9.10
为了解决一个层次树转父子树的问题,实验了一周,稍微总结一下为什么失败了这么多次.
首先数据库里有这样一张表嗯,然后主键唯一的macid对应唯一macname,每个macid有一个可以重复的macpath.
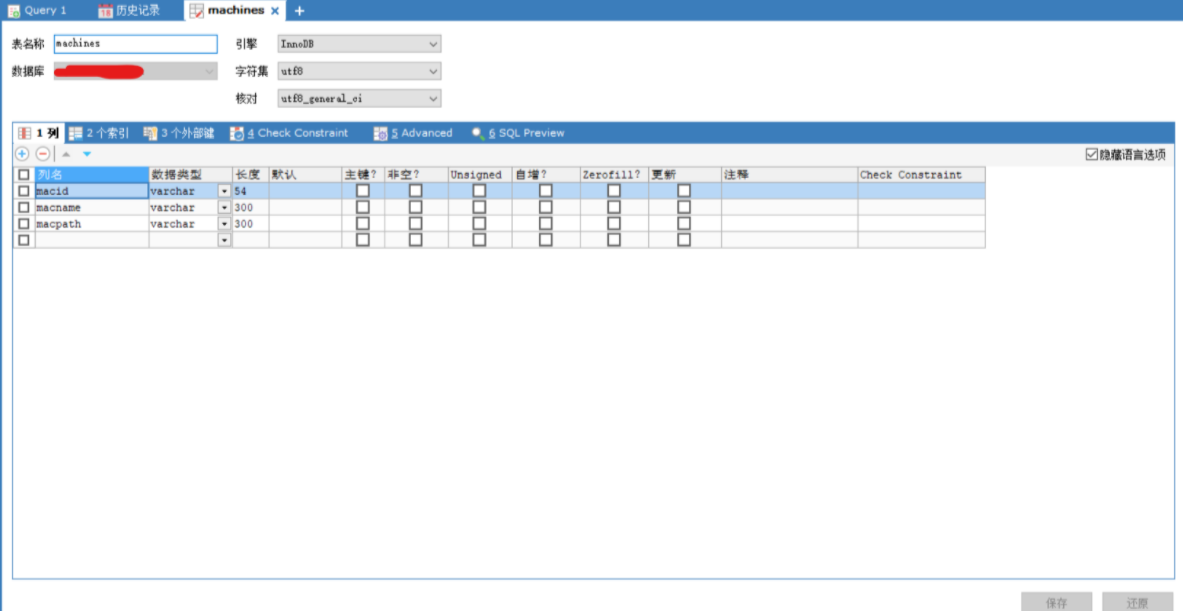
表的行类似于
{"macid": "114514""macname": "下北泽""macpath": "亚欧大陆/中原/大吴疆土/合肥"}
然后前端页面需要传递给element-ui的tree组件的格式和这个完全不一样.前端给一个macname过来后端数据库根据macpath模糊查询符合条件的所有macname,macpath.
对于这种路径不定的macpath,我比较尴尬,我没有处理这种层次树的经验,以前都是处理那种有父节点id的二维表.
然后我的第一种方案是先for一下,但是这样是查出来了,没有实现同一父节点的合并.
