CMS是老年代垃圾收集器,在收集过程中可以与用户线程并发操作。它可以与Serial收集器和Parallel New收集器搭配使用。CMS牺牲了系统的吞吐量来追求收集速度,适合追求垃圾收集速度的服务器上。可以通过JVM启动参数:-XX:+UseConcMarkSweepGC来开启CMS。
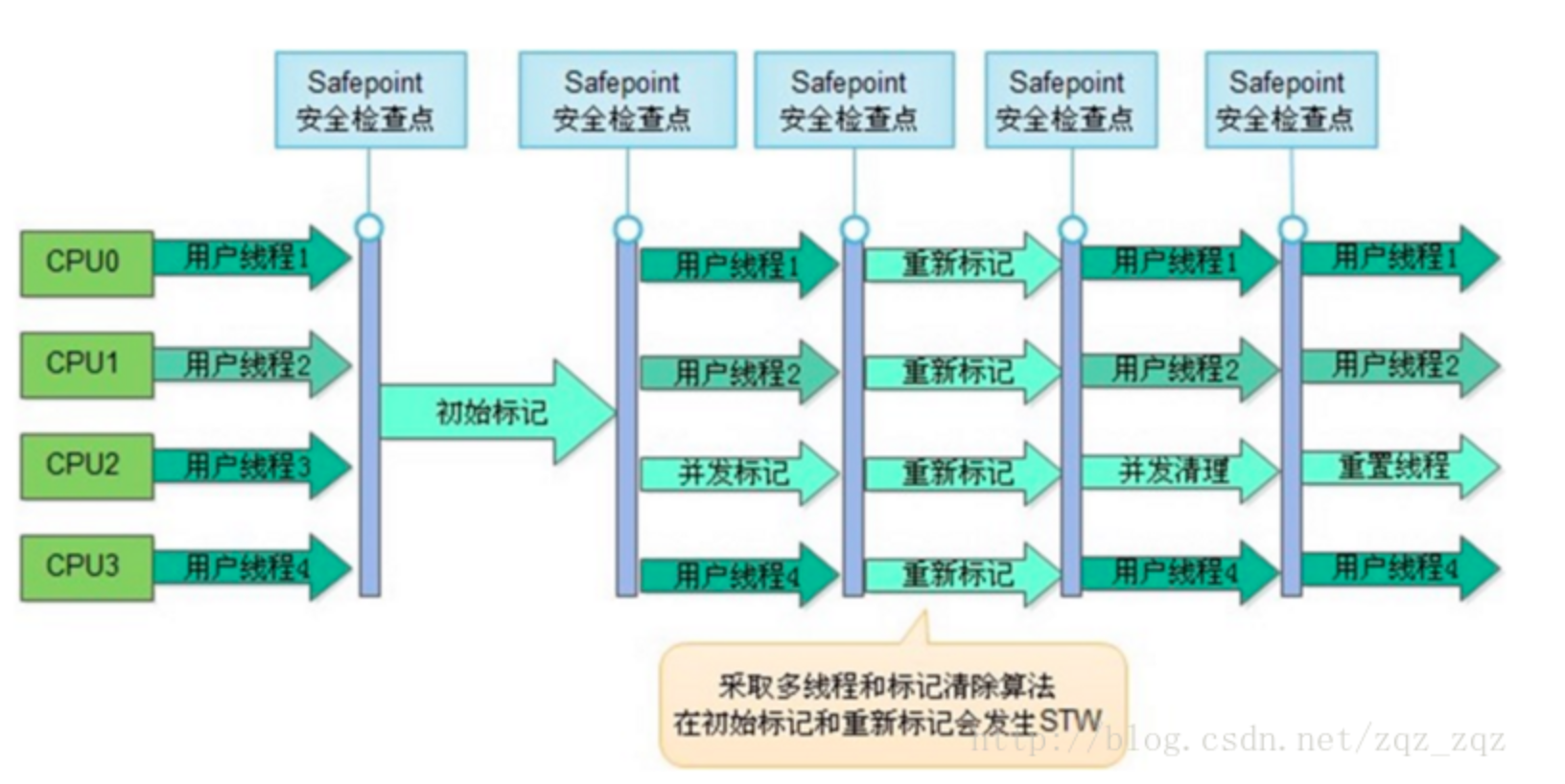
CMS 处理过程有七个步骤:
| 机制 | 时间 | ||
|---|---|---|---|
| 初始标记 | STW,标记老年代中能被GCroot直接引用的对象(list1) | 1% | |
| 并发标记 | 从list1出发,标记老年代所有对象(过程中用户线程会产生新的对象,标记为Dirty Card) | 80% | 可能会产生concurrent mode failure |
| 预清理 | 从 Dirty Card出发,标记老年代中的对象 | 5% | |
| 可被终止的预清理 | 没懂 | ||
| 重新标记 | STW,标记整个年老代和新生代的所有的存活对象 | ||
| 并发清除 | 清除那些没有标记的对象并且回收空间 | 会产生浮动垃圾 | |
| 并发重置 | 重新设置CMS算法内部的数据结构 |
Full/Major GC
2016-08-23T11:23:07.321-0200: 64.425: [GC (CMS Initial Mark)1[1 CMS-initial-mark: 10812086K(11901376K)] 10887844K(12514816K), 0.0001997 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
2016-08-23T11:23:07.321-0200: 64.425: [CMS-concurrent-mark-start]
2016-08-23T11:23:07.357-0200: 64.460: [CMS-concurrent-mark2: 0.035/0.035 secs] [Times: user=0.07 sys=0.00, real=0.03 secs]
2016-08-23T11:23:07.357-0200: 64.460: [CMS-concurrent-preclean-start]
2016-08-23T11:23:07.373-0200: 64.476: [CMS-concurrent-preclean3: 0.016/0.016 secs] [Times: user=0.02 sys=0.00, real=0.02 secs]
2016-08-23T11:23:07.373-0200: 64.476: [CMS-concurrent-abortable-preclean-start]
