,InnoDB中有一条规则说,一个页面至少要有2行,因此,我们的行大小限制为8000字节。
如果你认为这听起来像俄罗斯套娃(请自行搜图^_^),你是对的,下面的图片将有助于你理解:
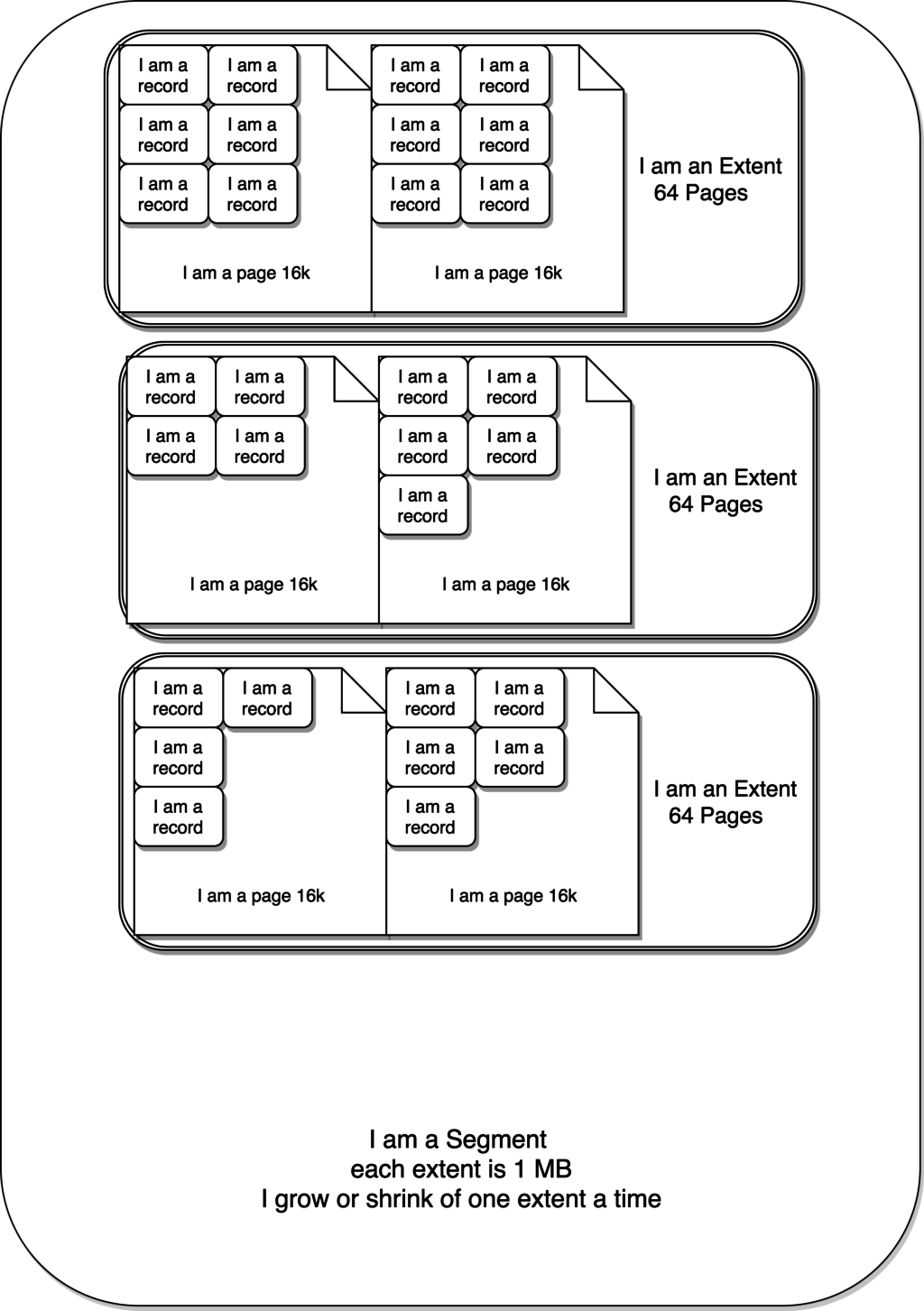
InnoDB使用B树来跨区段组织页面内部的数据。
根(Roots),分支(Branches)和叶子(Leaves)
每个页面(叶子)包含由主键组织的2-N行,树有专门的页面来管理不同的分支。这些被称为内部节点(inode)。
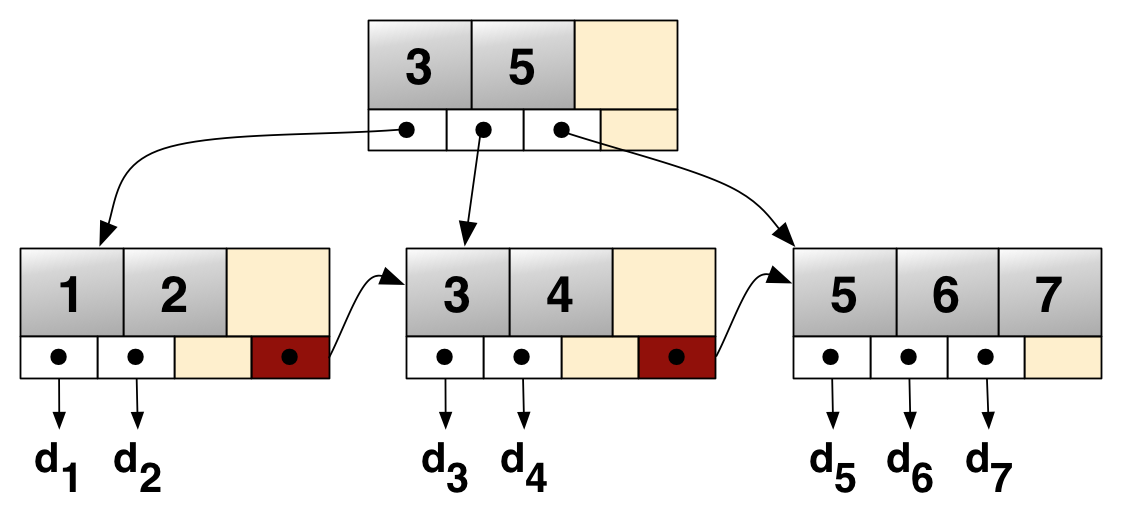
这张图片只是一个例子,并不代表下面的实际输出。
让我们来看看细节:
ROOT NODE #3: 4 records, 68 bytesNODE POINTER RECORD ≥ (id=2) → #197INTERNAL NODE #197: 464 records, 7888 bytesNODE POINTER RECORD ≥ (id=2) → #5LEAF NODE #5: 57 records, 7524 bytesRECORD: (id=2) → (uuid="884e471c-0e82-11e7-8bf6-08002734ed50", millid=139, kwatts_s=1956, date="2017-05-01", location="For beauty's pattern to succeeding men.Yet do thy", active=1, time="2017-03-21 22:05:45", strrecordtype="Wit")
表结构如下:
