# 生成画布,并设置画布的大小plt.figure(figsize=(6, 6))# 绘制柱状图plt.bar(x, height=y, color='darkorange', alpha=0.6)# 设置数据标签plt.text('第一季度', 59, 59, ha='center', va='bottom', fontsize=12)plt.text('第二季度', 70, 70, ha='center', va='bottom', fontsize=12)plt.text('第三季度', 68, 68, ha='center', va='bottom', fontsize=12)plt.text('第四季度', 56, 56, ha='center', va='bottom', fontsize=12)
# 生成画布,并设置画布的大小plt.figure(figsize=(6, 6))# 设置 x/y坐标值x = pd.Series(['第一季度', '第二季度', '第三季度', '第四季度'])y = pd.Series([59, 70, 68, 56])# 绘制柱状图plt.bar(x, height=y, color='darkorange', alpha=0.6)# 绘制折线图plt.plot(x, y, color='dodgerblue')# 设置图表标题名及字体大小plt.title('闪光科技2020年各季度研发费用分布图', fontsize=20)# 设置坐标轴的刻度字体大小plt.xticks(fontsize=12)plt.yticks(fontsize=12)# 设置坐标轴的标题名及字体大小plt.xlabel('季度', fontsize=15)plt.ylabel('研发费用(百万元)', fontsize=15)# 设置图例plt.legend(['研发费用变化', '研发费用分布'])# 设置数据标签for a, b in zip(x, y):plt.text(a, b, b, ha='center', va='bottom', fontsize=12)# 保存画布,并设置保存路径plt.savefig('./工作/闪光科技2020年各季度研发费用分布图.png')
# 生成画布,并设置画布的大小plt.figure(figsize=(6, 6))# 设置 x/y 坐标值x = order_number.indexy = order_number.values# 绘制折线图,并调整线条、标记点的样式plt.plot(x, y, linewidth=3, color='r', marker='o',markerfacecolor='w', markersize=10)# 设置图表标题名及字体大小plt.title('各月总订单量趋势图', fontsize=20)# 设置坐标轴的刻度字体大小plt.xticks(fontsize=12)plt.yticks(fontsize=12)# 设置坐标轴的标题名及字体大小plt.xlabel('月份', fontsize=15)plt.ylabel('各月总订单量(百万)', fontsize=15)# 保存画布plt.savefig('./工作/各月总订单量趋势图.png')# 提取各省各月订单量数据month_order = mask_data_clean.groupby(['月份', '省'])['订单量'].sum()# 将多级索引的的Series对象转换成DataFrame对象month_order_df = month_order.unstack()# 查看各省各月订单量数据month_order_df# 调整画布大小plt.figure(figsize=(6, 6))# 设置 x/y 坐标值x = month_order_df.indexy = month_order_df.values# 绘制折线图,并调整线条、标记点的样式plt.plot(x, y, linewidth=2, marker='o', markerfacecolor='w', markersize=10)# 设置图表标题名及字体大小plt.title('各省各月口罩订单量变化折线图', fontsize=20)# 设置坐标轴的刻度字体大小plt.xticks(fontsize=12)plt.yticks(fontsize=12)# 设置坐标轴的标题名及字体大小plt.xlabel('月份', fontsize=15)plt.ylabel('各省各月口罩订单量(百万)', fontsize=15)# 添加图例plt.legend(['其他', '广东', '江苏', '河南', '湖北', '湖南'])# 保存画布plt.savefig('./工作/各省各月口罩订单量变化折线图.png')# 生成画布,并设置画布的大小plt.figure(figsize=(6, 6))# 设置 x/y 坐标值x = mask_price.indexy = mask_price.values# 绘制柱状图,并调整柱子的样式plt.bar(x, height=y, color=['r', 'g', 'g', 'g', 'g', 'b'], width=0.6, alpha=0.6)# 