CAP介绍
C:Consistency 一致性
- 指的是强一致性。在分布式系统中的所有节点在同一时刻具有同样的值【都是最新的数据副本】,一致性保证了不管向哪台服务写入数据,其他服务器都能实时同步数据;
- 对于服务端来说,更新操作如何复制分布到整个系统,以保证数据最终一致的问题;
- 对于客户端来说,是指在并发访问时数据如何获取的问题;
A:Availability 可用性
- 服务一直可用,正常响应。系统不出现用户操作失败或者是访问超时等用户体验不好的情况;
- 部分节点宕机不影响整个集群对外提供服务,每次向未故障的节点发送请求,服务节点总能保证在有限的时间内处理完成并进行响应;
- 从用户的角度来看就是不会出现系统操作失败或者是访问超时等问题,但是系统内部可能会出现网络延迟等问题;
P:Partition Tolerance 分区容错性
- 因为网络的错综复杂,如果某个节点因为网络等问题造成数据不一致,或者是数据延迟很久才同步过来,虽然会影响部分节点数据的时效性,但是服务节点依然是可用的。分布式系统运行这样的情况,尽管网络上有部分消息丢失,但是系统仍然可继续工作。
分布式系统中,CAP是无法同时满足的,只能满足CAP中的两种,因此在设计分布式架构时,必须做出取舍,而对于分布式系统,分区容忍性是基本要求,必须满足。
CP和AP:分区容错是必须保证的,当发生网络分区的时候,如果要继续服务,那么强一致性和可用性只能二选一;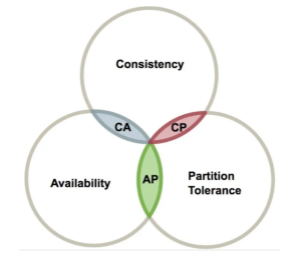
在P(分区容错)满足的情况下,为什么说CA不能同时满足,如果CA同时满足会如何:
- 假设现在要求满足C(一致性),那么所有的节点在某一刻的数据都必须一致,如果是在P的情况下不可能保证的,要保证的话,就只能把其他节点全部干掉。比如禁止读写,那这其实就是和A(可用性)是相悖的(某些节点虽然延迟,但是节点本身可用);
- 假设现在要求满足A(可用性),那么就是说只是节点本身没什么问题,就可以对外提供服务。哪怕有点数据延迟,很明显这是和C相悖的。
一致性的类别
CAP是分布式事务处理的理论基础,在分布式事务的最终解决方案中一般选择性牺牲一致来换取可用性和分区容错性,但是牺牲一致性并不是完全放弃数据的一致,而是放弃强一致性而换取弱一致性。一致性一般可以分为一下三种:
- 强一致性:在任意时刻,所有节点中的数据都是一样的,系统中的某个数据被成功更新后,后续任何对该数据的读取操作都将得到更新后的值。比如传统数据库的事务特性ACID,就是追求强一致性模型。
- 一个集群需要对外部提供强一致性,就务必损耗可用性,只要集群内部某一台服务器的数据发送了改变,那么就需要等待集群内其他服务器的数据同步完成后,才能正常的对外提供服务。
- 弱一致性:系统中的某个数据被更新后,后续对该数据的读取操作可能得到更新后的值,也可能是更改前的值,但即使过了不一致时间窗口后,后续对该数据的读取也不一定是最新值;
最终一致性:是弱一致性的特殊形式,虽然不保证在任意节点上的同一份数据都是相同的,但经过一段时间后,所有服务节点间的数据最终会达到一致的状态。
BA基本可用:指分布式系统在出现故障的时候,允许损失部分可用性,保证核心可用。但是不等价于不可用。如:搜索引擎0.5s返回查询结果,但由于故障,2s响应查询结果;网页访问过大时,部分用户提供降级服务等;
- 软状态:软状态是指允许系统存在中间状态,并且该中间状态不会影响系统整体可用性,即允许系统在不同节点间副本同步的时候存在延时;
- 最终一致性:系统中的所有数据副本经过一定时间后,最终能够达到一致的状态,不需要实时保证系统数据的强一致性;
很多时候我们并不要求数据的强一致性,而BASE通过牺牲强一致性来获得更好的可用性,所以BASE理论的适用性更广泛,比如更适合面向的是大型高可用可扩展的分布式系统。