2016-08-23T11:23:08.446-0200: 65.550: [CMS-concurrent-abortable-preclean4: 0.167/1.074 secs] [Times: user=0.20 sys=0.00, real=1.07 secs]
2016-08-23T11:23:08.447-0200: 65.550: [GC (CMS Final Remark5)
[YG occupancy: 387920 K (613440 K)]65.550: [Rescan (parallel) , 0.0085125 secs]65.559:
[weak refs processing, 0.0000243 secs]65.559: [class unloading, 0.0013120 secs]65.560:
[scrub symbol table, 0.0008345 secs]65.561: [scrub string table, 0.0001759 secs][1 CMS-remark: 10812086K(11901376K)] 11200006K(12514816K), 0.0110730 secs]
[Times: user=0.06 sys=0.00, real=0.01 secs]
2016-08-23T11:23:08.458-0200: 65.561: [CMS-concurrent-sweep-start]
2016-08-23T11:23:08.485-0200: 65.588: [CMS-concurrent-sweep6: 0.027/0.027 secs] [Times: user=0.03 sys=0.00, real=0.03 secs]
2016-08-23T11:23:08.485-0200: 65.589: [CMS-concurrent-reset-start]
2016-08-23T11:23:08.497-0200: 65.601: [CMS-concurrent-reset7: 0.012/0.012 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
1、初始标记 CMS-initial-mark
STW,标记老年代中对象(非全部)
方式:
1、从GC跟出发的,找到的老年跟
2、从GC跟出发的,经过年代代活动对象引用的老年代对象
[2]
This is one of the two stop-the-world events during CMS. The goal of this phase is to mark all the objects in the Old Generation that are either direct GC roots or are referenced from some live object in the Young Generation. The latter is important since the Old Generation is collected separately.