设置图表标题名及字体大小plt.title('各月平均单价分布图', fontsize=20)# 设置坐标轴的刻度字体大小plt.xticks(fontsize=12)plt.yticks(fontsize=12)# 设置坐标轴的标题名及字体大小plt.xlabel('月份', fontsize=15)plt.ylabel('各月平均单价(元)', fontsize=15)# 设置数据标签for a, b in zip(x, y):plt.text(a, b, '%.0f' % b, ha='center', va='bottom', fontsize=12)# 保存画布plt.savefig('./工作/各月平均单价分布图.png')
# 导入 pandas 库并将其简化为 pdimport pandas as pd# 导入matplotlib库的pyplot模块from matplotlib import pyplot as plt# 读取练习数据,文件路径为 './工作/exercise_clean.csv',文件编码为 'utf-8'exercise = pd.read_csv('./工作/exercise_clean.csv', encoding = 'utf-8')# 求出不同明细商品的总销售额sales_sum = exercise.groupby('明细')['订单金额'].sum()# 设置中文字体plt.rcParams['font.family'] = ['Source Han Sans CN']# 生成画布,并设置画布的大小(figsize=(6, 6))# 设置 x/y 坐标值x =y =# 绘制柱状图,并调整柱子的样式(x , height=y, width=0.6, alpha=0.6)# 设置图表标题名及字体大小('各明细商品总销售额分布图', fontsize=20)# 设置坐标轴的刻度字体大小(fontsize=12)(fontsize=12)# 设置坐标轴的标题名及字体大小('商品明细', fontsize=15)('总销售额', fontsize=15)newgoods_df = pd.DataFrame(goods_info, columns=['名称', '单价', '库存', '地址'])newgoods_df# 创建一个 DataFrame 对象的数据humans_df = pd.DataFrame({'姓名': ['小猿', '小马', '小鱼', '小猫', '小龙'], '身高': ['165', '170', '160', '172', '178'], '体重': [56, 45, 60, 40, 70]})humans_df# 重置数据 sorted_goods 的行索引reset_goods = sorted_goods.reset_index(drop=True)reset_goods# 依照【单价】列的数据进行排序sorted_goods = newgoods_df.sort_values(by='单价')sorted_goodsreset_goods['单价'] = round(reset_goods['单价'], 2)reset_goods如果一个项集是频繁的,那么它的所有非空子集都是频繁的。如果一个项集不是频繁的,那么它的所有超集也必然不是频繁的。
from apyori import apriori
RelationRecord(items=frozenset({'可乐'}), support=1.0, ordered_statistics=[OrderedStatistic(items_base=frozenset(), items_add=frozenset({'可乐'}), confidence=1.0, lift=1.0)])RelationRecord(items=frozenset({'薯条'}), support=0.75, ordered_statistics=[OrderedStatistic(items_base=frozenset(), items_add=frozenset({'薯条'}), confidence=0.75, lift=1.0)])RelationRecord(items=frozenset({'可乐', '奶茶'}), support=0.25, ordered_statistics=[OrderedStatistic(items_base=frozenset({'奶茶'}), items_add=frozenset({'可乐'}), confidence=1.0, lift=1.0)])RelationRecord(items=frozenset({'汉堡', '可乐'}), support=0.5, ordered_statistics=[OrderedStatistic(items_base=frozenset({'汉堡'}), items_add=frozenset({'可乐'}), confidence=1.0, lift=1.0)])RelationRecord(items=frozenset({'薯条', '可乐'}), support=0.75, ordered_statistics=[OrderedStatistic(items