ID生成问题
数据唯一ID用于标识一条记录,消息,指令等等,是软件开发必不可少的一个东西。ID最基本的要求是全局唯一,传统的生成策略有UUID、数据库自增序列等;特定场景下还会要求能够表达一定的语义,如20190724120005_1,用_将ID分成两部分,前半部分表示具体的时间(精确到秒),后半部分为递增序列,顺序标识这一秒内的记录。要实现类似这样的ID,需要在内存中缓存一个递增计数器,计数器以秒为单位周期性重置为0,同一秒内顺序递增。另外还需要注意并发和时钟回拨问题,如下示例代码,利用synchronized 解决并发冲突,同时缓存最近10秒内的计数器,解决10秒范围内的时钟跳变。
public static String genInfoID() {SimpleDateFormat dateFormat = new SimpleDateFormat(TIMEFORMAT);String keyPrefix = dateFormat.format(new Date());Long num = 0L;synchronized (counterMap.getClass()) {if (counterMap.get(keyPrefix) == null) {counterMap.put(keyPrefix, 1L);num = 1L;} else {num = counterMap.get(keyPrefix) + 1;counterMap.put(keyPrefix, num);}if (counterMap.size() > 10) {counterMap.remove(counterMap.firstKey());}}return keyPrefix + "_" + num;}
该方法在单机模式下看起来没什么问题,但随着业务规模的扩大,需要部署集群服务时,就出问题了:由于分别在每台机器内存中缓存了计数器,集群中多台机器生成的序号会重复。
一种优化策略是将计数器部分独立出来,如放到redis中供集群中所有机器共享,代码修改为如下内容:
public static String genInfoGroupID() {// 根据日期信息构造redis中的keySimpleDateFormat dateFormat = new SimpleDateFormat(TIMEFORMAT);String keyPrefix = dateFormat.format(new Date());Long num = 0L;RedisUtil redisUtil = RedisUtil.getRedisUtil();try {// redis方法获取自增序号num = redisUtil.incr("groupid:" + keyPrefix);// 设置过期时间,由于key是绑定到具体时刻(精确到秒)的,理论上设置1s失效即可。为防止校时错误设置为300s失效redisUtil.expire("groupid:" + keyPrefix, 300);return keyPrefix + "_" + num;} catch (Exception e) {e.printStackTrace();} finally {redisUtil.close();}return null;}