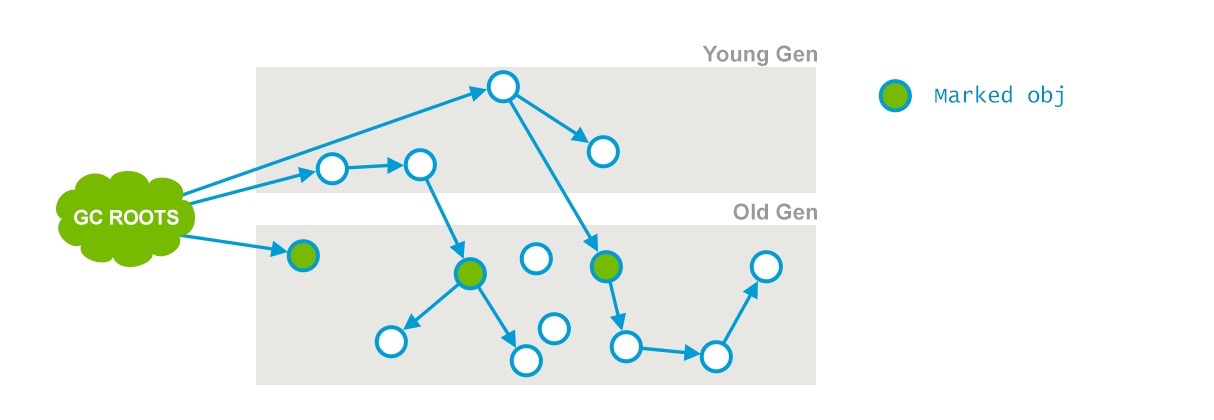
在Java语言里,可作为GC Roots对象的包括如下几种:
虚拟机栈(栈桢中的本地变量表)中的引用的对象 ;
方法区中的类静态属性引用的对象 ;
方法区中的常量引用的对象 ;
本地方法栈中JNI的引用的对象;
ps:为了加快此阶段处理速度,减少停顿时间,可以开启初始标记并行化,-XX:+CMSParallelInitialMarkEnabled,同时调大并行标记的线程数,线程数不要超过cpu的核数。
日志分析:
2016-08-23T11:23:07.321-0200: 64.421: [GC (CMS Initial Mark2[1 CMS-initial-mark: 10812086K3(11901376K)4] 10887844K5(12514816K)6, 0.0001997 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]7
- 016-08-23T11:23:07.321-0200: 64.42 – GC事件开始,包括时钟时间和相对JVM启动时候的相对时间,下边所有的阶段改时间的含义相同;
- CMS Initial Mark – 收集阶段,开始收集所有的GC Roots和直接引用到的对象;
- 10812086K – 当前老年代使用情况;
- (11901376K) – 老年代可用容量;
- 10887844K – 当前整个堆的使用情况;
- (12514816K) – 整个堆的容量;
- 0.0001997 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] – 时间计量;
从“初始标记”阶段标记的对象开始找出所有存活的对象;
2、并发标记 Concurrent Mark
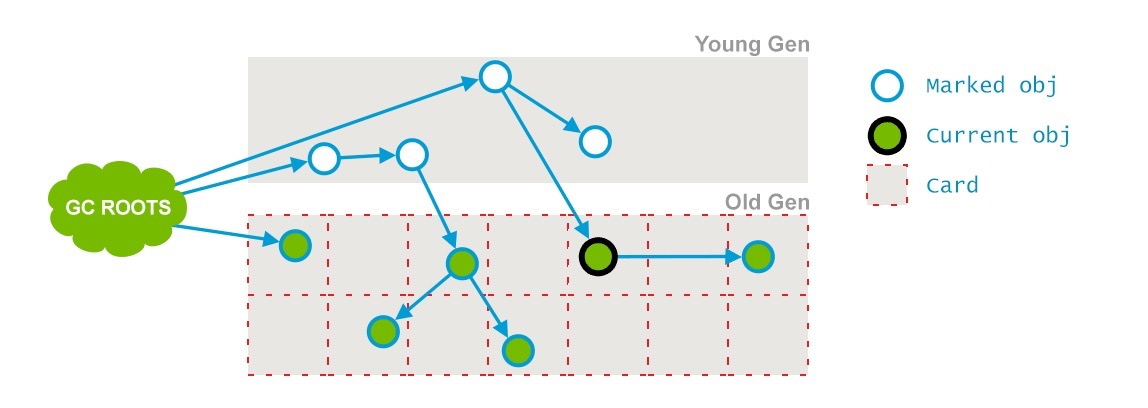
如下图所示,也就是节点1、2、3,最终找到了节点4和5。并发标记的特点是和应用程序线程同时运行。并不是老年代的所有存活对象都会被标记,因为标记的同时应用程序会改变一些对象的引用等。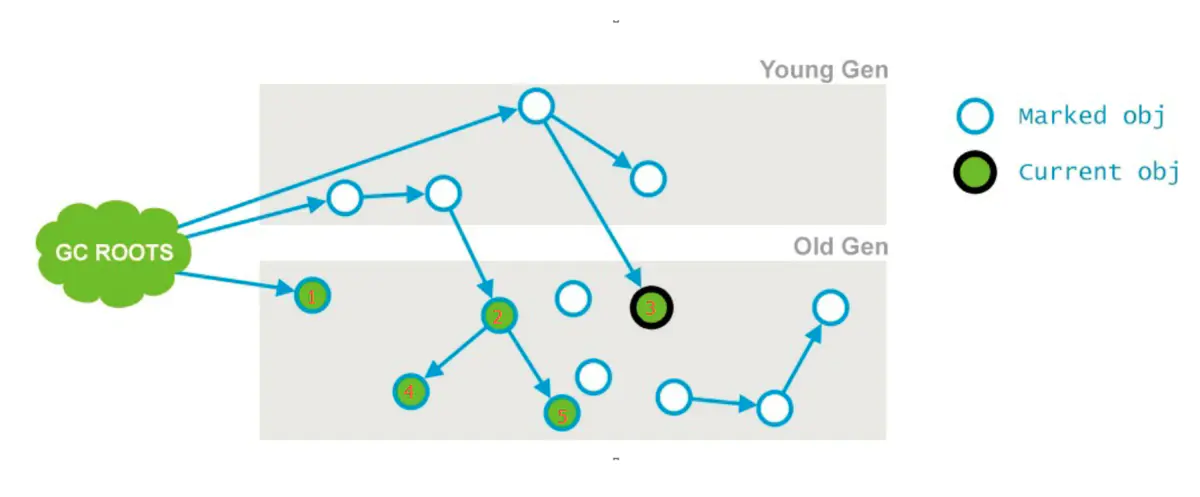
由于这个阶段是和用户线程并发的,可能会导致concurrent mode failure。
在比并发标记阶段,用户线程会新引用可能会产生一些新的老年代对象,每当产生时时,JVM将堆中包含变异对象的区域(称为“Card”)标记为“dirty”(称为Card Marking)。
如下图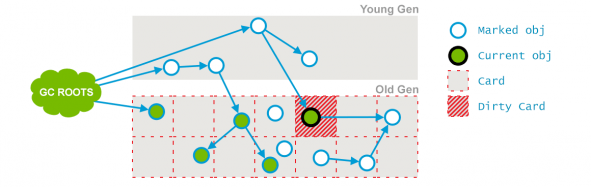
日志分析
2016-08-23T11:23:07.321-0200: 64.425: [CMS-concurrent-mark-start] 2016-08-23T11:23:07.357-0200: 64.460: [CMS-concurrent-mark1: 035/0.035 secs2] [Times: user=0.07 sys=0.00, real=0.03 secs]3
- CMS-concurrent-mark – 并发收集阶段,这个阶段会遍历整个年老代并且标记活着的对象;
- 035/0.035 secs – 展示该阶段持续的时间和时钟时间;
- [Times: user=0.07 sys=0.00, real=0.03 secs] – 同上
3、预清理阶段 Concurrent Preclean
这个阶段又是一个并发阶段,和应用线程并行运行,不会中断他们
从并发标记过程中产生的Dirty Card出发,标记从它们可到达的对象,并完成之后,清除脏状态。
