说明
在讨论 Java I/O 之前要先讨论以下内容:
- 缓冲区操作
- 内核空间用户空间
- 虚拟内存
- 文件 I/O , 流 I/O
- UNIX I/O 模型
理解了以上内容会对 I/O 有比较清晰的认识 。
缓冲区操作
缓冲区是所有类型 I/O 的基础 , I/O 就是把数据从缓冲区中移进或者移出。<br /> 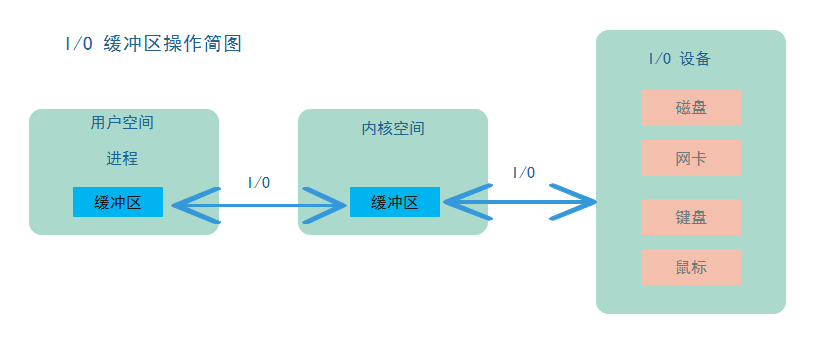<br /> I/O 过程是将数据在用户空间进程缓冲区和内核缓冲区之间进行移动 , 数据的来源是外部的 I/O 设备。当进程请求 I/O 操作时 , 会执行一个系统调用,将控制权移交给系统内核。比如 C/C++ 语言的底层函数 open() , read() , write() , close() , 要做的就是执行系统调用。当内核被调用时,它要找到进程所需的数据,并把数据传送到用户空间内指定的缓冲区。内核试图对数据进行高速缓存或者预读取,因此进程所需要的数据可能已经在内核空间中了,此时只需要把这些数据拷贝到用户空间中即可。如果数据不在内核空间中,那么内核空间要去读取数据,用户空间进程被挂起。<br /> 数据从内核空间到用户空间需要进行一次内存拷贝,无法直接将数据从I/O设备传送到用户空间。因为,硬件设备通常不能直接访问用户空间;像磁盘这种基于块存储的硬件设备操作的是固定大小的数据块,而用户进程请求的可能是任意大小的或非对齐的数据块。内核负责了对从I/O设备获取的数据进行处理。<br />
内核空间、用户空间
用户空间是常规进程所在区域,内核空间是操作系统以及一些驱动所在区域。应用程序在用户模式下运行,操作系统在内核模式下运行。**每个用户模式进程都有各自专用的虚拟地址空间,在内核模式运行下的所有代码都称为“系统空间”的单个虚拟地址空间。用户模式进程的虚拟地址空间称为“用户空间”。**用户模式下运行的代码可以访问用户空间,但是不能访问系统空间。内核模式下运行的代码可以访问系统空间和用户空间。<br />
