1、分类大纲
java集合的基本分类请看processOn文件:https://www.processon.com/mindmap/627fbb0e5653bb45ea679561
如图: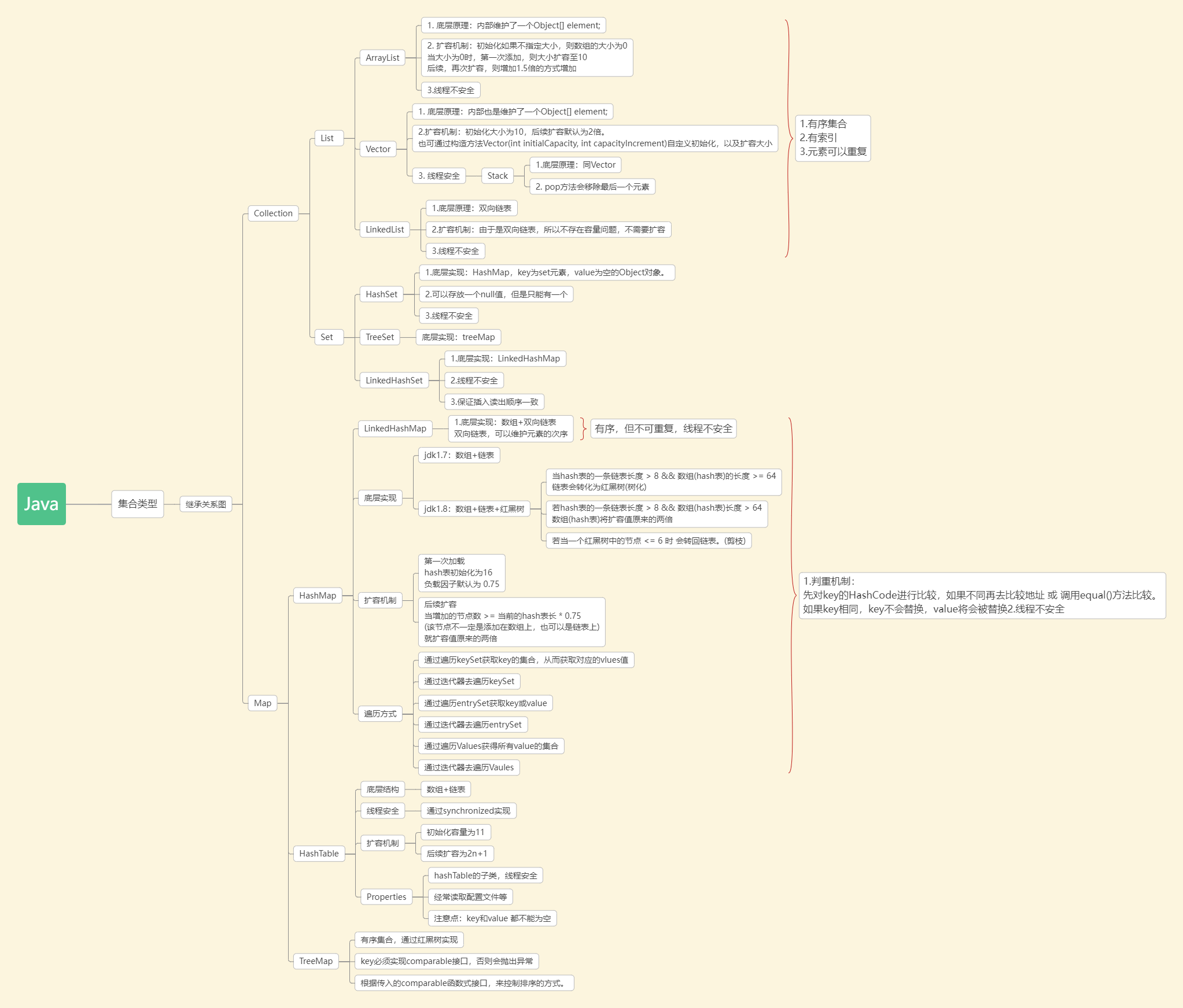
2、List基本介绍
单列元素。
2.1 ArrayList
特点:底层是elementData【】数组,查询块,增删慢,有序可重复,可以存储null值,线程不安全。
扩容机制:若使用无参构造器,则初始容量0,第一次添加,则扩容elementData为10,如需再次扩容,则扩容elementData为1.5倍;若使用有参构造器,则初始elementData容量为指定大小,如果需要扩容,则直接扩容elementData为1.5倍;扩容最终使用的Arrays.copyof()方法;最大容量Integer.MAX_VALUE - 8。
2.2 Vector
特点:和ArrayList基本一致,区别就是Vector是线程安全的,Vector 类的操作方法带有 ==synchronized==。
扩容机制:如果使用无参构造函数,默认10,满后,就按2倍扩容。如果指定大小,则每次直接按2倍扩容。
2.3 LinkedList
特点:LinkedList底层实现了双向链表。LinkedList中维护了两个属性 first 和 last 分别指向 首节点和尾节点,每个节点(Node对象),里面又维护了prev、next、item、三个属性,其中通过prev指向前一个,通过next指向后一个节点。最终实现双向链表。
有序,可重复。查询慢,增删快。线程不安全。
3、Set基本介绍
单列元素。
3.1 HashSet
特点:底层是HashMap,而HashMap的底层是数组+单向链表+红黑树。无序,不能重复(好好看源码理解“不能重复”,对象一般可以重复,但是字符串不可重复,主要看元素的equals() 和 hashCode()方法),可以为null(仅有一个),线程不安全。
第一次添加元素时,table数组扩容到16,临界值(threshold)是:16 0.75(loadFactor,加载因子)= 12。到达12后,再添加元素,会翻倍扩容到:162=32,新的临界值就是320.75 = 24,依次类推。
*扩容机制:
- 添加一个元素时,先得到hash值,再将hash值转化为索引值(放在数组的哪个位置)。
- 找到数据表,查看该索引的位置是否有元素。
- 若没有元素,则直接添加。若有元素,则调用equals()方法比较,如果相同,则不添加,若不同,则加在尾部(即链表里边)。
jdk8中,当链表中元素的个数达到8,同时数组中的个数超过64时,就会进化成红黑树(进一步提高查询效率)。 注:若链表中元素的个数到8,而数组未到64,则按数组容量*2进行扩容,直到扩容到64,再树化。
3.2 LinkedHashSet
特点:LinkedHashSet是HashSet的子类。底层是LinkedHashMap,维护了一个数组+双向链表(这是它和HashSet的主要区别)。不允许重复,有序,线程不安全,。
特别说明:在LinkedHashSet中维护了一个双向链表(有head和tail),每一个节点都有before和after属性,这样可以形成双向链表。