这个方案引入了redis中间件,增加了系统复杂度,并且对redis强依赖,容易形成性能瓶颈和单点故障。而我们对ID生成模块的性能和可用性要求是极高的,试想如果ID生成失败,意味着业务数据无法入库,整个系统都会瘫痪了。因此需要增加redis集群来进一步优化,又进一步增加了系统的复杂度。如果系统本身就用到了Redis集群来缓存一些业务数据,这个方案还是比较出色的,否则单纯为了一个ID生成功能而引入这么多依赖并不划算。那么还有什么更好的分布式ID生成方案吗?
SnowFlake算法
snowflake算法(雪花算法)是Twitter开源的一个分布式ID生成算法,它简单高效,可以说是分布式ID问题经典的解决方案。像百度、美团等互联网大厂的解决方案都是以此为基础的,后文会详细总结这些内容,我们先来了解一下这个算法。
算法介绍
snowflake算法的基本思路是用一个Long类型变量存储ID,Long占8个字节,共有64位。将这64位划分为如下几个部分: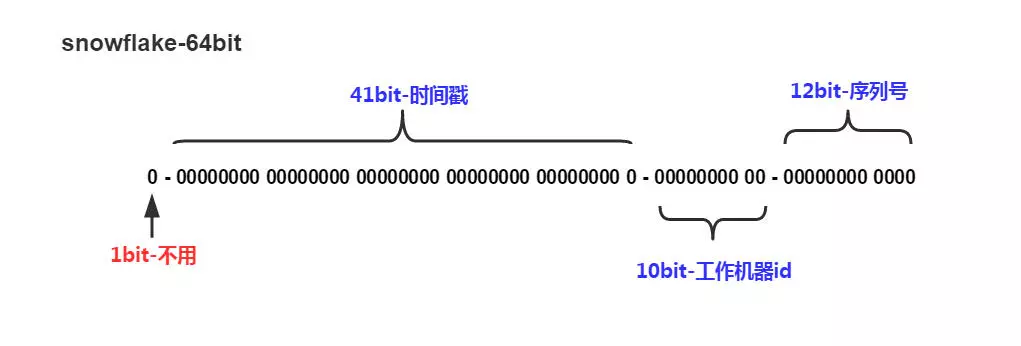
如上图所示,第一位不用,后面41位用来存储时间戳,表示当前时间距起始时间的毫秒数,共可以存储69.7年(2^41/1000_60_60_24_265);后面10位用来区分机器ID,共可以区分1024台机器,后12位顺序递增,表示同一机器同一毫秒内的并发数据,支持单机并发4096000/秒。
时钟回拨和机器ID配置问题
雪花算法存在一个时钟回拨问题:如果服务器时间向后跳变,跳变后那段时间内又恰好生成过ID,可能会产生ID冲突。官方对此并没有给出解决方案,只是进行了抛出异常处理。参考上文,将一定时间段内的计数器进行缓存,可以缓解该问题。
另外,10位机器ID如何配置也是个问题,如果将机器ID写在配置文件中,势必会大大增加运维成本。
扩展方案
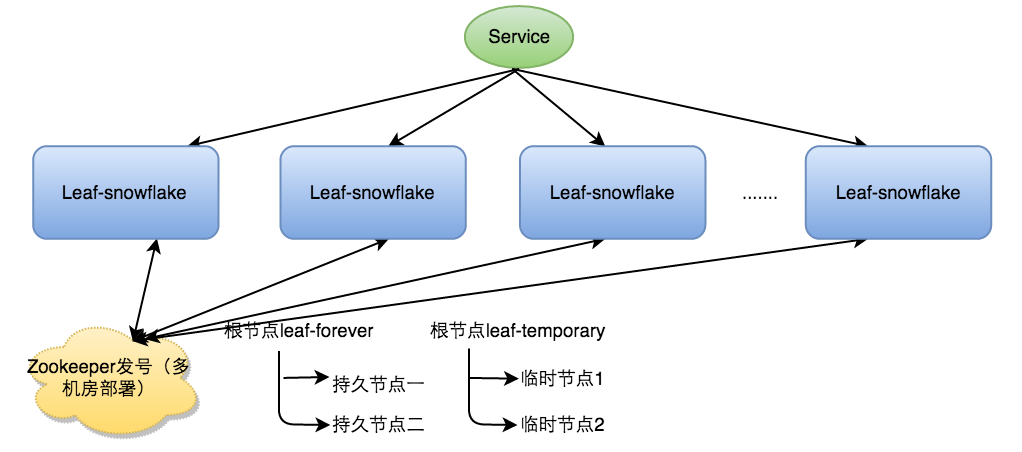
美团Leaf-snowflake方案
美团Leaf-snowflake核心还是snowflake算法,完全遵循1+41+10+12模式。并且从以下两方面进行了优化,确保算法落地:(引用自https://tech.meituan.com/2017/04/21/mt-leaf.html)
机器ID自动获取
Leaft-snowflake方案引入zookeeper,使用zookeeper持久顺序节点的特性自动对snowflake节点配置workerID,具体步骤如下:
- 启动Leaf-snowflake服务,连接Zookeeper,在leaf_forever父节点下检查自己是否已经注册过(是否有该顺序子节点)。
- 如果有注册过直接取回自己的workerID(zk顺序节点生成的int类型ID号),启动服务。
- 如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的workerID号,启动服务。