虚拟内存
从用户空间到内核空间 I/O 过程中会存在一次内存拷贝操作,利用虚拟内存技术可以避免这一次内存拷贝。<br /> 虚拟内存维基百科:虚拟内存是计算机系统内存管理的一种技术。它使得应用程序认为它拥有连续可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。与没有使用虚拟内存技术的操作系统相比,使用这种技术的操作系统使得大型程序的编写变得更容易,对物理内存的使用也更有效率。<br /> 注意:虚拟内存不只是“用磁盘空间来扩展物理内存”的意思,这只是扩充内存级别已使其包含硬盘驱动器而已。把内存扩展到磁盘只是使用虚拟内存技术的一个结果,它的作用也可以通过覆盖或者把处于不活跃状态的程序以及他们的数据全部交换到磁盘上的方式来实现。对虚拟内存的定义是基于对地址空间的重定义的,即把地址空间定义为“连续的虚拟内存地址”,以借此“欺骗”程序,使他们以为自己正在使用一大块“连续”地址。<br /> 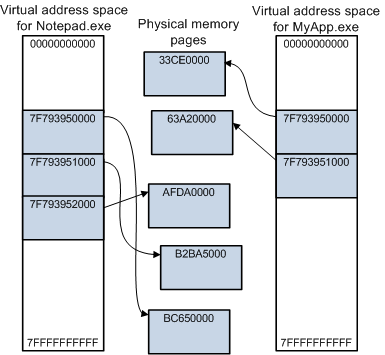<br /> <br /> 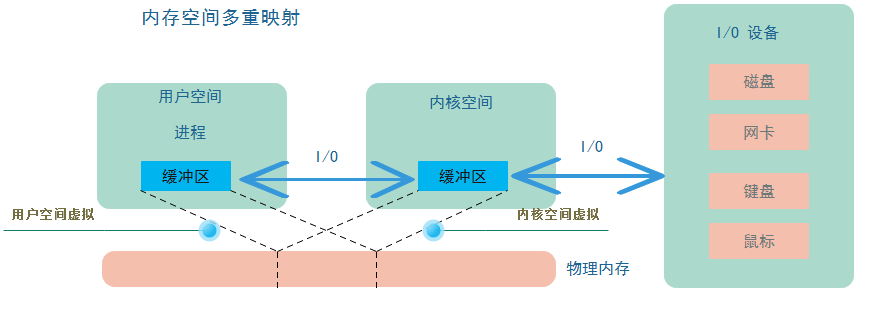<br /> **内核空间虚拟和用户空间虚拟映射的相同的物理内存区域,因为每一个进程的用户空间是独立的,内核空间可以操作任意用户空间。内核把数据存入这片内存区域后对用户进程来说也是可见的,这样就避免了内存拷贝。**
Linux 的内核将所有外部设备都可以看做一个文件来操作,那么我们对与外部设备的操作都可以看做对文件进行操作。我们对一个文件的读写,都通过调用 内核提供的系统调用; 内核给我们返回一个 file descriptor(fd,文件描述符)。 而对一个 socket 的读写也会有相应的描述符,称为 socketfd(socket 描述符), 描述符就是一个数字,指向内核中一个结构体(文件路径,数据区等一些属性)。 根据 Unix 网络编程对 IO 模型的分类,Unix 提供了五种 IO 模型。
