引入
在实际的案例中有没有碰到慢SQL语句?
补充: 正常的SQL语句通常几毫秒钟就可以实现结果的查询。但是在实际中会有一些SQL语句要几秒钟甚至十几秒钟才能实现结果的查询。 这样耗时较长,执行效率较低的SQL语句称为 —慢SQL
1.索引的本质
- 索引 :是帮助MySQL高效获取数据的排好序的数据结构。
- 索引的数据结构:
- 二叉搜索树
- 红黑树
- Hash表
- B-树
- B+树
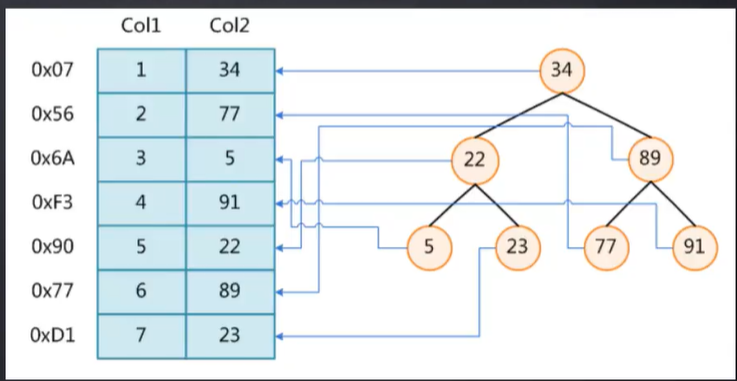
对于select * from t where t.col2=89; 这一条SQL语句
分析:
首先会匹配表的第一行记录,即Col2的第一行,结果为34,它会和89进行比较。二者不相等,它就会匹配下一个行记录,然后在和89比较,这样一行一行比较,直到表中的行记录和89相等,则查到结果。
对于没有索引的查询,它是从第一行开始查询,然后一行一行去查询,这样的速度是非常慢的,因为每查询一次就是一次IO交互,效率非常低。
上图就是对存储结构进行了改进,使用二叉搜索树的结构存储表记录。这样在查询的时候,首先查询根节点34,发现89大于根节点,这时直接查询右子树,则匹配到结果,只需要两次结果即可。
问题:
当表记录的值为Col1时,即使采用了二叉搜索树,发现结果是一个单列的分支树。树的深度很深,则查找的效率,就很低下。
解决方案:
引入了红黑树,或者二叉平衡树。二叉平衡树本质上还是一颗二叉树搜索树,但是它自己会平衡节点之间的关系。即每次插入新的节点的时候,不仅仅是将大的节点方到父节点的右侧,还会通过节点的偏移控制树的结构,使得左右子树深度之差小于等于1. 这样使得树的结构比较平衡,顶部尖,底部宽。
问题:
当数据量较大的时候,红黑树的深度依然会变的很高,不仅仅是红黑树,即使是满二叉树在庞大的数据量下也会变得深度较大。
解决方案:
在平衡树的基础上,每个节点存储多个元素。这样就解决了数据量较大的问题。之前因为每个节点只存储一个数据,现在可以在节点上存储多个元素,进而减少树的深度。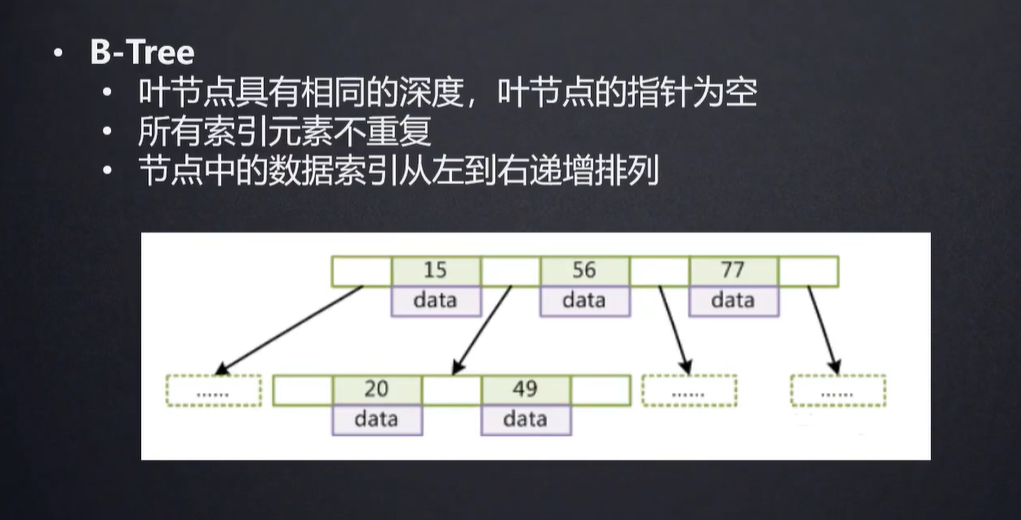
但是MySQL最终选择的是B+树的数据结构进行数据的存储。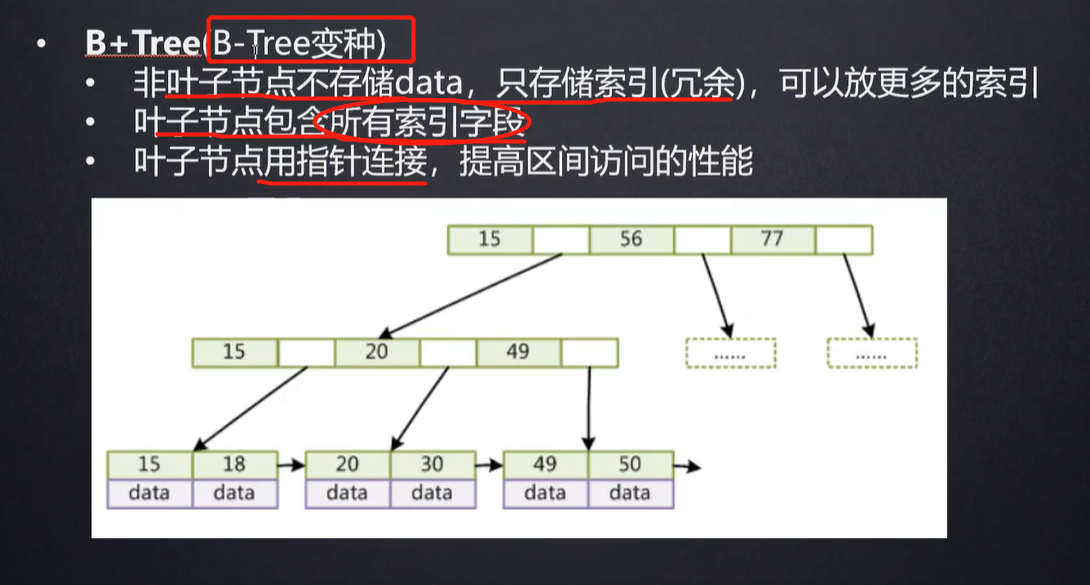
对比
B+树:非叶子节点中没有data域,不存放具体数据,只存储索引。所有的数据全部存放到叶子节点中,并使用指针连接成链表。B+树的叶子节点包含了所有的索引元素。

若有收获,就点个赞吧
0 人点赞