周期性服务器时间校对
通过与集群中所有机器的时间进行周期性校对,判断节点是否可靠。具体步骤如下: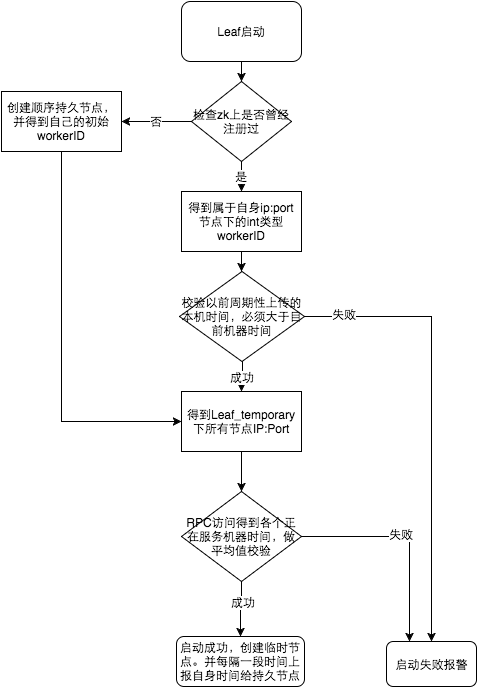
参见上图整个启动流程图,服务启动时首先检查自己是否写过ZooKeeper leaf_forever节点:
- 若写过,则用自身系统时间与leaf_forever/${self}节点记录时间做比较,若小于leaf_forever/${self}时间则认为机器时间发生了大步长回拨,服务启动失败并报警。
- 若未写过,证明是新服务节点,直接创建持久节点leaf_forever/${self}并写入自身系统时间,接下来综合对比其余Leaf节点的系统时间来判断自身系统时间是否准确,具体做法是取leaf_temporary下的所有临时节点(所有运行中的Leaf-snowflake节点)的服务IP:Port,然后通过RPC请求得到所有节点的系统时间,计算sum(time)/nodeSize。
- 若abs( 系统时间-sum(time)/nodeSize ) < 阈值,认为当前系统时间准确,正常启动服务,同时写临时节点leaf_temporary/${self} 维持租约。否则认为本机系统时间发生大步长偏移,启动失败并报警。
- 每隔一段时间(3s)上报自身系统时间写入leaf_forever/${self}。
百度uid-generator方案
百度的这个方案我个人认为很优雅巧妙,同时又是非常具备创新性的。它通过借用未来时间来解决了时间回拨问题,同时使用自增列解决workerid冲突问题,使用RingBuffer来提高ID生成速度。这一套组合下来,足以使其成为通用的工业级分布式ID生成解决方案。
自增列解决workid冲突问题
与美团的zookeeper方案不同,uid-generator使用数据库自增列来生成workerid,即使是同一机器,每次生成的workerid也不一样,确保workerid不冲突。
RingBuffer预生成策略
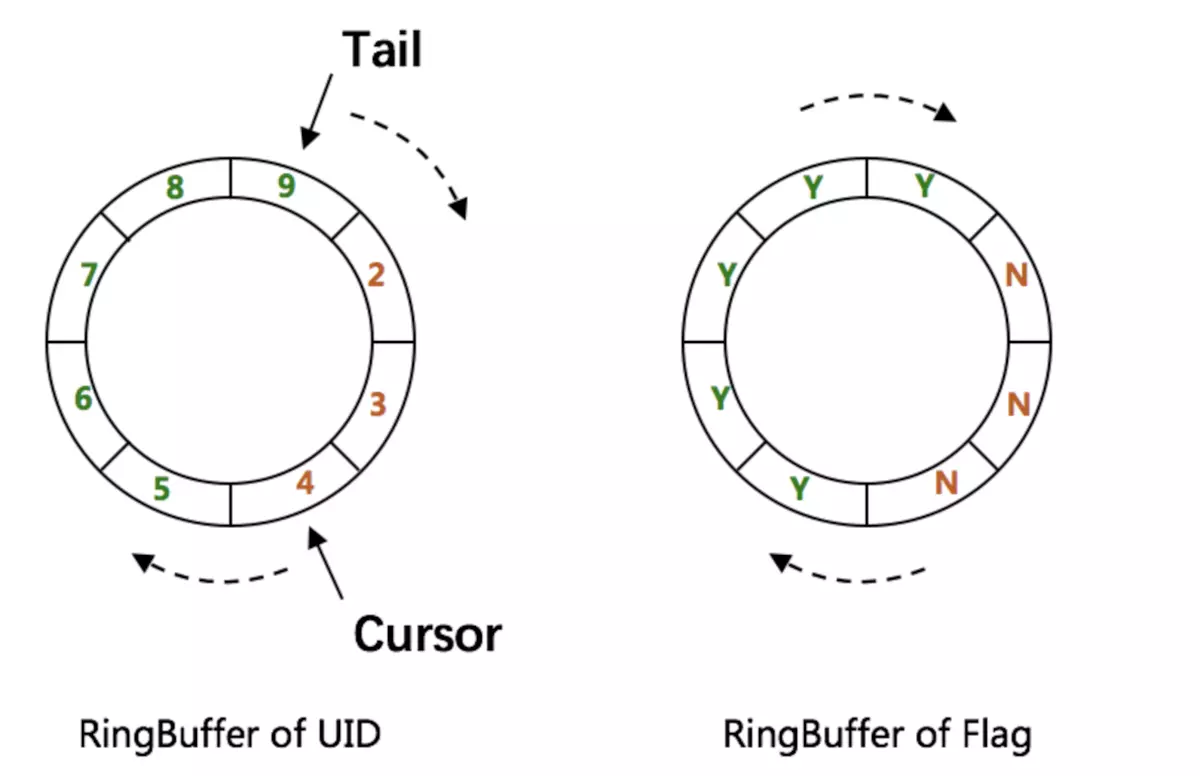
如图所示,uid-generator并不是在每次请求时实时生成ID,而是预先生成一批ID放到RingBuffer中,每次调用时直接从Buffer中获取。
借用未来时间解决时钟回拨问题
uid-generator方案在每次buffer中剩余空间不足50%时,会开启一个线程往buffer中填充新的ID。新ID生成策略还是以snowflake算法为原型,只是其中的时间戳部分不再是传统的System.currentTimeMillis()方式获取服务器时间了,而是引入AtomicLong类型变量lastSecond存储上次时间戳,调用lastSecond.incrementAndGet()来获得新的时间戳。