<br />
UNIX I/O 模型
- 阻塞 I/O (bloking I/O)
- 非阻塞 I/O(non-blocking I/O)
- 多路复用 I/O (multiplexing I/O)
- 信号驱动 I/O (signal-driven I/O)
- 异步 I/O (asynchronous I/O)
阻塞 I/O 模型
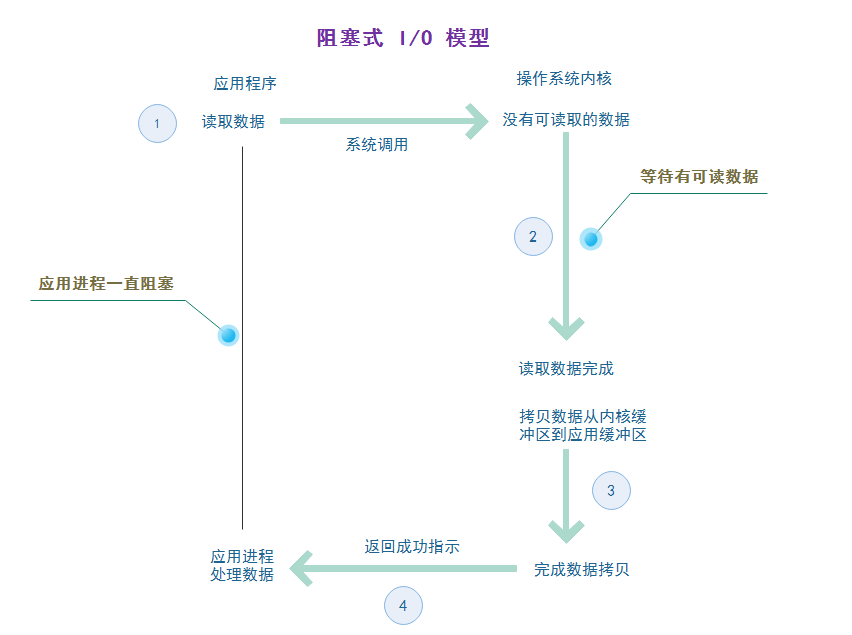<br /> 第①步应用程序触发操作系统读取数据;<br /> 第②步控制器移交给内核,如果有数据可读就进行读取,没有数据可读就等待;<br /> 第③步读取到数据 , 将数据从内核空间缓冲区拷贝到用户空间缓冲区;<br /> 第④步数据拷贝完成内核通知应用程序读取数据成功;<br /> 在这4步完成之前, 应用程序进程将一直处于阻塞状态。<br />
非阻塞 I/O 模型
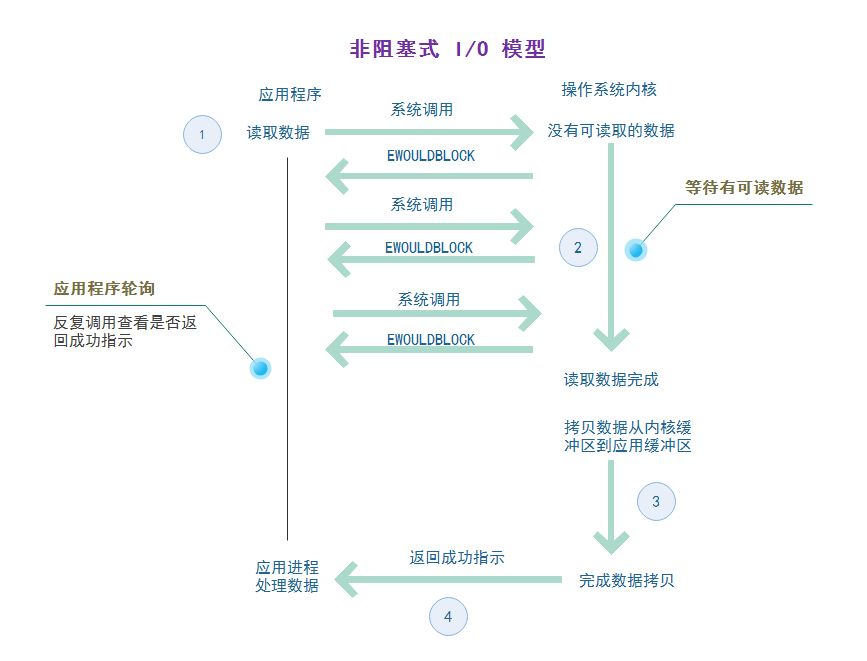<br /> 非阻塞模式做的改进是 , 在第④步没有完成之前,轮询的执行第 ① 步 , 此时引用程序进程不会阻塞,在没有收到成功指示的时候,进程可以去做别的事情,当收到成功指示后再去处理读取到的数据即可,不需要一直阻塞等待。<br />
多路复用 I/O 模型
多路复用 I/O 就是经常说的 select , poll , epoll 有写地方也称这种 I/O 方式为 event driven I/O 。多路复用 I/O 的好处就是一个进程可以处理多个网络连接 I/O,它的工作原理就是 select/poll/epoll 函数会不断的查询所监测的 socket 文件描述符中是否有 socket 准备好读写了,如果有,那么系统就会通知用户进程。