如下图,从Dirty Card 3出发找到了 6,标记它,而后清除3的状态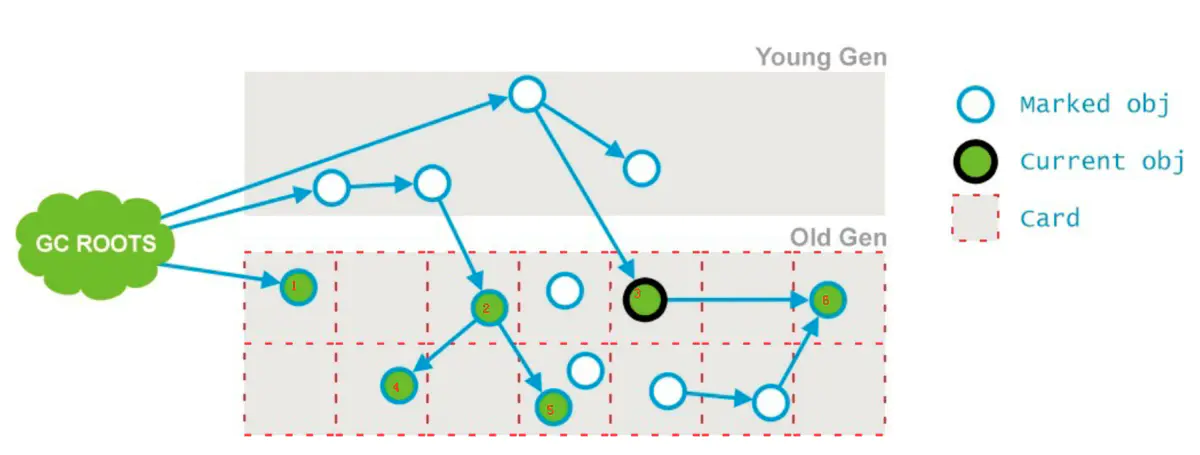
日志分析
2016-08-23T11:23:07.357-0200: 64.460: [CMS-concurrent-preclean-start] 2016-08-23T11:23:07.373-0200: 64.476: [CMS-concurrent-preclean1: 0.016/0.016 secs2] [Times: user=0.02 sys=0.00, real=0.02 secs]3
- CMS-concurrent-preclean – 这个阶段负责前一个阶段标记了又发生改变的对象标记;
- 0.016/0.016 secs – 展示该阶段持续的时间和时钟时间;
- [Times: user=0.02 sys=0.00, real=0.02 secs] – 同上
4、可终止的预处理 Concurrent Abortable Preclean
又一个并发阶段不会停止应用程序线程。
这个阶段尝试着去承担下一个阶段会STW的Final Remark阶段足够多的工作。这个阶段的确切持续时间取决于许多因素,因为它迭代做同样的事情,直到满足其中一个终止条件(例如迭代的次数、完成的有用工作的数量、经过的挂钟时间等)。
ps:此阶段最大持续时间为5秒,之所以持续5秒,另外一个原因也是为了期待这5秒内能够发生一次ygc,清理年轻代的引用,使得在下个阶段的重新标记阶段,扫描年轻带指向老年代的引用的时间减少;
日志分析
016-08-23T11:23:07.373-0200: 64.476: [CMS-concurrent-abortable-preclean-start] 2016-08-23T11:23:08.446-0200: 65.550: [CMS-concurrent-abortable-preclean1: 0.167/1.074 secs2] [Times: user=0.20 sys=0.00, real=1.07 secs]3
- CMS-concurrent-abortable-preclean – 可终止的并发预清理;
- 0.167/1.074 secs – 展示该阶段持续的时间和时钟时间
- [Times: user=0.20 sys=0.00, real=1.07 secs] – 同上
5、重新标记 Final Remark
STW.该阶段的任务是完成标记整个年老代和新生代的所有的存活对象。
方式:三色标记里的增量更新
这个阶段,重新标记的内存范围是整个堆,包含_young_gen和_old_gen。
为什么要扫描新生代呢,因为对于老年代中的对象,如果被新生代中的对象引用,那么就会被视为存活对象,即使新生代的对象已经不可达了,也会使用这些不可达的对象当做cms的“gc root”,来扫描老年代; 因此对于老年代来说,引用了老年代中对象的新生代的对象,也会被老年代视作“GC ROOTS”:
当此阶段耗时较长的时候,可以加入参数-XX:+CMSScavengeBeforeRemark,在重新标记之前,先执行一次ygc,回收掉年轻带的对象无用的对象,并将对象放入幸存带或晋升到老年代,这样再进行年轻带扫描时,只需要扫描幸存区的对象即可,一般幸存带非常小,这大大减少了扫描时间。
由于之前的预处理阶段是与用户线程并发执行的,这时候可能年轻带的对象对老年代的引用已经发生了很多改变,这个时候,remark阶段要花很多时间处理这些改变,会导致很长stop the word,所以通常CMS尽量在年轻代是足够干净的时候,运行Final Remark阶段。