_base=frozenset(), items_add=frozenset({'薯条', '可乐'}), confidence=0.75, lift=1.0), OrderedStatistic(items_base=frozenset({'可乐'}), items_add=frozenset({'薯条'}), confidence=0.75, lift=1.0), OrderedStatistic(items_base=frozenset({'薯条'}), items_add=frozenset({'可乐'}), confidence=1.0, lift=1.0)])RelationRecord(items=frozenset({'薯条', '奶茶'}), support=0.25, ordered_statistics=[OrderedStatistic(items_base=frozenset({'奶茶'}), items_add=frozenset({'薯条'}), confidence=1.0, lift=1.3333333333333333)])RelationRecord(items=frozenset({'薯条', '可乐', '奶茶'}), support=0.25, ordered_statistics=[OrderedStatistic(items_base=frozenset({'奶茶'}), items_add=frozenset({'薯条', '可乐'}), confidence=1.0, lift=1.3333333333333333), OrderedStatistic(items_base=frozenset({'可乐', '奶茶'}), items_add=frozenset({'薯条'}), confidence=1.0, lift=1.3333333333333333), OrderedStatistic(items_base=frozenset({'薯条', '奶茶'}), items_add=frozenset({'可乐'}), confidence=1.0, lift=1.0)])RelationRecord(items=frozenset({'汉堡', '可乐', '薯条'}), support=0.25, ordered_statistics=[OrderedStatistic(items_base=frozenset({'汉堡', '薯条'}), items_add=frozenset({'可乐'}), confidence=1.0, lift=1.0)])
# 调用 apriori 函数results = apriori(orders, min_support=0.2, min_confidence=0.7)# 遍历结果数据for result in results:# 获取支持度,并保留3位小数support = round(result.support, 3)# 遍历ordered_statistics对象for rule in result.ordered_statistics:# 获取前件和后件并转成列表head_set = list(rule.items_base)tail_set = list(rule.items_add)# 跳过前件为空的数据if head_set == []:continue# 将前件、后件拼接成关联规则的形式related_catogory = str(head_set)+'→'+str(tail_set)# 提取置信度,并保留3位小数confidence = round(rule.confidence, 3)# 提取提升度,并保留3位小数lift = round(rule.lift, 3)# 查看强关联规则,支持度,置信度,提升度print(related_catogory, support, confidence, lift)test1 = pd.DataFrame({'班级': [1, 2, 2, 1], '姓名': ['王薇', '刘敏', '陈芳', '袁芬']})test1 = test1.groupby(['班级']).sum()test1# 定义“格式转换”函数def conversion_data(category):# 判断文章类别是否已经转成了列表格式if str(category)[0] == '[':# 直接返回文章类别return category# 返回转成列表格式后的文章类别return [category]# 获取'文章类别'列,调用 agg() 方法analysis_data['文章类别'] = analysis_data['文章类别'].agg(conversion_data)# 查看处理后的数据analysis_data
# 执行Apriori 算法results = apriori(adjusted_data['文章类别'], min_support=0.1, min_confidence=0.3)# 创建列表extract_result = []for result in results:# 获取支持度,并保留3位小数support = round(result.support, 3)# 