<br /> 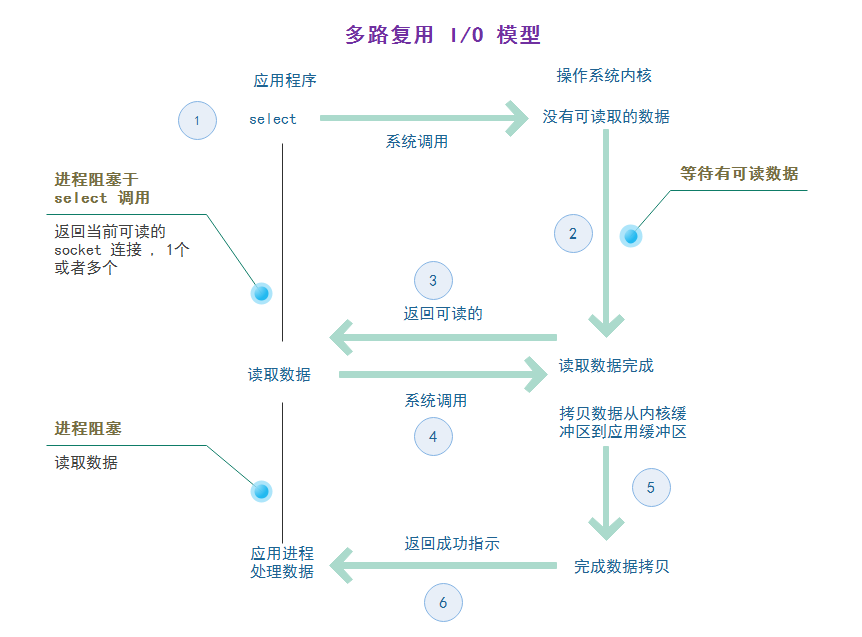<br /> select 不会像 阻塞I/O 那样长时间阻塞直到有数据可读, select 遍历所有的 socket 返回其中处于可读状态的。然后应用程序进程就可以对这些 socket 进行 I/O 操作 , 由于这些 socket 中已经有数据了 ,所以此时只需要进行内存拷贝,将数据从内核空间拷贝到用户空间中就完成了 I/O 操作。select 最大的缺陷是单个进程所打开的 socket 描述符是有一定限制的,它由 FD_SETSIZE 设置,默认是 1024 。对于需要成千上万个 TCP 连接的大型服务器来说太少了。epoll 并没有这个限制 , 它所支持的 FD 上限是操作系统的最大文件句柄数,例如在内存 1G 的机器上大约是 10万个句柄。select/poll 的另一个致命缺点,当拥有一个很大的 socket 集合时,由于网络延时或者链路空闲,任意时刻只有少部分的 socket 是“活跃”的,但是 select/poll 每次调用都会线性的扫描全部 socket 集合,导致了效率呈线性下降。epoll 不会存在这个问题 , 它只会对 “活跃” 的 socket 进行操作。<br />阻塞模式 ,和非阻塞模式一次都只能处理一个 I/O 操作 。多路复用模型可以一次处理多个 I/O 操作。event driven 的思想体现在 , 可以选择处于不同状态的 socket , 比如 accept , connect , read , write , 更具不同的状态进行相应的处理。<br />
信号驱动 I/O
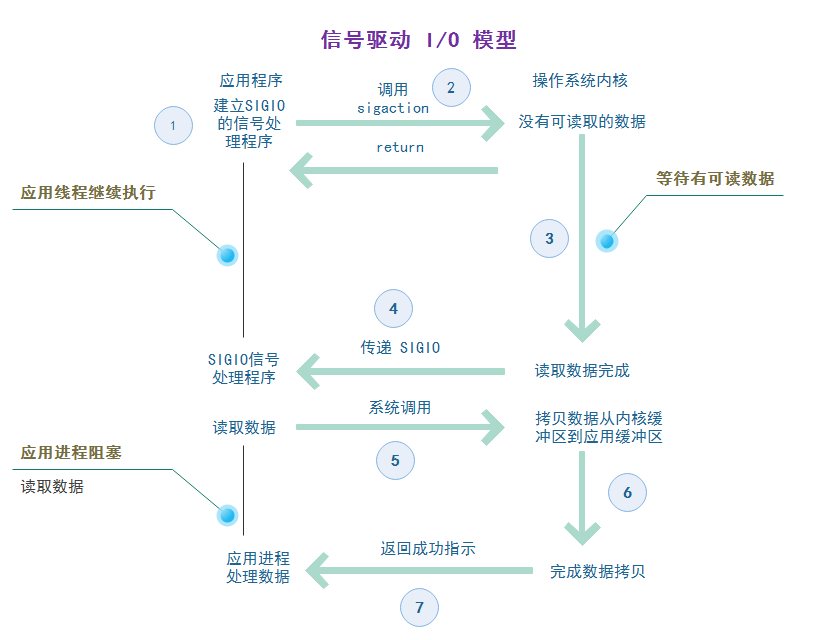<br /> ** Signal Driven I/O** 的工作原理就是用户进程首先和 kernel 之间建立信号的通知机制,即用户进程告诉 kernel,如果 kernel 中数据准备好了,就通过 `SIGIO` 信号通知我。然后用户空间的进程就会调用 read 系统调用将准备好的数据从 kernel 拷贝到用户空间。