CREATE TABLE `wmills` (`id` bigint(11) NOT NULL AUTO_INCREMENT,`uuid` char(36) COLLATE utf8_bin NOT NULL,`millid` smallint(6) NOT NULL,`kwatts_s` int(11) NOT NULL,`date` date NOT NULL,`location` varchar(50) COLLATE utf8_bin DEFAULT NULL,`active` tinyint(2) NOT NULL DEFAULT '1',`time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,`strrecordtype` char(3) COLLATE utf8_bin NOT NULL,PRIMARY KEY (`id`),KEY `IDX_millid` (`millid`)) ENGINE=InnoDB;
所有类型的B树都有一个入口点,称为根节点。我们在这里将其标识为第3页。根页面包含索引ID、inode数量等信息。INode页面包含关于页面本身及其值范围等信息。最后,我们有叶节点,这是我们可以找到数据的地方。在这个例子中,我们可以看到叶子节点#5有57条记录,总共7524个字节。在这一行下面是一条记录,您可以看到行数据。
这里的概念是,当你用表和行来组织数据时,InnoDB用分支、页面和记录来组织数据。记住InnoDB不是在单行基础上工作的,这一点非常重要。InnoDB总是对页面进行操作。加载页面后,它将扫描页面以查找请求的行/记录。
现在明白了吗?好,让我们继续。
页面内部(Page Internals)
一个页面可以是空的或是完全填满的(100%),行记录由主键组织,例如,如果你的表使用AUTO_INCREMENT,那么序列ID将是1、2、3、4,等等。
一个页面还有一个重要的属性:MERGE_THRESHOLD ,该参数的默认值是页面的50%,在InnoDB合并活动中起着非常重要的作用。

