梯度下降 https://towardsdatascience.com/gradient-descent-algorithm-a-deep-dive-cf04e8115f21
梯度下降仅适用于可微凹函数
CNN架构
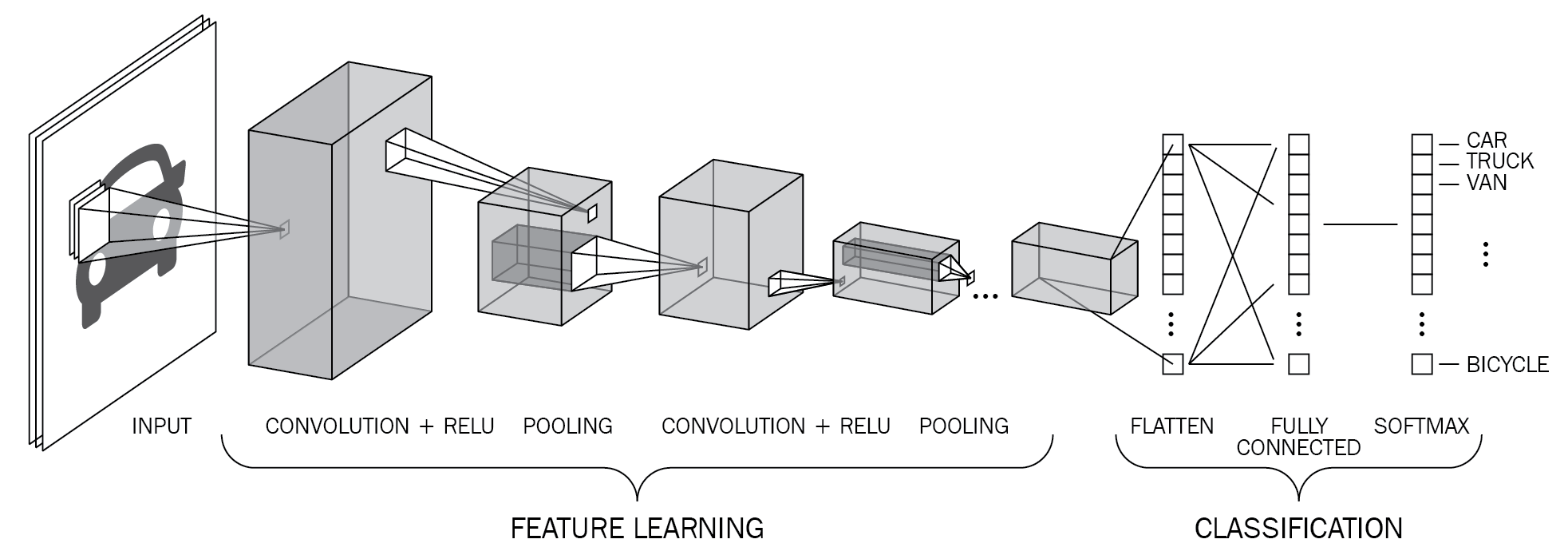
构建CNN模型
- 导入包
- 收集数据
- 准备数据
- 构建模型
- 训练模型
- 评估模型的准确性
导入库
!pip install pytorch-lightning!pip install opendatasetsimport osimport shutilimport opendatasets as odimport pandas as pdimport numpy as npfrom PIL import Imagefrom sklearn.metrics import confusion_matrixfrom sklearn.model_selection import train_test_splitimport matplotlib.pyplot as pltimport torchfrom torch import nn, optimfrom torch.utils.data import DataLoader, Datasetfrom torch.utils.data.sampler import SubsetRandomSamplerfrom torchvision.datasets import ImageFolderimport torchvision.transforms as Tfrom torchvision.utils import make_gridfrom torchmetrics.functional import accuracyimport pytorch_lightning as pl
收集数据
dataset_url = 'https://www.kaggle.com/c/histopathologic-cancer-detection'od.download(dataset_url)# 查看标签cancer_labels = pd.read_csv('histopathologic-cancer-detection/train_labels.csv')cancer_labels.head()# 从train文件夹中随机选择了10000张图像作为数据集np.random.seed(0)train_imgs_orig = os.listdir("histopathologic-cancer-detection/train")selected_image_list = []for img in np.random.choice(train_imgs_orig, 10000):selected_image_list.append(img)len(selected_image_list)# 8000张训练集 2000张测试集np.random.seed(0)np.random.shuffle(selected_image_list)cancer_train_idx = selected_image_list[:8000]cancer_test_idx = selected_image_list[8000:]print("Number of images in the downsampled training dataset: ", len(cancer_train_idx))print("Number of images in the downsampled testing dataset: ", len(cancer_test_idx))
准备数据

若有收获,就点个赞吧
0 人点赞