- 在添加元素时,先计算hash值,再计算索引,以确定元素在table的位置,然后将元素添加到双向链表(如果已存在,则不添加,和HashSet一样)。
- 由于双向链表的存在,我们插入元素和取出元素的顺序,是一致的。
3.3 TreeSet
特点:它的底层是TreeMap。
TreeMap底层是树形(红黑树)结构,作为Map的一员,包含着key—value形式的元素,和HashMap最大的区别是丢进去的东西自动排序。要注意的是默认的是对Key排序,也可以重写Comparator对Value排序,很方便。4、Map基本介绍
双列元素。
4.1 HashMap
特点:这是我们工作中最经常用到的,用于保存具有映射关系的数据:Key-Value,底层是数组+单向链表+红黑树。Key不允许重复(相同则替换),可以为null(仅有一个),Value可以重复。无序。线程不安全。
扩容机制:跟HashSet一样(因为HashSet底层就是HashMap)
- 添加一个元素时,先得到hash值,再将hash值转化为索引值(放在数组的哪个位置)。
- 找到数据表,查看该索引的位置是否有元素。
- 若没有元素,则直接添加。若有元素,则调用equals()方法比较,如果相同,则替换,若不同,则加在尾部(即链表里边)。
- jdk8中,当链表中元素的个数达到8,同时数组中的个数超过64时,就会进化成红黑树(进一步提高查询效率)。 注:若链表中元素的个数到8,而数组未到64,则按数组容量*2进行扩容,直到扩容到64,再树化。(链表长度减到6会减枝)
扩容为什么是2的幂次方?
HashMap长度为2的幂次方的原因是为了减少Hash碰撞,尽量使Hash算法的结果均匀。
首先看一下HashMap中putVal方法的源码: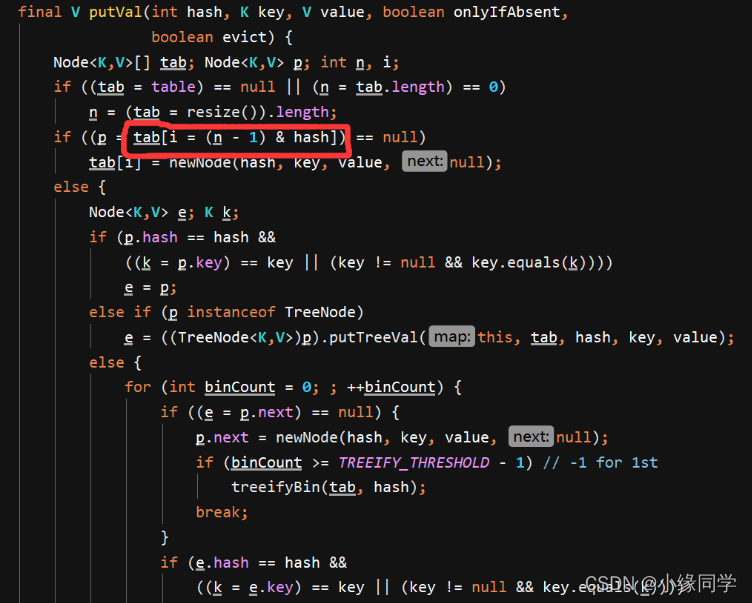
其中有个( n - 1) & hash的方法,那么这个方法是干什么的呢?
HashMap为了存取高效,就要尽量减少碰撞,将数据分配均匀,那么如何分配均匀,此时主要靠将数据存入到那个链表中的算法,这个算法就是( n - 1) & hash。& 是按位与运算,是一个位运算,而在计算机中位运算的效率很高,这就是不用%运算的原因。
按位与&的计算方式为当对应位置的数据都为1时,运算结果也为1。因此当HashMap的容量是2的幂次方时,( n - 1)的2进制都是111..11的形式,在与添加元素的hash值进行位运算时能够充分的散列,使添加的元素能均匀的分布在HashMap的每个位置上,减少hash碰撞。
4.2 Hashtable
特点:底层书数组+链表,初始容量为11,扩容加载因子0.75,键和值都不能为null,键不允许重复,相同则替换,线程安全。
扩容机制:
扩容后长度 = 扩容前table长度 * 2 +1
4.3 TreeMap
特点:TreeMap底层是树形(红黑树)结构,作为Map的一员,包含着key—value形式的元素,和HashMap最大的区别是丢进去的东西自动排序。要注意的是默认的是对Key排序,也可以重写Comparator对Value排序,很方便。

若有收获,就点个赞吧
0 人点赞