//下为OverViewAriesBO.java@Data@AllArgsConstructor@NoArgsConstructor@Builderpublic class OverViewAriesBO {private String id;private String label;private List<OverViewAriesBO> children;}//MachinesPO就是PO,对数据库的表完整映射// 下为OverViewServiceImpl.java//服务于element的tree组件的格式要求@Overridepublic List<OverViewAriesBO> findPathTree(String company) {List<MachinesPO> path = overViewMapper.findPathTree(company);List<OverViewAriesBO> overViewAriesBOS = new ArrayList<>();for (MachinesPO machinesPO : path) {OverViewAriesBO firstBo = OverViewAriesBO.builder().label(machinesPO.getMacpath().split("/", 3)[0]).build();overViewAriesBOS.add(firstBo);OverViewAriesBO secondBo = OverViewAriesBO.builder().label(machinesPO.getMacpath().split("/", 3)[1]).build();firstBo.setChildren(new ArrayList<OverViewAriesBO>() {{add(secondBo);}});OverViewAriesBO thirdBo = OverViewAriesBO.builder().label(machinesPO.getMacpath().split("/", 3)[2]).build();secondBo.setChildren(new ArrayList<OverViewAriesBO>() {{add(thirdBo);}});OverViewAriesBO finallyBo = OverViewAriesBO.builder().id(machinesPO.getMacid()).label(machinesPO.getMacname()).children(null).build();thirdBo.setChildren(new ArrayList<OverViewAriesBO>() {{add(finallyBo);}});}return overViewAriesBOS;}}
//别尬黑,我改过json数据了[{"id": null,"label": "叔叔我啊叔叔我啊","children": [{"id": null,"label": "真的要生气了","children": [{"id": null,"label": "红萝卜","children": [{"id": "1232864287364293","label": "PA11","children": null}]}]}]},{"id": null,"label": "叔叔我啊叔叔我啊","children": [{"id": null,"label": "真的要生气了","children": [{"id": null,"label": "红萝卜","children": [{"id": "23426346329232","label": "PA12","children": null}]}]}]},{"id": null,"label": "叔叔我啊叔叔我啊","children": [{"id": null,"label": "真的要生气了","children": [{"id": null,"label": "红萝卜","children": [{"id": "23462364328746329","label": "PTA2汽轮发电机组","children": null}]}]}]},{"id": null,"label": "叔叔我啊叔叔我啊","children": [{"id": null,"label": "真的要生气了","children": [{"id": null,"label": "红萝卜/白萝卜","children": [{"id": "234234345456","label": "PA2A","children": null}]}]}]},{"id": null,"label": "叔叔我啊叔叔我啊","children": [{"id": null,"label": "真的要生气了","children": [{"id": null,"label": "绿萝卜","children": [{"id": "2343456556544353","label": "PA2B","children": null}]}]}]}]
然后我试验了一下stream流,感觉不对劲,当时写完就觉得不妥.那个版本删了.
然后我手动操作了一下树.
/*** @类名称: MsgNode*/@Data@NoArgsConstructorpublic class MsgNode implements Serializable {/*** @属性名称: serialVersionUID*/private static final long serialVersionUID = 6334350503505500989L;private String fldNm; // 报文字段名称private String path; // 节点路径private List<MsgNode> children = null;public MsgNode(String path,String name) {this.path = path;this.fldNm = name;}}
//服务于element的tree组件的格式要求@Overridepublic List<MsgNode> findPathTree(String company) {List<MachinesPO> path = overViewMapper.findPathTree(company);List<MsgNode> msgNodes = pathToTree(path);return msgNodes;}public static List<MsgNode> pathToTree(List<MachinesPO> flds) {List<MsgNode> tree = new ArrayList<>();//hashset特点,HashSet 基于 HashMap 来实现的,是一个不允许有重复元素的集合。HashSet 允许有 null 值。HashSet 是无序的,即不会记录插入的顺序。