遍历ordered_statistics对象for rule in result.ordered_statistics:# 获取前件和后件并转成列表head_set = list(rule.items_base)tail_set = list(rule.items_add)# 跳过前件为空的数据if head_set == []:continue# 将前件、后件拼接成关联规则的形式related_catogory = str(head_set)+'→'+str(tail_set)# 提取置信度,并保留3位小数confidence = round(rule.confidence, 3)# 提取提升度,并保留3位小数lift = round(rule.lift, 3)# 将提取的数据保存到提取列表中extract_result.append([related_catogory, support, confidence, lift])# 将数据转成 DataFrame 的形式rules_data = pd.DataFrame(extract_result, columns=['关联规则', '支持度', '置信度', '提升度'])# 将数据按照“支持度”排序sorted_by_support = rules_data.sort_values(by='支持度')# 查看排序后的数据sorted_by_support
import matplotlib.pyplot as pltimport warnings# 关闭警告显示warnings.filterwarnings('ignore')# 设置中文字体plt.rcParams['font.family'] = ['Source Han Sans CN']# 创建df数据hairs = pd.DataFrame([['许钢铁', 6, 5], ['王铁锤', 8, 7], ['林志龙', 9, 7]], columns=['姓名', '去年发量', '今年发量'])# 绘制基本柱状图plt.bar(hairs.index, height=hairs['去年发量'], width=0.4)plt.bar(hairs.index-0.2, height=hairs['去年发量'], width=0.4)
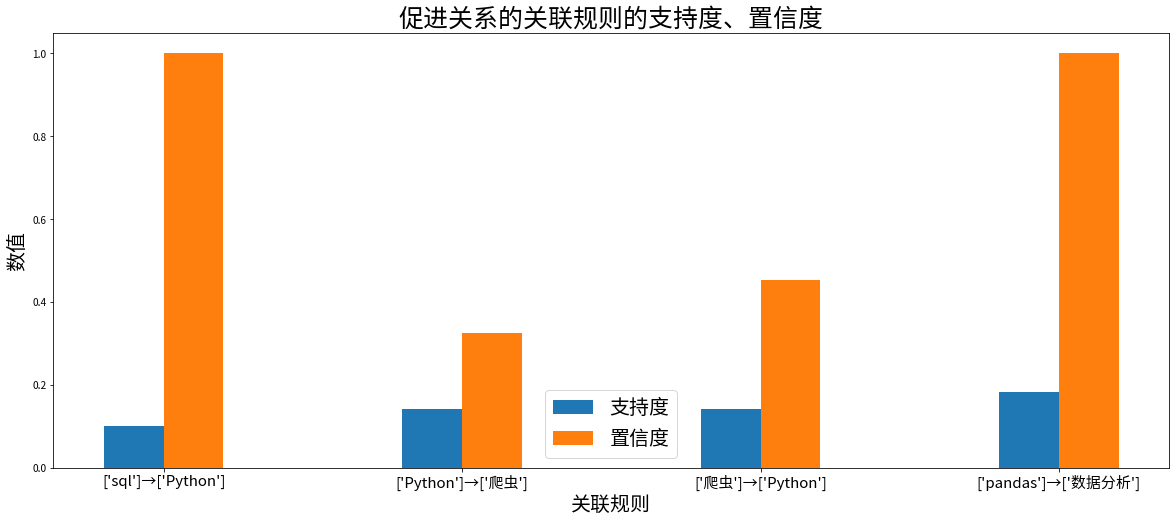
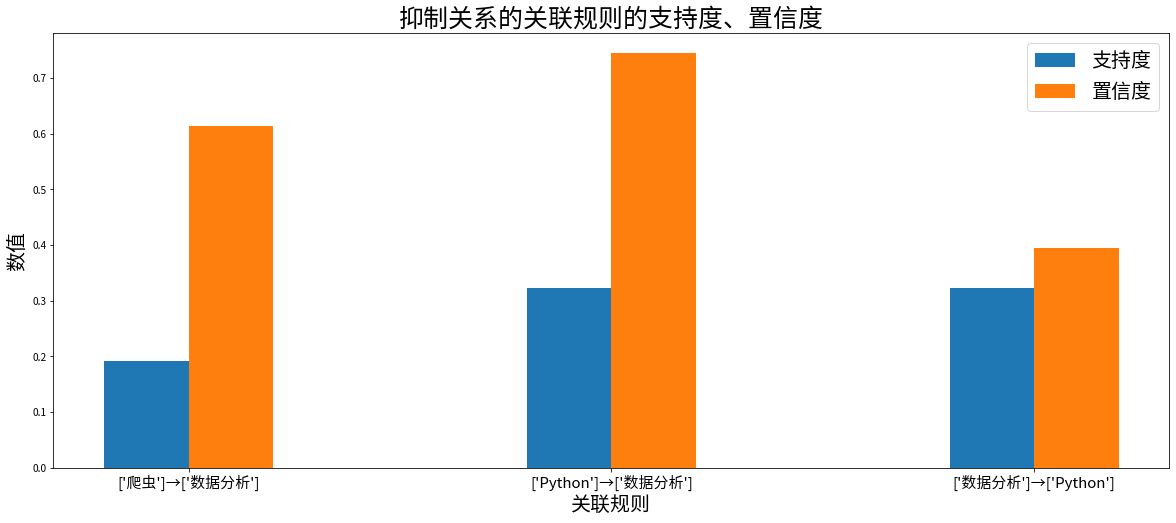
# 功能:绘制提升度大于 1 的强关联规则柱状图# 设置画布尺寸plt.figure(figsize=(20, 8))# 设置横纵坐标以及柱子的宽度width = 0.2# 画出柱状图plt.bar(promoted_rules.index-width/2, promoted_rules['支持度'], width=width)plt.bar(promoted_rules.index+width/2, promoted_rules['置信度'], width=width)# 设置图例plt.legend(['支持度', '置信度'], fontsize=20)# 设置标题plt.title('促进关系的关联规则的支持度、置信度', fontsize=25)# 设置刻度名称plt.xticks(promoted_rules.index, promoted_rules['关联规则'], fontsize=15)# 设置坐标轴标签plt.xlabel('关联规则', fontsize=20)plt.ylabel('数值', fontsize=20)# 功能:绘制提升度小于 1 的强关联规则柱状图# 设置画布尺寸plt.figure(figsize=(20, 8))# 画出柱状图plt.bar(restricted_rules.index-width/2, restricted_rules['支持度'], width=width)plt.bar(restricted_rules.index+width/2, restricted_rules['置信度'], width=width)# 设置图例plt.legend(['支持度', '置信度'], fontsize=20)# 设置标题plt.title('抑制关系的关联规则的支持度、置信度', fontsize=25)# 设置刻度名称plt.xticks(restricted_rules.index, restricted_rules['关联规则'], fontsize=15)# 设置坐标轴标签plt.xlabel('关联规则', fontsize=20)plt.ylabel('数值', fontsize=20)
# 功能:绘制提升度柱状图# 设置画布尺寸plt.figure(figsize=(20, 8))# 画出柱状图plt.bar(sorted_by_support.index, sorted_by_support['提升度'], width=width)# 设置标题plt.title('提升度柱状图', fontsize=25)# 设置刻度名称plt.xticks(sorted_by_support.index, sorted_by_support['关联规则'], fontsize=15)# 设置坐标轴标签plt.xlabel('关联规则', fontsize=20)plt.ylabel('提升度', fontsize=20)# 设置数据标签for a, b in zip(sorted_by_support.index, sorted_by_support['提升度']):plt.text(a, b, b, ha='center', va='bottom', fontsize=12)
支持度=Support=P(A&B)