另外,还可以开启并行收集:-XX:+CMSParallelRemarkEnabled。
日志分析:
2016-08-23T11:23:08.447-0200: 65.5501: [GC (CMS Final Remark2) [YG occupancy: 387920 K (613440 K)3]65.550: [Rescan (parallel) , 0.0085125 secs]465.559: [weak refs processing, 0.0000243 secs]65.5595: [class unloading, 0.0013120 secs]65.5606: [scrub string table, 0.0001759 secs7][1 CMS-remark: 10812086K(11901376K)8] 11200006K(12514816K) 9, 0.0110730 secs10] [[Times: user=0.06 sys=0.00, real=0.01 secs]11
- 2016-08-23T11:23:08.447-0200: 65.550 – 同上;
- CMS Final Remark – 收集阶段,这个阶段会标记老年代全部的存活对象,包括那些在并发标记阶段更改的或者新创建的引用对象;
- YG occupancy: 387920 K (613440 K) – 年轻代当前占用情况和容量;
- [Rescan (parallel) , 0.0085125 secs] – 这个阶段在应用停止的阶段完成存活对象的标记工作;
- weak refs processing, 0.0000243 secs]65.559 – 第一个子阶段,随着这个阶段的进行处理弱引用;
- class unloading, 0.0013120 secs]65.560 – 第二个子阶段(that is unloading the unused classes, with the duration and timestamp of the phase);
- scrub string table, 0.0001759 secs – 最后一个子阶段(that is cleaning up symbol and string tables which hold class-level metadata and internalized string respectively)
- 10812086K(11901376K) – 在这个阶段之后老年代占有的内存大小和老年代的容量;
- 11200006K(12514816K) – 在这个阶段之后整个堆的内存大小和整个堆的容量;
- 0.0110730 secs – 这个阶段的持续时间;
- [Times: user=0.06 sys=0.00, real=0.01 secs] – 同上;
通过以上5个阶段的标记,老年代所有存活的对象已经被标记并且现在要通过Garbage Collector采用清扫的方式回收那些不能用的对象了。
6、并发清理 Concurrent Sweep
这个阶段主要是清除那些没有标记的对象并且回收空间;
通过以上5个阶段的标记,老年代所有存活的对象已经被标记并且现在要通过Garbage Collector采用清扫的方式回收那些不能用的对象了。
由于CMS并发清理阶段用户线程还在运行着,伴随程序运行自然就还会有新的垃圾不断产生,这一部分垃圾出现在标记过程之后,CMS无法在当次收集中处理掉它们,只好留待下一次GC时再清理掉。这一部分垃圾就称为“浮动垃圾”。
日志分析:
2016-08-23T11:23:08.458-0200: 65.561: [CMS-concurrent-sweep-start] 2016-08-23T11:23:08.485-0200: 65.588: [CMS-concurrent-sweep1: 0.027/0.027 secs2] [[Times: user=0.03 sys=0.00, real=0.03 secs] 3
- CMS-concurrent-sweep – 这个阶段主要是清除那些没有标记的对象并且回收空间;
- 0.027/0.027 secs – 展示该阶段持续的时间和时钟时间;
- [Times: user=0.03 sys=0.00, real=0.03 secs] – 同上
7、并发重置 Concurrent Reset
这个阶段并发执行,重新设置CMS算法内部的数据结构,准备下一个CMS生命周期的使用。
日志分析
2016-08-23T11:23:08.485-0200: 65.589: [CMS-concurrent-reset-start] 2016-08-23T11:23:08.497-0200: 65.601: [CMS-concurrent-reset1: 0.012/0.012 secs2] [[Times: user=0.01 sys=0.00, real=0.01 secs]3
- CMS-concurrent-reset – 这个阶段重新设置CMS算法内部的数据结构,为下一个收集阶段做准备;
- 0.012/0.012 secs – 展示该阶段持续的时间和时钟时间;
- [Times: user=0.01 sys=0.00, real=0.01 secs] – 同上
CMS注意点
减少remark阶段停顿
一般CMS的GC耗时80%都在remark阶段,如果发现remark阶段停顿时间很长,可以尝试添加该参数:
-XX:+CMSScavengeBeforeRemark。
在执行remark操作之前先做一次Young GC,目的在于减少年轻代对老年代的无效引用,降低remark时的开销。
内存碎片问题
CMS是基于标记-清除算法的,CMS只会删除无用对象,不会对内存做压缩,会造成内存碎片,这时候我们需要用到这个参数:
-XX:CMSFullGCsBeforeCompaction=n
意思是说在上一次CMS并发GC执行过后,到底还要再执行多少次full GC才会做压缩。默认是0,也就是在默认配置下每次CMS GC顶不住了而要转入full GC的时候都会做压缩。 如果把CMSFullGCsBeforeCompaction配置为10,就会让上面说的第一个条件变成每隔10次真正的full GC才做一次压缩。
concurrent mode failure
这个异常发生在cms正在回收的时候。执行CMS GC的过程中,同时业务线程也在运行,当年轻带空间满了,执行ygc时,需要将存活的对象放入到老年代,而此时老年代空间不足,这时CMS还没有机会回收老年带产生的,或者在做Minor GC的时候,新生代救助空间放不下,需要放入老年代,而老年代也放不下而产生的。
设置cms触发时机有两个参数:
-XX:+UseCMSInitiatingOccupancyOnly
-XX:CMSInitiatingOccupancyFraction=70
-XX:CMSInitiatingOccupancyFraction=70 是指设定CMS在对内存占用率达到70%的时候开始GC。
-XX:+UseCMSInitiatingOccupancyOnly如果不指定, 只是用设定的回收阈值CMSInitiatingOccupancyFraction,则JVM仅在第一次使用设定值,后续则自动调整会导致上面的那个参数不起作用。
为什么要有这两个参数?