HashSet<MsgNode> set = new HashSet<>();for (MachinesPO fld : flds) { //对MachinesPO的List进行遍历String path = fld.getMacpath();while (path.contains("/")) { //当macpath存在多级路径,进入while循环// 子节点的路径和名称int index = path.lastIndexOf("/");MsgNode childNode = new MsgNode(path, path.substring(index + 1)); //path采用全路径,以路径的最后一级作为子节点的name// 父节点的路径和名称String parPaht = path.substring(0, index);//父节点的path为子节点path的前面全路径,name为子节点name的上一级路径,确保父子节点能衔接上MsgNode parentNode = new MsgNode(parPaht, parPaht.substring(parPaht.lastIndexOf("/") + 1));if (set.contains(parentNode)) { //如果hashset里面已经存在这个parentNode父节点for (MsgNode msgNode : set) { //对hashset集合的每一个MsgNode元素遍历if (msgNode.getPath().equals(parentNode.getPath())) { //找到这个已存在的父节点的pathparentNode = msgNode; //改变父节点为该值break; //退出for循环}}} else { //如果hashset里面不存在这个父节点set.add(parentNode); //将父节点加入hashset}if (set.contains(childNode)) { // 如果hashset里面已经存在这个childNode子节点for (MsgNode msgNode : set) { // 对hashset集合的每一个MsgNode元素遍历if (msgNode.getPath().equals(childNode.getPath())) { //找到这个已存在的子节点的pathchildNode = msgNode; //改变子节点为该值break; //退出for循环}}if (null != parentNode.getChildren()) { //如果hashset找到父节点,而且parentNode父节点存在子节点if (!parentNode.getChildren().contains(childNode)) { //如果childNode子节点的内容不等于parentNode父节点已存在子节点parentNode.getChildren().add(childNode); //parentNode父节点的子节点list加入这个新的childNode子节点}} else { // 无论hashset找没找到父节点,如果parentNode父节点不存在子节点List<MsgNode> children = new ArrayList<>();children.add(childNode);// parentNode父节点设置新的子节点list,并把childNode子节点赋给parentNode父节点的子节点list中去parentNode.setChildren(children);}} else { // 如果hashset里面不存在这个childNode子节点if (null != parentNode.getChildren()) { // 如果hashset找到父节点,而且parentNode父节点存在子节点parentNode.getChildren().add(childNode); // parentNode父节点将childNode子节点加入自己的子节点list} else { // 无论hashset找没找到父节点,如果parentNode父节点不存在子节点List<MsgNode> children = new ArrayList<>();children.add(childNode);// parentNode父节点设置新的子节点list,并把childNode子节点赋给parentNode父节点的子节点list中去parentNode.setChildren(children);}set.add(childNode); //hashset里添加这个childNode节点}path = parPaht; //让path等于parentNode父节点的path,执行下一轮while循环}} //此时才完成对MachinesPO的List的遍历for (MsgNode msgNode : set) { // 对于hashset的MsgNode进行遍历//因为hashset里面包含不重复的父节点和子节点,需要判断如果MsgNode的路径都不存在/了,即path只有单层层次,才让MsgNode进入treeif (!msgNode.getPath().contains("/")) {tree.add(msgNode); //让这个符合单层结构path的MsgNode进入List<MsgNode> tree}}return tree; //返回List<MsgNode> tree}
看起来非常不完美.蚌埠住了.
[{"fldNm": "概率论","path": "概率论","children": [{"fldNm": "你滴勋宗无限猖狂","path": "概率论/你滴勋宗无限猖狂","children": null}]},{"fldNm": "概率论","path": "概率论","children": [{"fldNm": "你滴勋宗无限猖狂","path": "概率论/你滴勋宗无限猖狂","children": [{"fldNm": "甲醇装置","path": "概率论/你滴勋宗无限猖狂/甲醇装置","children": null},{"fldNm": "煤气装置","path": "概率论/你滴勋宗无限猖狂/煤气装置","children": null}]}]},{"fldNm": "概率论","path": "概率论","children": [{"fldNm": "山西同煤广发化学工业有限公司","path": "概率论/你滴勋宗无限猖狂","children": [{"fldNm": "甲醇装置","path": "概率论/你滴勋宗无限猖狂/甲醇装置","children": null},{"fldNm": "煤气装置","path": "概率论/你滴勋宗无限猖狂/煤气装置","children": null}]}]},{"fldNm": "概率论","path": "概率论","children": [{"fldNm": "你滴勋宗无限猖狂","path": "概率论/你滴勋宗无限猖狂","children": [{"fldNm": "甲醇装置","path": "概率论/你滴勋宗无限猖狂/甲醇装置","children": null},{"fldNm": "煤气装置","path": "概率论/你滴勋宗无限猖狂/煤气装置","children": null}]}]}]
写一个去除数组中的空元素的中间方法时突然意识到问题
/**** 去除数组中的空元素* @author linghengqian* @date 2021/09/10 00:28* @return java.lang.String[]*/private static String[] deleteArrayNull(String[] string) {// step1: 定义一个list列表,并循环赋值ArrayList<String> strList = new ArrayList<>();Collections.addAll(strList, string);// step2: 删除list列表中所有的空值strList.removeIf(s -> Objects.equals(s, "") || s == null);// step3: 把list列表转换给一个新定义的中间数组,并赋值给它return strList.toArray(new String[0]);}
将集合转换为数组有两种样式:使用预先调整大小的数组(如c.toArray(new String [c.size()]))或使用空数组(如c.toArray(new String [ 0])。在较旧的Java版本中,建议使用预先调整大小的数组,因为创建适当大小的数组所需的反射调用非常慢。但是由于OpenJDK 6的后期更新,这个调用是内在的,使得性能得以提高与预先调整大小的版本相比,空数组版本相同,有时甚至更好。同时传递预先调整大小的数组对于并发或同步集合是危险的,因为大小和toArray调用之间可能存在数据争用,这可能会导致额外的如果集合在操作期间同时收缩,则数组末尾为空。此检查允许遵循统一样式:使用空数组(在现代Java中推荐)或使用预先调整大小的数组(在旧Java版本或基于非HotSpot的JVM中可能更快)。
不会有人部署时用Eclipse OpenJ9 JVM吧,不会吧不会吧?