这是uid-generator一大创新,从根本上解决了服务器时间回拨的问题。但也会带来ID中时间记录不准确的问题。例如:获取的某分布式ID的值为3200169789968523265,它的反解析结果为{“timestamp”:”2019-05-02 23:26:39”,”workerId”:”21”,”sequence”:”1”},但是这个ID可能并不是在”2019-05-02 23:26:39”这个时间产生的。
微信seqsvr序列号生成方案
最后说一下微信的序列号生成方案。微信序列号也是一个递增的64位整型变量,与上述不同的是,作为实时通讯工具,微信需要的是一个可靠递增的ID,上面的雪花算法由于有随机的workerid部分,并不能保证可靠递增。并且微信用户数亿,还需要解决极高的并发量问题。
鉴于此,微信为每个用户分配了一个独立sequence空间,每一份数据都赋予一个唯一的、递增的sequence。如果不考虑具体架构,应该是一个极大的64位数组:
每个用户都在这个数组中独占一格8字节空间,各自中存放上次分配出去的sequence:cur_seq。这样当新请求来时,只需找到对应的用户记录,将cur_seq++即可。
递增的问题解决了,下面要面临的是超高并发下的可靠性问题。考虑到可靠,很容易想到将这个数组持久化到硬盘中,但高并发场景下每次都从硬盘中读取,性能明显是接受不了的。
预分配中间层
考虑到只需要递增,并没有要求连续,微信设计了预分配中间层来大幅减少硬盘读取次数:
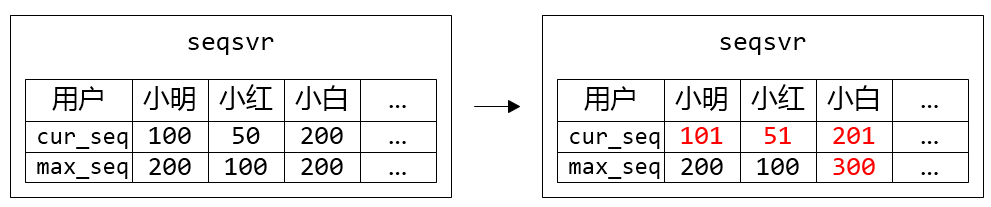
- 内存中储存最近一个分配出去的 sequence:cur_seq,以及分配上限:max_seq
- 分配 sequence 时,将 cur_seq++,同时与分配上限 max_seq 比较:如果 cur_seq > max_seq,将分配上限提升一个步长 max_seq += step,并持久化 max_seq
- 重启时,读出持久化的 max_seq,赋值给 cur_seq
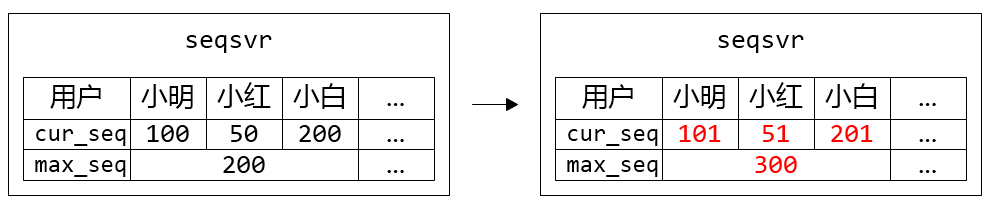
进一步,为了减少max_seq的占用空间,可以引入用户段的概念,多个用户共享一个max_seq:
总结
分布式ID生成算法主要关注的点有以下几个方面:
- 全局唯一,这是最基本的要求。基于时间的ID需要考虑时间回拨问题
- 递增性要求,像snowflake系列可以保证趋势递增,像微信等IM系统、数据库事务等则需要保证单调递增
- 信息安全,避免ID泄漏机器信息,或者被竞争对手利用递增特性来估算业务量;
单以snowflake为原型,分布式ID方案就有很多变种,有时候方案并没有一定的章法和优劣之分,架构设计时还是以合适原则为第一要务,有时候这是一门权衡的艺术,要A就要舍弃B。如百度ui-generator采用借用未来时间解决时间回拨问题,相应的就失去了在ID中准确记录时间戳的功能;微信采用预分配层解决硬盘读取次数,响应的就失去了ID的连续性等等。
参考资料
微信序列号生成器架构设计及演变
百度开源的分布式唯一ID生成器UidGenerator
uid-generator
Leaf——美团点评分布式ID生成系统
Year 2038 problem

若有收获,就点个赞吧
0 人点赞
