RDD的血缘关系
RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列 Lineage (血统)记录下来,以便恢复丢失的分区。RDD 的 Lineage 会记录 RDD 的元数据信息和转 换行为,当该 RDD 的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
RDD 依赖关系
这里所谓的依赖关系,其实就是两个相邻 RDD 之间的关系。
RDD 窄依赖
窄依赖表示每一个父(上游)RDD 的 Partition 最多被子(下游)RDD 的一个 Partition 使用, 窄依赖我们形象的比喻为独生子女。
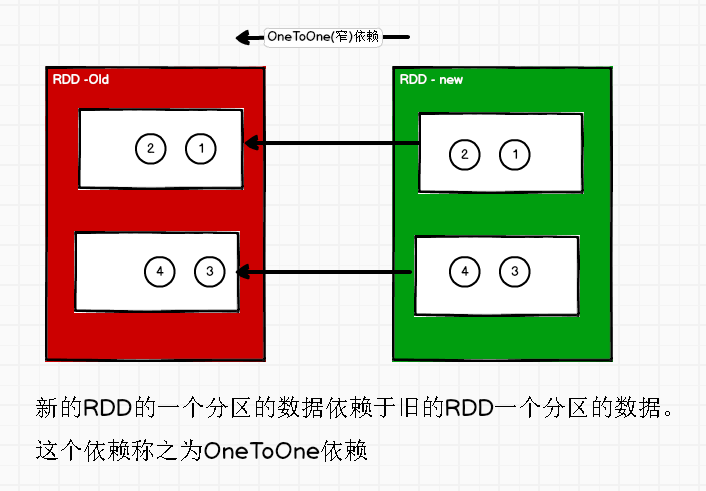
RDD 宽依赖
宽依赖表示同一个父(上游)RDD 的 Partition 被多个子(下游)RDD 的 Partition 依赖,会引起 Shuffle,总结:宽依赖我们形象的比喻为多生。
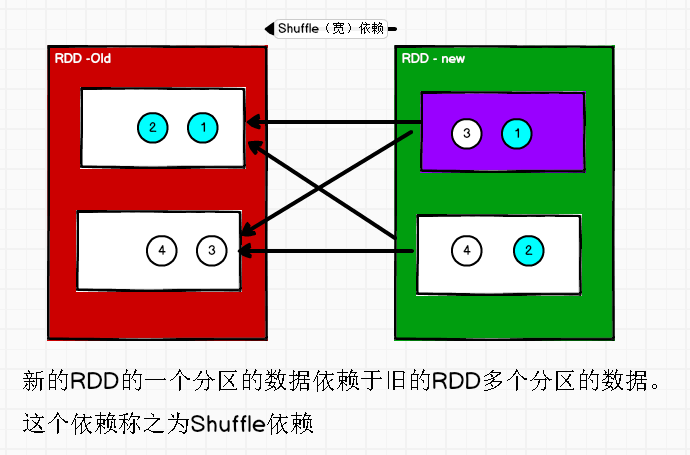
RDD 阶段划分
DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向, 不会闭环。例如,DAG 记录了 RDD 的转换过程和任务的阶段。
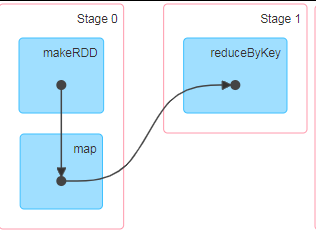
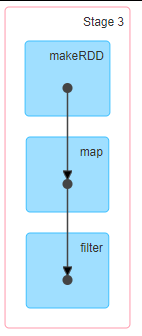
RDD 任务划分
RDD 任务切分中间分为:Application、Job、Stage 和 Task
1, Application:初始化一个 SparkContext 即生成一个 Application;
2, Job:一个 Action 算子就会生成一个 Job;
3, Stage:Stage 等于宽依赖(ShuffleDependency)的个数加 1;
4, Task:一个 Stage 阶段中,最后一个 RDD 的分区个数就是 Task 的个数。
注意:Application->Job->Stage->Task 每一层都是 1 对 n 的关系。
遇到一次宽依赖,就会划分一个stage。
因此spark划分stage的整体思路是:从后往前推,遇到宽依赖就断开,划分为一个stage;遇到窄依赖就将这个RDD加入该stage中。

若有收获,就点个赞吧
0 人点赞