由于在垃圾收集阶段用户线程还需要运行,那也就还需要预留有足够的内存空间给用户线程使用,因此CMS收集器不能像其他收集器那样等到老年代几乎完全被填满了再进行收集,需要预留一部分空间提供并发收集时的程序运作使用。
CMS前五个阶段都是标记存活对象的,除了”初始标记”和”重新标记”阶段会stop the word ,其它三个阶段都是与用户线程一起跑的,就会出现这样的情况gc线程正在标记存活对象,用户线程同时向老年代提升新的对象,清理工作还没有开始,old gen已经没有空间容纳更多对象了,这时候就会导致concurrent mode failure, 然后就会使用串行收集器回收老年代的垃圾,导致停顿的时间非常长。
CMSInitiatingOccupancyFraction参数要设置一个合理的值,设置大了,会增加concurrent mode failure发生的频率,设置的小了,又会增加CMS频率,所以要根据应用的运行情况来选取一个合理的值。如果发现这两个参数设置大了会导致full gc,设置小了会导致频繁的CMS GC,说明你的老年代空间过小,应该增加老年代空间的大小了。
promotion failed
在进行Minor GC时,Survivor Space放不下,对象只能放入老年代,而此时老年代也放不下造成的,多数是由于老年带有足够的空闲空间,但是由于碎片较多,新生代要转移到老年带的对象比较大,找不到一段连续区域存放这个对象导致的。
过早提升与提升失败
在 Minor GC 过程中,Survivor Unused 可能不足以容纳 Eden 和另一个 Survivor 中的存活对象, 那么多余的将被移到老年代, 称为过早提升(Premature Promotion),这会导致老年代中短期存活对象的增长, 可能会引发严重的性能问题。 再进一步,如果老年代满了, Minor GC 后会进行 Full GC, 这将导致遍历整个堆, 称为提升失败(Promotion Failure)。
早提升的原因
Survivor空间太小,容纳不下全部的运行时短生命周期的对象,如果是这个原因,可以尝试将Survivor调大,否则端生命周期的对象提升过快,导致老年代很快就被占满,从而引起频繁的full gc;
对象太大,Survivor和Eden没有足够大的空间来存放这些大对象。
提升失败原因
当提升的时候,发现老年代也没有足够的连续空间来容纳该对象。为什么是没有足够的连续空间而不是空闲空间呢?老年代容纳不下提升的对象有两种情况:
老年代空闲空间不够用了;
老年代虽然空闲空间很多,但是碎片太多,没有连续的空闲空间存放该对象。
解决方法
如果是因为内存碎片导致的大对象提升失败,cms需要进行空间整理压缩;
如果是因为提升过快导致的,说明Survivor 空闲空间不足,那么可以尝试调大 Survivor;
如果是因为老年代空间不够导致的,尝试将CMS触发的阈值调低。
Minor GC
过程
在GC开始的时候,对象只会存在于Eden区和名为“From”的Survivor区,Survivor区“To”是空的。紧接着进行GC,Eden区中所有存活的对象都会被复制到“To”,而在“From”区中,仍存活的对象会根据他们的年龄值来决定去向。年龄达到一定值(年龄阈值,可以通过-XX:MaxTenuringThreshold来设置)的对象会被移动到年老代中,没有达到阈值的对象会被复制到“To”区域。经过这次GC后,Eden区和From区已经被清空。这个时候,“From”和“To”会交换他们的角色,也就是新的“To”就是上次GC前的“From”,新的“From”就是上次GC前的“To”。
不管怎样,都会保证名为To的Survivor区域是空的。Minor GC会一直重复这样的过程,直到“To”区被填满,“To”区被填满之后,会将所有对象移动到年老代中。