<br />但是这种 I/O 模型存在一个非常重大的**缺陷问题**:`SIGIO` 这种信号对于每个进程来说只有一个!如果使该信号对进程中的两个描述符(这两个文件描述符都等待着 I/O 操作)都起作用,那么进程在接到此信号后就无法判别是哪一个文件描述符准备好了。所以 **Signal Driven I/O** 模型在现实中用的非常少。<br />
异步 I/O
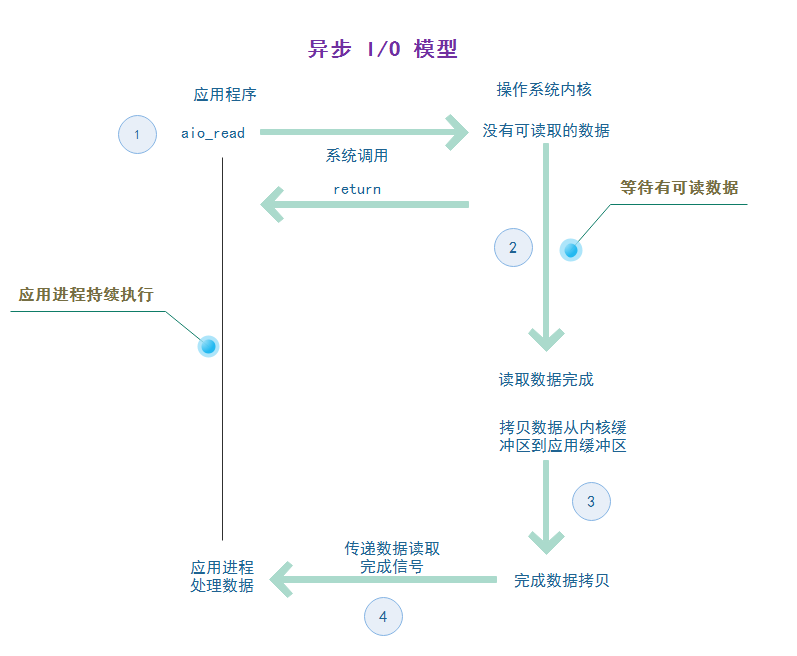<br />
阻塞 I/O Java服务端通信模型
Java 是运行在 JVM 之上 , JVM 运行在操作系统之上,JVM 是一个用户进程 。 Java 应用程序并非是真的受着 I/O 的束缚。操作系统并非不能快速的传递数据 。是因为 JVM 在 I/O 方面效率欠佳。操作系统与 Java 基于流的 I/O 模型有写不匹配。操作系统要移动的是大块的数据(缓冲区) ,而 JVM 的 I/O 类喜欢操作一小块数据 — 单一字节、几行文本。结果操作系统送来整块缓冲区的数据,Java I/O 流数据类再花大量时间把他们拆成小块,往往拷贝一小块就要往返几层对象。
JDK 在 1.4 之前是只支持阻塞式 I/O 的,Java 的网络编程也只能是基于阻塞式 I/O 的模式工作,为了避开 I/O 时线程阻塞的问题,只能采用多线程处理连接请求。
原阻塞 I/O 模型
<br />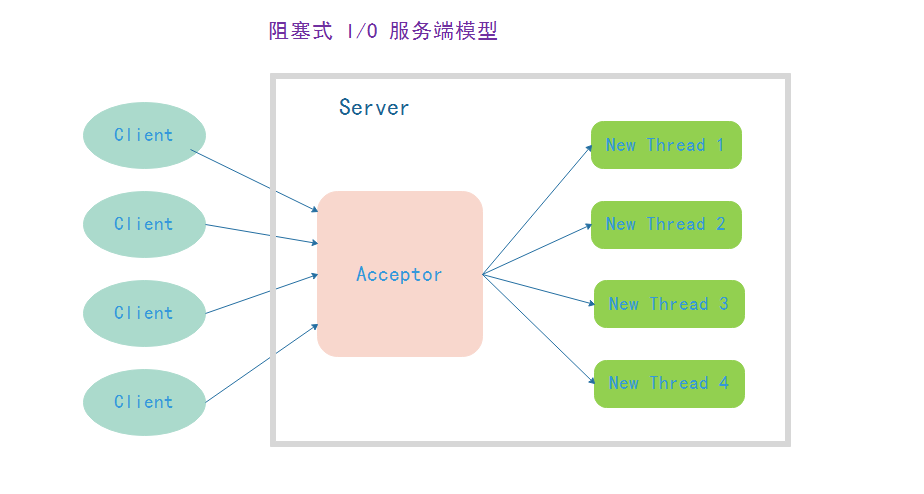<br />该模型的问题:
每当有一个客户端连接,服务端都要分配一个新的线程来处理这个客户端请求,随着客户端的增多服务端线程也线性增长,内存开销增大,CPU 上下文切换性能开销大。线程是 JVM 非常宝贵的系统资源,当线程数非常多以后,系统性能急剧下降,不具备可伸缩性。随着并发量的上升可能会导致文件句柄溢出,线程堆栈溢出,最终导致服务器宕机。
**
问题:为什么不使用一个线程处理多个连接链路?