当你插入数据时,如果传入的记录可以容纳在页面中,那么页面将按顺序被填满。
当一个页面被填满时,下一条记录将被插入到下一个页面:

鉴于B树的性质,该结构不仅可以自上而下沿着树枝进行浏览,还可以横向浏览叶子节点。这是因为每个叶子节点页都有一个指向包含序列中下一个记录值的页的指针。
例如,第5页有对下一页(第6页)的引用。第6页向后引用前一页(第5页),并向前引用下一页(第7页)。
链表的这种机制允许快速、有序的扫描(即:范围扫描)。如前所述,这是在插入和基于AUTO_INCREMENT的主键时发生的情况。但是如果我开始删除值呢?
页面合并(Page Merging)
当你删除一条记录,该条记录不会物理删除,相反,它将记录标记为已删除,并且所使用的空间可以回收。

当一个页面接收到足够的删除操作以匹配MERGE_THRESHOLD(默认为页面大小的50%)时,InnoDB开始查看最近的页面(下一个和前一个),看看是否有机会通过合并这两个页面来优化空间利用率。
在这个例子中,第6页使用了不到一半的空间。第5页收到了许多删除,现在使用的也不到50%。从InnoDB的角度来看,它们是可合并的:

合并操作的结果是第5页包含先前的数据和第6页的数据。第6页变为空页,可用于新数据。
当我们更新一条记录并且新记录的大小使页面低于阈值时,也会发生同样的过程。
规则是: 合并发生在涉及紧密链接页面的删除和更新操作上。如果合并操作成功,则 INFORMATION_SCHEMA.INNODB_METRICS 中的 index_page_merge_successful 指标将递增。
页面拆分(Page Splits)
如上所述,一个页面可以被填充到100%。当这种情况发生时,下一页将记录新记录。
但是如果我们有以下情况呢?

第10页没有足够的空间容纳新的(或更新的)记录。按照下一页的逻辑,记录应该在第11页。然而:
第11页也是满的,不能无序插入数据。那么我们能做些什么呢?
还记得我们讲过的链表吗?此时,第10页的Prev=9, Next=11。
InnoDB要做的是:
- 创建一个新页面
- 确定可以将原始页面(第10页)分割到哪里(在记录级别)
- 移动记录
- 重新定义页面关系

创建一个新的页面#12:

第11页保持原样。改变的是页面之间的关系:
- 页面#10 Prev=9,Next=12
- 页面#12 Prev=10, Next=11
- 页面#11 Prev=12,Next=13
b树的路径仍然可以看到一致性,因为它遵循逻辑组织。然而,页面的物理位置是无序的,并且在大多数情况下处于不同的区段。
作为一个规则,我们可以说: 页面分裂发生在插入或更新时,并导致页面错位(在许多情况下,在不同的区段上)。
InnoDB跟踪 INFORMATION_SCHEMA.INNODB_METRICS 中的页面分割数量。可查看 index_page_split 和 index_page_reorg_tries/success 指标。
一旦创建了分割页面,回退的唯一方法是将创建的页面放到合并阈值以下。当这种情况发生时,InnoDB使用合并操作将数据从拆分页面移动。
另一种方法是通过OPTIMIZE表来重新组织数据。这可能是一个非常繁重和漫长的过程,但是,通常这是从过多页面位于稀疏区段的情况中恢复的惟一方法。
要记住的另一个方面是,在合并和拆分操作期间,InnoDB获得索引树的x-latch。在繁忙的系统中,这很容易成为一个关注点。这可能导致索引latch争用。如果没有合并和分割(又名写操作)只接触单个页面,这在InnoDB中称为“乐观”更新,latch是共享的。合并和分割称为“悲观”更新,latch是排他的。
我的主键
一个好的主键(PK)不仅对于检索数据很重要,而且在写入时正确地分布区段内的数据也很重要(这对于拆分和合并操作也很重要)。
在第一个例子,我有一个简单的自动主键。在第二个例子中,我的PK基于ID(范围1-200)和一个自自增值。在第三个示例中,我有相同的ID(范围1-200),但与UUID关联。
当插入时,InnoDB必须添加页面。这是一个分割操作: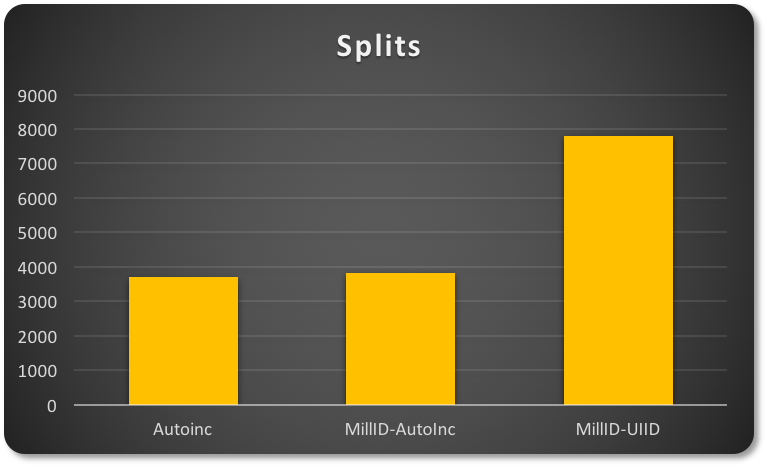
根据我使用的主键的类型,行为是非常不同的。
前两种示例中的数据分布将更加“紧凑”。这意味着它们也将有更好的空间利用率,而UUID的半随机特性将导致显著的“稀疏”页面分布(导致更多的页面和相关的分割操作)。
在合并的情况下,尝试合并的次数因PK类型而异。
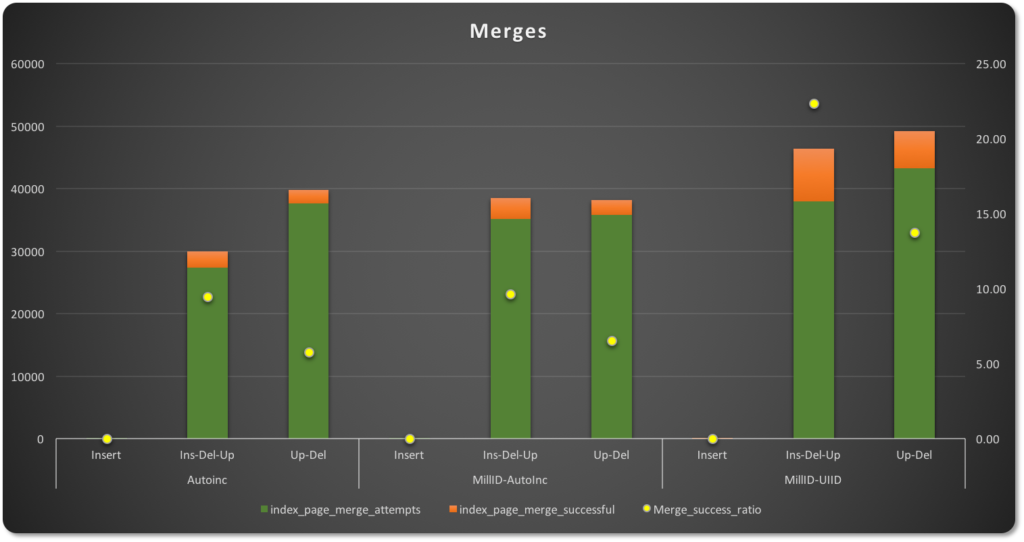
在插入-更新-删除操作中,与其他两种类型相比,自增主键具有更少的页面合并尝试和9.45%的成功率。带有UUID的PK(在图片的另一边)有更高的合并尝试次数,但同时也有显著更高的成功率,为22.34%,这是由于“稀疏”分布使得许多页面部分为空。
具有类似数字的PK值也来自二级索引。
讨论
MySQL/InnoDB经常执行这些操作,而您对它们的可见性非常有限。但是它们会咬你一口,而且咬得很厉害,特别是如果使用主轴存储与SSD(顺便说一下,这两者有不同的问题)。
可悲的是,我们也几乎无法在服务器端使用参数或其他一些神奇的方法来优化它。但好消息是,在设计时可以做很多事情。
使用适当的主键并设计一个二级索引,记住不要滥用它们。计划适当的表维护窗口,你将有高效率的插入/删除/更新。
在InnoDB中,你不会有碎片化的记录,但是在页面-区段级别上,您可能遭遇噩梦。忽略表维护将导致IO级、内存级和InnoDB缓冲池级的更多工作。这是要记住的重要一点。
你必须定期重新构建一些表。使用它需要的任何技巧,包括分区和外部工具(pt-osc)。不要让一张表变得巨大和完全碎片化。
浪费磁盘空间? 需要加载三个页面而不是一个来检索您需要的记录集? 每次搜索都会显著增加读取量?
这是你的错,做事马虎没有借口!
祝大家享受MySQL!
致谢
Laurynas Biveinis: 他花时间耐心地向我解释一些内部原理。
Jeremy Cole: 他的项目InnoDB_ruby(我经常使用)。

若有收获,就点个赞吧
0 人点赞