2016-08-23T02:23:07.219-02001: 64.3222:[GC3(Allocation Failure4) 64.322: [ParNew5: 613404K->68068K6(613440K)7, 0.1020465 secs8] 10885349K->10880154K9(12514816K)10, 0.1021309 secs11][Times: user=0.78 sys=0.01, real=0.11 secs]12
- 2016-08-23T02:23:07.219-0200 – GC发生的时间;
- 64.322 – GC开始,相对JVM启动的相对时间,单位是秒;
- GC – 区别MinorGC和FullGC的标识,这次代表的是MinorGC;
- Allocation Failure – MinorGC的原因,在这个case里边,由于年轻代不满足申请的空间,因此触发了MinorGC;
- ParNew – 收集器的名称,它预示了年轻代使用一个并行的 mark-copy stop-the-world 垃圾收集器;
- 613404K->68068K – 收集前后年轻代的使用情况;
- (613440K) – 整个年轻代的容量;
- 0.1020465 secs – 这个解释用原滋原味的解释:Duration for the collection w/o final cleanup.
- 10885349K->10880154K – 收集前后整个堆的使用情况;
- (12514816K) – 整个堆的容量;
- 0.1021309 secs – ParNew收集器标记和复制年轻代活着的对象所花费的时间(包括和老年代通信的开销、对象晋升到老年代时间、垃圾收集周期结束一些最后的清理对象等的花销);
- [Times: user=0.78 sys=0.01, real=0.11 secs] – GC事件在不同维度的耗时,具体的用英文解释起来更加合理:
- user – Total CPU time that was consumed by Garbage Collector threads during this collection
- sys – Time spent in OS calls or waiting for system event
- real – Clock time for which your application was stopped. With Parallel GC this number should be close to (user time + system time) divided by the number of threads used by the Garbage Collector. In this particular case 8 threads were used. Note that due to some activities not being parallelizable, it always exceeds the ratio by a certain amount.
我们来分析下对象晋升问题(原文中的计算方式有问题):
开始的时候:整个堆的大小是10885349K,年轻代大小是613404K,这说明老年代大小是 10885349-613404=10271945K,
收集完成之后:整个堆的大小是 10880154K,年轻代大小是68068K,这说明老年代大小是 10880154-68068=10812086K,
老年代的大小增加了:10812086-10271945=608209K,也就是说 年轻代到年老代promot了608209K的数据;
图形分析: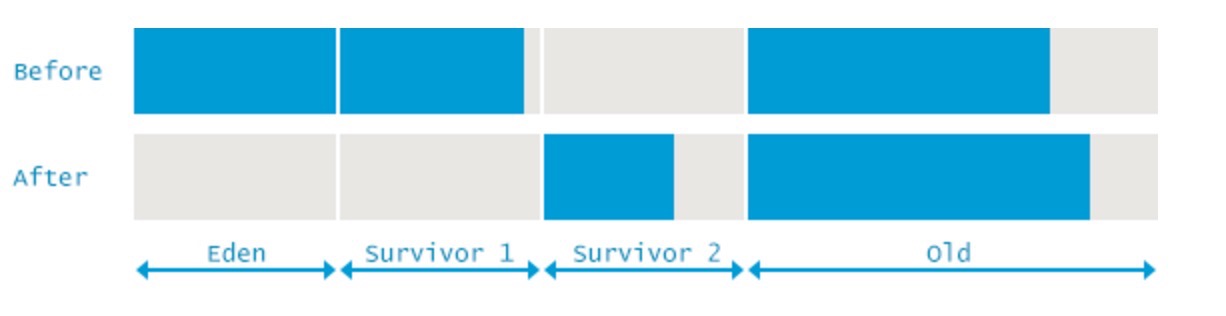
参考
1、 GC之详解CMS收集过程和日志分析 - 凌渡冰 - 博客园)
2、https://plumbr.io/handbook/garbage-collection-algorithms-implementations#concurrent-mark-and-sweep

若有收获,就点个赞吧
0 人点赞
