本文介绍 Word embeddings(词嵌入),并包含实际训练的代码以及使用 Embedding Projector 实现词向量的可视化。本文翻译自:Word embedding | Tensorflow Core。
用向量表示文本——Word embeddings
计算机将向量作为神经网络的输入,在处理文本时我们首先要做的就是将字符串“向量化”。Word embeddings 是一种高效密集的表示方式,其中相似的单词具有相似的编码。这些词向量不是人工指定的,而是可训练的参数(就像模型学习密集层的权重一样,模型在训练的过程中生成词向量)。
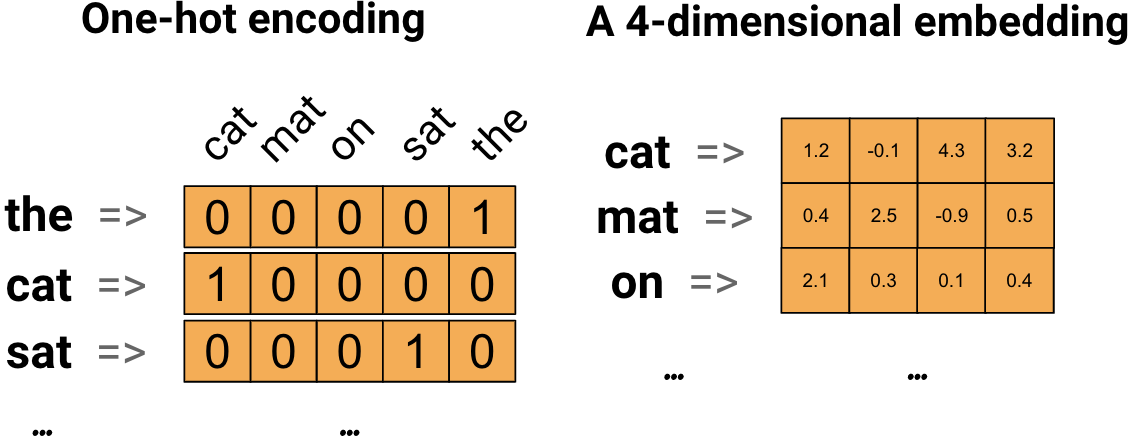
One Hot(左)与 Word embedding(右)示意图
上述两图分别是 One Hot 与 Word emdedding 的示意图。可以看出在 Word embedding 法中,每个单词可以表示为一个四维向量,向量的元素都为浮点数。
嵌入层(Embedding layer)
嵌入层可以理解为一张建立了整数索引(代表特定的词语)与密集向量(词语的嵌入)之间的映射表。创建一个嵌入层:
embedding_layer = tf.keras.layers.Embedding(1000, 5)
当你创建一个嵌入层时,嵌入的权重就像其他各层一样是随机初始化的。训练的过程中,它们会通过反向传播的方式自动调整。一旦训练完成,学习到的词嵌入将大致表示词语之间的相似性。
如果将整数放入嵌入层,就会用生成的向量代替这些整数,如下:
result = embedding_layer(tf.constant([1, 2, 3]))print(result.numpy())# 输出:[[ 0.01298423 -0.03437867 0.00031806 -0.04428304 -0.00638938][-0.03787944 0.01562094 -0.02019413 0.01932223 0.02133374][ 0.02877618 -0.03842849 -0.0194179 0.01550866 0.04344362]]
对于文本或序列(sequence)问题,嵌入层采用 2D 整数张量,其形状为 (samples, sequence_length) ,其中每个条目均为整数序列。当给定一批序列作为输入时,嵌入层将返回形状 (samples, sequence_length, embedding_Dimensionity) 的 3D 浮点张量。
embedding Dimensionity 译为:嵌入维度

若有收获,就点个赞吧
0 人点赞