然后我网上又整了一套下来看,对着打注释
//服务于element的tree组件的格式要求@Overridepublic List<MachinesPO> findPathTree(String company) {List<String> fileList = Arrays.asList("192.168.3.140/SPShareFile/secondtest.txt", "192.168.3.140/SPShareFile/新建文本文档.txt", "/opt/Spinfo/testCL/typeofball.txt");List<NameToValDto> nvdListAll = new ArrayList<>(); //引入新的NameToValDto的list,名为nvdListAllfileList.forEach(f -> { //对fileList的每一个String对象,即pathString[] pathesP = f.split("/"); //把path分割为若干份单路径,合为数组String[] notNullVal = deleteArrayNull(pathesP); //删除pathesP数组中的空元素,叫notNullValList<NameToValDto> nvdList = new ArrayList<>(); //新建一个NameToValDto的临时list,叫nvdListString tagFileOnly = ""; //新建一个叫tagFileOnly的string对象for (int i = 0; i < notNullVal.length; i++) { //对无重复路径的notNullVal的每一个string对象做遍历tagFileOnly += notNullVal[i]; //对notNullVal的第i个string对象,添加到tagFileOnly尾部String topName = notNullVal[0]; //将notNullVal的第0个string对象,即最高一级路径赋给topName(string)if (i == notNullVal.length - 1) { //如果i已经是notNullVal的最后一个string对象//将i+1的值转字符串,notNullVal的第i个string对象,i的值转字符串,最后一级的判断属性(file),莫名其妙的sp,最高一级路径(notNullVal的第0个string对象),istop属性,加上notNullVal的第i个string对象后的tagFileOnlyNameToValDto nvd = new NameToValDto(String.valueOf(i + 1), notNullVal[i], String.valueOf(i), "file", "sp", topName, false, tagFileOnly);// 把这个NameToValDto,add进叫nvdList的NameToValDto的临时listnvdList.add(nvd);} else if (i == 0) { //如果i是notNullVal的第0个string对象NameToValDto nvd = new NameToValDto(String.valueOf(i + 1), notNullVal[i], String.valueOf(i), "dir", "sp", topName, true, tagFileOnly);nvdList.add(nvd);} else { //如果i是notNullVal中间而非两端的string对象NameToValDto nvd = new NameToValDto(String.valueOf(i + 1), notNullVal[i], String.valueOf(i), "dir", "sp", topName, false, tagFileOnly);nvdList.add(nvd);}} //完成对notNullVal的遍历nvdListAll.addAll(nvdList); //把nvdList的NameToValDto全部放入nvdListAll中,进行下一个String的foreach遍历}); //完成fileList原始数据的foreach操作List<NameToValDto> nts = new ArrayList<>(); //制造新的NameToValDto的list,取名ntsMap<String, List<NameToValDto>> ntMap = nvdListAll.stream().collect(Collectors.groupingBy(NameToValDto::getTopName)); //制造ntMap.forEach((k, v) -> {String uuid = IdUtils.UUID();v.forEach(o -> {o.setId(uuid + o.getId());o.setPid(uuid + o.getPid());});List<NameToValDto> nv = v.stream().collect(Collectors.collectingAndThen(Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(NameToValDto::getName))), ArrayList::new));nts.addAll(nv);});NameToValDto creatTopOne = new NameToValDto("-1", "信息源", "0");nts.forEach(s -> {if (s.isTop()) {s.setPid("-1");}});nts.add(creatTopOne);List<NameToValDto> parentNode = nts.stream().filter(x -> x.getPid().equals("0")).collect(Collectors.toList());DiGuiTree audeptTree = new DiGuiTree(parentNode, nts);List<NameToValDto> treelist = audeptTree.returnList();List<MachinesPO> path = overViewMapper.findPathTree(company);return path;}/**** 去除数组中的空元素* @date 2021/09/10 07:28* @return java.lang.String[]*/private static String[] deleteArrayNull(String[] string) {// step1: 定义一个list列表,并循环赋值ArrayList<String> strList = new ArrayList<>();Collections.addAll(strList, string);// step2: 删除list列表中所有的空值strList.removeIf(s -> Objects.equals(s, "") || s == null);// step3: 把list列表转换给一个新定义的中间数组,并赋值给它return strList.toArray(new String[0]);}