该模型使用的 java 1.4 之前的 api, java.io.socket 通过 获取 InputStream 或者 OutPutstream 进行网络读写。
InputStream 的 read() 方法 和OutPutstream 的 write() 方法是阻塞的。当某个连接数据没有处理玩时,后面的socket 连接是没有办法处理的。长时间的等待会导致连接超时,所以通常采用一个连接一个线程的处理方式。
This method blocks until input data is available, the end of the stream is detected, or an exception is thrown. see read() 方法。
/**
* Reads the next byte of data from the input stream. The value byte is
* returned as an <code>int</code> in the range <code>0</code> to
* <code>255</code>. If no byte is available because the end of the stream
* has been reached, the value <code>-1</code> is returned. This method
* blocks until input data is available, the end of the stream is detected,
* or an exception is thrown.
*
* <p> A subclass must provide an implementation of this method.
*
* @return the next byte of data, or <code>-1</code> if the end of the
* stream is reached.
* @exception IOException if an I/O error occurs.
*/
public abstract int read() throws IOException;
优化后的阻塞 I/O 模型
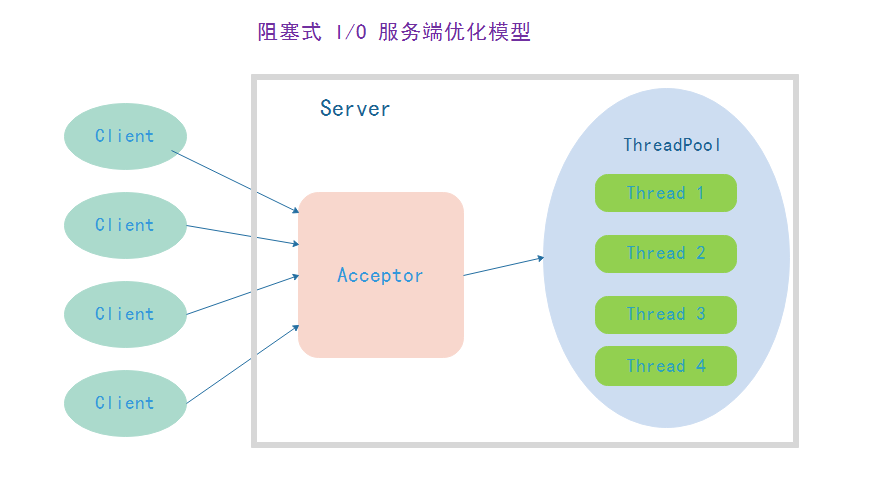<br /> <br />通过复用线程,减少了线程创建的开销,并通过控制线程的总量可以保证系统负载不过载。优化后可以缓解原模型存在的问题,但是没有办法从根本上解决问题。
- 由于读写方法是阻塞的,如果并发量增大或者网络延迟增加,会导致线程执行时间被拉长,最终可能导致任务堆积;导致任务拒绝或者内存溢出;
- 由于网络的时延、客户端的执行速度和服务器的处理能力不同, IO 读写阻塞时间往往也是不可控的,它会导致 IO 线程的不可预期性阻塞,降低系统的处理能力和网络吞吐量。在大规模高并发、高性能的服务器端,使用 JAVA 的同步 IO 来构建服务端是无 法满足性能、可扩展性和可靠性要求的;(实际生产环境下,客户端的数量是远远大于服务器可以创建的线程数量的)

若有收获,就点个赞吧
0 人点赞