置信度=Confidence=P(A&B)/P(A)
提升度=Lift=( P(A&B)/P(A))/P(B)=P(A&B)/P(A)/P(B)
# 导入 matplotlib 库import matplotlib.pyplot as plt# 设置字体plt.rcParams['font.family'] = ['Source Han Sans CN']# 设置画布尺寸plt.figure(figsize=(20, 8))# 画出以置信度为高度的柱状图,x 坐标为 rules_data.index-0.1,设置柱子的宽度为 0.2plt.bar(rules_data.index-0.1, rules_data['置信度'], width=0.2)# 画出以支持度为高度的柱状图,x 坐标为 rules_data.index+0.1,设置柱子的宽度为 0.2plt.bar(rules_data.index+0.1, rules_data['支持度'], width=0.2)# 导入 matplotlib 库import matplotlib.pyplot as plt# 设置字体plt.rcParams['font.family'] = ['Source Han Sans CN']# 设置画布尺寸plt.figure(figsize=(20, 8))# 画出以置信度为高度的柱状图,x 坐标为 rules_data.index-0.1,设置柱子的宽度为 0.2plt.bar(rules_data.index-0.1, rules_data['置信度'], width=0.2)# 画出以支持度为高度的柱状图,x 坐标为 rules_data.index+0.1,设置柱子的宽度为 0.2plt.bar(rules_data.index+0.1, rules_data['支持度'], width=0.2)# 设置名称分别为置信度、支持度的图例,设置字体大小(fontsize)为 15plt.legend(['置信度', '支持度'], fontsize=15)# 设置标题为“关联规则的置信度、支持度柱状图”,设置字体大小(fontsize)为 20plt.title('关联规则的置信度、支持度柱状图', fontsize=20)# 设置刻度名称为对应的“关联规则”,刻度间隔为 rules_data.indexplt.xticks(rules_data.index, rules_data['关联规则'])# 设置坐标轴标签plt.xlabel('关联规则', fontsize=15)plt.ylabel('数值', fontsize=15)# 部分唐朝诗人数据df_2 = pd.DataFrame({'诗人': ['白居易', '李白', '杜甫', '王勃', '王维'],'称号': ['诗魔', '诗仙', '诗圣', '诗杰', '诗佛'],'年龄': [74, 61, 58, 26, 60],'诗歌大致数量': [3000, 900, 1500, 80, 400]})# 按诗人的诗歌大致数量从高到低进行排序并重置行索引df_2 = df_2.sort_values(by='诗歌大致数量', ascending=False).reset_index(drop=True)# 查看数据df_2# 部分唐朝诗人数据df_3 = pd.DataFrame({'诗人': ['白居易', '李白', '杜甫', '王勃', '王维'],'称号': ['诗魔', '诗仙', '诗圣', '诗杰', '诗佛'],'年龄': [74, 61, 58, 26, 60],'诗歌大致数量': [3000, 900, 1500, 80, 400]})# 按诗人的诗歌大致数量从高到低进行排序并重置行索引df_3 = df_3.sort_values(by='诗歌大致数量', ascending=False, ignore_index=True)# 查看数据df_3# 带有重复行的部分唐朝诗人数据df_5 = pd.DataFrame({'诗人': ['白居易', '李白', '杜甫', '王勃', '王勃', '王维'],'称号': ['诗魔', '诗仙', '诗圣', '诗杰', '诗杰', '诗佛'],'年龄': [74, 61, 58, 26, 26, 60],'诗歌大致数量': [3000, 900, 1500, 80, 80, 400]})# 使用 drop_duplicates() 方法删除重复行并用 ignore_index 参数重置行索引df_5 = df_5.drop_duplicates(ignore_index=True)# 查看数据df_5
# 将数据写入到【新成绩单.xlsx】工作簿中的【2 班】工作表data_2.to_excel('新成绩单.xlsx', sheet_name='2 