//没实现完....懒得实现了@Datapublic class NameToValDto {private String id;private String pid;private String name;private String topName;private boolean isTop;private List<NameToValDto> children;public NameToValDto(String id, String pid, String name, String topName, boolean isTop, List<NameToValDto> children) {this.id = id;this.pid = pid;this.name = name;this.topName = topName;this.isTop = isTop;this.children = children;}public NameToValDto(String valueOf, String s, String valueOf1, String file, String sp, String topName, boolean b, String tagFileOnly) {}public NameToValDto(String valueOf, String 信息源, String valueOf1) {}}
@AllArgsConstructorpublic class DiGuiTree {/*** 父节点*/private List<NameToValDto> root;/*** 所有节点(或不包含父节点)*/private List<NameToValDto> body;public List<NameToValDto> returnList() {if (body != null && !body.isEmpty()) {Map<String, String> map = new HashMap<>();root.forEach(entity -> getChildren(entity, map));return root;}return null;}public void getChildren(NameToValDto tnvo, Map<String, String> map) {List<NameToValDto> children = new ArrayList<>();body.stream().filter(entity -> !map.containsKey(entity.getId())).filter(entity -> entity.getPid().equals(tnvo.getId())).forEach(entity -> {map.put(entity.getId(), entity.getPid());getChildren(entity, map);children.add(entity);});tnvo.setChildren(children);}}
public class IdUtils {/*** 基于UUID+MD5产生唯一无序ID* <pre>* 线程数量: 100* 执行次数: 1000* 平均耗时: 591 ms* 数组长度: 100000* Map Size: 100000* </pre>** @return ID长度32位*/public static String UUID() {return DigestUtils.md5Hex(UUID.randomUUID().toString());}/* ---------------------------------------------分割线------------------------------------------------ *//*** 字符串MD5处理类*/private static class DigestUtils {private static final char[] DIGITS_LOWER ={'0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f'};private static char[] encodeHex(final byte[] data) {final int l = data.length;final char[] out = new char[l << 1];for (int i = 0, j = 0; i < l; i++) {out[j++] = DigestUtils.DIGITS_LOWER[(0xF0 & data[i]) >>> 4];out[j++] = DigestUtils.DIGITS_LOWER[0x0F & data[i]];}return out;}public static String md5Hex(String str) {String md5;try {md5 = new String(encodeHex(MessageDigest.getInstance("MD5").digest(str.getBytes(StandardCharsets.UTF_8))));} catch (Exception e) {throw new RuntimeException(e);}return md5;}}}
越整越复杂,我全丢了算了,直接用递归,不考虑时间复杂度了

若有收获,就点个赞吧
0 人点赞