柔性事务和刚性事务:柔性事务满足BASE理论(基本可用,最终一致),刚性事务满足ACID理论。
一致性协议
Gossip协议
集群节点之间需要进行通信,当一个节点加入到集群中或者是集群中的一个节点下线,都需要通知集群中的其他节点,将数据信息分享出去。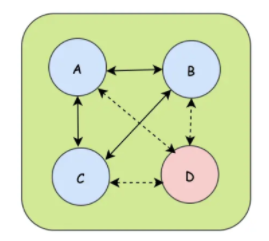
- A、B、C节点相互传递消息,D节点下线的时候需要广播通知其他的节点,广播中使用到的协议就是Gossip协议
- Gossip协议,也称为流行病协议。当一个消息到来,通过Gossip协议就可以像病毒一样感染全部集群节点;
- 先是由一个种子节点发起,当一个种子节点有信息需要同步到网络中的其他节点时,它就会随机选择它周围的几个节点散播消息,收到消息的节点也会重复该过程,直到网络中的所有节点都收到消息。
- 这个过程需要一定的时间,不能保证某个时间点所有的节点都会收到消息,但是理论来说最终所有的节点都会收到消息,是一个最终一致性的协议。
- 特点:
- 周期性散播消息,每隔一段时间传播一次;
- 被感染的节点每次可以继续散播个节点;
- 每次散播消息的时候,都会选择尚未发送过的节点进行散播,不会向已经发送的节点散播;
- 同一个节点可能会收到重复的消息,因为可能同时多个节点正好向其散播;
- 集群是去中心化的,节点之间都是平等的;
- 消息的散播不用等接收节点的ack,消息可能会丢失,但是最终都应该被感染到;
- Gossip的传播类似于图的广度优先遍历算法,一般用于网络拓扑结构信息的分享和维护,比如redis集群中节点的运行状态使用的就是Gossip协议进行传递的。
Raft一致性协议
Raft算法,在数据安全和性能之间做了折中,只能保证绝大部分节点同步数据成功。实现了分布式系统的不同节点间的数据一致性,当客户端发送请求到任何一个节点都能收到一致的返回,当一个节点出现故障后,其他节点仍然能以已有数据正常进行;
Raft算法中节点的角色:
- Leader节点:同大多数分布式中的Leader节点一样,所有数据的变更都需要先经过Leader;
- Follower节点:Leader节点的追随者,负责复制数据并且在选举时候进行投票的节点;
- Candidate候选节点:参与选举的节点,就是Follower节点参与选举时会切换的角色。
Raft算法将一致性问题分解为两个子问题:Leader选举+数据日志的复制;
Leader选举
- 系统刚开始,所有的节点都是Follower节点,每个节点都有机会参与选举,现实变成Candidate节点,然后投自己一票,再通知其他节点来投票。当票数超过半数以上,Candidate节点变成Leader节点。【为了防止节点转换变成死循环,每个Follower都有一个定时器,定时器的时间是随机的,当某个Follower的定时器时间走完之后,会确认当前是否存在Leader节点,如果不存在则把自己切换成Candidate节点】;
- Leader节点选举之后,需要触发心跳机制,不断向其他的Follower节点发送心跳,以告诉这些节点自己的状态。Follower会根据心跳,清空自己的定时器,表明此时不需要选举;
- 如果Follower收不到Leader的心跳,那么就会触发新一轮选举,如之前的选举一样,优先跑完定时器的Candidate节点理论上成为Leader的概率更大;
数据日志复制 :::danger 当Leader节点收到客户端的变更数据操作的时候,会把变更记录到log中,然后在发送心跳机制的时候同时通知Follower节点,收到消息的Follower节点会把变更写入到日志中,之后回复Leader节点,当Leader收到大多数的回复后,就把变更写入自己的存储空间,同时回复客户端,然后再通知Follower应用这个log。集群就此达到变更共识。 :::

若有收获,就点个赞吧
0 人点赞