班', index=False)data_5['总分'] = data_5['语文'] + data_5['数学'] + data_5['英语'].astype(int)data_5data_6 = pd.DataFrame({'商品名':['猪头皮', '醋', '高压锅'], '单价': [10, 13, 800], '数量':['5', '2', '1']})data_6# 创建一个 DataFrame 对象的数据data_7 = pd.DataFrame({'性别':['难', '女', '难', '女', '女'],'城市':['.', '潮州市', '山头市', '汕尾市', '山头市'],'年龄':[25, 26, 24, 25, 26],'爱好':['蓝球', '跑步', '跳舞', '逛街', '读书']})data_7# 定义字典 fix_typofix_typo = {'山头市':'汕头市', '蓝球':'篮球'}# 对【城市】、【爱好】列的错字进行修改data_7 = data_7.replace(fix_typo)data_7# 定义字典 fix_typofix_typo = {'山头市':'汕头市', '蓝球':'篮球'}# 对【城市】列的错字进行修改data_7['城市'] = data_7['城市'].replace(fix_typo)data_7
# 按【用户 ID】分组后,获取【时间间隔】列的最小值、【订单号】列的数量,以及【总金额】列的总和rfm_data = grouped_data.groupby('用户 ID', as_index=False).agg({'时间间隔': 'min', '订单号': 'count', '总金额': 'sum'})# 导入 pandas 库import pandas as pd# 书籍的部分销售数据df_1 = pd.DataFrame({'书名': ['狂人日记', '活着', '狂人日记', '格林童话', '活着', '格林童话', '周易', '论语', '活着', '论语', '狂人日记', '周易'],'销售金额': [30, 50, 90, 40, 25, 60, 50, 120, 25, 40, 60, 50],'数量': [1, 2, 3, 2, 1, 3, 1, 3, 1, 1, 2, 1]})# 根据`书名`进行分组,同时对销售金额和数量进行求和,要包含自带的行索引df_1 = df_1.groupby(by='书名', as_index=False).sum()# 查看数据df_1# 根据`书名`进行分组,同时对销售金额和数量进行求和,不包含自带的行索引,用书名作为行索引df_2 = df_2.groupby(by='书名', as_index=True).sum()# 查看数据df_2# 某男子私立大学三名延毕学生数据df_4 = pd.DataFrame({'姓名': ['零某某', '徐放牛', '文学'],'性别': ['男', '女', '女'],'专业': ['生物信息', '人工智能', '文学'],'挂科次数': ['7', '5', '4'],'旷课次数': [45, 44, 30]})# 新建一个总次数列来计算挂科次数和旷课次数的和df_4['总次数'] = df_4['挂科次数'].astype(int) + df_4['旷课次数']# 查看数据df_4# 某男子私立大学三名延毕学生数据df_5 = pd.DataFrame({'姓名': ['零某某', '徐放牛', '文学'],'性别': ['男', '女', '女'],'专业': ['生物信息', '人工智能', '文学'],'挂科次数': ['7', '5', '4'],'旷课次数': [45, 44, 30],'总次数': [52, 49, 34]})# 第一种方式:对所有列的指定数据进行批量替换data_1 = df_5.replace({'女': '男', '文学': '电子竞技'})# 第二种方式:对指定列的指定数据进行批量替换data_2 = df_5# 替换性别data_2['性别'] = data_2['性别'].replace({'女': '男'})# 替换专业data_2['专业'] = data_2['专业'].replace({'文学': '电子竞技'})# 打印结果print(data_1)print(data_2)# 某男子私立大学三名延毕学生数据df_7 = pd.DataFrame({'姓名': ['零某某', '徐放牛', '文学'],'性别': ['男', '男', '男'],'专业': ['生物信息', '人工智能', '电子竞技'],'挂科次数': ['7', '5', '4'],'旷课次数': [45, 44, 30],'总次数': [52, 49, 34]})# 先定义一个函数def map_judge(x):if x >= 50:return "开除"else:return "延毕"# 将函数 map_judge 作为参数传入 df.map()df_7['总次数'] = df_7['总次数'].map(map_judge)# 查看数据df_7

若有收获,就点个赞吧
0 人点赞
